Ubuntu-22.04搭建 k8s-1.30.1集群,开启Dashboard-v2.7.0(以及Token不生成的问题)、部署ingress-nginx-1.10.1
引言
最近在研究分布式计算,想将分布式计算都容器化,使用
k8s来调度,所以从0开始学k8s,这是我遇到坑后百度、查资料一点一点总结的搭建过程,贴在这方便以后自己找,也希望对你能有所帮助,后续有问题我会更新这篇博客的内容
***特别注意:当k8s集群init了以后的kubectl命令最好都等上一步的命令执行完了再进行下一步操作,不要抢着执行,随时看Pod的状态kubectl get pods -A,只要还有一个没有Running就不要着急下一步
一、系统环境准备
用
Ubuntu-22.04版本,CentOS操作核心是一样的,只是命令不同罢了
1、关闭 swap
官方要求关闭
swap,虚拟内存相关,因为Kubernetes无法读取虚拟内存相关的数据,开启这个可能会导致Kubernetes的内存问题
要想永久关,得先解除程序占用,临时关闭
swap:
swapoff -a
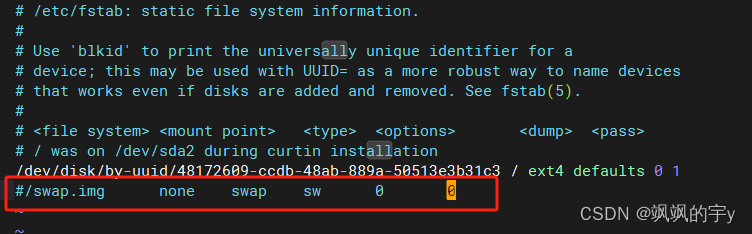
修改配置文件永久关闭,注释这个文件:
vi /etc/fstab
中的关于
swap的那一行,如图,注释掉它:
2、关闭 SELinux
Ubuntu没有这个东西可以不管,CentOS执行:
sudo sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
然后重启系统即可。
SELinux是系统安全方面的,如果你懂怎么弄可以自己配置SELinux就不用关,很麻烦,所以大家基本都关了的
3、关闭防火墙
需要关闭防火墙,因为节点之间要互相通信,开防火墙容易出问题
ufw disable
# 或者
systemctl disable --now ufw
4、设置时区(根据自己的时间情况可选)
因为关系到集群机器之间的通信,需要一个时间同步大家的行为。设置为上海时区
timedatectl set-timezone Asia/Shanghai
重启时间同步服务
systemctl restart systemd-timesyncd.service
看一下时间对不对:
timedatectl status
# 或者
date
5、修改 /etc/hosts 、/etc/hostname
这个是为了后面填地址的时候方便以及
Kubernetes要识别主机名
修改
hosts文件,将自己的IP地址和主机名填进去:
echo "192.168.10.10 k8s-master" | sudo tee -a /etc/hosts
其他节点的你想填也填进去
修改
hostsname文件,两种办法,一种是hostnamectl命令,一种是直接修改文件,修改文件的方式:
echo "k8s-master" | sudo tee /etc/hostname
修改完主机名文件后最好重启一次ssh终端或系统
6、开启流量转发
开这个的原因是让各个主机承担起网络路由的角色,因为后续还要安装网络插件,要有一个路由器各个
Pod才能互相通信。开IPv4,跟着抄就行,我也是抄的:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
二、安装 containerd 运行时环境
Kubernetes-1.24版本移除了dockershim的支持,所以之前的先安装docker再安装Kubernets的方式已经不可行了,可能会导致Kubelet报错退出,所以我们要先安装containerd运行时环境。这时可能就有人问了,安装Docker时不是带有containerd了吗,你说得对,安装Docker时确实是apt install -y docker-ce docker-ce-cli containerd.io,确实安装了containerd,但是这是Docker的containerd啊,这么安装的containerd是由Docker管理的,k8s无法管理,所以就会导致报错,踩过的坑啊。
1、下载安装
***如果使用k8s1.24版本以上,那么containerd一定要单独安装,不要想着安装Docker了会自带,k8s启动会报错
去GitHub上下载二进制包,想要其他版本的话替换两处1.7.17为你想要的版本即可:
curl -O https://github.com/containerd/containerd/releases/download/v1.7.17/cri-containerd-cni-1.7.17-linux-amd64.tar.gz
解压到根目录:
tar -zxvf cri-containerd-cni-1.7.17-linux-amd64.tar.gz -C /
启动
containerd并且开机自启:
sudo systemctl start containerd
sudo systemctl enable containerd
执行看版本正不正常:
containerd -v

2、生成配置文件(重要)
因为我们是用二进制包直接解压的,所以要手动生成配置文件,很重要,没有这个配置文件的话,你会发现整个
kubelet在无限重启,因为etcd起不来,导致其他容器都在重启。执行:
sudo mkdir -p /etc/containerd
sudo containerd config default > /etc/containerd/config.toml
(可选,看情况)修改这个文件的
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]中的SystemdCgroup为true:
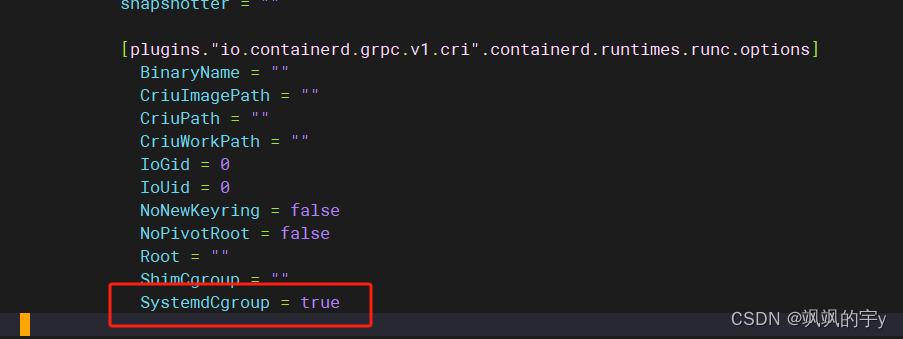
这个配置指定是否使用
systemd来管理cgroup,如果你的etcd一直重启的话就开启这个选项试试
改完了别忘记重启一下
containerd:
systemctl restart containerd
三、安装 kubeadm、kubelet、kubectl
1、简单介绍
kubeadm是自动引导整个集群的工具,本质上k8s就是一些容器服务相互配合完成管理集群的任务,如果你知道具体安装哪些容器那么可以不用这个。
kubalet是各个节点的总管,它上面都管,管理Pod、资源、日志、节点健康状态等等,它不是一个容器,是一个本地软件,所以必须得安装
kubectl是命令行工具,给我们敲命令与k8s交互用的,必须得安装
2、安装
首先得保证源都是新的:
sudo apt update
sudo apt upgrade -y
然后安装一些必要工具:
sudo apt install -y apt-transport-https ca-certificates curl gpg
下载并安装
k8s包仓库的公共签名密钥:
sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
sudo chmod 644 /etc/apt/keyrings/kubernetes-apt-keyring.gpg
添加
k8s的apt仓库,这一步有点小坑,k8s官网的教程不够及时。事情是这样的,k8s之前的官方软件仓库于2023 年 9 月 13 日被冻结了,我在2024年5月19日使用官网的教程给的地址发现怎么都安装不了,但是5月21日的教程更新了,是正常的。
***这个地址:
deb http://apt.kubernetes.io/ kubernetes-xenial main
已经不行了,别再用这个地址了,如果你用这个地址,
apt update会报错:
sudo apt-get update
Hit:1 http://us.archive.ubuntu.com/ubuntu jammy InRelease
Hit:2 http://us.archive.ubuntu.com/ubuntu jammy-updates InRelease
Hit:3 http://us.archive.ubuntu.com/ubuntu jammy-backports InRelease
Hit:4 http://security.ubuntu.com/ubuntu jammy-security InRelease
Ign:5 https://packages.cloud.google.com/apt kubernetes-xenial InRelease
Err:6 https://packages.cloud.google.com/apt kubernetes-xenial Release
404 Not Found [IP: 74.125.142.139 443]
Reading package lists... Done
E: The repository 'https://apt.kubernetes.io kubernetes-xenial Release' does not have a Release file.
N: Updating from such a repository can't be done securely, and is therefore disabled by default.
N: See apt-secure(8) manpage for repository creation and user configuration details.
回到正题,添加
apt仓库,使用其他版本的换v1.30就行:
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo chmod 644 /etc/apt/sources.list.d/kubernetes.list
更新
apt索引,并且安装,还要防止软件更新,三步:
sudo apt update
sudo apt install -y kubelet kubectl kubeadm
sudo apt-mark hold kubelet kubeadm kubectl
启动
kubelet,并且设置开机自启:
sudo systemctl enable --now kubelet
看看有没有安装成功:
kubeadm version

四、初始化主节点(只在主节点上做)
1、提前拉取镜像
如果你觉得慢或者出了什么未知的问题,可以提前将所需的镜像拉取下来,因为之前说过了,
k8s实质上是一堆容器服务组合,调度管理其他容器的,那么运行容器就得需要镜像。你可以在init前运行这个命令:
sudo kubeadm config images pull \
--kubernetes-version=v1.30.1 \
--cri-socket=unix:///run/containerd/containerd.sock
# --image-repository=registry.aliyuncs.com/google_containers \ # 觉得慢加上这个
这个命令会将所需的镜像提前拉取下来,然后再
init就会快很多
2、初始化节点
有了
kubeadm,就能一键初始化集群主节点了,运行:
sudo kubeadm init \
--apiserver-advertise-address=192.168.10.10 \
--control-plane-endpoint=k8s-master \
--kubernetes-version=v1.30.1 \
--service-cidr=10.50.0.0/16 \
--pod-network-cidr=10.60.0.0/16 \
--cri-socket=unix:///run/containerd/containerd.sock
# --image-repository=registry.aliyuncs.com/google_containers \ # 嫌慢的可以加上这句,用阿里云的镜像,我科学上网就不用了
apiserver-advertise-address填主节点的IP地址
control-plane-endpoint,还记得我们在/etc/hosts文件中配置的映射关系吗,填主节点的地址或者主机名
kubernetes-version版本不多说
service-cidr这是Service负载均衡的网络,就是你运行了一堆容器后有一个将它们统一对外暴露的地址,并且将对它们的请求统一收集并负载均衡的网络节点,得为它配置一个网段
pod-network-cidr每个Pod所在的网段
cri-socket照抄,指定容器化环境
如果
init失败,而且失败的原因是没有连接上api-server的话,使用命令查看kubelet的日志:
journalctl -u kubelet -xe
如果其中有类似这样的错误,但是无法拉取的镜像叫
pause:3.8的话:

*如果不是pause:3.8,那就是镜像拉取失败,可能是没有指定国内的源去国外下载失败了,需要指定国内的源并提前拉取镜像;
*还有可能是我们指定的源(比如阿里源)没有这个镜像,因为k8s-v1.30.1这个版本会默认使用3.8版本的沙箱,不知道什么原因拉取不下来这个镜像,所以只能拉取3.9下来改为3.8:
ctr --namespace k8s.io image pull registry.aliyuncs.com/google_containers/pause:3.9
ctr --namespace k8s.io image tag registry.aliyuncs.com/google_containers/pause:3.9 registry.k8s.io/pause:3.8
init失败后需要重置再重新init,执行:
sudo kubeadm reset # 重置 kubeadm ,执行这个后需要敲 y 回车
sudo rm -rf /etc/cni/net.d # 删除上次 init 生成的文件
sudo rm -rf /var/lib/etcd # 删除上次 init 生成的文件
再次
init,当然,你也可以选择配置文件的方式,和命令行的方式二选一:
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: v1.30.1
controlPlaneEndpoint: "k8s-master:6443"
networking:
podSubnet: "10.100.2.0/24"
serviceSubnet: "10.100.1.0/24"
apiServer:
extraArgs:
advertise-address: "192.168.2.203"
etcd:
local:
imageRepository: registry.aliyuncs.com/google_containers
imageRepository: registry.aliyuncs.com/google_containers
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
nodeRegistration:
criSocket: /run/containerd/containerd.sock
这个只需要
init时指定配置文件就行:
kubeadm init --config conf.yaml
init后成功的话会看到类似:
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join k8s-master:6443 --token is5atc.cc70psy934ptmb4j \
--discovery-token-ca-cert-hash sha256:cc01bdb1c2c0677ce9043af9f4996352320ae29b81c567a88c42f510f1817715 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-master:6443 --token is5atc.cc70psy934ptmb4j \
--discovery-token-ca-cert-hash sha256:cc01bdb1c2c0677ce9043af9f4996352320ae29b81c567a88c42f510f1817715
的东西,在这些命令之前还有几个命令,都执行一下,这是固定的,都这么执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
init完后给的命令:
kubeadm join k8s-master:6443 --token is5atc.cc70psy934ptmb4j \
--discovery-token-ca-cert-hash sha256:cc01bdb1c2c0677ce9043af9f4996352320ae29b81c567a88c42f510f1817715 \
--control-plane
一个有
--control-plane,一个没有,没有的那个是子节点运行的,一个子节点只要按照上面的步骤走到安装kubelet、kubectl、kubeadm后执行不带--control-plane的这部分命令就可以加入集群作为一个子节点,同样的,带--control-plane的是加入集群作为主节点,当真正的主节点挂后,这个加入的主节点就有可能成为主节点
3、注意的问题
***特别注意,apiserver-advertise-address、service-cidr、pod-network-cidr三者的IP网段不能重叠不能重叠不能重叠,不但三者之间不能重叠,三者每个也不能与互联网上的地址重叠,不然会出问题,后两个一般用10.x.x.x网段,这个网段是留给内网的
五、安装网络插件 Calico (重要)
我们走到这步后还没有完成,因为集群只是在主节点上初始化了,其他机器要想加入集群,还得使用网络插件将它们连接起来,所以得安装一个网络插件,有很多个,选
Calico就行。按照官网给的教程安装:
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
如果报错连接不上的话将文件手动下载下来再执行,没办法国外的网站:
wget https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
# 或者
curl -O https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
下载下来后一定不要用
kubectl apply -f来执行,会报错:
The CustomResourceDefinition "installations.operator.tigera.io" is invalid: metadata.annotations:
Too long: must have at most 262144 bytes
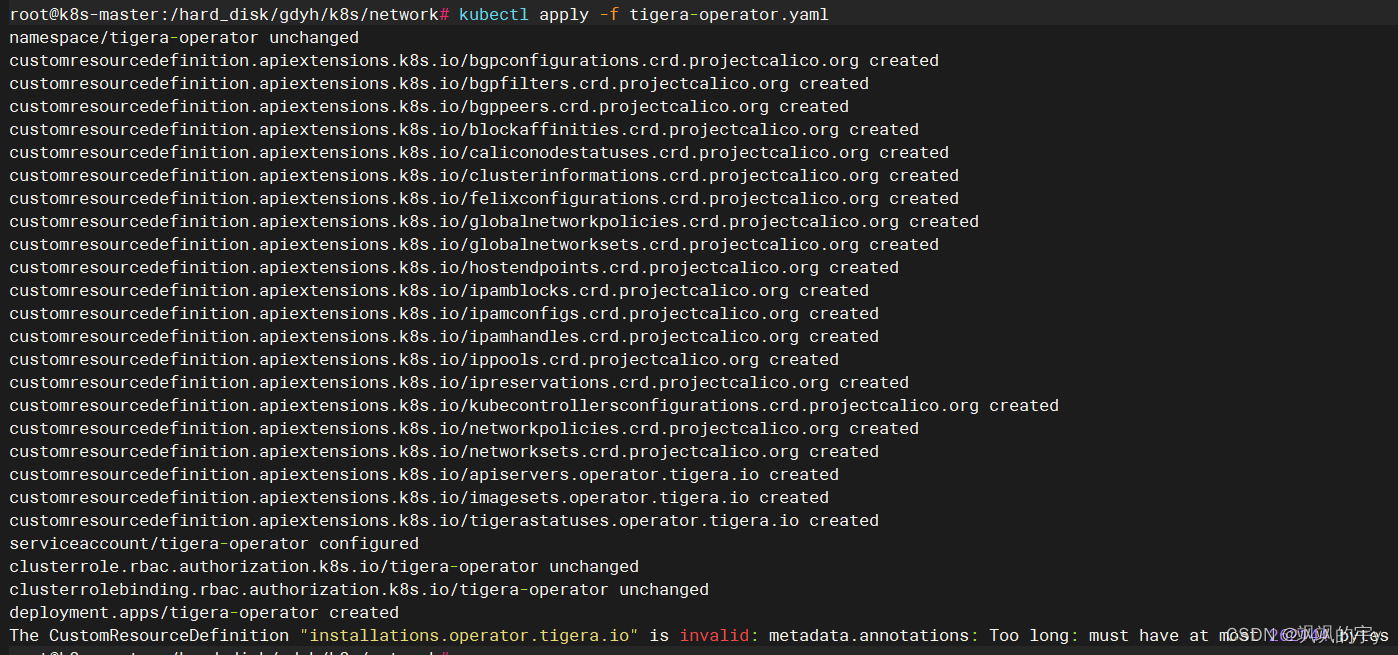
意思是
annotation长度过长了,原因是apply和create的处理不同,这点GitHub上也有人在吐槽,这是 GitHub上的吐槽地址
改配置文件中这个选项的长度就不改了,我们不用apply使用create:
kubectl create -f tigera-operator.yaml
没报错就没问题
第二步将配置文件下载下来,因为要改内容:
curl https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/custom-resources.yaml
修改这个文件中的
192.168.0.0为你刚才init时指定的--pod-network-cidr:
vi custom-resources.yaml
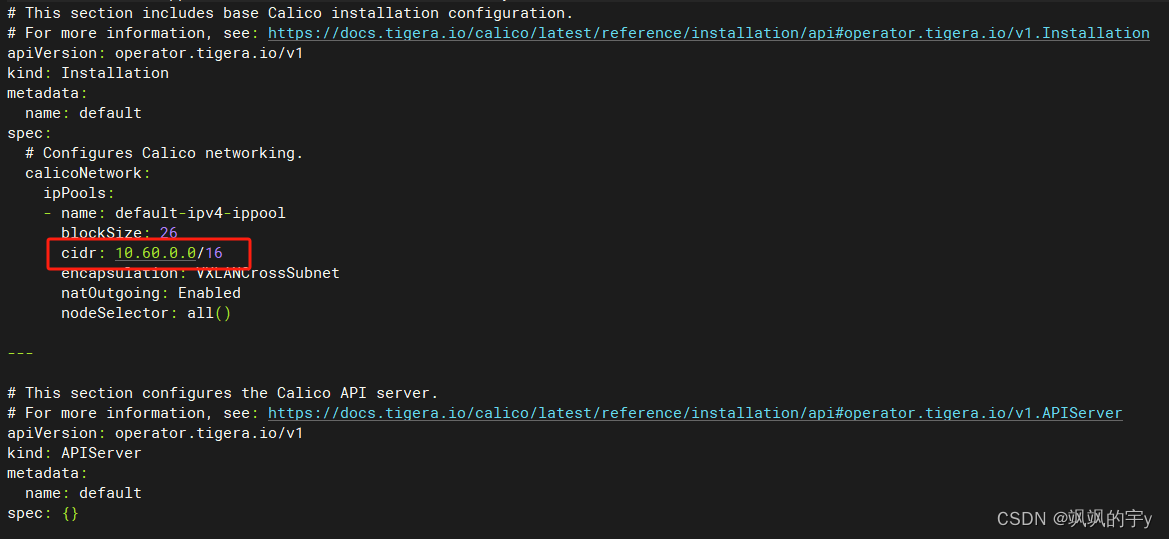
原本是
192.168.0.0改为你指定的IP地址
改好后执行命令,这个文件可以用
apply因为没有超限制(乐):
kubectl apply -f custom-resources.yaml
就会开始初始化网络插件,耐心等待,直到:
kubectl get pods -A
显示的所有容器都
Running就完成了
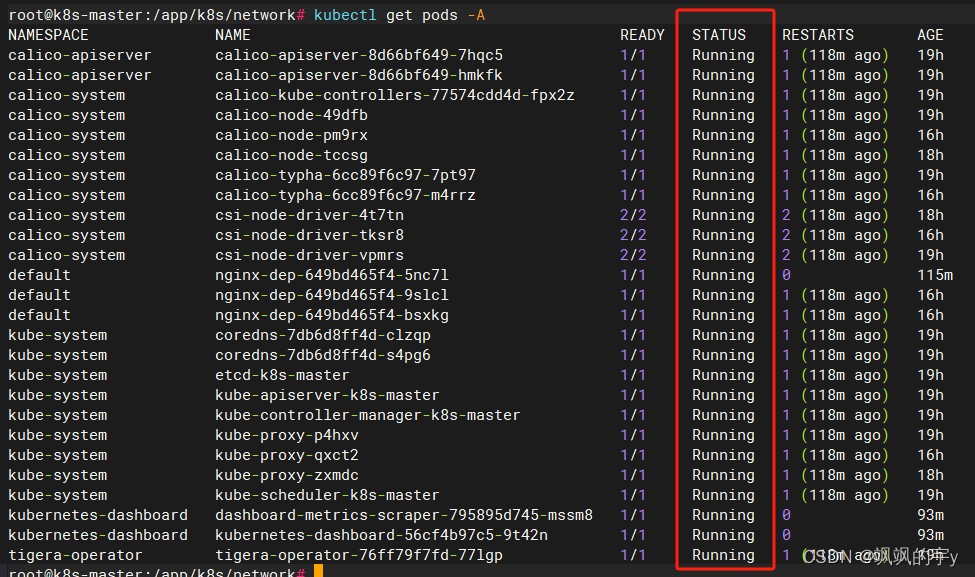
六、其他节点加入集群(非必须)
1、其他节点加入集群
首先得保证这个节点能与主节点网络连通,然后执行本文目录中
一、二和三的步骤,三个步骤一点都不要漏。
***需要注意的是,我们上面遇到的那个沙箱的问题,pause-3.9、pause-3.8在这个新节点上也要手动拉,在join之前。
还记得我们之前
init初始化主节点成功时得到的类似:
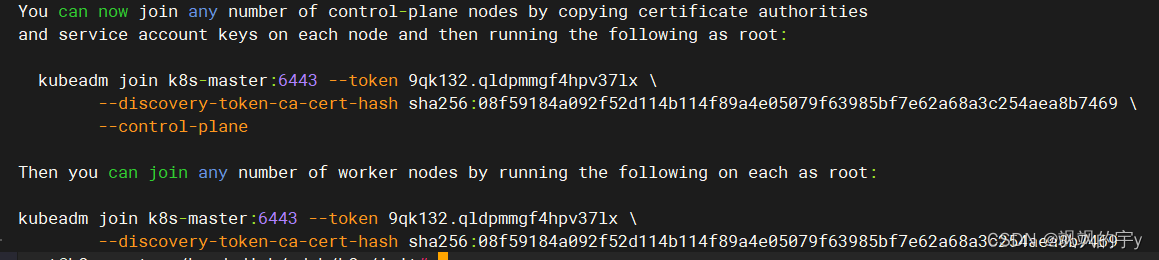
的字符串吗?复制下面那串:
kubeadm join k8s-master:6443 --token 9qk132.qldpmmgf4hpv37lx \
--discovery-token-ca-cert-hash \
sha256:08f59184a092f52d114b114f89a4e05079f63985bf7e62a68a3c254aea8b7469
到要加入集群的这个节点中去执行,但是前提是
一、二、三中的步骤你都完全执行完了并且没有报错。
这个命令中有一个
--token,它是会过期的,过期时间好像是24小时,如果token过期了,执行:
kubeadm token create
生成新的
token,替换命令中的--token就行。节点机上成功是这样的:
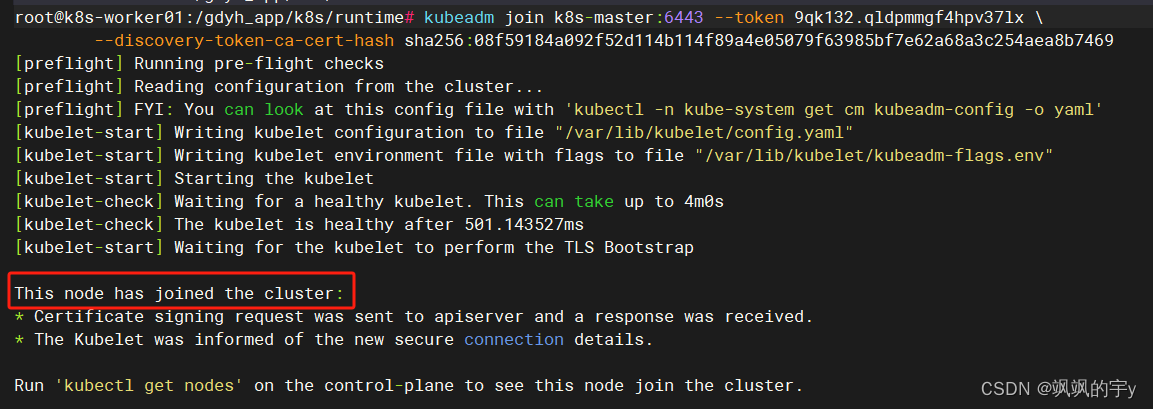
执行完后这里的成功其实还不算完全成功,要等它
init完成才算,你只需要在主节点上盯着所有的Pod都Running了后就可以继续下一步了。
2、本机成为工作节点 worker node(可选)
如果你只想在本机上运行所有的
Pod,那么只需要将主节点配置为工作节点,以便它可以调度并运行工作负载。在主节点上启用调度器,一般是移除主节点上的污点(taint),这些污点会阻止调度器将工作负载调度到主节点。执行命令查看都有哪些污点:
kubectl describe node <主节点的名字,就是我们设置的主机名hostname> | grep Taints
# 我的是:
kubectl describe node k8s-master | grep Taints
Taints: node-role.kubernetes.io/control-plane:NoSchedule
然后再删除这个污点:
kubectl taint nodes k8s-master node-role.kubernetes.io/control-plane-
现在主节点上也会被部署
Pod了。
3、如果节点初始化失败
如果这个节点初始化失败,需要重置集群中关于这个节点的东西:
kubectl drain <节点名称> --ignore-daemonsets --delete-emptydir-data # 驱逐节点上的所有 Pod
kubectl delete node <节点名称> # 从集群中删除节点
然后到节点上执行:
sudo kubeadm reset # 执行后按 y
sudo rm -rf /etc/cni/net.d # 移除 CNI 配置
# 清除 iptables 规则
sudo iptables -F
sudo iptables -t nat -F
sudo iptables -t mangle -F
sudo iptables -t raw -F
sudo iptables -X
sudo rm -rf ~/.kube # 删除 kubeconfig 文件(根据你的具体配置路径可能有所不同)
sudo reboot # 可选,可以重启一下节点
重置后再根据情况重新初始化
七、安装 Kubernetes Dashboard 前端控制面板(可选)
一直使用命令行手都敲累了,这时候你可以选择安装一个前端可视化页面来控制整个集群。
首先你得安装官方提供的前端页面,下载这个配置文件,你可以将链接中的
v2.7.0替换成你想要的版本:
curl -O https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
需要修改差不多二三十行处的
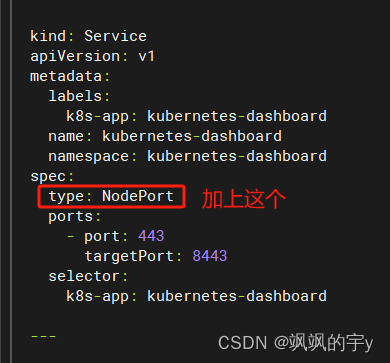
再执行:
kubectl apply -f recommended.yaml
然后就是等待它结束后创建一个配置,用于配置账户和获取token以登录页面,一定要等上面的结束再接着(结束标志是所有的
Pod都Running):
vi admin.yaml
添加以下内容:
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
然后再执行:
kubectl apply -f k8s-admin-user.yaml # 这句是创建账户
做到这步后网上的大多数帖子都是让执行:
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
他们都能生成Token,但是我的不行我的执行了这句代码后出来的是这样的:
root@k8s-master:/app/k8s/dashboard# kubectl -n kubernetes-dashboard describe secret \
$(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
Name: kubernetes-dashboard-certs
Namespace: kubernetes-dashboard
Labels: k8s-app=kubernetes-dashboard
Annotations: <none>
Type: Opaque
Data
====
Name: kubernetes-dashboard-csrf
Namespace: kubernetes-dashboard
Labels: k8s-app=kubernetes-dashboard
Annotations: <none>
Type: Opaque
Data
====
csrf: 256 bytes
Name: kubernetes-dashboard-key-holder
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
priv: 1675 bytes
pub: 459 bytes
并没有
Token,可能是由于 API 服务器还没有为我们创建的账户创建默认的Token,这时候需要自己手动生成密钥,新建一个yaml文件,加入:
apiVersion: v1
kind: Secret
metadata:
name: admin-user-token
namespace: kubernetes-dashboard
annotations:
kubernetes.io/service-account.name: admin-user # 如果上面的用户名你自定义了,记得替换这里
type: kubernetes.io/service-account-token
创建密钥:
kubectl apply -f admin-user-secret.yaml
检查一下生成没有:
kubectl -n kubernetes-dashboard get secret | grep admin-user

发现有,这时候我们再查看
Token:
kubectl -n kubernetes-dashboard describe secret token的名字,这里我们的是admin-user-token
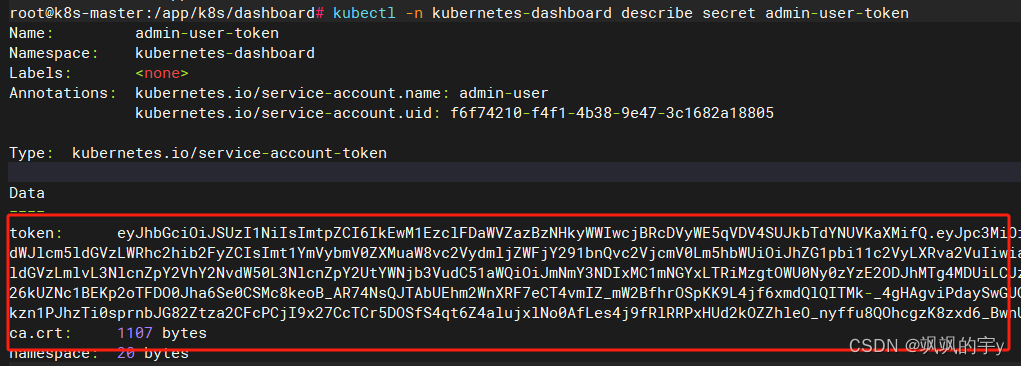
生成了,是不是有点像
RSA密钥?复制这个Token保存一下,以后要用就直接找文件了。
查看前端页面暴露出去的端口是多少:
kubectl get svc -n kubernetes-dashboard
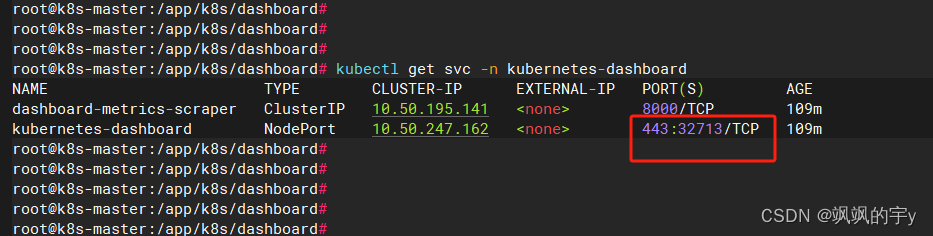
很明显,我的这个端口是
32713,网页访问任意一台节点的https://IP:端口,就能打开页面,记住,必须是https协议哦。
打开页面有警告不管,点击高级继续访问,你会看到:
还记得之前复制的那个像
RSA密钥的token吗?粘贴进去就能登录了。
如果上面的步骤还是存在问题,可以删除并重新创建
ServiceAccount和ClusterRoleBinding:
kubectl delete serviceaccount admin-user -n kubernetes-dashboard
kubectl delete clusterrolebinding admin-user
kubectl apply -f - <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
等待几分钟,然后再次检查生成的 Secret。
八、部署 ingress 接收外部流量转发到 service(可选)
1、简介
大白话就是:在此之前我们都是直接访问
service,让service负载均衡到Pod上,优点是直接,缺点是随着service的增多端口会越来越多,不好记。
于是我们在service之上再套一层,统一管理众多的service
流量流向是:
流量-->ingress-->service-->pod
2、部署 ingress-nginx
首先得明确
ingress其实也是一个service,它接收外部的流量转发到配置好的指定了的service,所以当我们部署ingress-nginx时会发现生成了一个关于ingress的service;
k8s的ingress实现有很多个,就不一一列举了,大家都用ingress-nginx;
执行语句,从
GitHub上拉取yaml开始配置(需要其他版本的改v1.10.1,但是得注意兼容情况):
curl -O https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.10.1 \
/deploy/static/provider/cloud/deploy.yaml
修改
kind: Service处的两个地方:
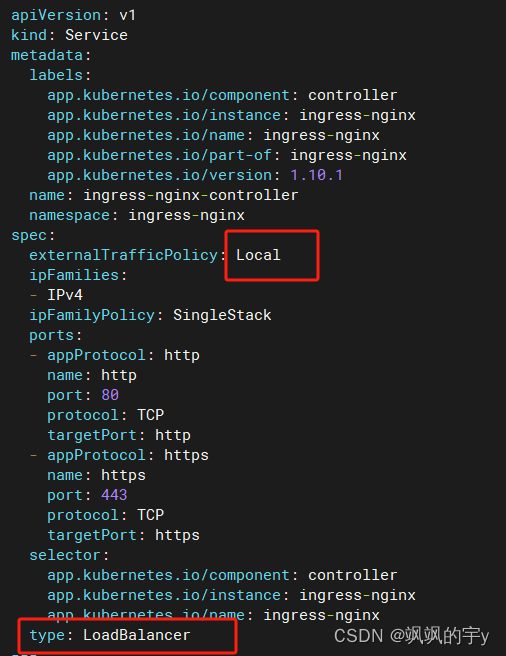
***上面的从Local改为Cluster,如果是Local,那么只有到达节点的流量才会被处理,而非自己节点的流量没有反应,意思就是说如果你的主节点是192.168.10.10,恰好ingress-nginx又没有部署在主节点上,那么你想通过192.168.10.10访问ingress就不行,改为Cluster的话,你在集群中任何一台机器上用IP:port访问ingress都可以,Cluster的好处是不管从哪都能访问,缺点是会增加集群内部的流量,因为你的请求流量会在集群之间转发,而且你的源IP地址也会变化,因为当你访问到一个没有部署ingress的节点上时,它会被路由到有ingress的节点上,所以内部流量才会增加,IP才会变
***下面的LoadBalancer改为NodePort,LoadBalancer是给云服务器或者自己弄了负载均衡的用的
应用配置文件:
kubectl apply -f deploy.yaml
查看
ingress暴露的端口:
kubectl get svc -A
找一个类似这样的:

我这里就是
32536,配置一个ingress资源,编辑一个yaml加入:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
namespace: default
spec:
rules:
- host: mynginx.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-nginx
port:
number: 80
这个配置文件的作用是创建一个
Ingress,并且将mynginx.com的流量都转发到my-nginx这个service的80端口中去,在win机上编辑hosts文件(C:\Windows\System32\drivers\etc),加入192.168.10.10 mynginx.com,浏览器访问http://mynginx.com:32536就能访问到我们部署的NginxPod了。
不想这么麻烦的也可以在集群外搭建一个
MetalLB实现负载均衡上面的步骤就都不用了,会给你生成一个能直接访问的集群外网地址,EXTERNAL-IP项就不为<none>或<pending>了。
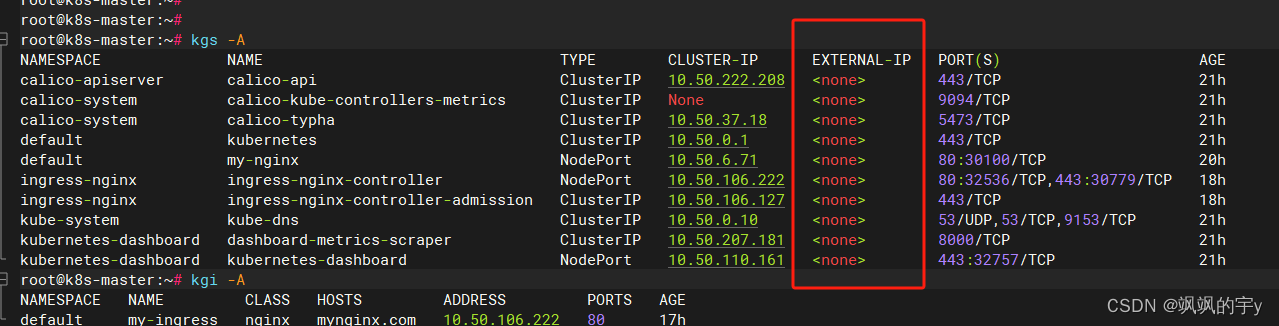
图里的命令是我取的别名,不是正规命令
九、结尾的话
全部内容大概就是这样,给个免责声明吧:以上仅代表我个人观点,不可能全对,也可能有错的地方,如果后续有错了我会回来改正。后续不定时更新这篇博客的内容。
参考文献
在Ubuntu22.04 LTS上搭建Kubernetes集群
k8s1.24+ dashboard不能自动生成token的问题
Kubernetes — Dashboard
CentOS7-安装kubernetes v1.30.0版本
k8s集群部署时etcd容器不停重启问题及处理