砍柴的娃和放羊的娃一起玩,晚上回来,他的羊吃饱了,你的柴呢?
Latch
结构
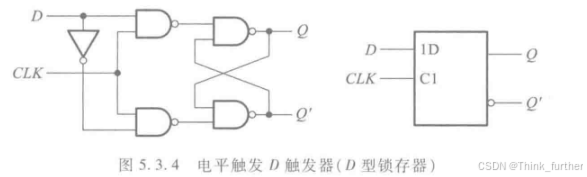
锁存器(Latch):电平触发,数据存储取决于信号的电平值。电平有效时,输出信号被锁存。
锁存器如下:
生成latch与避免latch
在组合逻辑中,如果Verilog的if语句中缺少else分支时,或者在case语句中没有覆盖所有可能的条件且没有default分支时,综合工具往往会生成锁存器。
比如:
input[3:0] data_in;
always @(data_in)
begin
case(data_in)
0: out1 = 1'b1;
1,3: out2 = 1'b1;
2,4,5,6,7: out3 = 1'b1;
default: out4 = 1'b1;
endcase
end
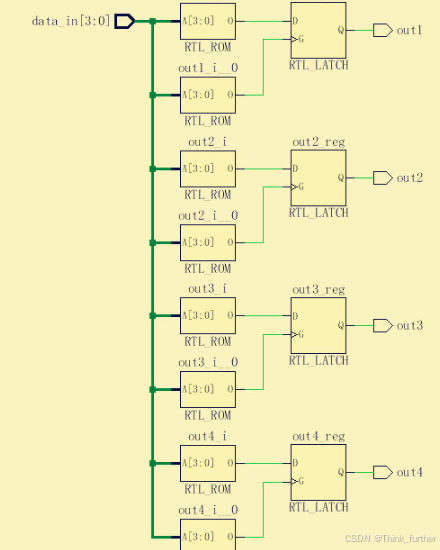
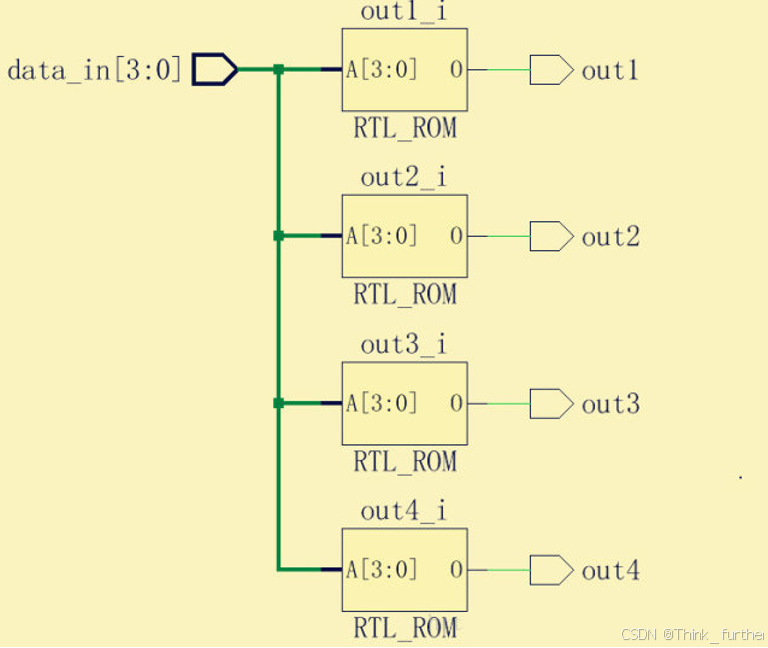
该代码生成了四个latch,
因为out1234方便只在自己值改变的情况下赋值了,在其他情况下没有赋值
在组合逻辑中,如果将输出变量显式地赋值给自己,综合工具往往也会生成锁存器。
module latch_assign (
input wire in,
input wire enable,
output reg out
);
always @(*) begin
if (enable) out = in;
else out = out; // 显式自赋值,生成锁存器
end
endmodule
always @(*) begin
if(condition)
aa = 1'b0;
else
aa = aa; //generate latch
end
确保所有条件分支完整,避免显式自赋值,可以规避在组合逻辑中综合出latch
always @(*) begin
if (enable) out = in;
else out = 0; // 提供默认值
end
信号特别多的情况下,在每个条件下都给每个信号赋值,这样就会导致代码很冗长,此时可以给每个信号一个初值。修改方法为:
input[3:0] data_in;
always @(data_in)
begin
out1 = 1'b0;
out2 = 1'b0;
out3 = 1'b0;
out4 = 1'b0;
case(data_in)
0: out1 = 1'b1;
1,3: begin
out2 = 1'b1;
end
2,4,5,6,7: begin
out3 = 1'b1;
end
default: beign
out4 = 1'b1;
end
endcase
end
更简单的方法是,使用sv,always_comb块会综合出组合逻辑,always_latch会综合出锁存器
Flip-flop
触发器(Flip-Flop):边沿触发,数据存储取决于信号的上升沿或下降沿。
DFF

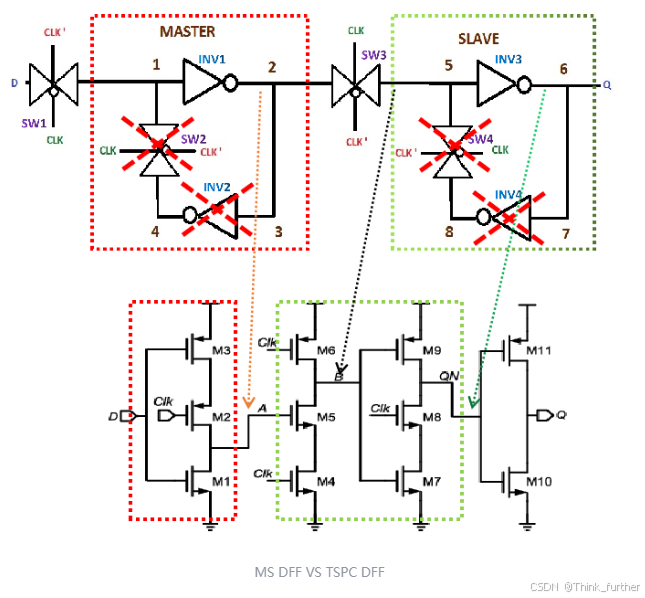
下面是一个典型的由一对主从latch构成的dff:
更省管子的TSPC DFF:
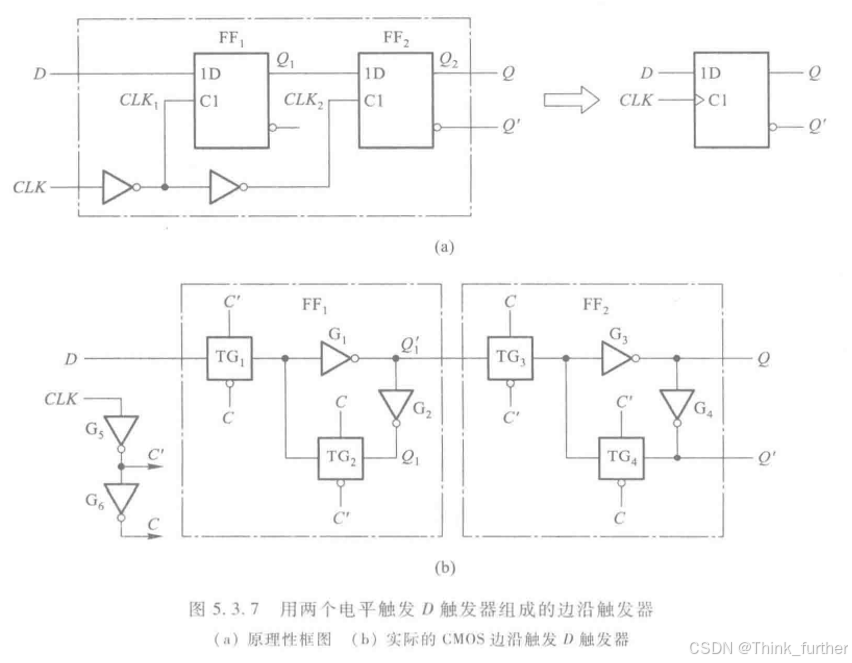
为什么可以这样省呢?首先,一个很正常思维的想法,SW2, INV2, SW4, INV4不直接在signal path上面的,先删了试试,那么就得到下图所示的结构
CK和CK非分别控制上下两个MOSFET, CK是1,CK非是0,这个clocked inverter可以导通。否则当CK是0,CK非是1,这个inverter关断。这个结构可以实现和主从latch一样的功能,这个结构叫做Clocked CMOS( C2MOS )。
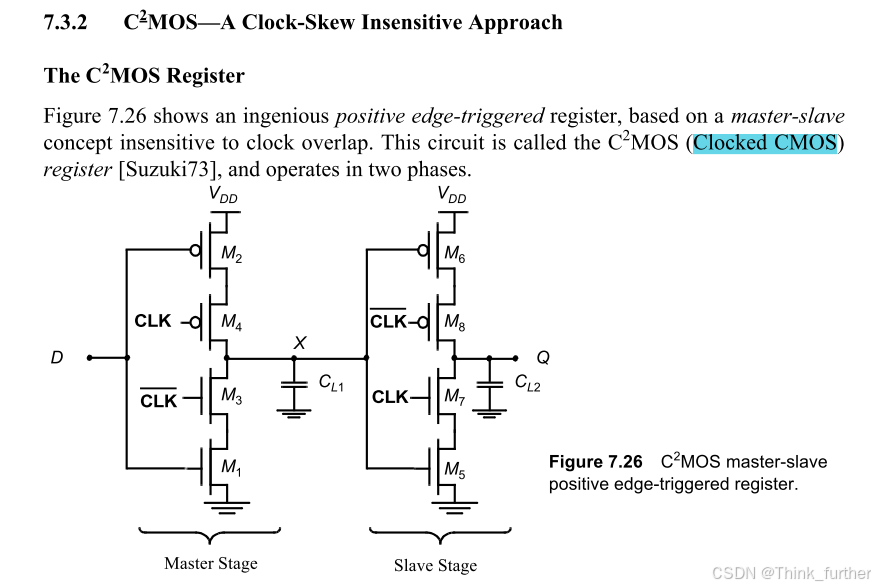
但这个结构会带来一个新的问题,见 数字集成电路——(设计透视)P316:
A C2MOS register with CLK-CLK clocking is insensitive to overlap, as long as the rise and
fall times of the clock edges are sufficiently small.
所以出现了这样的结构
只有一个CK来控制所有的模块。比如CK是1的时候,N block(假设就是一个NMOS),输入的1可以通过N block传到X(X被N block和由CK控制的NMOS拉到0), 紧接着的P block(比如就是一个PMOS)能容易的采样到这个0,然后Y……Y没法改变。因为Y此时被下面的NMOS拉到了0,此时的X并不能传到Y。
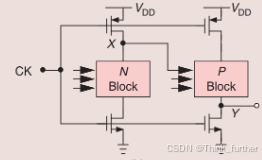
如果用这种被N block和P block轮流控制的结构来改造传统的DFF,就成了我们所熟知的TSPC DFF。
Verilog写法
带异步复位和同步置位的DFF:
parameter len=8;
module csdff (
input clk , // Clock
input set , // set
input rst_n , // Asynchronous reset active low
input [len-1:0]d , //input
output reg [len-1:0]q //output
);
always @(posedge clk , negedge rst_n , posedge set) begin
if(~rst_n) begin
q <= {len{1'b0}} ;
end
else if(set) begin
q <= {len{1'b1}} ;
end
else begin
q <= d ;
end
end
endmodule
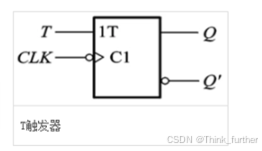
T触发器
T触发器是在数字电路中,凡在CP时钟脉冲控制下,根据输入信号T取值的不同,具有保持和翻转功能的触发器,即当T=0时能保持状态不变,当T=1时一定翻转的电路。

module tff (
input clk ,
input rst_n ,
input T ,
output reg Q
);
always @(posedge clk or negedge rst_n) begin
if(~rst_n) begin
Q <= 0;
end
else begin
Q <= (T&~Q)|(~T&Q) ;
end
end
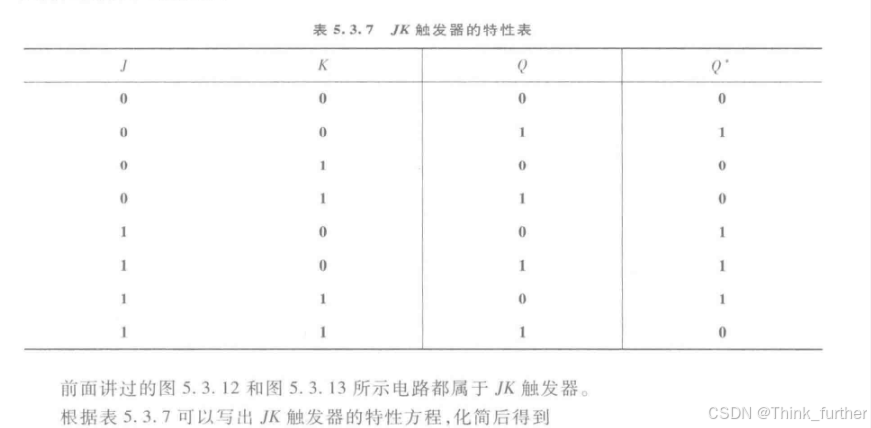
JK触发器
JK触发器是数字电路触发器中的一种基本电路单元。JK触发器具有置0、置1、保持和翻转功能。在各类集成触发器中,JK触发器的功能最为齐全。在实际应用中,它不仅有很强的通用性,而且能灵活地转换其他类型的触发器。由JK触发器可以构成D触发器和T触发器。

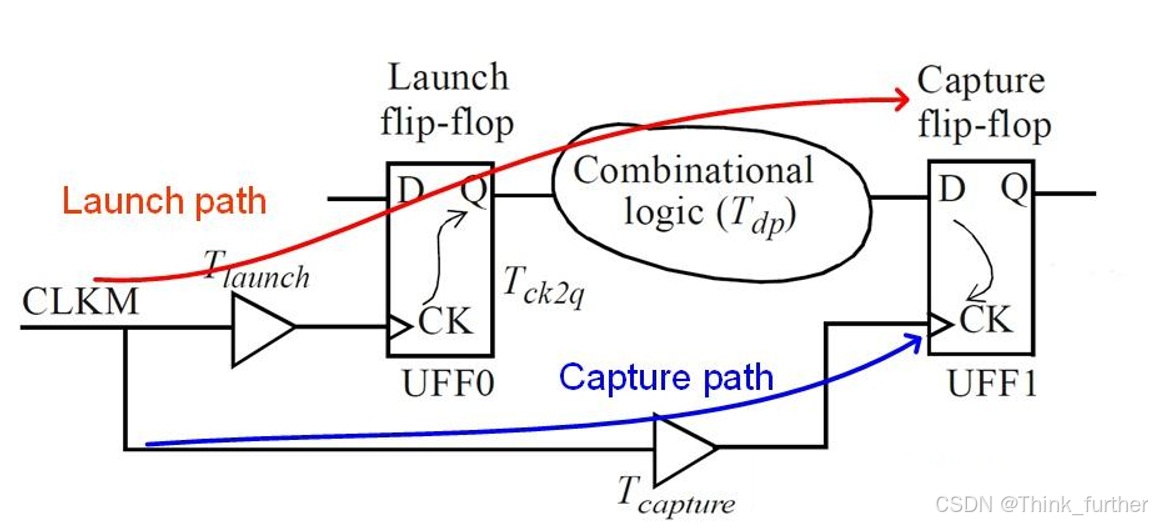
建立保持时间
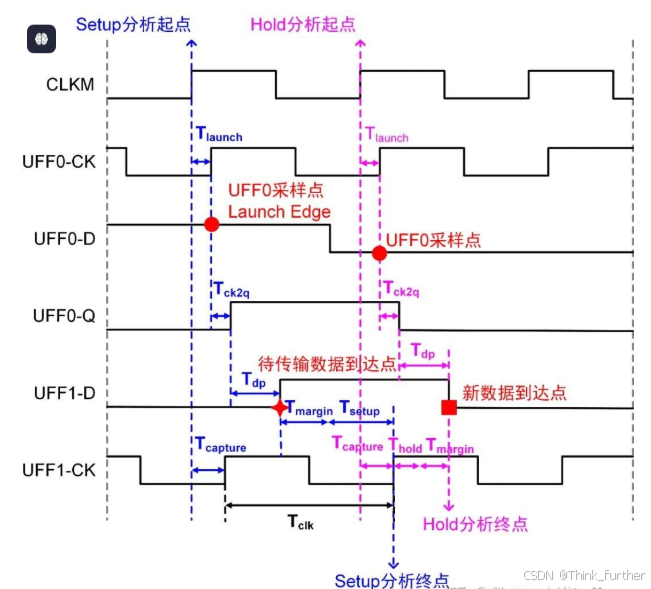
建立时间
set up time 就是时钟有效沿(本文以上升沿为例)到来前信号需要保持稳定的时间。
这句话就是个套话官话是吧,时钟上升沿是哪个的时钟上升沿?为什么需要保持稳定?我上课时第一次听也没听懂,下来网上查了查才明白,说人话就是:
时钟上升沿指的这一级的DFF的Capture edge。对这一级的DFF的Capture edge来说,上一级DFF通过datapath传到它D端的这一拍的数据不能来的太晚,否则这一级的DFF就会采样到还在变化的非稳态数据(x态,可能成0了也可能成1了),甚至是时钟上一拍的数据;
具体计算方法
数据到达UFF1/D所需时间Arrival time为:
Ta = T_launch + T_ck2q + T_dp
满足setup要求时所允许的最长时间Required time为:
Tr = T_capture + T_clk - T_setup
因此setup time要求可表示为:Tr - Ta = T_margin ,时间裕度,通常最低要求取决于jitter以及时钟不确定性。
我们在DC或者ICC里面看到的setup slack的计算方式就是:
Setup Slack = Data Required Time – Data Arrival Time=Tr - Ta
我们要求这个值至少是大于0的,才能满足setup的要求
其中:
T_launch:CLKM到UFF0时钟端CK的延时
T_ck2q:UFF0的CK->Q的传输时间
为什么是ck2q或者c2Q,而不是d2q?一个是因为这个触发器不一定是dff,可能是tff或者大家都喜欢的jk,二是因为d的值是早就变化了的,这个时间是 “clk变化稳定后” 到 “q变化稳定后” 的时间,和d没关系
T_dp:组合逻辑延时
T_margin:设计裕量
T_setup:UFF1的setup时间要求
T_capture:CLKM到UFF1时钟端CK的延时
T_clk: 时钟周期
Data Arrival Time : 数据在datapath上传输的时间
Data Required Time : 时钟在clock path上传输的时间
由此可见,setup检查发生在不同时钟边沿,与时钟频率有关。
保持时间
hold time是指在时钟有效沿(本文以上升沿为例)之后,数据输入端信号必须保持稳定的最短时间。
说人话:对这一级的DFF的Capture edge来说,上一级DFF通过datapath传到它D端的下一拍的数据不能来太早,不然这一拍的数据都还没采样完,就被下一拍的数据覆盖了。
计算方法
同setup计算一样,数据到达UFF1/D所需时间Arrival time没有变,仍然为:
Ta = T_launch + T_ck2q + T_dp
但是满足hold要求时所允许的最短时间Required time和setup的不一样,为:
Tr = T_capture + T_hold
这是从另一个方面提出的要求,即下一拍的数据不能来太早
因此hold time要求可表示为:Ta - Tr = T_margin >= 0。
我们在DC或者ICC里面看到的hold slack的计算方式就是:
Setup Slack = Data Arrival Time - Data Required Time = Ta - Tr
我们要求这个值至少是大于0的,才能满足hold 的要求
注意这个计算公式和setup是相反的。
总结一下,我们可以把一条流水线比作一群做题家坐一排在算题,第一个人算第一步,第二个人算第二步,第n个人算第n步,两个人中间摆一个草稿本(也就是寄存器或者说dff),这些个做题家就是两个寄存器之间的组合逻辑,也叫datapath;第一个草稿本就写的是老板让做题家们算的题,就叫输入,最后一个草稿本就写的是给甲方爸爸看的答案,就叫output,中间的草稿本就写做题家们算的中间结果,第二个草稿本就是第一步的结果,第三个草稿本就是第二步的结果。clk有效沿一到,做题家们一听啪的一声时钟敲拍了,就齐刷刷往左边的草稿本瞟一眼上一个做题家算出来的中间结果,然后脑袋里面开始算,算好了之后就把右边的草稿本擦了写上自己算的中间结果。
要是你身为做题家算的太慢了,或者写答案太慢了,右边的做题家听到时钟敲拍的声音来瞟你的答案了,你都还没写完你的答案,就叫setup不满足; 要是你身为做题家算太快了,右边的做题家听到时钟敲拍的声音来瞟你的答案的时候,你都开始擦答案写下一个答案了甚至都擦完了,就叫hold不满足;如果你离clk敲拍的地方太远了,声音传播有时间的,每次大家齐刷刷看左边的时候你都慢个几ns,这就叫time skew。
setup不满足怎么办呢,把你开除了换个算得快点的,这就叫逻辑优化;你不想被开除,和右边的做题家商量一下,让他每次听到时钟敲拍的声音的时候等个几纳秒,等你写完了答案再来瞟你右边的草稿本,这就叫time borrow;那他不lend给你时间呢?他等你几纳秒再看草稿本,少的是他的时间,待会他该看不完了。你找老板,老板说你这个步骤确实要复杂些,这样吧,你把它也分成两步,你说你不会分,或者确实这个工作就是分不了,就得一个人算,不能串行也不能并行。老板说好好好,我看你花的时间是别人的六倍,那你听到六次敲拍的声音后再写草稿本,你不写后面的人不算,这就叫反压;你一想这样不行啊,我一个人慢连累着后面的人全慢了,不行不行,
于是你还是找老板要来了5个人,你们六个一起算。第一次敲钟,做题家1看左边的草稿本然后算;第二次敲钟,做题家2看左边的草稿本然后算;第n次敲钟做题家n mod 6看左边的草稿本然后算。你们都是听到六次敲拍的声音后再写草稿本。这样虽然你们不能一起工作不能分工,还是6拍做一次,但是吞吐量上升了6倍,不会影响后面的做题家同学了。

那你离clk敲拍的地方太远了,导致每次大家齐刷刷看左边的时候你都慢个几ns这事儿怎么解决呢?让隔得近的等一下,保证你们“齐刷刷”,这就是CTS。其实也没必要真的齐刷刷,反正不耽搁看草稿本写草稿本的事就行,都还有人悄悄借时间呢。那如果确实影响到事儿了呢,而且如果流水钱太长离clk敲拍的地方近的人也等太久了,等的时间都敲几拍了。那这事儿就说明你们没坐对位置(布局布线太烂了),明儿个叫人事来给你们调整一下位置,坐成一个ring,每个人离敲拍的地方等距。那确实人太多了办公室太小了(面积限制),位置不好做呢。那干脆放多放两个敲拍的钟了,左边一个右边一个,一楼一个二楼一个。
如果多个时钟是同一个人敲的(同步时钟,派生时钟),好办,相差固定,要是远一点刚好差个整数倍时钟周期,调都不用调。
那不同的人敲的拍子不好同步啊,异步时钟源的相位差问题怎么解决?明天,继续介绍:
亚稳态_STA_CDC