研究问题
我们为无监督视觉表征学习提供了MoCo(动量对比)。从对比学习当作字典查询的角度上来看,我们构建了一个带有队列和移动平均编码的动态字典。在预训练过程中,可以构建一个很大且具有一致性的字典,这对无监督的对比学习非常有利。MoCo效果不错且能够很好地应用到下游任务中。在很多数据集中,7个检测、分类项目中MoCo都有很好的效果,甚至强于监督学习预训练的同样网络模型。在视觉领域,监督学习和无监督表征学习之间的差距越来越小。
一.Introduction
第一段:介绍无监督表征学习在NLP领域中取得很大的成功,但是在CV领域中远远落后于监督预训练方法。其中的原因来自它们各自的信号空间。语言任务有离散的信号空间可以构建文本数据分词化词典(tokenized dictionary,就是把某个词对应成某个特征),而无监督学习可以基于此。相比在视觉领域中,由于原始信号处于连续的高维空间中,所以更加关注字典构建。
第二段:最近的几项研究在使用与对比损失相关的方法进行无监督视觉表征学习时取得了很好的成果。尽管这些方法目的不同,但都是在构建动态字典。字典中的token从数据中采样,并由编码器网络表示。无监督学习训练编码器执行字典查询:编码的“查询”应该与其匹配的键相似,与其他的键不相似。这就叫做最小化对比损失。
第三段:构建字典。从这个角度来看,我们假设建立字典是可取的:(i)大,(ii)在训练过程中保持一致。直观地说,更大的字典可以更好地采样底层连续的高维视觉空间,而字典中的键应该由相同或类似的编码器表示,以便它们与查询的比较是一致的。然而,使用对比损耗的现有方法可能在这两个方面中的一个方面受到限制。
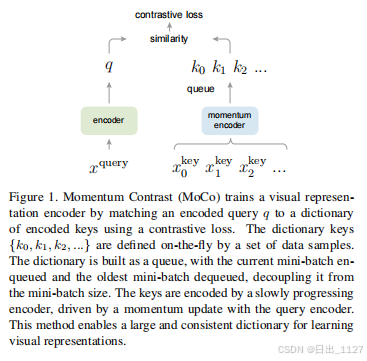
第四段:提出MoCo是无监督学习中使用对比损失来构建大且具有一致性的字典的一种方法,如何保证这个动态字典大且在训练过程中保持一致性。一方面,我们将字典当做数据样本的队列来维护, 当前小批量的编码表示加入队列,最早的小批量编码表示退出队列,队列将字典大小和小批量大小解耦,从而允许字典很大。另一方面,字典中的key要保持一致,也就是说key需要使用相同或相似的编码器产生得到,由于字典的键来自于前面的几个小批量,而之前的key都是用不同时刻的编码去抽取的特征,导致不能一致,所以提出了动量编码器,一种缓慢推进的键编码器,作为查询编码器的基于动量的移动平均来实现,保证字典中的K使用相似编码器来生成的,最大可能保持一致性。
第五段:MoCo是为对比学习构建动态字典的一种机制,可以被应用于各种代理任务(代理任务就是在自监督学习中,是人为制定的一些规则,作为训练的监督信号)中。在本文中,我们就遵循一个简单的实例识别任务:如果他们来自于同一个图像的编码视图,则查询匹配同一个键(代理任务)。
第六段:卖结果。无监督学习一个主要的目的就是预训练表征,而这些表征可以通过微调转移到下游任务中。一方面,MoCo在七个检测和分割相关的下游任务中效果都超过了同样网络模型的有监督学习;另外一方面,通过在image net数据集和十亿Instagram图像数据集上进行训练证明,MoCo可以在真实任务中且大规模数据集上训练效果较好。MoCo大大缩小了视觉领域中无监督表征学习和有监督表征学习之间的界限,甚至能够取代在实际应用中一直使用的ImageNet预训练模型。
二.Related Work
无监督学习和自监督学习方法一般都包含两个方面,代理任务和损失函数。代理任务一般都不是真正想要解决的问题,它仅仅是为了学习更好的数据特征。损失函数通常独立于代理任务进行研究。MoCo更侧重于损失函数。
损失函数:
定义损失函数最一般的方法就是去测量模型预测和固定目标之间的差距。比如通过L1或者L2损失来重建输入像素,或者通过交叉熵或基于边缘的损失来将输入分类为预定义的类别。
对比损失测量的是在同一表征空间中样本对的相似性。在对比损失公式中,样本可以在训练的过程中动态变化,可以根据网络计算的数据表征来定义,而不是将输入到固定目标的匹配。
对抗性损失测量概率分布的差异。在无监督的数据生成中取得广泛成就。对抗性生成网络和噪声对比,估计之间存在关系。
代理任务:
现在已经提出各种各样的代理任务,包括很在损坏的情况下恢复输入,比如去噪自编码器,上下文字编码器等等。
代理任务与对比学习:
各种代理任务都基于某种形式的对比损失函数。
三.Method
3.1. Contrastive Learning as Dictionary Look-up(把对比学习当成字典查询)
对比学习及其最近的发展,都可以被认为成为字典查询任务训练一个编码器。
考虑将编码查询q和一组编码的样本k作为字典的键。假设在字典中有一个k值与q匹配(称为K+)。当q和其正键(K+)相似,且和其他的键不相似(负键)时,对比损失的函数值较低。通过点击度量相似性,本文提出一种叫做InfoNCE的对比损失函数,公式为
。其中τ表示温度超参数。编码查询q和它的正键K+做点积后除以温度超参数作为分子,编码查询q和K个负键做点积后除以温度超参数的和作为分母,最后,取对数加负号。
InfoNCE的对比损失函数最初来自于softmax,但在监督学习中Soft max公式中的k代表分类的类别数,但是在无监督学习中此处代替的是所有负样本的类别数目,是一个巨大的数字,所以不能直接套用soft max公式。NCE就是noise contrastive estimation,就是将多分类问题转化成二分类问题,包含正样本和负样本,由于负降本的数目太多,所以这里采用估计,当字典越大的时候这个估计就越准确。InfoNCE是NCE的一个变体,因为负样本类别太多,把所有负样本看成一个类别也不合适,所以把它看成多分类问题比较合适。
InfoNC与交叉商损失函数的区别:交叉商损失函数中的k代表类别数目的多少,对比学习中的inf once中的k代表的是负样本的个数。
对比损失作为无监督目标函数,用来训练表示查询和建的编码器网络。通常查询表示为q = fq(xq) ,其中fq表示查询的编码器网络,xq表示查询样本。其实例化决定于具体的代理任务。输入的xq和xk可以是图像、Patches和由一组patches组成的文本。网络fq和fk可以是相同的,也可以部分共享的,或者不同的。
3.2. Momentum Contrast(动量对比)
从以上观点来看,对比学习就是一种在高维且连续的空间中(比如图像)建立离散字典的方法。这个离散字典是动态的,因为键值是随机取样的,并且键值的编码器在预训练的过程中也是不断发展的。如果要学好一个特征,字典必须有两个特点,一个是字典得足够大(一个大的字典包含很多负样本,容易学到有判别意义的特征),一个是字典的一致性(主要为了模型的训练,避免模型学到一些捷径)。基于此,提出了动量对比。
Dictionary as a queue:
我们方法的核心就是将字典维护成数据样本的队列。这允许我们从小批量的数据样本中重用编码的键值。引入队列后,字典的大小和小批量的大小解耦,字典的大小可以远远大于小批量,同时,字典的大小也可以灵活且独立的被设置为超参数。
字典中的样本是不断被更新的,当前的小批量进入队列,最久的小批量移除队列。(引入队列就是为了采用FIFO的规则)字典总代表所有数据的一个抽样子集,维护这个字典的额外计算也是可以管理的。此外,从字典中移出最早的小批量也是有益的,因为最早的小批量是由最早的键值编码器编码的,与现在更新了的编码器编码不一致。
Momentum update:
引入队列可以使字典变得很大,但是它也使得利用反向传播(梯度应该传播到队列中的所有样本)来更新键值的编码器变得更加困难。最简单的方法就是从询问编码器中复制到键值编码器,忽略这个梯度,但是这个方法在具体的实验中效果很差,我们认为原因是快速变化的编码器降低了键值表示的一致性,所以我们提出了动量更新。
动量更新编码器。其中m是0到1之间的动量参数。尽管队列中的键值是由不同的字典编码器所编码的,但是这些编码器之间的差异很小。m大比较合适,编码器缓慢的更新尽最大可能保证字典的一致性。
Relations to previous mechanisms:(与先前机制的关系)
Moco是使用对比损失的一种机制,我们将其和其他两种通用机制进行比较,它们在字典的大小和一致性上表现出不同的属性。

介绍图二中的a方式。图二中的a方式使用反向传播来端到端更新,它使用当前批量作为字典,所以字典中的键值能够被一致的编码。但是字典的大小就和小批量的大小相关,受到内存大小的限制,同时还受到了小批量优化的挑战。最近一些方法基于由局部位置驱动的代理任务,多个位置可以使字典变大,但是这种代理任务需要特殊的网络设计,可能会使向下游任务转移变得更复杂。(优:一致性好;缺:字典大小受限)
介绍图二中的b方式。是一种记忆库方式。内存记忆库由数据集中的所有样本组成,每一个小批量的字典都是从内存库中随机采样,没有反向传播,所以它可以支持很大的字典。当最后一次看样本时,内存库中样本的表示是更新的,因此采用的编码器在本质上也是不同的,所以没有具有一致性。后续也提出过动量更新,但是这里的动量更新并不是对编码器进行更新,而是对相同样本的表示进行动量更新。(优:字典大;缺:牺牲字典的一致性)
结果表示,MoCo方法具有更高的内存效率,可以在十亿规模的数据上进行训练。

3.3. Pretext task(代理任务)
对比学习可以使用于各种代理任务中,本文的核心的并不是去设计一个新的代理任务,而是我们采用了一个简单的代理任务,主要是遵循实例区分。
如果键值和查询来自于同一个图像,我们就将其认为是正对,其他的都认为是负对。我们在随机数据增强的情况下,对一张图像随机的取两个视图形成正对,分别由查询的编码器和字典的编码器进行编码,编码器可以是任何卷积神经网络。
Technical details:
我们采用resnet作为编码器,他的最后一个全连接层有固定维度的输出。输出向量由l2参数归一化。温度超参数τ为0.07,数据增强的操作等。
shuffling BN:
查询的编码器和键值的编码器以及标准的Resnet都有批处理归一化。但是在实验中发现BN会阻止模型学习良好的表示,很容易找到低损失的解决方案,原因可能在于样本之间的批量通信泄露了信息。
我们通过变换BN来解决这个问题,使用多个GPU进行训练,并且对于每个GPU的样本独立执行BN。对于键值编码器,在当前小批量中打乱采样顺序将其分配给gpu。对于查询编码器,小批量的适量顺序没有改变。这就确保了用于计算查询和证件的批统计信息来自于两个不同的子集,有效的解决了作弊问题。
五.Discussion and Conclusion
本文证明了MoCo在视觉任务和数据集上无监督学习的不错的效果。一方面,MoCo的改进很明显,但相对较小,这表明更大规模的数据集没有得到充分的利用,希望有一个更好的代理任务来改善这个问题。另一方面,MoCo除了可以应用于简单的实例识别任务以外,还可以探索将MoCo和Masked auto-encoding结合来使用。(BERT )
创新点
1.采用队列来保证可以构建一个巨大的字典
2.采用动量移动平均编码来尽可能保证字典中的key由相似的编码器来生成,尽最大可能保证一致性。
3.写论文时,最好每个部分之间都要有承上启下的段落。想要引出一个东西,最好将出为什么需要他。
知识点补充
1.计算机领域中的对比学习:对比学习就是对比着去学习,是一种自监督的学习方法(在视觉中,使用pretext task一些代理任务,人为地定义一些规则,从而提供监督信号来训练模型)。通过训练模型,算法学习区分相似和不相似的数据点,并最大化相似数据点之间的相似度,最小化不相似数据点之间的相似度。在对比学习中,通常做法是预测两个数据点是否来自于同一个类别。
2.动量:可以理解为移动加权平均。Yt = m * Y(t-1) + (1-m) * Xt
其中m就是动量这个超参数,介于0到1之间。使得当前时刻的输出不只依赖于当前时刻的输入,还需要原来时刻的输出。
3.对比损失,是一种常用于图像分类任务的损失函数。旨在使近似样本的输出特征间距离尽可能小,不相似样本的输出特征间距离尽可能大。
4.tokenized dictionary,文本数据分词化词典,就是把某个词对应某个特征。
5.Instagram图像:场景非常丰富,而且能够展现出真实世界数据中的一些特征。比如数据分类不均衡导致的长尾问题、一张图片中含有多个物体的问题等。