Comment: Accepted to ICCV-2023. Camera-Ready version. Project page: https://muzairkhattak.github.io/PromptSRC/
自我调节的提示:没有遗忘的基础模型适应
摘要
提示学习已经成为微调基础模型(CLIP)适应下游任务的有效替代方法。传统的方法使用任务特定的目标,即交叉熵损失进行训练,提示往往会过拟合到下游数据分布上,并且很难从冻结的CLIP中捕捉到任务无关的通用特征。这就导致了模型原本泛化能力的损失。
为了解决这个问题,本文引入了一个自正则化的提示框架,称为Prompt SRC(带有自我调节约束的提示)。
PromptSRC 通过三管齐下的方法对任务特定和任务无关的表征进行优化:(a)通过与冻结模型的相互一致性最大化来调节提示表征(b)在训练阶段对提示进行自我集合,从而编码其互补的优势增强模型的泛化能力(c)通过文本多样性的调节来缓解样本多样性和视觉分支的不平衡。
本文是第一个使用提示学习的正则化框架,通过共同关注预训练模型的特征、提示的训练轨迹和文本多样性来避免过拟合。Prompt SRC引导提示学习一个表征空间,在不影响CLIP泛化性的前提下,最大化下游任务的性能。本文在4个基准测试集上进行了广泛的实验,与现有方法相比,PromptSRC表现良好。
Introduction
视觉-语言模型,如CLIP和ALIGN,在下游任务中表现出显著的泛化能力。这些VL模型是在大规模网络数据上训练,具有对比损失,这使得它们可以在共享嵌入空间中对齐图像和文本对,从而编码开放词汇概念。所得到的模型适用于下游任务,如开放词汇图像识别,目标检测和图像分割。
最近的研究表明,提示学习已经成为微调大规模模型的一种更有效的替代方法。提示学习在大规模模型(CLIP)引入一些可学习的提示向量,以适应下游任务,同时保持预训练的模型权重固定。然而,由于提示是针对任务特定的目标进行优化的,例如ImageNet分类的交叉熵损失,随着训练的进行,提示模型会过度拟合任务特定的数据分布。这会导致预训练模型失去冻结CLIP模型对新任务原有的泛化能力。因此,对任务特定和任务无关表征进行建模的提示仍然是调整基础模型的主要挑战。
本文旨在自我调节提示,来解决提示过拟合的问题。为此,本文提出一个自正则化框架,指导提示使用三管齐下的方法对任务特定和任务无关的表征进行联合优化。
a )通过相互一致最大化进行调节:已知可泛化的zero-shot知识保存在冻结的预训练VL模型特征中,但它们缺乏任务特定的知识。相比之下,提示对给定任务的适应更好,但对新任务的泛化能力降低。因此,本文提出在适应下游任务的同时,通过最大化提示和冻结的VL模型特征之间的一致性来调节学习到的提示。
b )自组合的调节作用:在早期阶段(前几个epoch),提示对上下文信息的捕获并不成熟。随着训练的进行,提示变得具有任务特定性。因此,本文在训练过程中部署了一个加权提示聚合技术,利用它们在训练阶段的自集成来调节它们。权重从高斯分布中采样,适当地聚合了不同训练阶段提示学习的有用知识。
c )文本多样性的调节:与视觉分支中每个类别有多个图像样本不同,每个类只有单个文本标签可用。因此,由于文本分支缺乏多样性,对多模态特征施加相互一致的约束会导致次优的性能。本文通过每个类的不同文本标签模板来调节提示,从而克服差异。
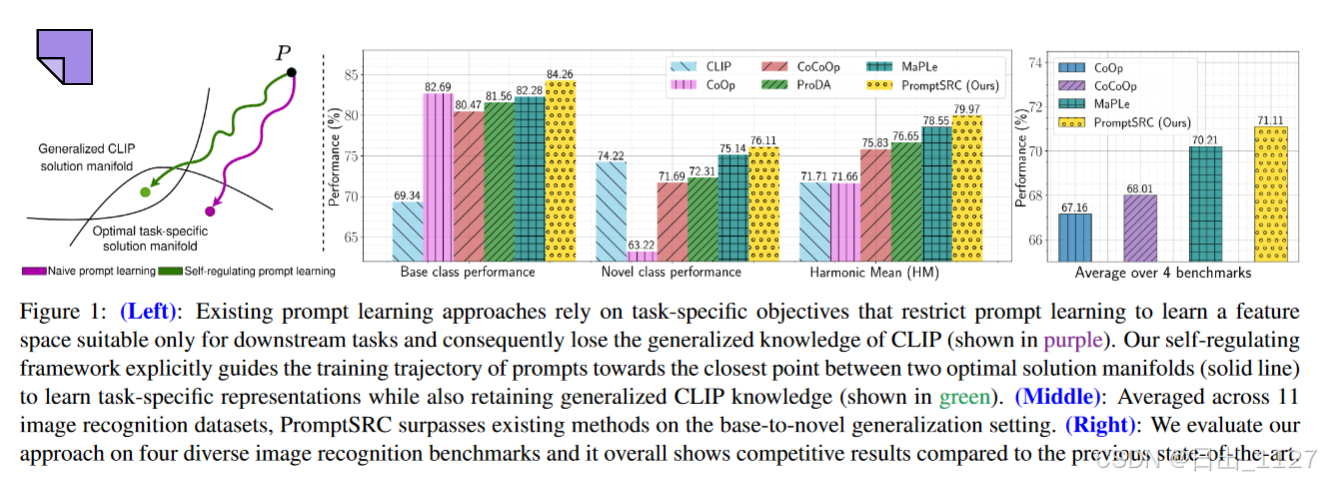
解释图1:左:本文方法引导提示学习一个表示空间,在不损害预训练的CLIP泛化的情况下,最大化其在下游任务上的性能。本文在四个具有代表性的任务上证明了PromptSRC的有效性。中:在11个数据集上的从基类到新类的泛化基准上,本文方法在调和均值上比最新的MaPLe获得了+ 1.42 %的平均增益,在CLIP上获得了+ 8.26 %的平均增益。右:此外,PromptSRC在跨数据集迁移、领域泛化和小样本图像识别方面取得了具有竞争力的结果。

本文贡献
(1)本文通过自正则化来解决调整基础模型时提示过拟合问题。本文框架通过最大化提示和冻结的VL模型特征之间的相互一致性,指导提示联合获取任务特定知识和任务无关的广义知识。
(2)本文提出一种用于提示的加权自集成策略,该策略能够捕获在训练过程中不同时期学习到的互补特征,并增强它们的泛化性能。
(3)为了克服文本分支和视觉分支之间显著的多样性不匹配,本文提出了文本侧多样性,通过多个文本增强来补充有限的文本标签,并对提示进行正则化,以学习更广义的上下文。
Proposed Method
提示学习旨在调整VL基础模型的一般知识,而不需要完全微调。由于提示是唯一可学习的向量,该策略旨在保留CLIP预训练的泛化特征表示,同时通过提示将其适应下游任务特定的数据。虽然有效,但它们在有监督的下游任务(图2)上容易过拟合,并且它们对新类的泛化能力比原始的零样本预训练CLIP有所降低。
本文旨在解决提示的过拟合行为。与主要从模型结构角度来提高泛化性的先验提示方法不同,本文从正则化角度来展开工作。预训练的CLIP具有稳健的泛化特性,表现出很强的零样本性能。然而,在训练提示时,如果单纯地使用有监督的任务特定损失函数,则很难保留从冻结的CLIP模型中获得的通用知识。为此,本文提出一个自正则化框架来指导提示的训练轨迹,以最大限度地使其与冻结CLIP中存储的预训练知识进行交互。
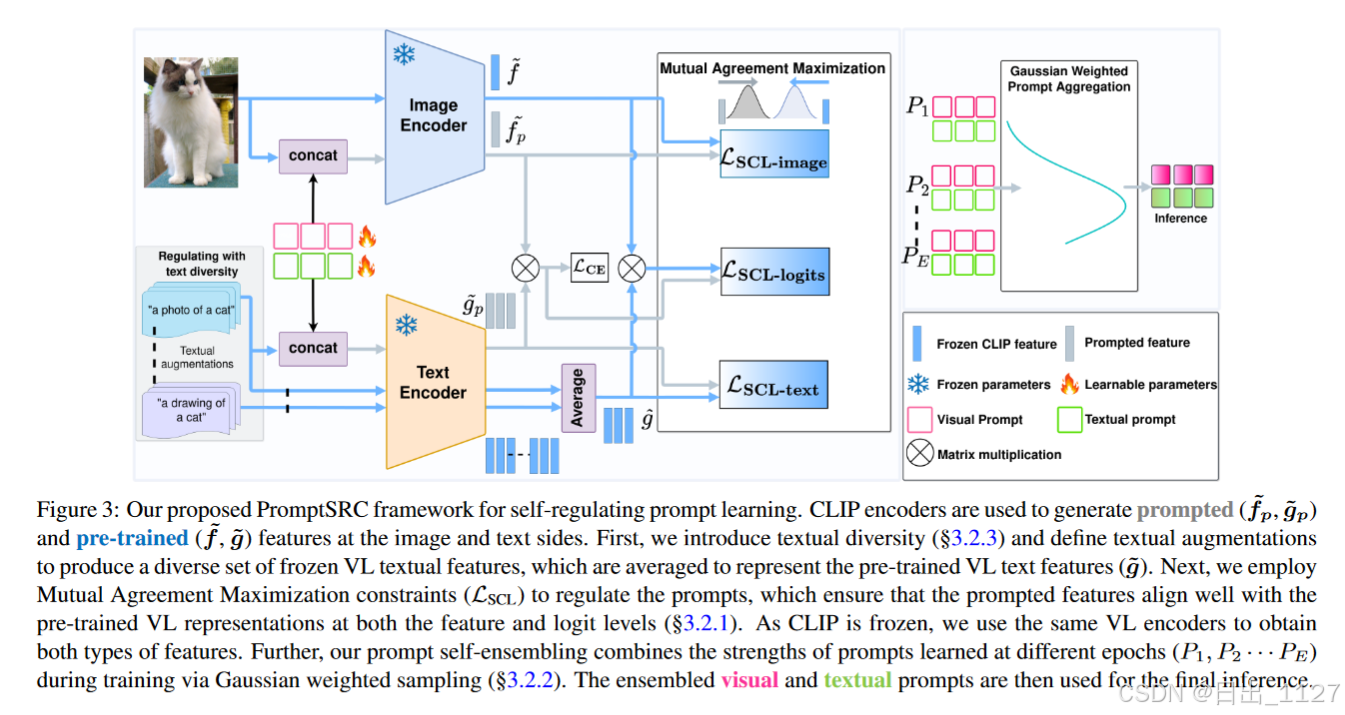
图3展示了本文优化提示的整体方法,具体如下:
a )通过相互一致性最大化的正则化:本文在CLIP嵌入空间中对提示特征和预训练的CLIP特征之间施加一致性约束。
b )通过提示自集成的正则化:为了进一步减少过拟合,本文在不同训练阶段学习的提示向量的高斯加权平均。这种集成层次的正则化聚合了不同时期学习到的提示的信息,以提高泛化能力。
c )通过文本多样性进行正则化:与每个类都有多个图像不同,微调过程中的文本标签受限于类别的数量。本文为给定的类定义多个文本标签模板来合并文本增强。文本标签的集成在优化过程中对提示进行了正则化处理,以获得更好的泛化性。
Preliminaries
CLIP由两个并行编码器组成,文本编码器用于将文本输入映射为文本特征向量,图像编码器用于将视觉输入映射为图像特征向量。
Image Encoder
在这项工作中,选择ViT作为图像编码器。
(1)给定输入图像I∈RH×W ×3,包含K个transformer层的图像编码器将图像打成M个固定大小的patch.
(2)得到投影patch的嵌入向量E0∈RM×dv。
(3)嵌入向量和一个可学习的类标记ck一起被输入到图像编码器Vk+1的第(k+1)层,并依次通过以下变换:
(4)为了获得最后的图像特征向量,将最后一个transformer层的类标记ck通过ImageProj投影到共同给特征空间中:
Text Encoder
(1)文本编码器包含K个transformer层,将输入的单词打成若干token,然后映射为单词嵌入W0。然后将单词嵌入向量送到文本编码器的Lk+1层:
最终的文本表示z是通过TextProj与最后一个transformer层输出的token投影到潜在的嵌入空间:
Zero Shot Prediction
对于zero-shot预测,在CLIP的语言分支中引入提示,通过加入与下游任务相关联的每个类名来构成文本输入。然后选择余弦相似度分数最高的类别作为图像的预测标签:
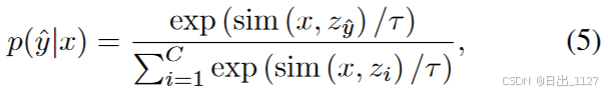
Self-Regularization for Prompt Learning
Lce目标使用真实标签来优化下游任务的提示,因此,提示可以调整并学习任务特定的知识。训练过程中,提示通过transformer块中的自注意力层与预训练并且冻结的CLIP token进行交互。提示令牌与预训练的CLIP权重θCLIP之间的交互提供了隐式正则化,并鼓励在提示中保留与任务无关的通用知识。然而,随着训练伦次的增加,提示对下游任务中产生过拟合,并且会偏离CLIP广义空间。因此,尽管CLIP中图像编码器θf和文本编码器θg的权重都冻结但新任务的性能仍然下降。随着提示经过进一步的训练,隐式泛化约束相对于Lce目标变得更弱。
解决这个问题最简单的方法就是减少训练epoch,从而在基类和新类之间取得平衡。然而,训练较少的迭代次数从而防止失去泛化性需要牺牲较低的监督任务的性能。本文提出一种提示学习方法,在不牺牲新任务和新类别性能的前提下,最大化监督任务的性能。
Mutual agreement maximization(创新点1)
如上所述,Lce损失导致对下游任务数据的过拟合,并且很难利用来自冻结CLIP的通用知识。本文提出通过施加一个约束引导训练轨迹,从而最大化提高冻结的CLIP特征和提示之间的相互一致性。本文直接将提示与CLIP特征保持一致来实现。由于这种条件化不需要任何第二个模型,因此称这种正则化损失为自我一致性损失(SCL,self-consistency loss)。
(1)给定输入样本及其对应的文本标签,在冻结的CLIP潜在空间中,利用可学习提示和预训练的视觉特征获得视觉特征fp和f,类似,得到文本特征gp和g。
(2)然后,本文对提示的文本特征和视觉特征添加约束,从而确保它们与CLIP预训练特征保持一致性:
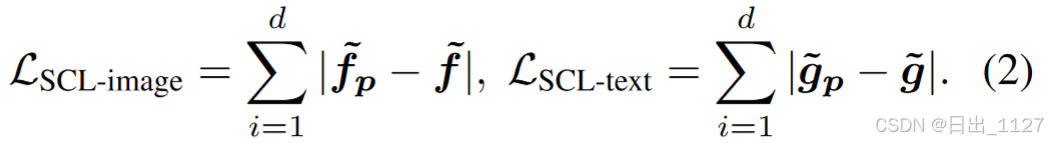
本文使用L1损失来增强特征级别的一致性。并且本文的自我一致性约束也可以兼容其他匹配性损失的变体,例如MSE损失、余弦相似度。
(3)为了进一步实现正则化约束并且最大化通用特征与提示特征之间的对齐,本文添加logits级别的自我一致性正则化,并通过最小化KL散度,将提示的logits分布限制在预训练CLIP的logits分布上:
(4)总的来说,自我一致性训练目标引导提示从预训练的CLIP特征中获得互补性知识,从而提供泛化性更强的提示:
因此,总训练目标为:
Regularization with prompt self-ensembling(创新点2)
本文自正则化框架中第二个组件使用提示自集成来强制正则化。在权重空间中进行模型集成已被证明可以同时提高模型的性能和泛化性。然而,它在提示学习的背景下并没有得到积极的研究,其中提示只是具有冻结模型参数的可学习参数。
为了有效利用之前训练迭代中的提示知识,本文提出一种可泛化的提示聚合方法。对于E个epoch的训练计划,每个epoch中提示为,聚合提示(AP)的计算公式为(wi代表每个epoch t分配给提示的权重):
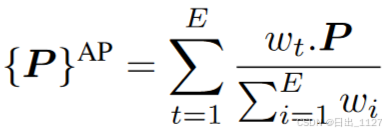
在靠前的epoch中,由于提示的随机初始化,提示捕捉上下文信息并不成熟。因此在聚合期间,需要为他们分配更小的权重,因为它们充当输入数据携带的噪声。另一方面,最后几个epoch 中学到的提示是特征任务的,有利于下游任务。本文提出高斯加权提示聚合(GPA),其中在最初epoches中赋予较小的权重,中间epoches权重较高,最后epoches权重较小,从而产生对下游任务泛化性好的提示。其中GPA从高斯分布wi ∼ N (μ, σ2)中采样来提供最佳权重值wi,其中μ和σ2都是超参数并且满足:
高斯分布是在epoch上定义,其平均值由epoch编号决定。本文将权重表述为移动平均线,以避免保存多个提示副本,方法为在每个epoch i保留一个额外的副本,该副本通过聚合更新:

Regulating prompts with textual diversity(创新点3)
通过Lscl损失,视觉提示特征从预训练CLIP视觉特征中灌输多样化的通用上下文,因为每个类别都有多个图像样本。这就在图像分支中提供了增强来源,并促进了额外的正则化。然而,与视觉分支中每个类别多种图像相反,微调的文本分支是有限的,提示文本特征根据预训练CLIP文本特征学习,每个类别只有一个特征表示。视觉分支和文本分支多样性的不匹配导致提示文本特征的次优效果。
为了解决多样性不匹配的问题,本文在文本编码器中加入文本多样性。具体来说,本文使用一组文本提示模板,用于为每个类别生成N个增强的文本特征。
预训练的CLIP文本特征是作为多个提示模板的集合获得的:
由于预训练CLIP的文本特征目前由每个标签的多个增强集合表示,因此提示的文本特征从冻结的CLIP中学习到了更多不同的广义上下文。本文提出的文本多样性与CLIP作者探索的标准提示集成技术不同,CLIP在推理期间使用文本提示的组合进行分类,而本文在训练过程中,利用自正则化强制集成特征与提示特征相互一致,并在推理时使用提示特征。
Conclusion
提示学习已成为适应 CLIP 等基础 VL 模型的有效范式。然而,大多数现有方法学习的提示本质上倾向于过拟合于任务特定的目标,从而损害 CLIP 固有的泛化能力。本文工作提出了一个自我调节的提示学习框架,解决了提示过拟合问题,以实现更好的泛化。本文表明,通过自我一致性约束鼓励提示与冻结模型的相互一致,并辅以结合文本多样性,从而指导提示的训练轨迹至关重要。本文还提出一种提示的自集成策略,在训练过程中通过高斯加权方法适当地聚合它们。对多个基准的广泛评估表明,本文自我调节方法对提示学习的好处。