一.认识HTML
1.什么是HTML (HyperText Markup Language)
- HTML是超文本标记语言的缩写,它包含一系列的标签, “超文本”是一种组织信息的方式,利用HTML标记,告诉浏览器被标记的内容如何显示到浏览器页面上。
例如:< p>我热爱我的祖国< /p>,被标记的内容是“我热爱我的祖国”,而< p></ p>则是HTML的标记符;当浏览器读取到这个标记时,就可以将这段文本内容显示到浏览器页面上。
- 使用HTML语言可以建立自己的WEB站点文件,HTML文件运行在浏览器上,由浏览器来解析,并将标记的内容显示出来。
注意:HTML语言为解释型语言,即写出来代码直接就能运行,而例如C语言、JAVA则为编译型语言,需要编译成二进制文件,计算机才能解释执行。
2.HTML文档结构
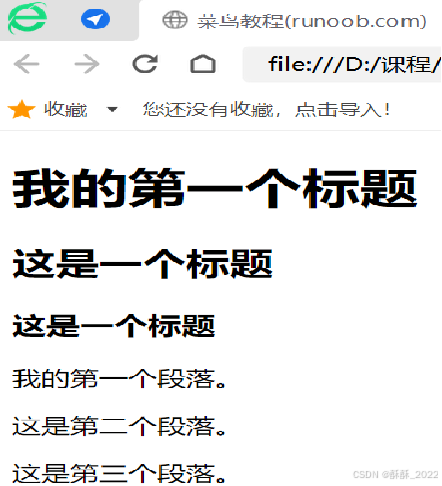
以下是一个简单的HTML代码段,浏览器执行效果如图所示:
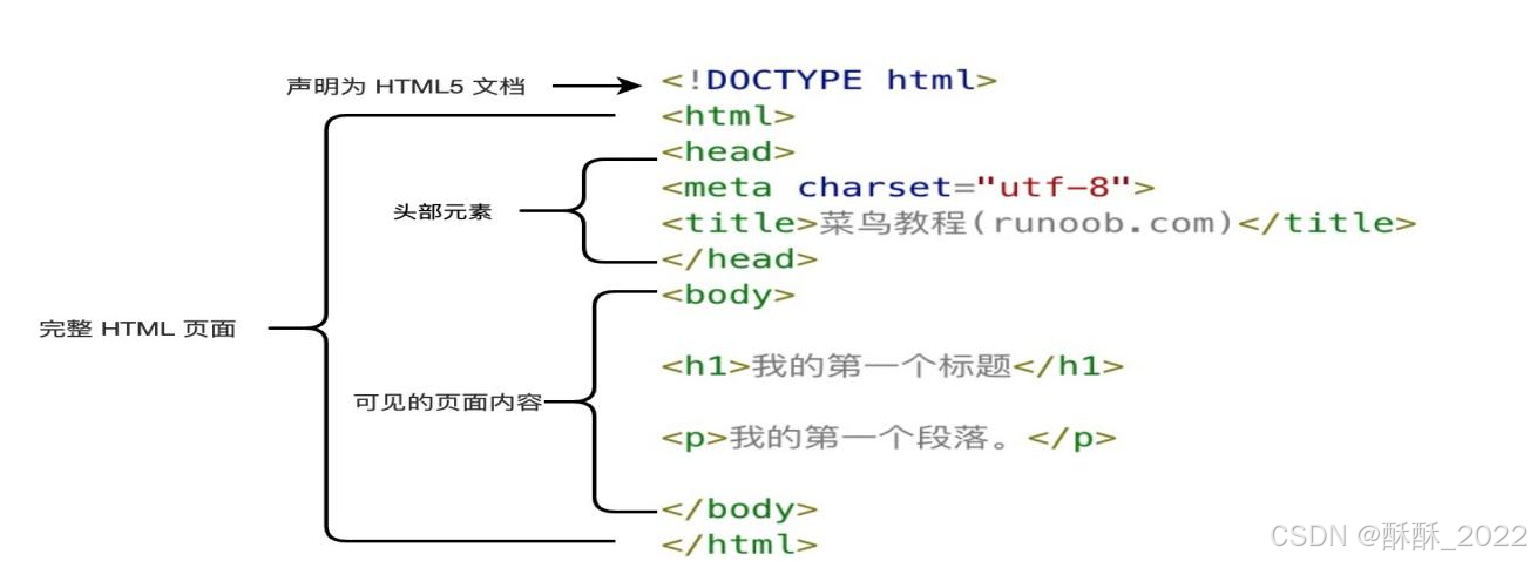
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<h1>我的第一个标题</h1>
<h2>这是一个标题</h2>
<h3>这是一个标题</h3>
<p>我的第一个段落。</p>
<p>这是第二个段落。</p>
<p>这是第三个段落。</p>
</body>
</html>
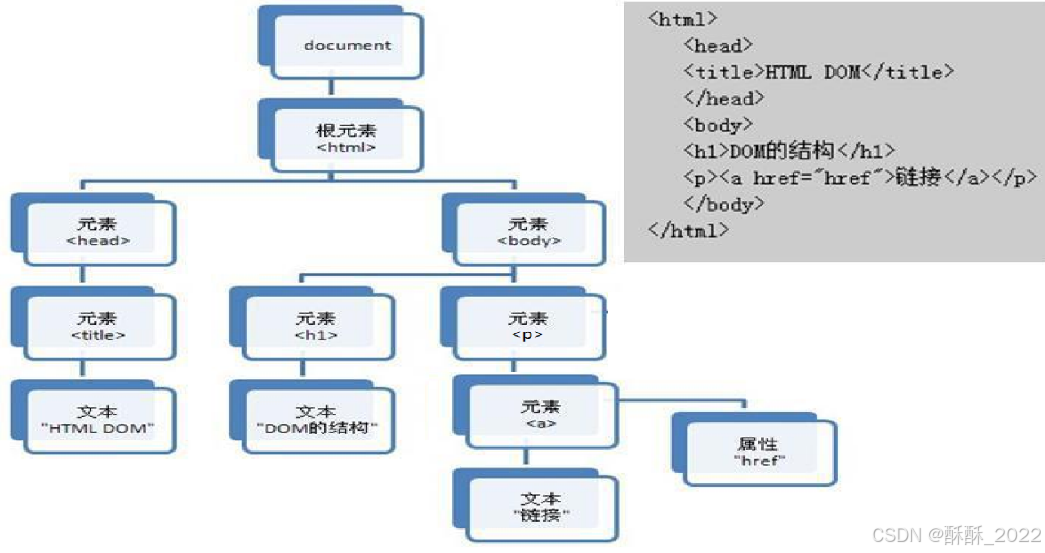
一个具体的HTML文档标签解析为一颗树(DOM树):
HTML常用标签、元素及标签属性
HTML 是所有网页制作技术的核心和基础,也是每个网页制作者必须掌握的基本知识,而 html 标签是 html 语言中最基本的单位,是 HTML最重要的组成部分。
HTML常用标签
HTML标签的特点:
①HTML标签是由尖括号包围的关键词,比如 < html >
②HTML标签分别双标签和单标签,标签中有属性,属性具有属性值。
③HTML双标签,比如 < b> 和 < /b>为双标签,标签对中的第一个标签是开始标签,第二个标签是结束标签,开始和结束标签也被称为开放标签和闭合标签。
④HTML 标签是与大小写无关的,例如“< BODY>”跟< body>表示的意思是一样的,推荐使用小写。
HTML元素
一个 HTML 元素包含了开始标签与结束标签,如下为一个HTML元素:
<p>这是一个段落。</p>有时也把元素称为节点。HTML 元素以开始标签起始,以结束标签终止,元素的内容是开始标签与结束标签之间的内容。某些 HTML 元素具有空内容(empty content),空元素在开始标签中进行关闭(以开始标签的结束而结束)。大多数 HTML元素可拥有属性,可以嵌套。
HTML标签属性
属性是用来修饰标签的,放在开始标签里面,提供了有关 HTML 元素的更多的信息。比如在a标签,属性可以定义跳转的超链接,或者类名称
<a href="http://www.w3school.com.cn">This is a link</a>
属性类似于描述人的形容词,比如,戴眼镜,帅气,体重200斤等。 HTML把属性分为四类:
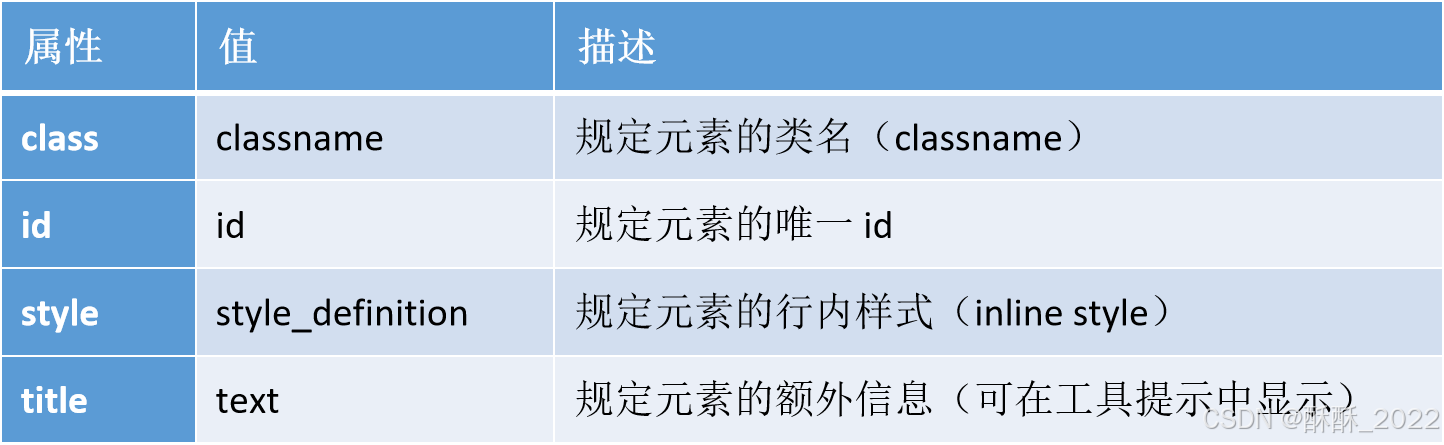
Xpath
1.什么是XPath
XPath即为DOM解析树路径语言(XML Path Language),它是一种用来确定HTML文档中某部分位置的语言。
XPath 使用路径表达式来选取HTML文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。路径表达式是从一个HTML节点(当前的上下文节点)到另一个节点、或一组节点的步骤顺序。这些步骤以“/”字符分开,每一步有三个构成成分:
(1)轴描述(用最直接的方式接近目标节点);
(2)节点测试(用于筛选节点位置和名称);
(3)节点描述(用于筛选节点的属性和子节点特征)。
假设有一个网页的解析树如图:
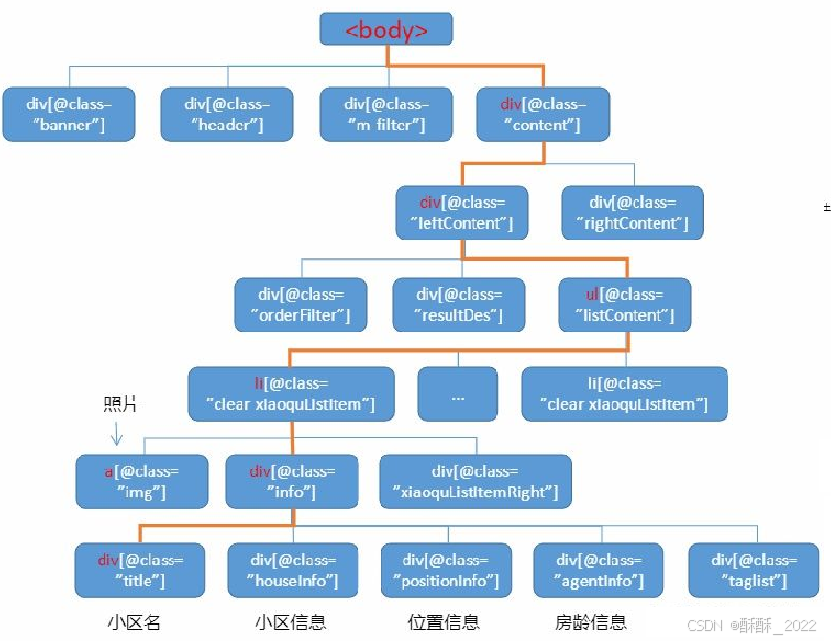
那么获取小区名的Xpath就是:
/html/body/div[4]/div[1]/ul/li[1]/div[1]/div[1]
从这个例子可知,XPath就是html代码解析树的一个个节点,其中数字是节点出现的序号。 用标签结合属性Xpath可以达到同样的效果,如:
div[@class ="title"]
可以获取网页中属性class为title的所有节点,但有些非小区名称的数据也可能会被提取出来。
Xpath路径表达式语法
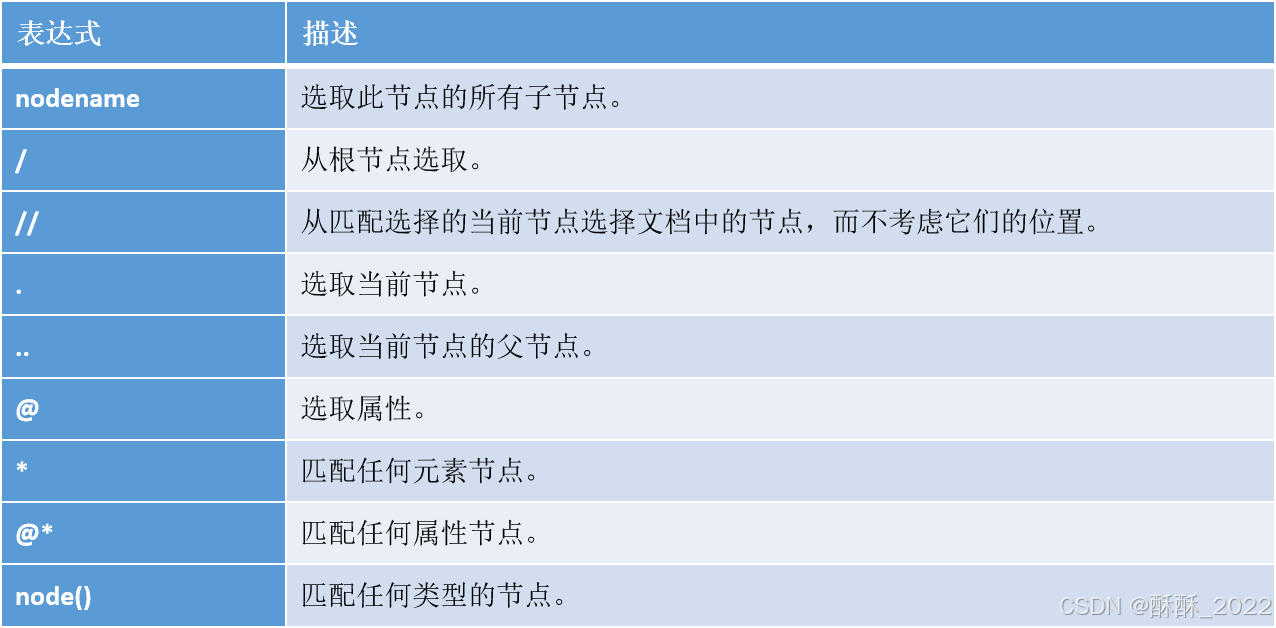
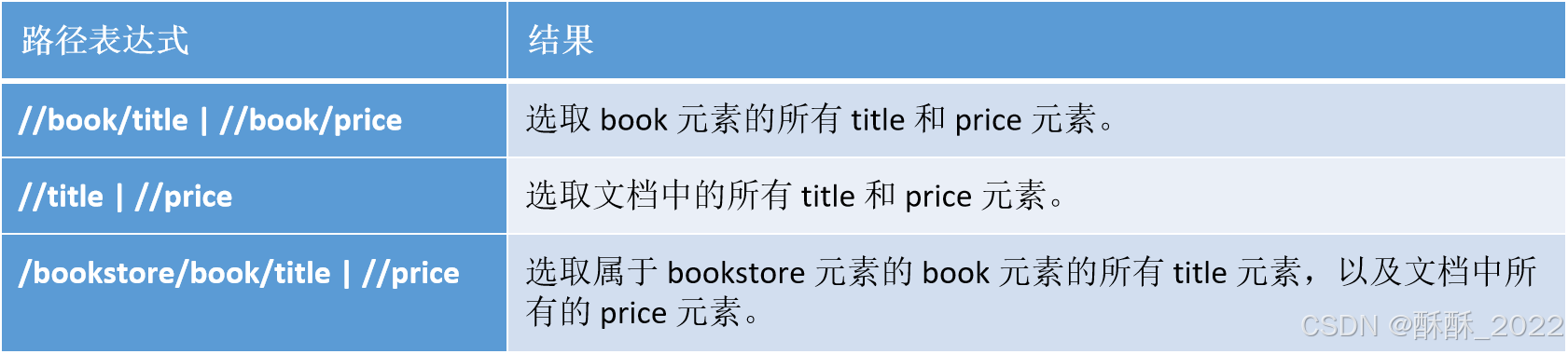
使用路径表达式
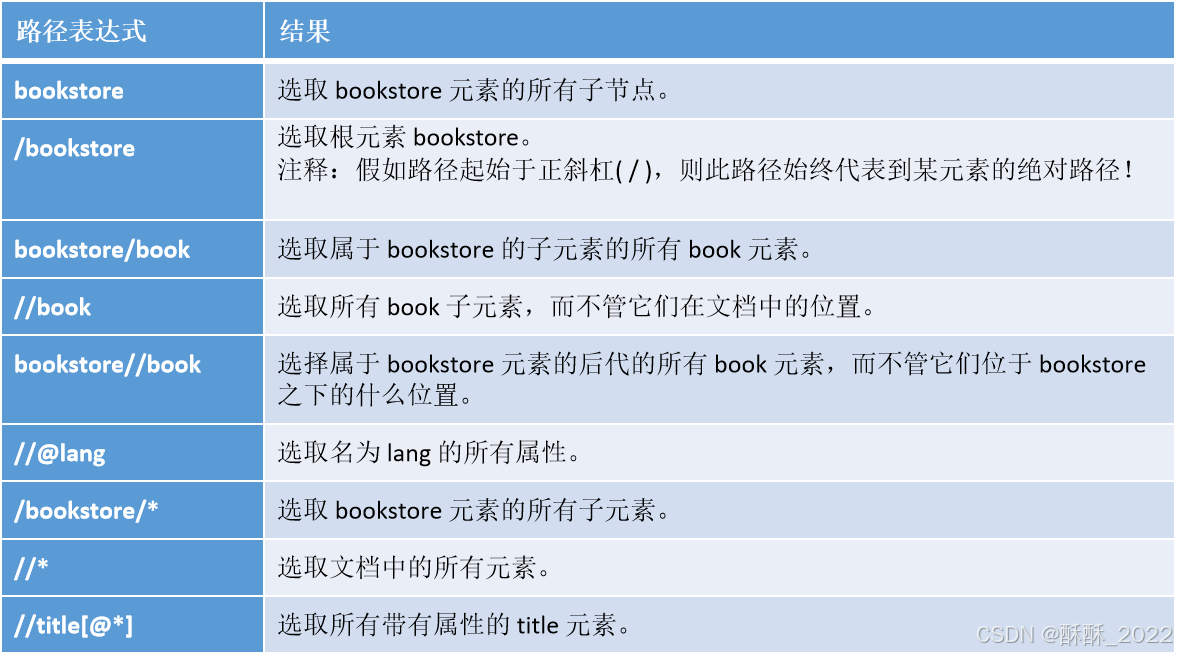
带有谓语的一些路径表达式,以及表达式的结果如表所示:

通过使用”|”,可以选取若干路径
二.爬 虫 原 理
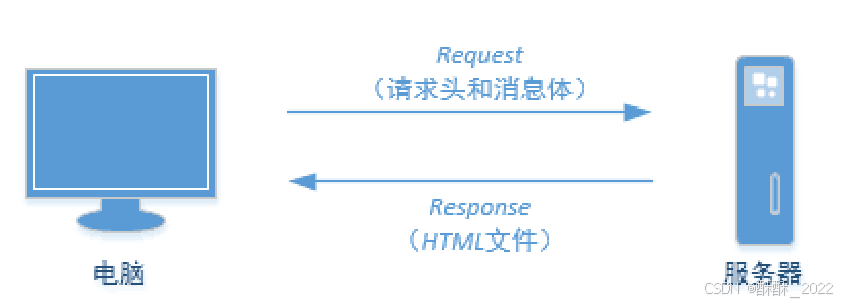
1.网络连接
网络连接像是在自助饮料售货机上购买饮料一样:购买者只需选择所需饮料,投入硬币(或纸币),自助饮料售货机就会弹出相应的商品。网络连接也正是如此,如图所示,本机电脑(购买者)带着请求头和消息体(硬币和所需饮料)向服务器(自助饮料售货机)发起一次Requests请求(购买),相应的服务器(自助饮料售货机)会返回本机电脑相应的HTML文件作为Response(相应的商品)。
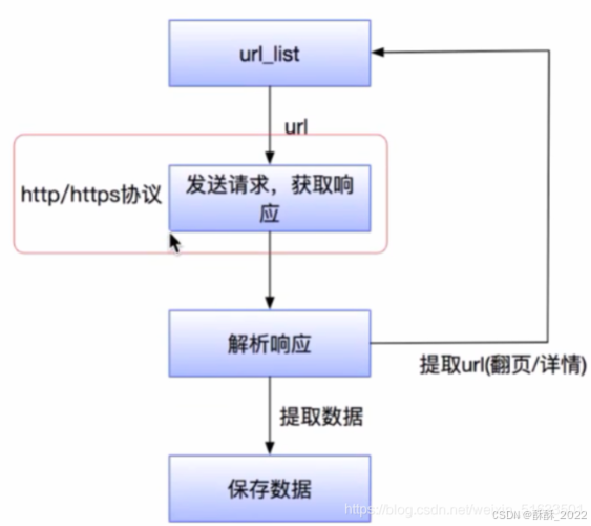
2.爬虫流程
网络连接需要一次Requests请求和服务器端的Response回应。所以爬虫需要二件事:
(1)模拟电脑对服务器发起Requests请求。
(2)接收服务器端的Response的内容并解析提取所需信息。 但互联网网页错综复杂,一次的请求和回应不能够批量获取网页的数据,这时就需要设计爬虫的流程,如图所示。
简单地讲就是:网页采集-->网页解析--->数据入库
常用模块
1、Requests模块
Requests库官方文档指出:让HTTP服务人类。细心的读者就会发现,Requests模块的作用就是请求网站获取网页数据的。
response的属性:
(1)response.status_code:http请求的返回状态,2XX 表示连接成功,3XX 表示跳转 , 4XX 客户端错误 , 500 服务器错误
(2)response.text:http响应内容的 字符串(str) 形式,请求url对应的页面内容。
(3)response.encoding=“utf-8” 或者 response.encoding=”gbk”:打印文本没有乱码。
(4)response.content:HTTP响应内容的 二进制(bytes) 形式。
(5)response.headers:http响应内容的头部内容。
例如:
import requests
res = requests.get('http://bj.xiaozhu.com/')
print(res) #如果返回200,说明请求网址成功,若为404,400则请求网址失败。
print(res.text)
写成函数:
def getHtml(url):
#异常处理
try:
res= requests.get(url) #使用get函数打开指定的url
res.raise_for_status() #如果状态不是200,则引发异常
res.encoding = 'utf-8' #更改编码方式
return r.text #返回页面内容
except:
return "打开网页失败" #发生异常返回空字符
url='http://bj.xiaozhu.com/'
html=getHtml(url)

2、BeautifulSoup模块
通过BeautifulSoup模块可以轻松的解析Requests模块请求的网页,并把网页源代码解析为Soup文档,以便过滤提取数据,如:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">数据在这里</b>')
tag = soup.b #见表11.6
print(tag.text) #返回 “数据在这里”BeautifulSoup 对象的常用属性
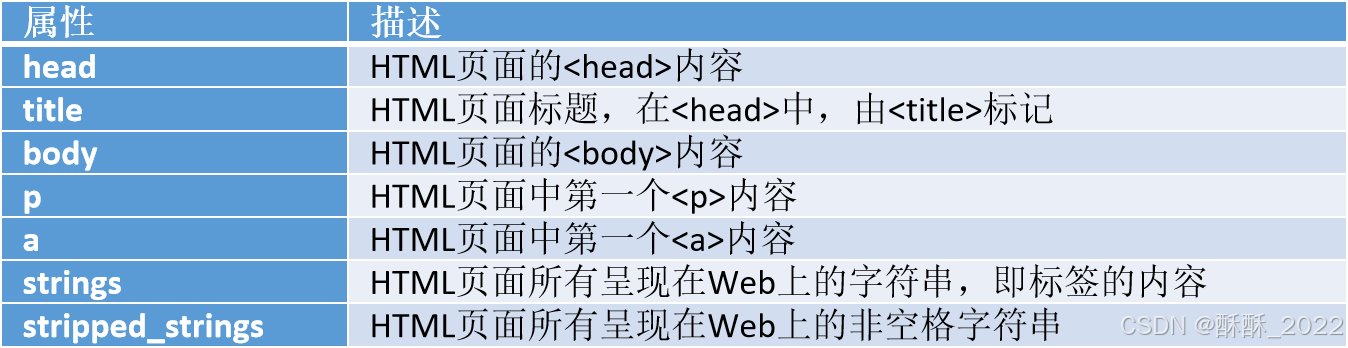
Tag 对象的常用属性

注意:按照 HTML 语法,可以在标签中嵌套其他标签,因此,string 属性的返回值遵循如下原则: (1)如果标签内部没有其他标签,string 属性返回其中的内容。
(2)如果标签内部还有其他标签,但只有一个标签,string 属性返回最里面标签的内容。
(3)如果标签内部还有其他标签,且不止一个标签,string 属性返回 None。
3、lxml模块
lxml是以Python语言编写的库,主要用于解析和提取HTML或者XML格式的数据,它不仅功能非常丰富,而且便于使用,可以利用XPath语法快速地定位特定的元素或节点。
lxml模块中大部分的功能都位于 lxml.etree子模块中。
lxml模块中ElementPath类:可以理解为XPath,用于搜索和定位节点。提供了三个常用的方法,可以满足大部分搜索和查询需求,并且这两个方法的参数都是XPath语句,具体如下:
find()方法:返回匹配到的第一个子元素;
findall()方法:以列表的形式返回所有匹配的子元素。
iterfind()方法:返回一个所有匹配元素的迭代器。
三.小结
(1)对于定向信息的爬取,网络爬虫主要采取数据抓取、数据解析、数据入库等几个步骤; (2)requests 模块、beautifulsoup4 模块、lxml模块都是第三方库,使用前需先进行安装;
(3)requests 模块中使用 requests.get()函数获取网页信息;
(4)beautifulsoup4 模块用于解析和处理 HTML 和 XML 文件,其最大的优点是,能够根据 HTML 和 XML 语法建立解析树,进而提高解析效率;
(5)BeautifulSoup 对象的 find_all()方法会遍历整个 HTML 文件,按照条件返回标签内容(列表类型) ;
(6)Xpath使用路径表达式来选取HTML文档中的节点或者节点集;
(7)lxml可以利用XPath语法快速地定位特定的元素或节点。