- ubuntu 18.04 64bit
- anaconda with 3.7
- nvidia gtx 1070Ti
- cuda 10.1
- pytorch 1.5
- YOLOv5
YOLOv5环境配置
请参考之前的文章,YOLOv5目标检测
使用COCO数据集
YOLOv5的预训练模型是基于 COCO数据集,如果自己想去复现下训练过程,可以依照下面的命令
$ python train.py --data coco.yaml --cfg yolov5s.yaml --weights '' --batch-size 64
yolov5m 48
yolov5l 32
yolov5x 16
COCO的数据集可以通过data文件夹下get_coco2017.sh脚本进行下载,包含图片和lable文件。COCO的数据集实在是太大了,整个压缩包有18G,考虑到自己到的网速还有机器的算力,还是洗洗睡吧。。。
制作自己的数据集
如果没有对应目标的公开数据集,那就只有自己出手收集了,图片到手后,接下来就是艰辛的打标签工作了,
LabelImg使用Qt做了图形化的界面,操作还是很方便的,这也是选择它的理由,它提供了默认的class,如果你不需要这些类型的话,可以将其删除
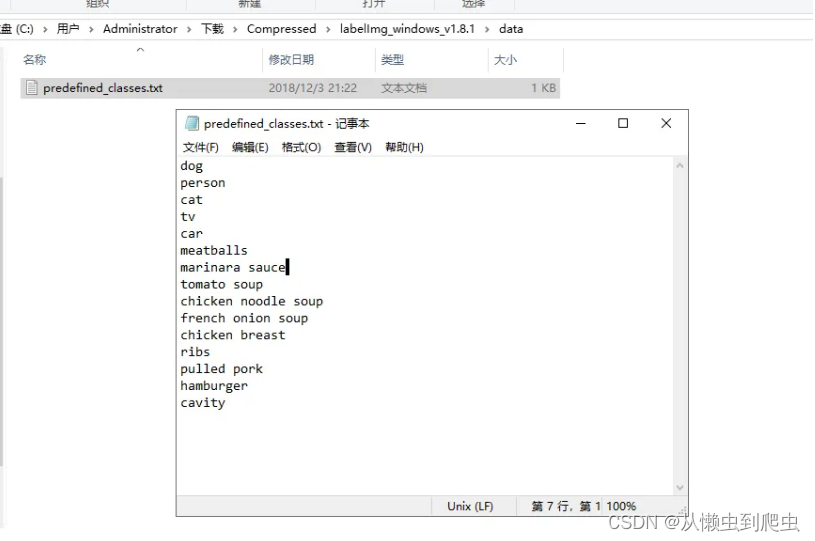
接下来就可以打开exe文件,点击Open导入图片,按下快捷键w,选定目标后,会弹出输入框,写上class名称,就可以了,如果有多个目标,那就继续标
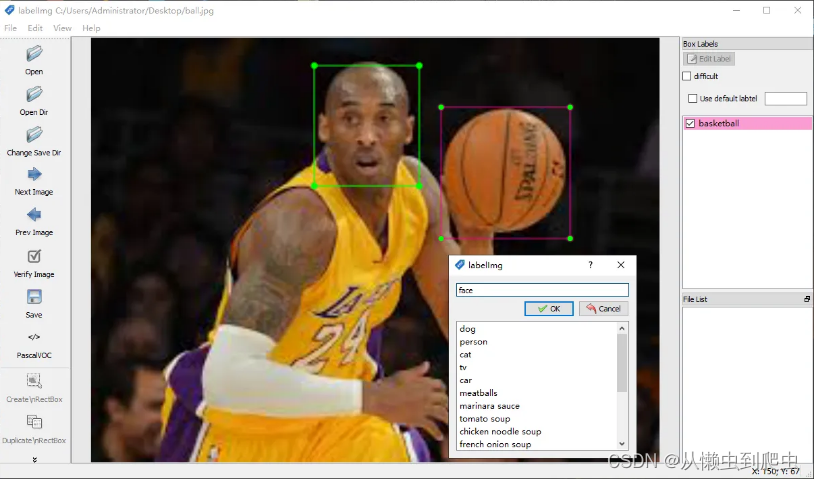
labelImg还支持文件夹的导入,在标完一张后,在左侧选择Next Image就可以切换到下一张继续了。输出格式部分,目前labelImg支持YOLO和PascalOVC2种格式,前者标签信息是存储在txt文件中,而后者是存储在xml中
打完标签后,就可以进行保存了,图片和标签文件我们分开存放,但是文件名是对应的,只是扩展名不同
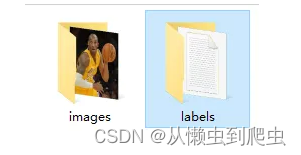
最后来看看标签文件的内容
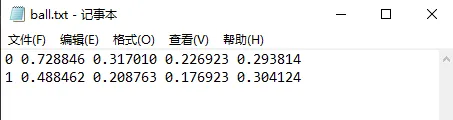
一行代表一个目标,格式是
class x_center y_center width height
使用公开的数据集进行训练
下载下来是一个压缩包,解压后,文件夹内的文件结构是这样的
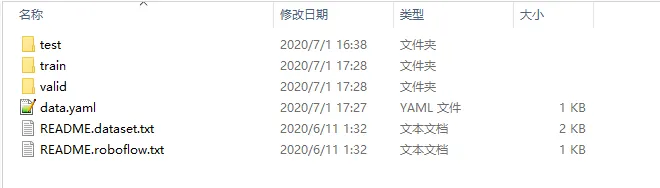
其中文件夹train包含了参加训练的图片以及对应的label文件,两者只有扩展名不同而已,目前图片只有105张。我们将包含数据集的文件夹重命名为mask,存储在yolov5工程的同级目录下
接着修改mask/data.yaml文件内容为
(base) xugaoxiang@1070Ti:~/Works/github/mask$ cat data.yaml
train: ../mask/train/images
val: ../mask/valid/images
nc: 2
names: ['mask', 'no-mask']
最后修改yolov5/models/yolov5s.yaml,将nc = 80修改为nc = 2,因为数据集中只有mask和no-mask2个类别
接下来执行训练命令
cd yolov5
python train.py --img 640 --batch 16 --epochs 300 --data ../mask/data.yaml --cfg models/yolov5s.yaml --weights ''
# 总结
如果你选择了IT行业并坚定的走下去,这个方向肯定是没有一丝问题的,这是个高薪行业,但是高薪是凭自己的努力学习获取来的,这次我把P8大佬用过的一些学习笔记(pdf)都整理在本文中了
**《Java中高级核心知识全面解析》**

**小米商场项目实战,别再担心面试没有实战项目:**

> **找小编(vip1024c)领取**
存中...(img-Xu23i1v2-1721722088189)]
**小米商场项目实战,别再担心面试没有实战项目:**
[外链图片转存中...(img-T5IoKFz1-1721722088190)]
> **找小编(vip1024c)领取**