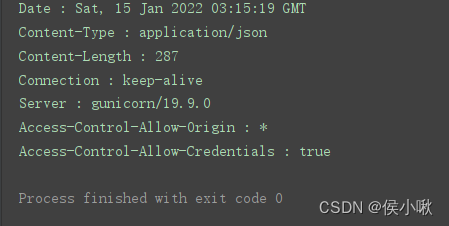
可通过info()方法获取响应头信息。
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = ‘https://www.httpbin.org/get’ # get请求测试地址
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request(‘GET’, url) # 发送GET请求,默认重试请求
response_header = r.info() # 获取响应头
for key in response_header.keys(): # 循环遍历打印响应头信息
print(key, ‘:’, response_header.get(key))
处理服务器返回的JSON信息
通过json模块的 loads() 方法将响应json数据转换为字典类型。
import urllib3 # 导入urllib3模块
import json # 导入json模块
urllib3.disable_warnings() # 关闭ssl警告
url = ‘https://www.httpbin.org/post’ # post请求测试地址
params = {‘name’: ‘Jack’, ‘country’: ‘中国’, ‘age’: 30} # 定义字典类型的请求参数
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request(‘POST’, url, fields=params) # 发送POST请求
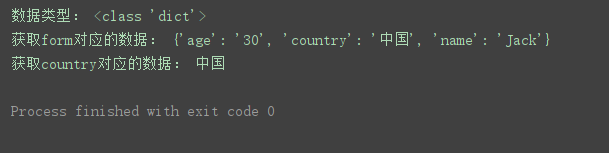
j = json.loads(r.data.decode(‘unicode_escape’)) # 将响应数据转换为字典类型
print(‘数据类型:’, type(j))
print(‘获取form对应的数据:’, j.get(‘form’))
print(‘获取country对应的数据:’, j.get(‘form’).get(‘country’))
二进制数据
如果响应数据为二进制数据,则可以使用open()函数将二进制数据转换为图片。
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = ‘http://sck.rjkflm.com:666/spider/file/python.png’ # 图片请求地址
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request(‘GET’, url) # 发送网络请求
print(r.data) # 打印二进制数据
f = open(‘python.png’, ‘wb+’) # 创建open对象
f.write(r.data) # 写入数据
f.close() # 关闭
运行结果省略。生成图片文件如下:

==============================================================================
示例如下:
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = ‘https://www.httpbin.org/get’ # get请求测试地址
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36’}
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request(‘GET’, url, headers=headers) # 发送GET请求
print(r.data.decode(‘utf-8’)) # 打印返回内容
超时的参数与时间可以写在request()方法中,也可以写在PoolManager()实例对象中。
示例:
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
baidu_url = ‘https://www.baidu.com/’ # 百度 超时请求测试地址
python_url = ‘https://www.python.org/’ # Python 超时请求测试地址
http = urllib3.PoolManager() # 创建连接池管理对象
try:
r = http.request(‘GET’, baidu_url, timeout=0.01) # 发送GET请求,并设置超时时间为0.01秒
except Exception as error:
print(‘百度超时:’, error)
http2 = urllib3.PoolManager(timeout=0.1) # 创建连接池管理对象,并设置超时时间为0.1秒
try:
r = http2.request(‘GET’, python_url) # 发送GET请求
except Exception as error:
print(‘Python超时:’, error)

如果需要更精准,则可以使用 Timeout 实例对象设置连接超时与读取超时。
示例代码:
import urllib3
from urllib3 import Timeout
urllib3.disable_warnings()
timeout = Timeout(connect=0.5, read=0.1)
http = urllib3.PoolManager(timeout=timeout)
http.request(‘GET’, “https://www.python.org/”)
或者
import urllib3
from urllib3 import Timeout
urllib3.disable_warnings()
timeout = Timeout(connect=0.5, read=0.1)
http = urllib3.PoolManager()
http.request(‘GET’, “https://www.python.org/”, timeout=timeout)
设置代理IP需要创建ProxyManager对象,该对象需要有两个参数;proxy_url表示需要使用的代理IP,headers即请求头。
import urllib3 # 导入urllib3模块
url = “http://httpbin.org/ip” # 代理IP请求测试地址
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36’
}
创建代理管理对象
proxy = urllib3.ProxyManager(‘xxxxxxxxxxxx’, headers=headers)
r = proxy.request(‘get’, url, timeout=2.0) # 发送请求
print(r.data.decode()) # 打印返回结果
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!

三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典
简历模板
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)

18年进入阿里一直到现在。**
深知大多数初中级Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)
[外链图片转存中…(img-CaL6wl95-1710877566851)]