

思路
总的有两步,第一步:查询用户,第二步:查询地址。
1.先根据id查询用户,得到用户集合。
1.1如果用户集合为空返回一个空集合。
2.查询地址。
2.1.获取用户的id集合。
2.2.根据用户的id集合查询地址,得到一个总的地址集合(也就是根据用户id查出来的所有的地址)。
2.3.转换地址VO。
2.4.用户地址集合分组,相同用户的放入一个集合(组)中,也就是说根据用户的id进行分组,哪几个地址是该id用户的,就放入该id用户对应的集合里面去。得到一个Map集合。key就是用户id,value是该id用户对应的地址。
3.转换VO返回。
public List<UserVO> queryUserAndAddressByIds(List<Long> ids) {
//1.查询用户
List<User> users = listByIds(ids);
if (CollUtil.isEmpty(users)){
return Collections.emptyList();
}
//2.查询地址
//2.1.获取用户id集合
List<Long> userIds = users.stream().map(User::getId).collect(Collectors.toList());
//2.2.根据用户id查询地址
List<Address> addresses = Db.lambdaQuery(Address.class).in(Address::getUserId, userIds).list();
//2.3.转换地址VO
List<AddressVO> addressVOList = BeanUtil.copyToList(addresses, AddressVO.class);
//2.4.用户地址集合分组,相同用户的放入一个集合(组)中
Map<Long, List<AddressVO>> addressMap = new HashMap<>(0);
if (CollUtil.isNotEmpty(addressVOList)){
addressMap = addressVOList.stream().collect(Collectors.groupingBy(AddressVO::getUserId));
}
//3.转换VO返回
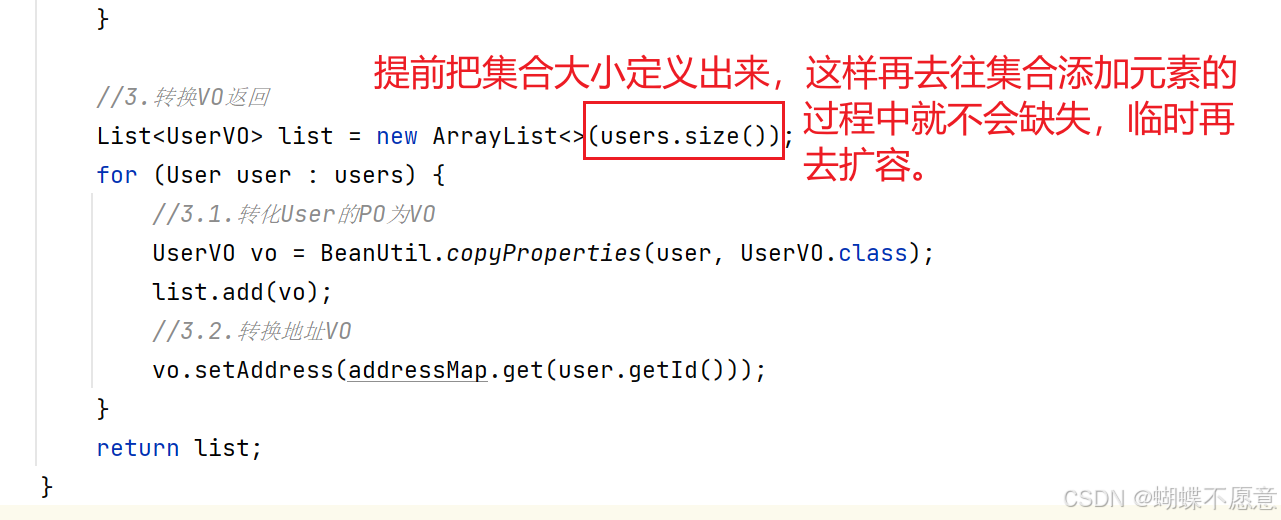
List<UserVO> list = new ArrayList<>(users.size());
for (User user : users) {
//3.1.转化User的PO为VO
UserVO vo = BeanUtil.copyProperties(user, UserVO.class);
list.add(vo);
//3.2.转换地址VO
vo.setAddress(addressMap.get(user.getId()));
}
return list;
}
Stream提供的常用中间方法
<R>Stream<R> map(Function<? super T,extends R> mapper)
对元素进行加工,并返回对应的新流。
Collectors工具类提供了具体的收集方式
public static <T> collector toList()
把元素收集到List集合中。
·ArrayList底层基于数组实现的,根据查询元素快,增删相对慢。
ArrayList第一次创建集合并添加第一个元素的时候,在底层创建一个默认长度为10的数组。
1. 扩容触发条件
每次调用 add()方法添加元素时,ArrayList会检查当前元素数量(size)是否等于底层数组长度(elementData.length)。
如果 size + 1 > elementData.length(即当前数组已满),则会触发扩容。
2. 扩容机制
计算新容量:新容量通常是旧容量的 1.5 倍(即 newCapacity = oldCapacity + (oldCapacity >> 1))。例如,初始容量为 10,第一次扩容后变为 10 + 5 = 15。
处理极端情况:如果一次性添加大量元素(如通过 addAll()),新容量会直接调整为刚好能容纳所有元素的最小值,而不是严格按 1.5 倍增长。
数组复制:将旧数组中的元素复制到新数组中,后续操作基于新数组进行。
建议:如果提前知道需要存储大量元素,可通过构造函数 new ArrayList<>(initialCapacity) 指定初始容量,减少扩容次数。
总结
当 ArrayList 的初始容量 10 被填满后,会通过 1.5 倍扩容策略动态调整底层数组大小,确保能够持续添加元素。这是ArrayList实现动态增长的核心机制。