10)mapValues
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo10MapValues {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("MapValues算子演示")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val kvRDD1: RDD[(String, Int)] = linesRDD.map(_.split(",")).map {
case Array(_, name:String, age:String, _,_) =>
(name, age.toInt)
}
/**
* mapValues函数也是作用在kv格式的算子上
* 将每个元素的值传递给后面的函数,进行处理得到新的值,键不变,这个处理后的组合重新返回到新的RDD中
* 不改变键,只改变每个键所对应的值(是每个人的年龄加100)
*/
kvRDD1.mapValues(_ + 100).foreach(println)
}
}
11)sortBy
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo12SortBy {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("MapValues算子演示")
val sc: SparkContext = new SparkContext(conf)
//TODO parallelize:将scala的集合变成spark中的RDD
val rdd1: RDD[Int] = sc.parallelize(List(34, 123, 6, 1, 231, 1, 34, 56, 2))
//TODO 与Scala中不同,若是.sortBy(e)形式则会报错
val rdd2: RDD[Int] = rdd1.sortBy((e: Int) => e)
rdd2.foreach(println)
}
}
12)mapPartitions
mapPartitions:一次处理一个分区中的数据
它与map的区别在于,map是每次处理一条数据就返回一条数据到下一个rdd
而mapPartitions一次处理一个分区的数据,处理完再返回
最后的处理效果和map的处理效果是一样的
mapPartition可以优化与数据库连接的次数
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo11partitionBy {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("MapValues算子演示")
val sc: SparkContext = new SparkContext(conf)
// TODO spark/data/wcs/*目录下有两个文件,相当于两个block块,会生成两个分区
val linesRDD: RDD[String] = sc.textFile("spark/data/wcs/*")
/**
* mapPartitions:一次处理一个分区中的数据
* 它与map的区别在于,map是每次处理一条数据就返回一条数据到下一个rdd
* 而mapPartitions一次处理一个分区的数据,处理完再返回()
* 最后的处理效果和map的处理效果是一样的
* mapPartition可以优化与数据库连接的次数,使用mapPartition时,可以将一个分区的数据视为一个批次,
* 并在该批次内统一处理。这意味着可以在处理整个分区之前建立一次数据库连接,并在处理完整个分区后断开连接。
*/
val rdd1: RDD[String] = linesRDD.mapPartitions((itr: Iterator[String]) => {
// 每个分区打印一次
println("=========================================")
itr.map((e: String) => {
e
})
})
val rdd1: RDD[String] = linesRDD.map((itr: String) => {
// 每条数据打印一次
println("=========================================")
itr
})
// linesRDD.map((e:String)=>{
// //...数据库连接
// })
rdd1.foreach(println)
}
}
2、行动算子
1)foreach
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo13foreach {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("MapValues算子演示")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val rdd1: RDD[Array[String]] = linesRDD.map((e: String) => {
e.split(",")
})
val rdd2: RDD[(String, String, String, String, String)] = rdd1.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
(id, name, age, gender, clazz)
}
/**
* 行动算子,就可以触发一次作业执行,有几次行动算子调用,就会触发几次
*
* rdd是懒加载的性质
*/
// rdd2.foreach(println)
// println("====================================")
// rdd2.foreach(println)
println("$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$") // 一定会打印,属于Scala而不属于spark作业中的语句
val rdd3: RDD[(String, String, String, String, String)] = rdd2.map((t5: (String, String, String, String, String)) => {
println("===============================")
t5
})
println("#############################")
rdd3.foreach(println)
while (true) {
}
}
}
2)collect
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo14collect {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("MapValues算子演示")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val rdd1: RDD[Array[String]] = linesRDD.map((e: String) => {
e.split(",")
})
val rdd2: RDD[Student] = rdd1.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
Student(id.toInt, name, age.toInt, gender, clazz)
}
//collect将rdd转成合适的scala中的数据结构
val stuArray: Array[Student] = rdd2.collect()
//foreach是scala中的foreach,不会产生作业执行的
stuArray.foreach(println)
while (true){
}
}
}
case class Student(id: Int, name: String, age: Int, gender: String, clazz: String)
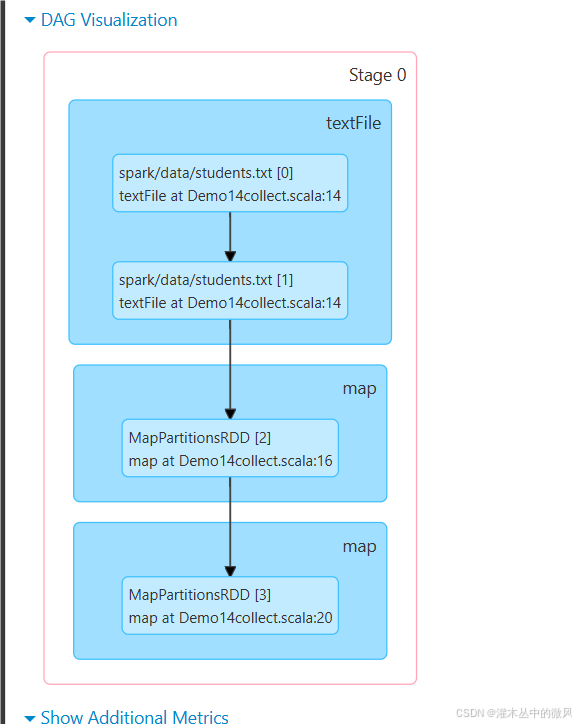
3、算子案例
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo15StudentTest1 {
def main(args: Array[String]): Unit = {
//求年级总分前10的学生各科分数的详细信息
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("MapValues算子演示")
val sc: SparkContext = new SparkContext(conf)
/**
* 文件中数据格式为:
* 1500100001,1000001,98
* 1500100001,1000002,5
* 1500100001,1000003,137
* 1500100001,1000004,29
*/
val linesRDD: RDD[String] = sc.textFile("spark/data/score.txt")
val idWithScoreRDD: RDD[(String, String, Int)] = linesRDD.map((line: String) => {
line.split(",") match {
case Array(id: String, subject_id: String, score: String) =>
(id, subject_id, score.toInt)
}
})
val array1: Array[String] = idWithScoreRDD
.map((t3: (String, String, Int)) => (t3._1, t3._3))
// 求出每个人的总分,为下面取总分前十名做铺垫
.reduceByKey(_ + _)
.sortBy((kv: (String, Int)) => -kv._2)
.take(10)
.map(_._1)
idWithScoreRDD.filter((t3: (String, String, Int)) => {
val bool: Boolean = array1.contains(t3._1)
if(bool){
println("存在")
}
bool
}).foreach((t3: (String, String, Int)) => {
println("==========================")
println(t3)
})
}
}
Spark中的缓存
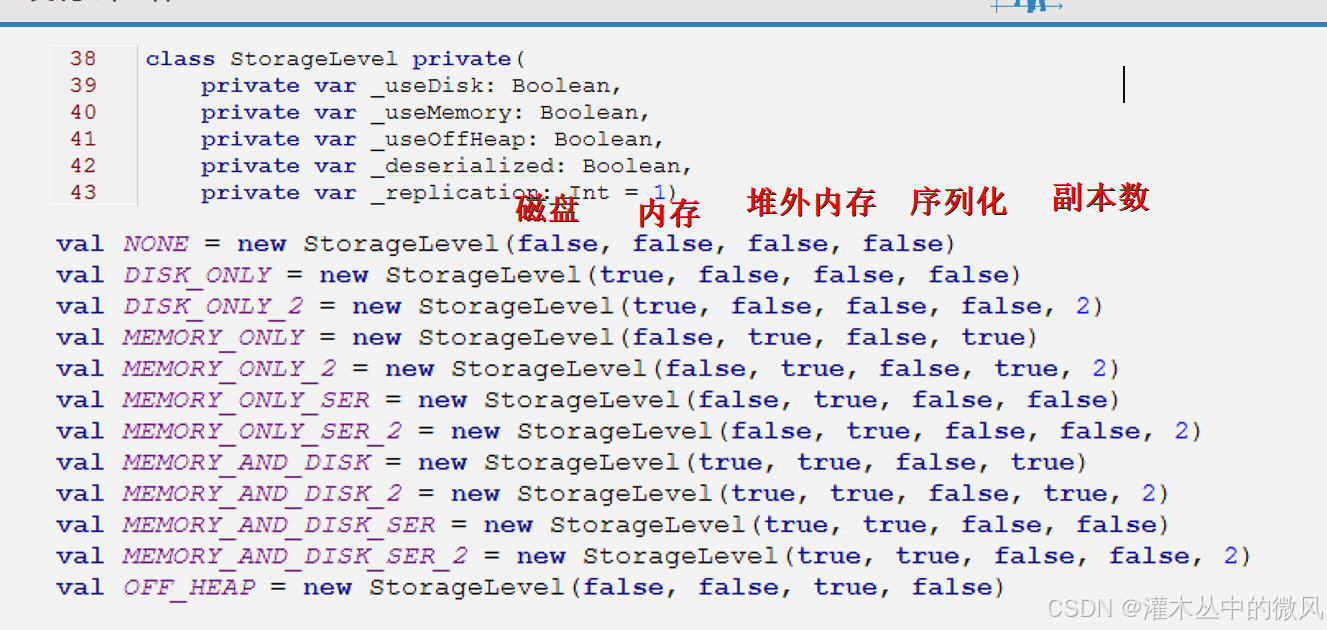
checkpoint和cache的区别?
cache是将一个复杂的RDD做缓存,将来执行的时候,只是这个rdd会从缓存中取
checkpoint是永久将rdd数据持久化,将来执行的时候,直接从检查点的rdd往后执行
1、cache
执行过后缓存就都没了
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Demo16Cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("缓存演示")
val sc: SparkContext = new SparkContext(conf)
//===================================================================
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val studentsRDD: RDD[Student2] = linesRDD.map(_.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
Student2(id, name, age.toInt, gender, clazz)
}
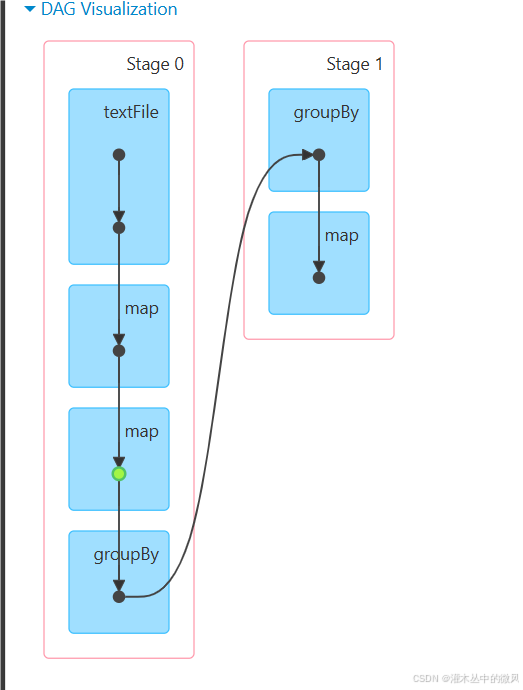
/**
* 缓存:
* 在缓存的第一次执行时,就已经从缓存中放入数据并且下面取的时候就从缓存中取数据了
* 缓存的目的是为了spark core作业执行的时候,缩短rdd的执行链,能够更快的得到结果
* RDD在缓存之后,若是再次执行这个RDD有向无环图时,即可从所缓存的RDD开始执行,缩短执行速度
* 缓存的实现方式:
* 1、需要缓存的rdd调用cache函数
* 2、persist(StorageLevel.MEMORY_ONLY) 修改缓存级别
*/
// studentsRDD.cache() // 默认将rdd缓存到内存中,缓存级别为memory_only
// 将rdd缓存到磁盘中
studentsRDD.persist(StorageLevel.MEMORY_AND_DISK)
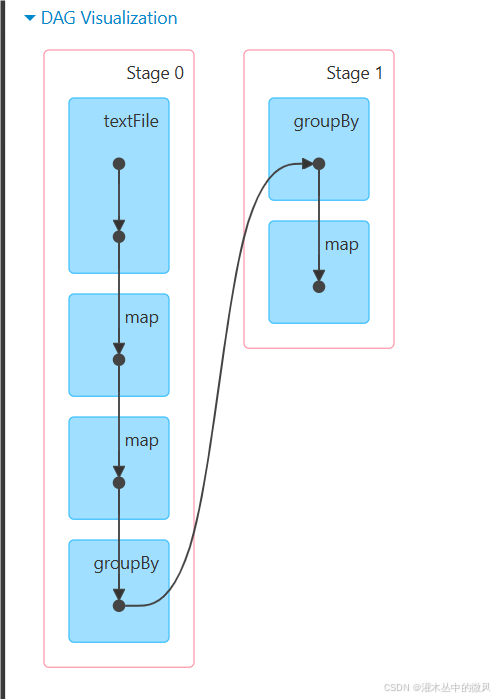
//需求1:求每个班级的人数
val rdd1: RDD[(String, Iterable[Student2])] = studentsRDD.groupBy(_.clazz)
val resRDD1: RDD[(String, Int)] = rdd1.map((kv: (String, Iterable[Student2])) =>
(kv._1, kv._2.size))
resRDD1.foreach(println)
//需求2:求每个年龄的人数
val rdd2: RDD[(Int, Iterable[Student2])] = studentsRDD.groupBy(_.age)
val resRDD2: RDD[(Int, Int)] = rdd2.map((kv: (Int, Iterable[Student2])) =>
(kv._1, kv._2.size))
resRDD2.foreach(println)
while (true){
}
}
}
case class Student2(id:String,name:String,age:Int,gender:String,clazz:String)
缓存前
缓存后
2、checkpoint
永久将执行过程中RDD中流动的数据存储到磁盘(hdfs)中
checkpoint
需要设置checkpoint的路径,统一设置的
checkpoint也相当于一个行动算子,触发作业执行(触发一个新的Job作业的执行)
第二次DAG有向无环图执行的时候(再存储完之后的又一次调用行动算子后),直接从最后一个有检查点的rdd开始向下执行
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo17Checkpoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("缓存演示")
val sc: SparkContext = new SparkContext(conf)
//TODO 设置检查点的存储路径
sc.setCheckpointDir("spark/data/checkpoint1")
//===================================================================
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val studentsRDD: RDD[Student2] = linesRDD.map(_.split(","))
.map {
case Array(id: String, name: String, age: String, gender: String, clazz: String) =>
Student2(id, name, age.toInt, gender, clazz)
}
// TODO checkpoint
studentsRDD.checkpoint()
//需求1:求每个班级的人数
val rdd1: RDD[(String, Iterable[Student2])] = studentsRDD.groupBy(_.clazz)
val resRDD1: RDD[(String, Int)] = rdd1.map((kv: (String, Iterable[Student2])) => (kv._1, kv._2.size))
resRDD1.foreach(println)
//需求2:求每个年龄的人数
val rdd2: RDD[(Int, Iterable[Student2])] = studentsRDD.groupBy(_.age)
val resRDD2: RDD[(Int, Int)] = rdd2.map((kv: (Int, Iterable[Student2])) => (kv._1, kv._2.size))
resRDD2.foreach(println)
while (true) {
}
}
}
运行界面信息
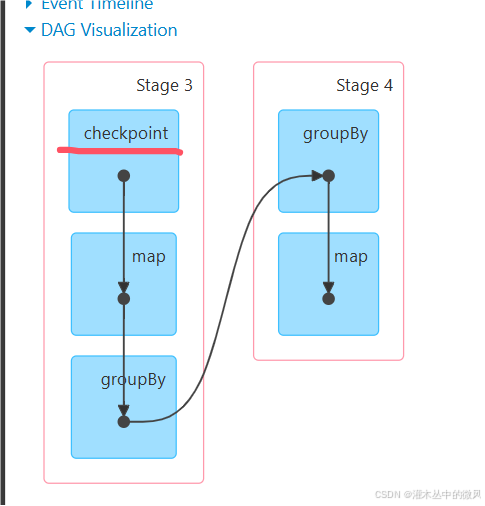

Spark在linux中的部署
配置
1、上传解压,配置环境变量 配置bin目录
解压
tar -zxvf spark-3.1.3-bin-hadoop3.2.tgz -C …/
重命名
mv spark-3.1.3-bin-hadoop3.2 spark-3.1.3
配置环境变量
vim /etc/profile更改用户组:
chown -R root:root spark-3.1.3
2、修改配置文件 conf
cp spark-env.sh.template spark-env.sh
增加配置:
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171master相当于RM worker相当于NM
增加从节点配置
cp workers.template workersvim workers
更改localhost为:
node1
node2
3、复制到其它节点
scp -r spark-3.1.3 node1:
pwd
scp -r spark-3.1.3 node2:pwd
4、在主节点执行启动命令
启动集群,在master中执行
./sbin/start-all.shhttp://master:8080/ 访问spark ui
standalone client模式
1、standalone client模式 日志在本地输出,一般用于上线前测试(bin/下执行)
需要进入到spark-examples_2.11-2.4.5.jar 包所在的目录下执行
cd /usr/local/soft/spark-2.4.5/examples/jars提交spark任务
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512m --total-executor-cores 1 ./spark-examples_2.12-3.1.3.jar 10
2、standalone cluster模式 上线使用,不会在本地打印日志
在该模式下运行时,必须保证node1、node2的/usr/local/soft/spark-3.1.3/examples/jars下由所要运行的jar包。因为不确定是哪个节点在运行任务。
scp spark-1.0.jar node1:/usr/local/soft/spark-3.1.3/examples/jars
执行模板:
spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 1 --deploy-mode cluster ./spark-examples_2.12-3.1.3.jar 100
spark-shell : spark 提供的一个交互式的命令行,可以直接写代码
spark-shell master spark://master:7077
整合yarn
yarn中之前没有配置yarn.application.classpath,需要对其进行配置:
样例:
在Linux中查找value:
hadoop classpath<property> <name>yarn.application.classpath</name> <value>/usr/local/soft/hadoop-3.1.3/etc/hadoop:/usr/local/soft/hadoop-3.1.3/share/hadoop/common/ lib/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/common/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/hd fs:/usr/local/soft/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/hdf s/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/usr/local/soft/hadoop-3.1.3/share/hado op/mapreduce/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/yarn:/usr/local/soft/hadoop-3.1.3/share/hado op/yarn/lib/*:/usr/local/soft/hadoop-3.1.3/share/hadoop/yarn/*</value> </property>
提交到了yarn上,可以在master:9870网页查看
在公司一般不适用standalone模式,因为公司一般已经有yarn 不需要搞两个资源管理框架
停止spark集群
在spark sbin目录下执行 ./stop-all.shspark整合yarn只需要在一个节点整合, 可以删除node1 和node2中所有的spark 文件
1、增加hadoop 配置文件地址
conf目录下 vim spark-env.sh 增加 export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.1.3/etc/hadoop2、往yarn提交任务需要增加两个配置 yarn-site.xml(/usr/local/soft/hadoop-3.1.3/etc/hadoop/yarn-site.xml)(Hadoop配置时已配置)
先关闭yarn
stop-all.shcd /usr/local/soft/hadoop-3.1.3/etc/hadoop
vim yarn-site.xml
增加配置
yarn.nodemanager.vmem-check-enabled false
yarn.nodemanager.pmem-check-enabled
false
4、同步到其他节点,重启yarn(Hadoop配置时已配置)
scp -r yarn-site.xml node1:
pwd
scp -r yarn-site.xml node2:pwd启动yarn
start-all.shcd /usr/local/soft/spark-3.1.3/examples/jars
3.spark on yarn client模式 日志在本地输出,一班用于上线前测试
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client spark-examples_2.12-3.1.3.jar 1004.spark on yarn cluster模式 上线使用,不会再本地打印日志 减少io
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster spark-examples_2.12-3.1.3.jar 100获取yarn程序执行日志 执行成功之后才能获取到
yarn logs -applicationId application_1560967444524_0003hdfs webui
http://node1:50070yarn ui
http://node1:8088