首先看一下我们的示例代码
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
"""
------------------------------------------
Description : TODO:
SourceFile : etl_stream_kafka
Author : zxx
Date : 2024/11/14
-------------------------------------------
"""
if __name__ == '__main__':
os.environ['JAVA_HOME'] = 'D:/bigdata/03-java/java-8/jdk'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/bigdata/04-Hadoop/hadoop/hadoop-3.3.1/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'D:/bigdata/22-spark/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/bigdata/22-spark/Miniconda3/python.exe'
spark = SparkSession.builder.master("local[2]").appName("etl_stream_kafka").config(
"spark.sql.shuffle.partitions", 2).getOrCreate()
# 连接kafka
readDF = spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", "bigdata01:9092") \
.option("subscribe", "topicA") \
.load()
# 使用DSL语句
etlDF = readDF.selectExpr("cast(value as STRING)").filter(F.col("value").contains("success"))
etlDF.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "bigdata01:9092") \
.option("topic", "etlTopic") \
.option("checkpointLocation", "../../datas/kafka_stream") \
.start().awaitTermination()
# 关闭
spark.stop()
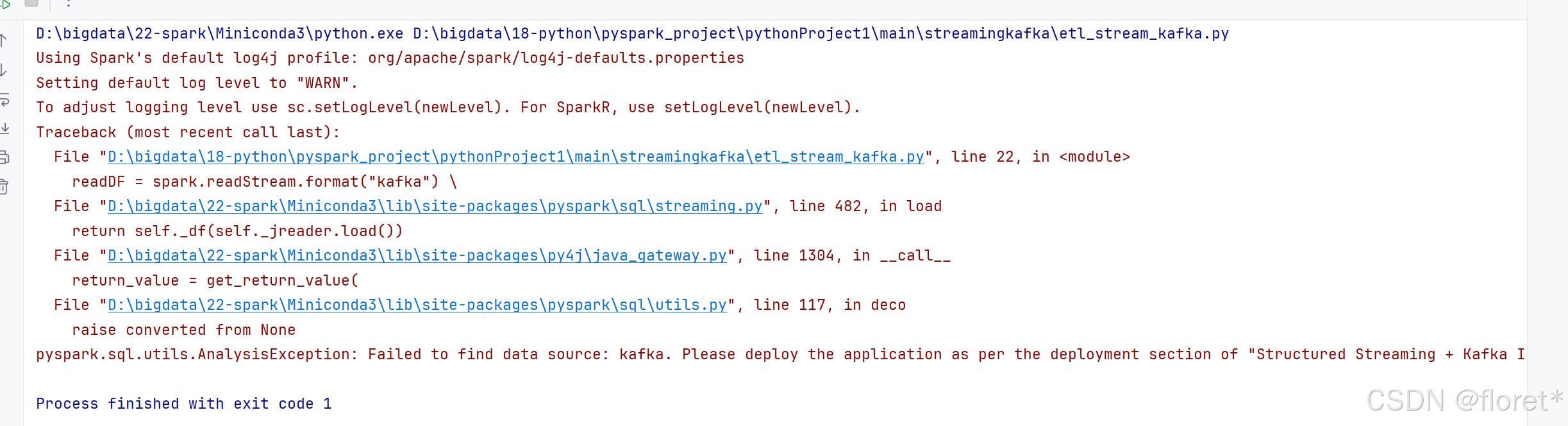
运行发现报错
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Traceback (most recent call last):
File "D:\bigdata\18-python\pyspark_project\pythonProject1\main\streamingkafka\etl_stream_kafka.py", line 22, in <module>
readDF = spark.readStream.format("kafka") \
File "D:\bigdata\22-spark\Miniconda3\lib\site-packages\pyspark\sql\streaming.py", line 482, in load
return self._df(self._jreader.load())
File "D:\bigdata\22-spark\Miniconda3\lib\site-packages\py4j\java_gateway.py", line 1304, in __call__
return_value = get_return_value(
File "D:\bigdata\22-spark\Miniconda3\lib\site-packages\pyspark\sql\utils.py", line 117, in deco
raise converted from None
pyspark.sql.utils.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".
报错 : org.apache.spark.sql.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;
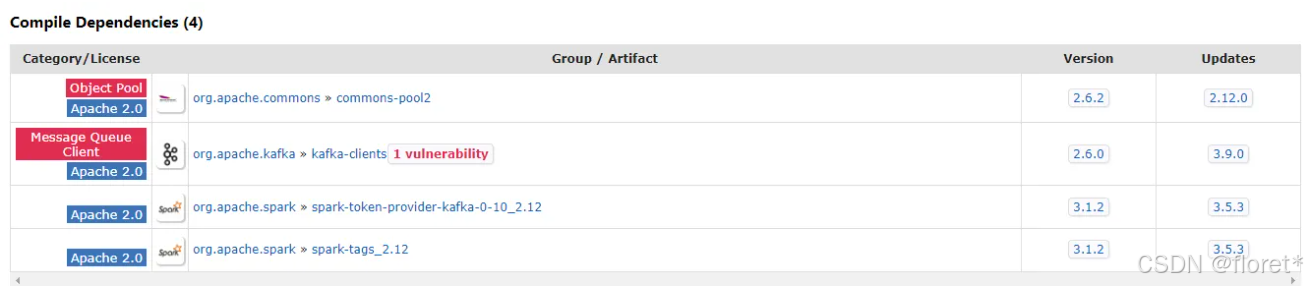
解决:这个是因为缺少了Kafka和Spark的集成包,前往https://mvnrepository.com/artifact/org.apache.spark
下载对应的jar包即可,比如我是SparkSql写入的Kafka,那么我就需要下载Spark-Sql-Kafka.x.x.x.jar
进入网站(已打包放入文章末尾)
找到对应有关spark 和kafka的模块

找到对应的版本 ,这里我用的kafka是3.0版本,下载的是3.1.2版本
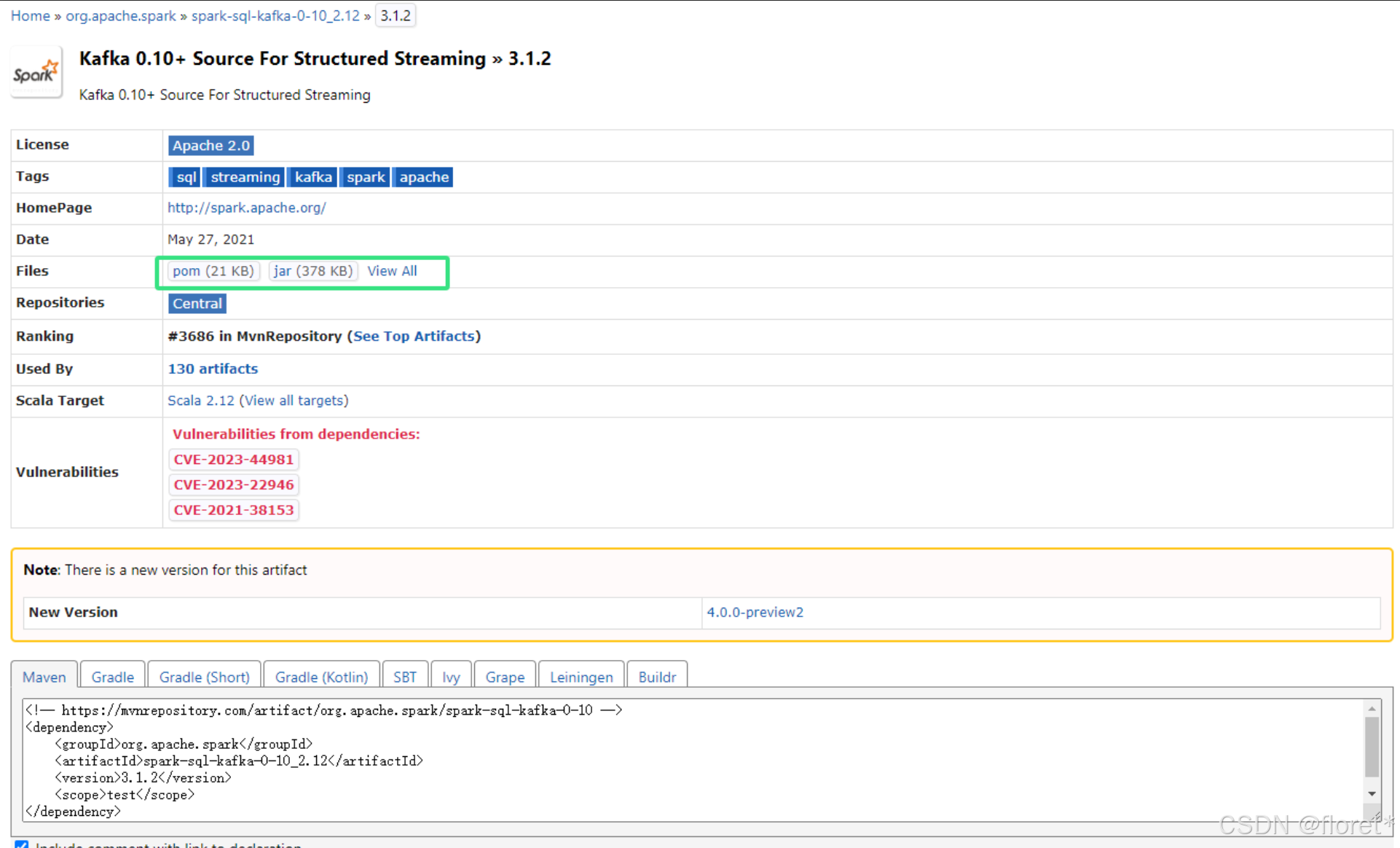
点进去,下载jar包
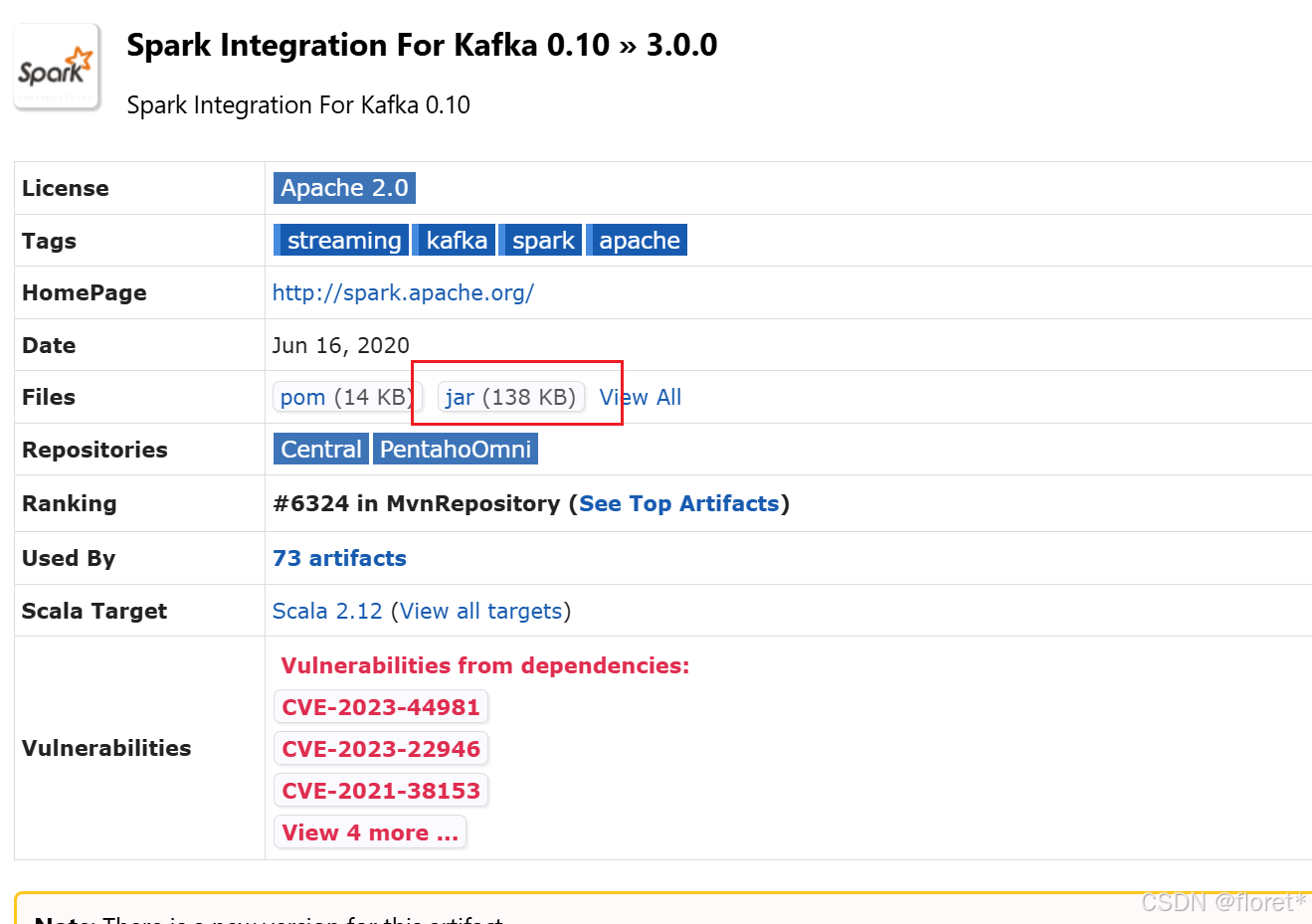
再次运行会发现仍然报错,这是因为jar包之间的依赖关系,从刚才下载的界面下面再下载有关的jar包
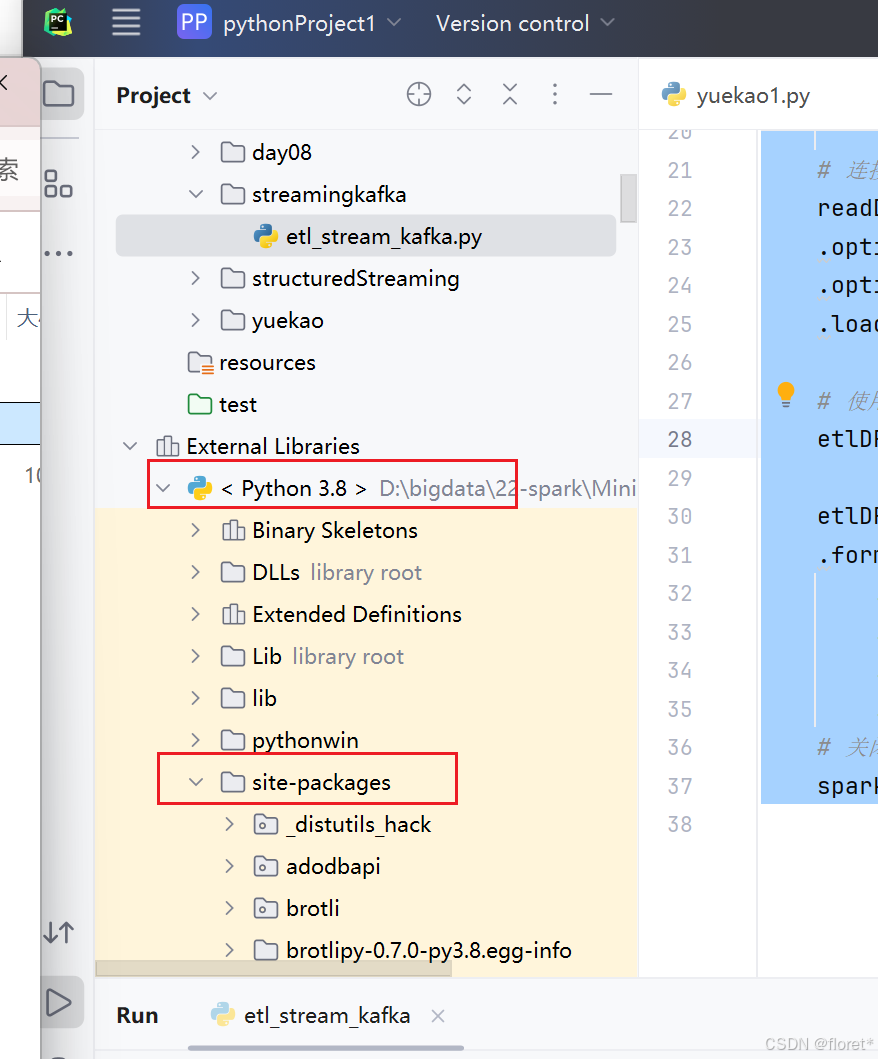
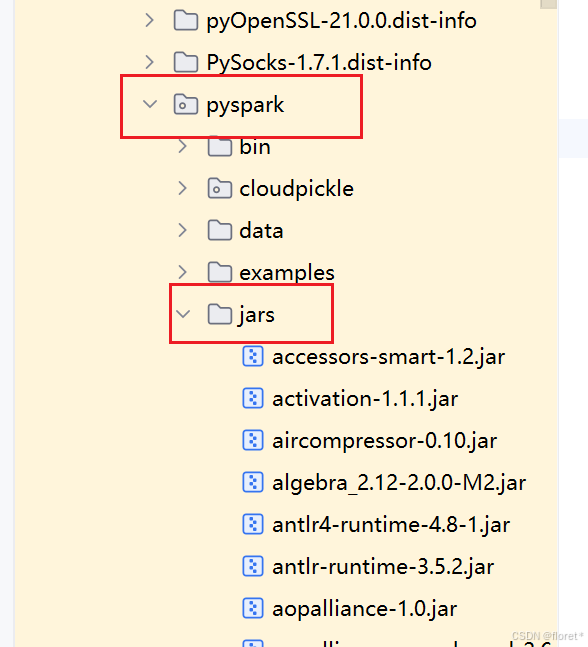
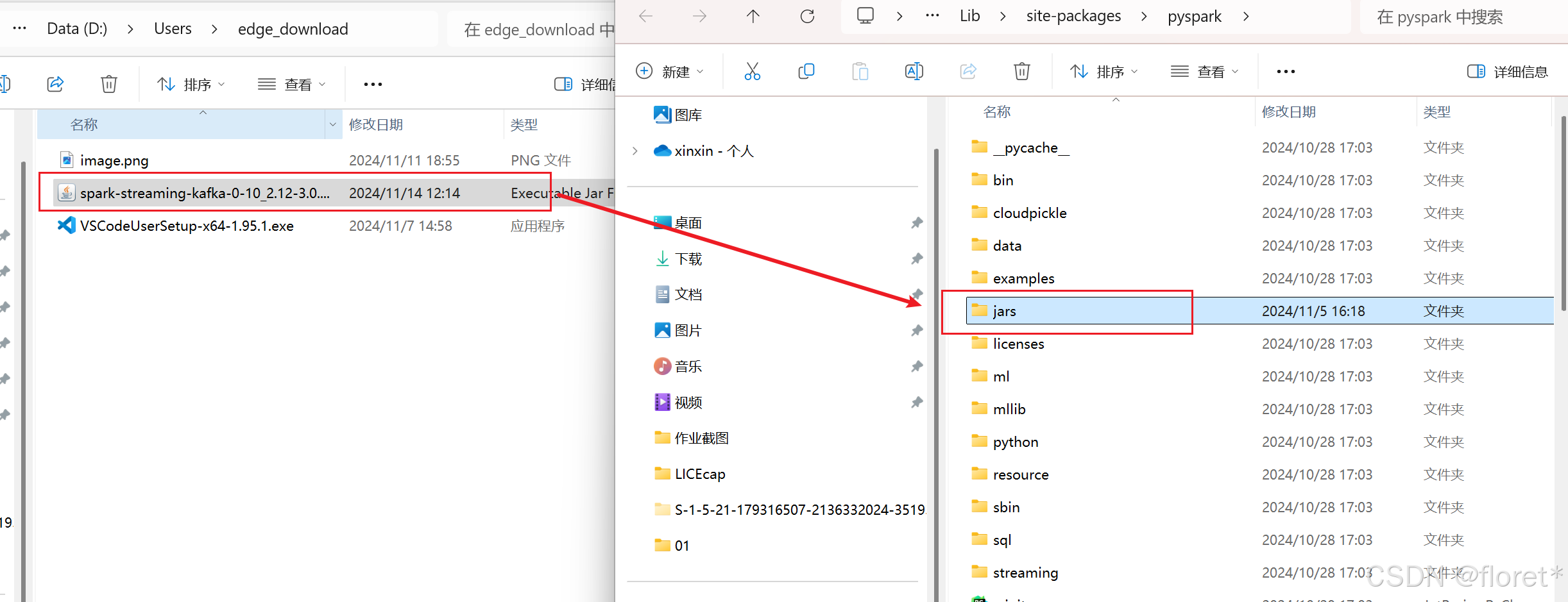
再次运行即可
jar包下载链接