-
寻找数据真实接口
-
请求网页
-
解析网页
-
通过循环,爬取所有页面的评论数据
寻找数据真实接口
打开京东商品网址(https://item.jd.com/100009464799.html) 查看商品评价。我们点击评论翻页,发现网址未发生变化,说明该网页是动态网页。
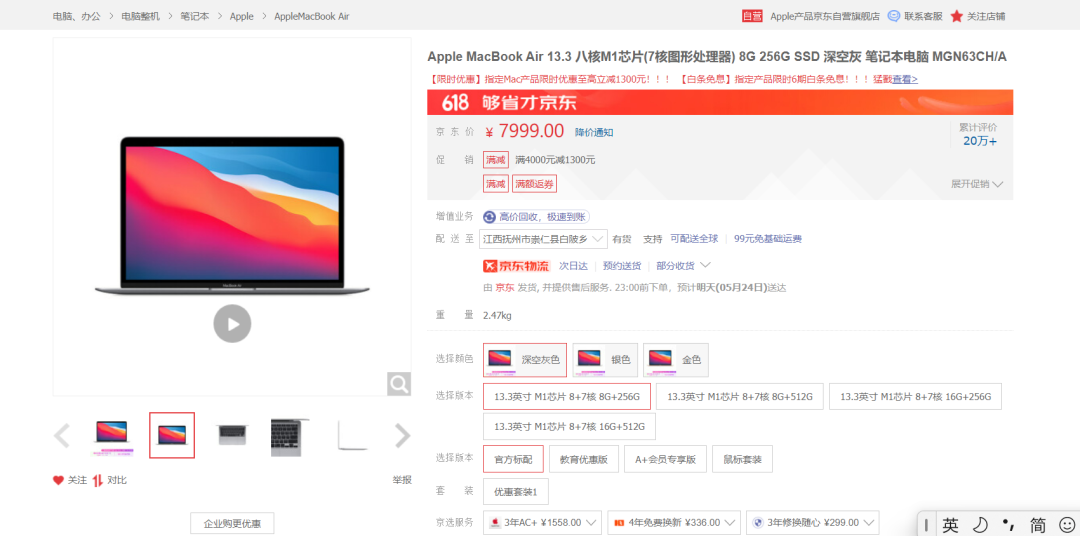
我们在浏览器右键点击“检查”,,随后点击“Network”,刷新一下,在搜索框中输入”评论“,最终找到网址(url)。我们点击Preview,发现了我们需要找的信息。

请求网页
使用requests请求数据库,请求方法是get。

我们查看Headers发现请求方法为get请求,查看Payload并点击,即为get请求参数,完整代码如下所示。
import requests import pandas as pd items=[] header = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.4031 SLBChan/105'} url=f'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1684832645932&loginType=3&uuid=122270672.2081861737.1683857907.1684829964.1684832583.3&productId=100009464799&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1&bbtf=1&shield=' response= requests.get(url=url,headers=header)
解析网页
由于网页返回的是json格式数据,获取我们所需要的评论内容、评论时间,我们通过字典访问即可。


先嵌入字典解析库,通过访问字典,一层一层将数据提取到一页的部分信息,编辑代码。
json=response.json() data=json['comments'] for t in data: content =t['content'] time =t['creationTime']
通过循环,爬取所有页面的评论数据
翻页爬取的关键是找到真实地址的“翻页”规律。我们分别点击第1页、第2页、第3页,发现不同页码的除了page参数不一致,其余相同。第1页的“page”是1,第2页的“page”是2,第2页的“page”是2,以此类推。 我们嵌套一个For循环,并通过pandas存储数据。运行代码让其自动爬取其他页面的评论信息,并储存t.xlsx的文件中。 所有代码如下:
import requests import pandas as pd items=[] for i in range(1,20): header = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.4031 SLBChan/105'} url=f'https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1684832645932&loginType=3&uuid=122270672.2081861737.1683857907.1684829964.1684832583.3&productId=100009464799&score=0&sortType=5&page={i}&pageSize=10&isShadowSku=0&rid=0&fold=1&bbtf=1&shield=' response= requests.get(url=url,headers=header) json=response.json() data=json['comments'] for t in data: content =t['content'] time =t['creationTime'] item=[content,time] items.append(item) df = pd.DataFrame(items,columns=['评论内容','发布时间']) df.to_excel(r'C:\Users\蓝胖子\Desktop\t.xlsx',encoding='utf_8_sig')
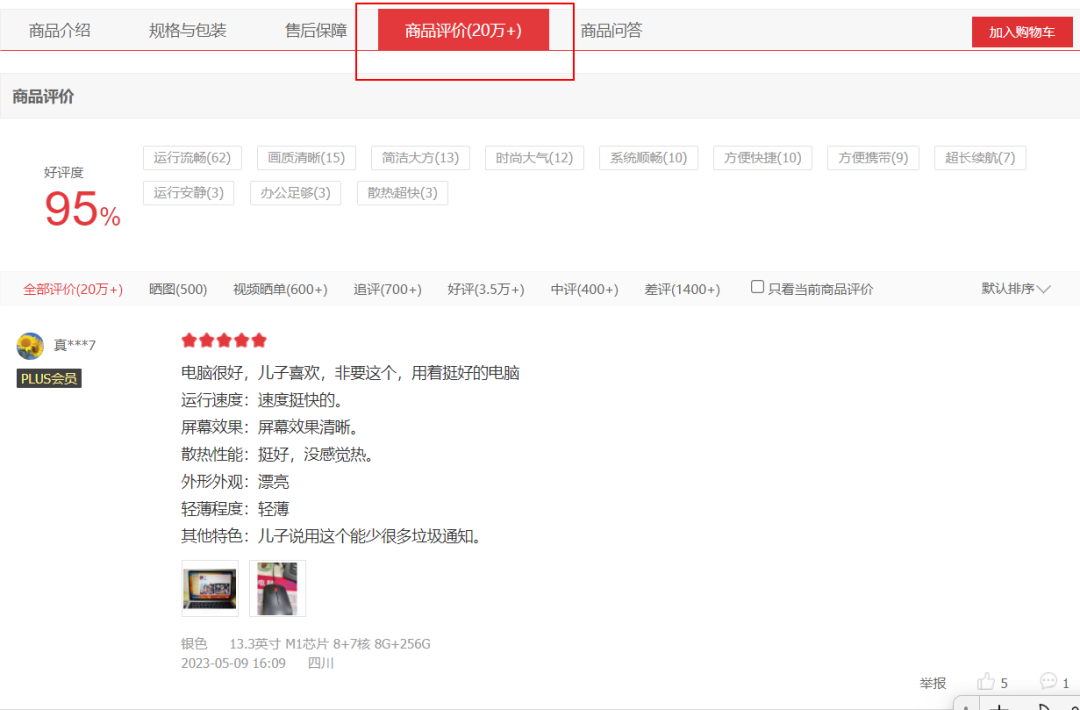
最后,得到爬取的数据结果如下:

以上就是“Python爬取京东商品评论”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
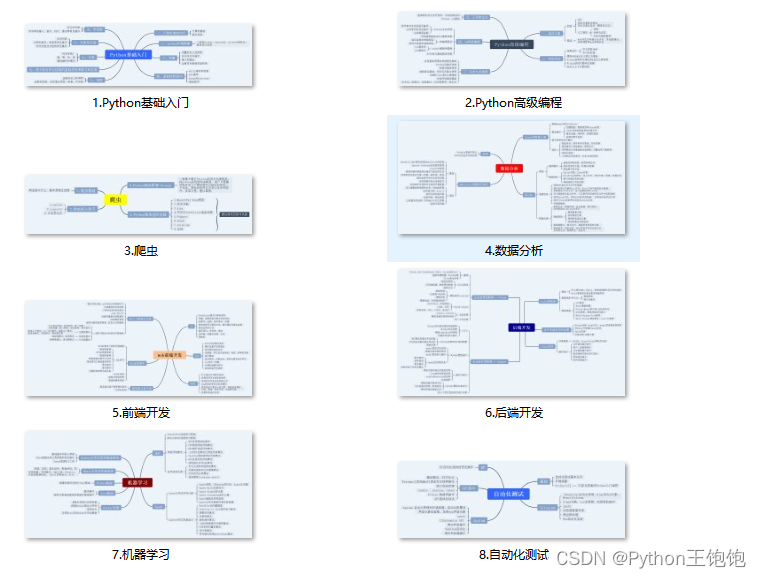
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
