前言
今天给大家分享一个特别强大的Stable]'Diffusion插件:EasyPhoto,这个插件一直在迭代,从最开始的AI写真,然后是AI视频,到最近的AI换装,能力一直在持续增强。
这个插件的基础能力是Lora训练,只需要5-20张特定人物或者场景的照片,不需要对图片进行任何格式化和打标的处理,也不需要理解各种复杂的参数,就可以生成一个独特的Lora模型;然后基于这个模型,我们就可以生成特定形象的照片、视频,可以文生图(视频),也可以图生图(视频)。
下面是我的效果展示,人物形象来自寡姐,最左边这张是原图,右边两张是生成的图片。效果还不错,最有特色的就是寡姐的这个小鼻子,模仿的惟妙惟肖。

安装插件
进入Stable DiffusionWebUI的插件管理页面,选择“从网址安装”,输入插件地址,点击“安装”即可。
插件获取方式:参考文末

但是大家要考虑下硬盘空间,最好准备20G的空闲硬盘空间。
安装成功之后,重启WebUI,就能在一级菜单中看到EasyPhoto了。

训练Lora
如下图所示,首先上传5-20张用来训练模型的图片,可以去百度图片上下载;然后需要一个基础模型,最好是和训练图片的风格搭配的,训练人物用默认的这个也可以,它会自动下载模型;最后点击“StartTraning”开始训练,这个过程需要的时间可能比较长,可能需要20分钟,请耐心等待。其它参数使用默认的即可,当然如果你想调整,可以看我这篇文章:LoRA模型训练

训练成功之后,会显示:The training has been completed.

除了训练人物,我们还可以训练场景,方便生成时让人物出现在不同的场景中,比如朋克场景、室内场景、圣诞场景、新年场景等,训练场景时同样需要包含人物在训练图片中,只不过换成了场景不怎么变、人物多变。
生成图片
我们首先来看下图生图,这其实是个AI写真的功能,可以换掉图片中的人脸。我们可以使用插件自带的模版,也可以上传你认可的照片,这里选择一张肖像照片。

下边还有一些生成参数:
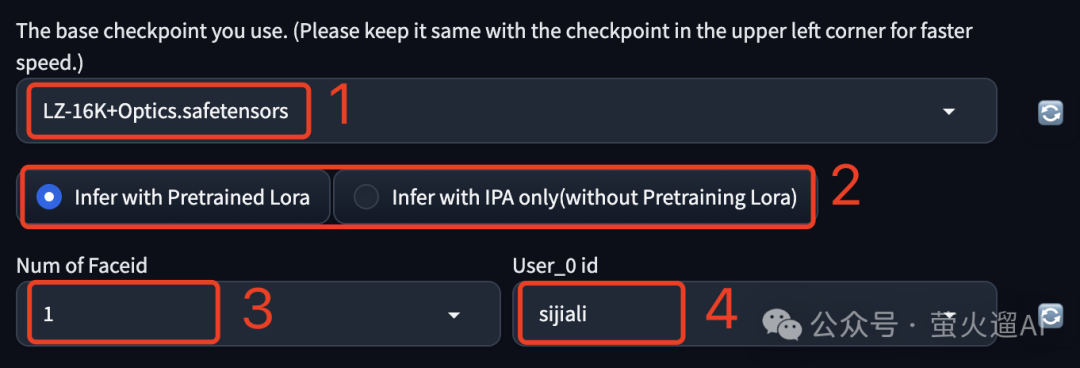
- 一个生成图片用的大模型,需要和上边选择的参考图片风格保持一致。
- 基于预训练的大模型(Infer with Pretrained Lora)、基于IP-Adapter ControlNet(Infer with IPA only,这种方法不需要预训练的Lora模型)。
如果选择“Infer with Pretrained Lora”,需要设置下边的参数:
- 如果图片中有多张脸需要替换,可以使用“Num of Faceid”来指定要替换的脸的数量,最多替换5张。
- “User_x id”用来选择上一步训练的Lora模型。
如果选择“Infer with IPAonly”,则需要上传一张照片,生成的图片中会使用这张照片中的人脸,我们还可以设置ControlNet的权重,设置的权重越高,生成图片中的人脸越靠近这里上传的照片。
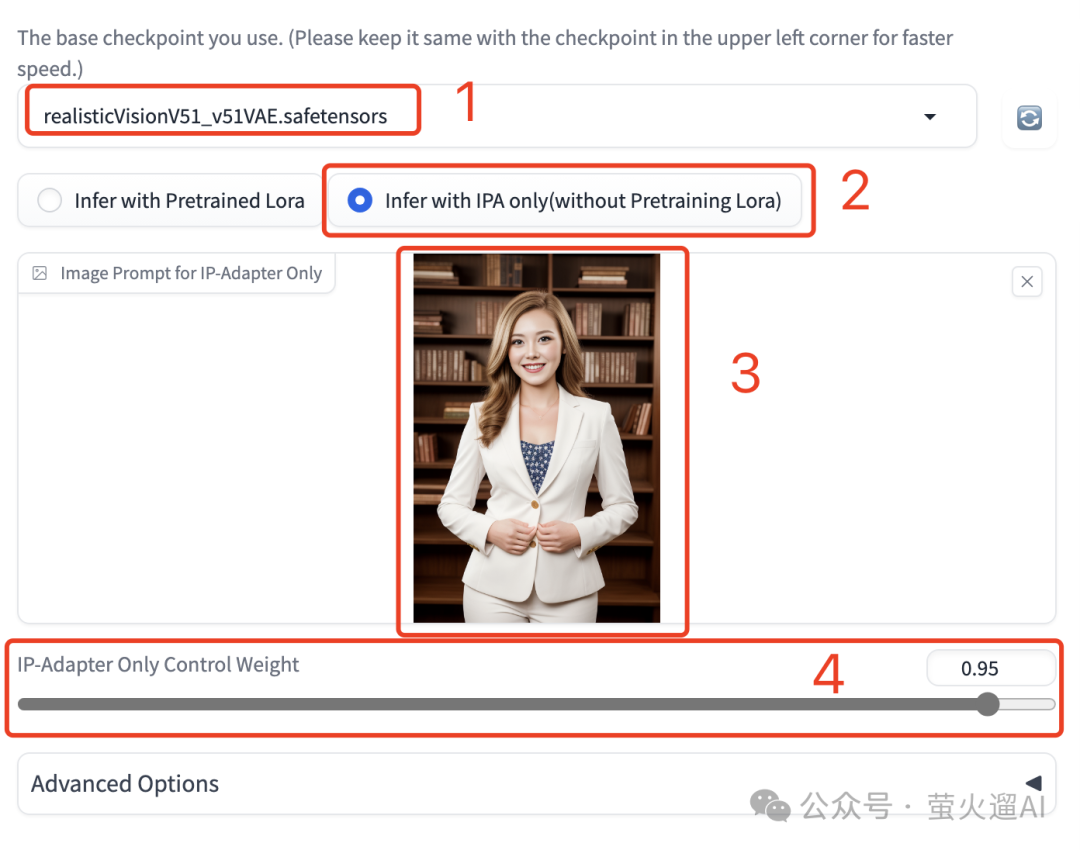
使用预训练模型生成图片的效果如下图所示:

文生图和图生图的参数有些差别,如下图所示,依次是:提示词,选择场景Lora(插件会自带一些,我们也可以自己训练场景Lora),图片的分辨率,姿势控制方式、生成图片用的基础模型、人脸的来源(预训练Lora、IP-Adapter控制器)。

生成视频
EasyPhoto生成视频使用的是AnimateDiff,支持文生图、图生图和视频生视频。
先看视频生成效果:


文生视频
的一些参数设置:既然是文生视频,这里需要一些提示词,另外还可以通过上传一个视频来控制生成视频的的人物动作。注意EasyPhoto中生成视频时必须使用上文提到的预训练Lora模型。
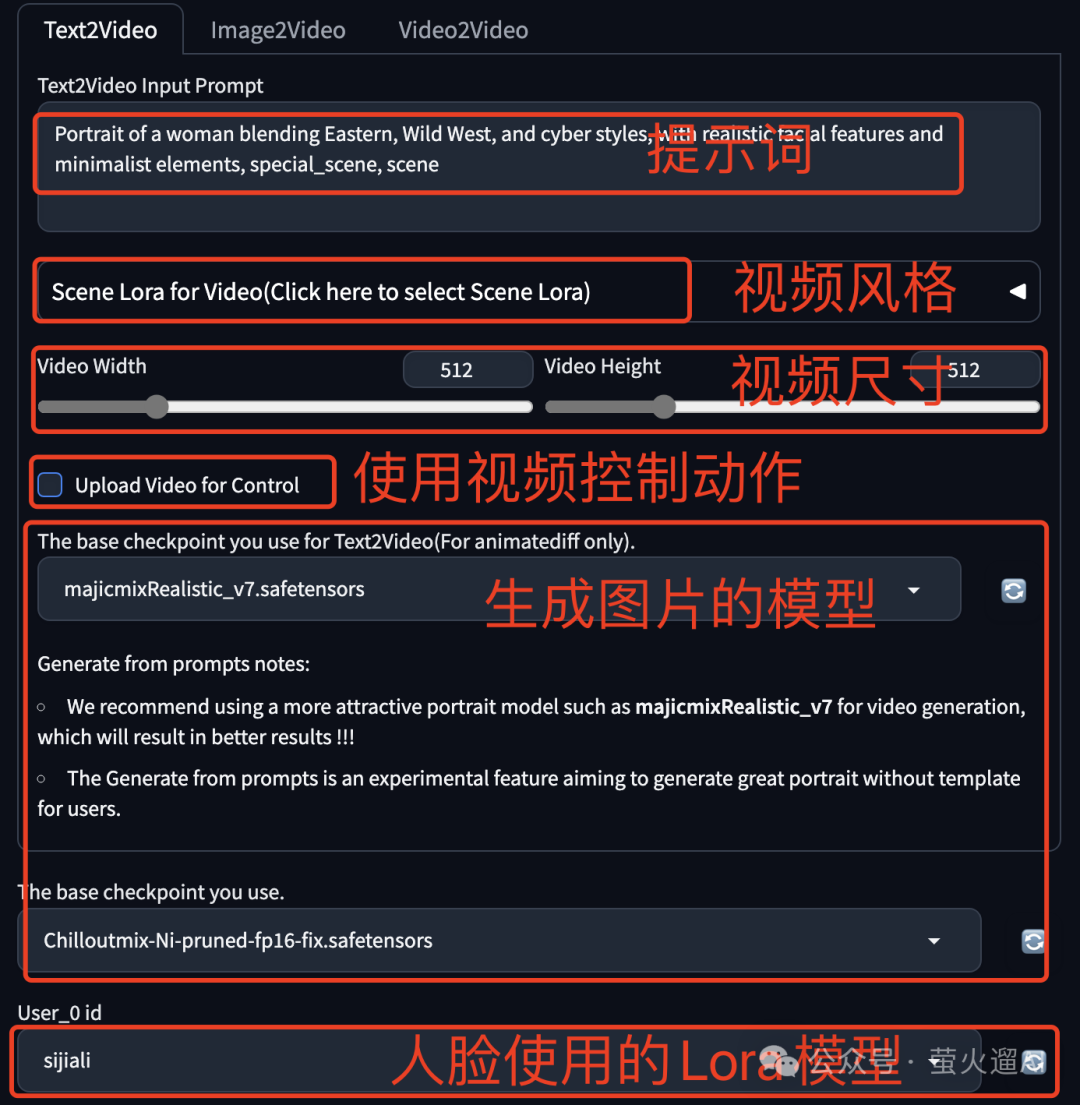
点开高级设置,还有一些对生成视频影响比较大的参数。
Prompt 提示词:就是Stable Diffusion生成图片的提示词,可以用来控制一些图片效果。
视频帧数:Video Max num of frames 是视频的全部帧数,Video Max fps 是每秒帧数,Video Save as
是保存成gif还是mp4。
Lora模型的权重:Video Lora Weights of User id 是生成图片时Lora模型的权重。

图生视频
的一些设置:参考图可以基于一张图片,也可以从一张图片过渡到另一张图片。提示词要写一下,最好是描述动作的。图片重绘度要设置的小一点,避免生成图片变化太多。

下面是官方给出的一个图片过渡的效果展示:

视频生成视频 的设置:这个设置比较简单,上传一个参考视频,生成的视频会使用此视频中的动作;选择合适的生图模型,最后选择之前预训练的Lora模型。

换装
点击“Virtual Try On”进入换装模块。
首先在这里上传一张要换装的图片,用画笔涂抹要换装的区域,或者上传一张模版图片。
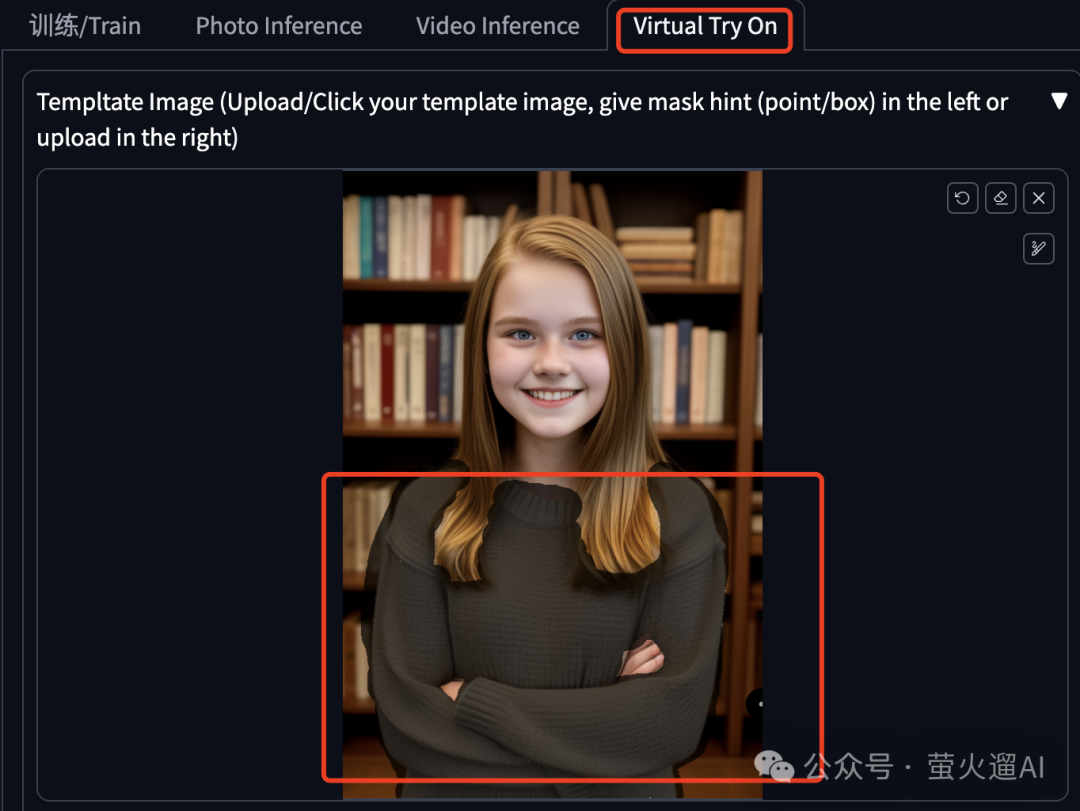
然后在这里选择或者上传要使用的服装。

这个换装的效果不是特别稳定,如果效果不太好,可以多试几次。
资源下载
我都给大家整理好了,有需要可以扫描下方二维码,免费获取

Stable Diffusion 最强提示词手册
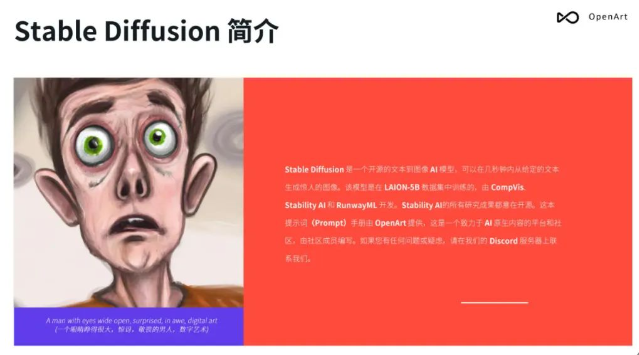
- Stable Diffusion介绍
- OpenArt介绍
- 提示词(Prompt) 工程介绍
- …
第一章、提示词格式
- 提问引导
- 示例
- 单词的顺序
- …

有需要的朋友,可以点击下方卡片免费领取!
第二章、修饰词(Modifiers)
- Photography/摄影
- Art Mediums/艺术媒介
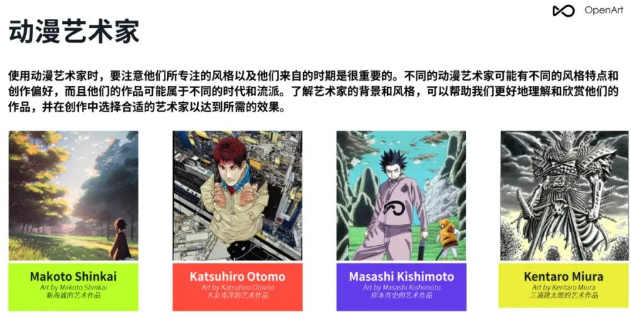
- Artists/艺术家
- Illustration/插图
- Emotions/情感
- Aesthetics/美学
- …

第三章、 Magic words(咒语)
- Highly detailed/高细节
- Professional/专业
- Vivid Colors/鲜艳的颜色
- Bokeh/背景虚化
- Sketch vs Painting/素描 vs 绘画
- …

第四章、Stable Diffusion参数
- Resolution/分辨率
- CFC/提词相关性
- Step count/步数
- Seed/种子
- Sampler/采样
- 反向提示词(Prompt)

第5章 img2img(图生图),in/outpainting(扩展/重绘)
- 将草图转化为专业艺术作品
- 风格转换
- lmg2lmg 变体
- Img2lmg+多个AI问题
- lmg2lmg 低强度变体
- 重绘
- 扩展/裁剪
- …
第6章 重要提示
- 词语的顺序和词语本身一样重要
- 不要忘记常规工具
- 反向提示词(Prompt)
- …
第7章 OpenArt展示
- 提示词 (Prompt)
- 案例展示
- …
篇幅有限,这里就不一一展示了,有需要的朋友可以点击下方的卡片进行领取!
