
一、常见元素定位
定位器是 Playwright 自动等待和重试能力的核心部分。简而言之,定位器代表了一种随时在页面上查找元素的方法,以下是常用的内置定位器。
1、按角色定位
按显式和隐式可访问性属性进行定位语法:page.get_by_role() Dom结构示例1:

示例代码1:
page.get_by_role("button", name="Sign in").click()
说明:按名称为“Sign in”button的角色找到元素。Dom结构示例2:
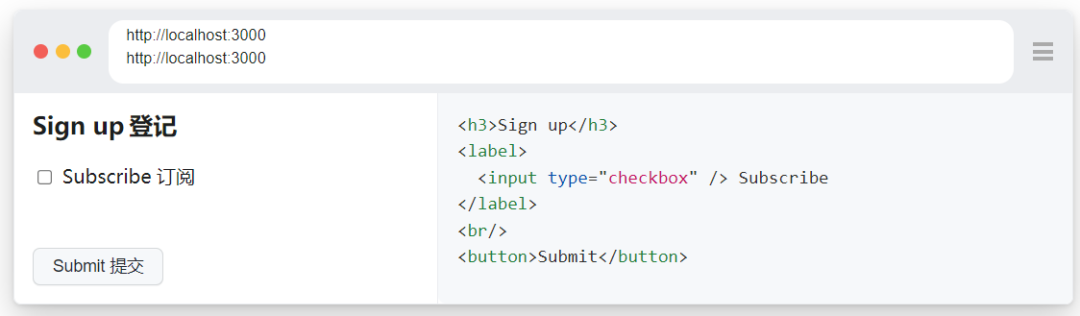
示例代码2
expect(page.get_by_role("heading", name="Sign up")).to_be_visible()
page.get_by_role("checkbox", name="Subscribe").check()
page.get_by_role("button", name=re.compile("submit", re.IGNORECASE)).click()
说明:
-
角色定位器包括按钮、复选框、标题、链接、列表、表格等,并遵循 ARIA 角色、ARIA 属性和可访问名称的 W3C 规范。请注意,许多 html 元素(如)都具有隐式定义的角色,该角色可由角色定位器识别。
-
建议优先考虑角色定位器来定位元素,因为这是最接近用户和辅助技术感知页面的方式。
page.get_by_label()通过关联标签的文本查找表单控件。
2、按标签定位
通过关联标签的文本查找表单控件语法:page.get_by_label() Dom结构示例:

示例代码:
page.get_by_label("Password").fill("secret")
3、按占位符定位
语法:page.get_by_placeholder()Dom结构示例:

示例代码:
page.get_by_placeholder("[email protected]").fill("[email protected]")
4、通过文本定位
按占位符查找输入语法:page.get_by_text()Dom结构示例:

示例代码:
# 可以通过元素包含的文本找到该元素
page.get_by_text("Welcome, John")
# 设置完全匹配
page.get_by_text("Welcome, John", exact=True)
# 正则表达式匹配
page.get_by_text(re.compile("welcome, john", re.IGNORECASE))
说明:
-
按文本匹配始终会规范化空格,即使完全匹配也是如此。例如,它将多个空格转换为一个空格,将换行符转换为空格,并忽略前导和尾随空格。
-
建议使用文本定位器来查找非交互式元素,如 div、span、p 等。对于button、a、input等交互式元素,请使用角色定位器。
5、通过替代文本定位
通过其文本替代来定位元素(通常是图像),所有图片都应具有描述图像的 alt 属性。可以使用page.get_by_alt_text() 根据替代文本查找图片。语法:page.get_by_alt_text()Dom结构示例:
示例代码:
page.get_by_alt_text("playwright logo").click()
说明:当元素支持替代文本(如 img 和 area 元素)时,建议使用此定位器
6、按标题定位
按元素的 title 属性查找元素语法:page.get_by_title()Dom结构示例:

示例代码:
expect(page.get_by_title("Issues count")).to_have_text("25 issues")
说明:当元素具有 title 属性时,建议使用此定位器7、按测试 ID 查找根据元素data-testid 属性来定位元素(可以配置其他属性)语法:page.get_by_title()Dom结构示例:

示例代码:
page.get_by_test_id("directions").click()
8、设置自定义测试 ID 属性
默认情况下,page.get_by_test_id() 将根据 data-testid 属性查找元素,但您可以在测试配置中或通过调用 selectors.set_test_id_attribute() 来配置它。将测试 ID 设置为对测试使用自定义数据属性,示例代码:
playwright.selectors.set_test_id_attribute("data-pw")
Dom结构:
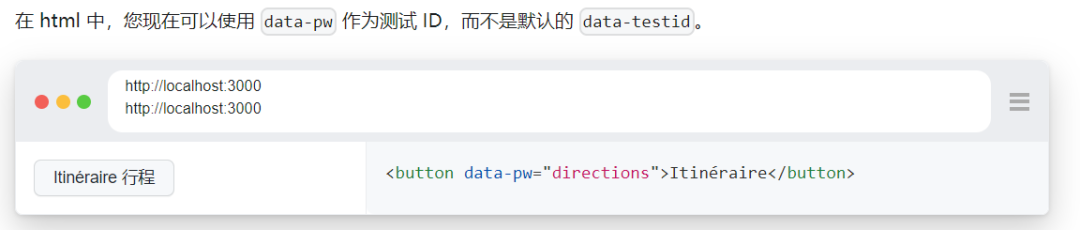
然后像往常一样找到该元素,示例代码如下:
page.get_by_test_id("directions").click()
9、通过 CSS 或 XPath 定位
如果绝对必须使用 CSS 或 XPath 定位器,则可以使用 page.locator() 创建一个定位器,该定位器采用一个选择器来描述如何在页面中查找元素。Playwright 支持 CSS 和 XPath 选择器,如果省略 css= 或 xpath= 前缀,则会自动检测它们。示例代码:
page.locator("css=button").click()
page.locator("xpath=//button").click()
page.locator("button").click()
page.locator("//button").click()
说明:
-
XPath 和 CSS 选择器可以绑定到 DOM 结构或实现。当 DOM 结构更改时,这些选择器可能会中断。
-
不建议使用 CSS 和 XPath,因为 DOM 经常会更改,从而导致无法复原的测试。相反,请尝试提供一个接近用户感知页面的定位器,例如角色定位器,或者使用测试 ID 定义显式测试协定。
二、在 Shadow DOM 中定位
1、什么是Shadow DOM?
Shadow DOM 是 Web Components 技术的一部分,它提供了一种将 HTML 结构、样式和行为封装在一个独立的、封闭的 DOM 中的机制。以下是一个使用 Shadow DOM 的例子,该例子展示了如何创建一个简单的自定义组件,并将内容、样式封装在 Shadow DOM 中。示例代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Shadow DOM Example</title>
<style>
/* 外部样式,不会影响 Shadow DOM 内部 */
.container {
font-size: 20px;
color: red;
}
</style>
</head>
<body>
<div id="hostElement" class="container">Shadow Host (这里不会显示 Shadow DOM 的内容)</div>
<script>
// 自定义元素定义及 Shadow DOM 创建
class MyCustomElement extends HTMLElement {
constructor() {
super();
// 创建 Shadow Root
const shadowRoot = this.attachShadow({ mode: 'open' });
// Shadow DOM 内部样式和内容
shadowRoot.innerHTML = `
<style>
.shadow-content {
font-size: 16px;
color: blue;
}
</style>
<div class="shadow-content">This is inside the Shadow DOM.</div>
`;
}
}
// 注册自定义元素
customElements.define('my-custom-element', MyCustomElement);
// 将自定义元素添加到文档中
const customElement = document.createElement('my-custom-element');
document.body.appendChild(customElement);
// 注意:在实际应用中,你可能会将自定义元素直接写在 HTML 中,如:<my-custom-element></my-custom-element>
// 而不是通过 JavaScript 动态创建和添加。
</script>
</body>
</html>
dom结构:
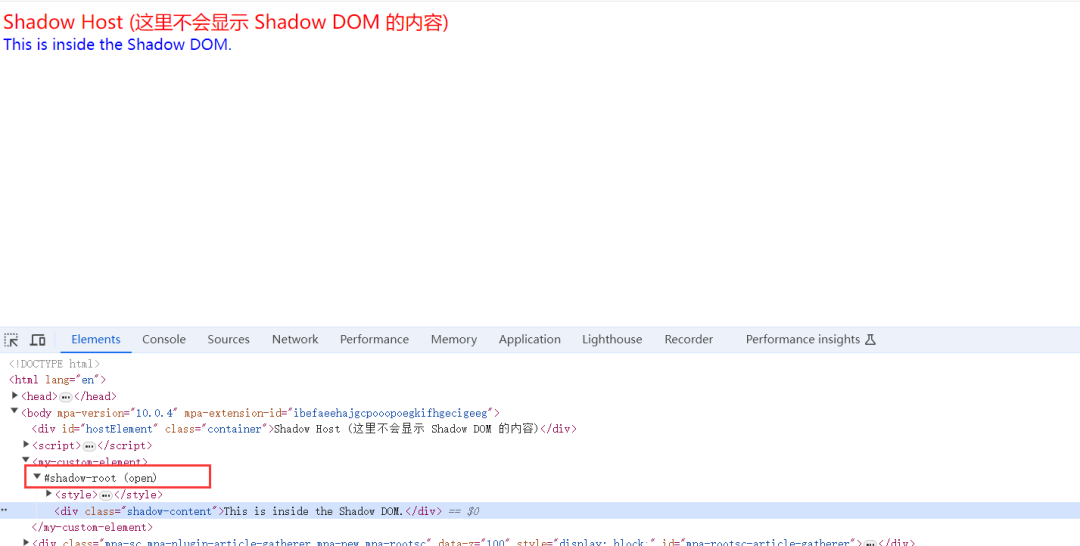
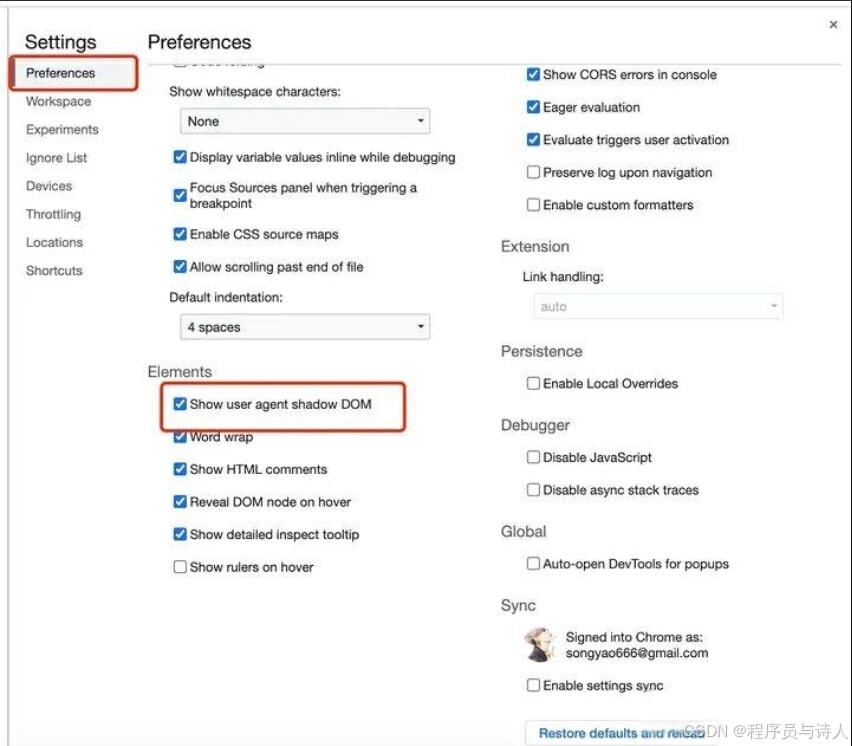
2、如何查看Shadow DOM
首先打开浏览器控制台的设置选项

然后再找到Preference -> Elements,把show user anent shadow dom勾上
这时候我们再来看一下此时的dom元素发生了什么变化
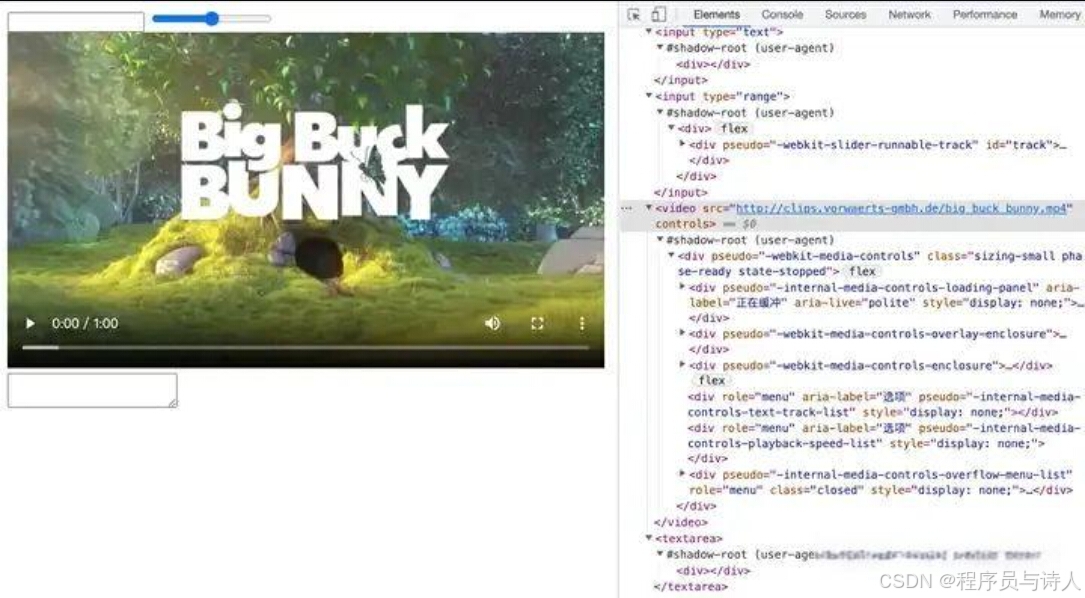
我们会发现这些标签内部都大有乾坤,在这些标签下面都多了一个shadow root,在它里面才是这些标签的真实布局。
3、在 Shadow DOM 中定位
默认情况下,Playwright 中的所有定位器都使用 Shadow DOM 中的元素。例外情况包括:
-
通过 XPath 定位不会刺穿阴影根
-
不支持闭合模式阴影根
要定位,使用page.get_by_text("")或page.locator("", has_text="")都可以,要确保
包含文本“This is inside the Shadow DOM.”,示例代码如下:
page.goto("http://localhost:8080/shadowDOM.html")
expect(page.get_by_text("This is inside the Shadow DOM.")).to_contain_text("Shadow DOM")
expect(page.locator("div", has_text="This is inside the Shadow DOM.")).to_contain_text("This is inside")
三、筛选定位
1、dom结构
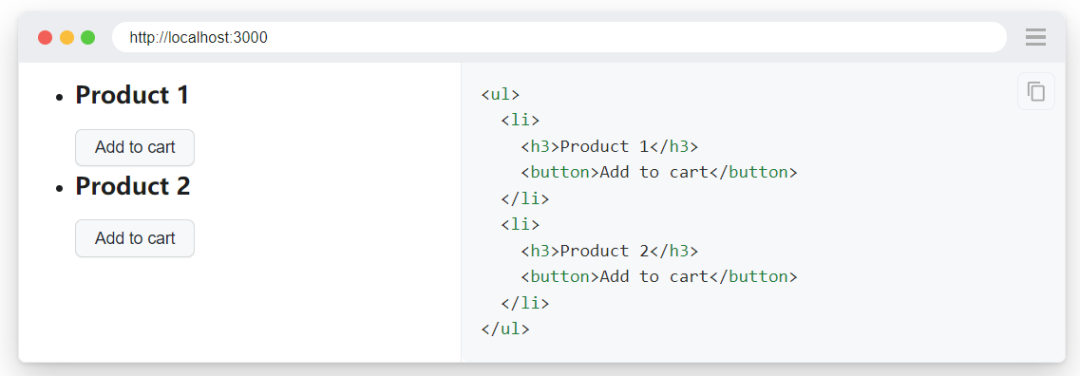
2、按文本筛选定位
可以使用 locator.filter() 方法按文本过滤定位器。它将在不区分大小写的情况下搜索元素内部的某个特定字符串,可能在后代元素中。示例代码:
page.get_by_role("listitem").filter(has_text="Product 2").get_by_role(
"button", name="Add to cart"
).click()
#传递正则表达式。
page.get_by_role("listitem").filter(has_text=re.compile("Product 2")).get_by_role(
"button", name="Add to cart"
).click()
2.1、按没有文本进行筛选
expect(page.get_by_role("listitem").filter(has_not_text="Out of stock")).to_have_count(2)
2.2、按子项/后代筛选
定位器支持仅选择具有或没有与另一个定位器匹配的后代的元素的选项。因此,您可以按任何其他定位器进行过滤,例如 locator.get_by_role()、locator.get_by_test_id()、locator.get_by_text() 等。示例代码:
page.get_by_role("listitem").filter(
has=page.get_by_role("heading", name="Product 2")
).get_by_role("button", name="Add to cart").click()
断言产品卡,确保只有一个,示例代码如下:
expect(
page.get_by_role("listitem").filter(
has=page.get_by_role("heading", name="Product 2")
)
).to_have_count(1)
过滤定位器必须相对于原始定位器,并且从原始定位器匹配项(而不是文档根节点)开始查询。
2.3、按没有子/后代进行筛选
通过内部没有匹配的元素进行过滤,示例代码:
expect(
page.get_by_role("listitem").filter(
has_not=page.get_by_role("heading", name="Product 2")
)
).to_have_count(1)
注意,内部定位器是从外部定位器开始匹配的,而不是从文档根目节点开始匹配的。
四、使用约束条件定位
1、在定位器内匹配
就先定位元素,再去定位子节点元素,以将搜索范围缩小到页面的特定部分。示例代码
product = page.get_by_role("listitem").filter(has_text="Product 2")
product.get_by_role("button", name="Add to cart").click()
也可以将两个元素定位组合在一起使用,示例代码如下:
save_button = page.get_by_role("button", name="Save")
# ...
dialog = page.get_by_test_id("settings-dialog")
dialog.locator(save_button).click()
2、使用and条件匹配
方法 locator.and_() 通过匹配其他定位器来缩小现有定位器的范围,可以理解为xpath的and使用方法,都是定位一个元素,示例代码如下:
page.get_by_role("link").and_(page.get_by_text("新闻")).click()
3、使用or条件匹配
如果您想定位两个或多个元素中的一个,但不知道会是哪一个,请使用 locator.or_() 创建与所有备选项匹配的定位器。示例代码如下:
def test_navigationCnblogs(page: Page):
page.goto("https://www.baidu.com/")
login=page.get_by_role("link").and_(page.get_by_text("登录"))
message=page.get_by_text("短信登录")
expect(message.or_(login).first).to_be_visible()
if (login.is_visible()):
login.click()
message.click()
4、仅匹配可见元素
考虑一个有两个按钮的页面,第一个不可见,第二个可见,这时候就可以进行约束,示例代码如下:
page.locator("button").locator("visible=true").click()
五、列表元素操作
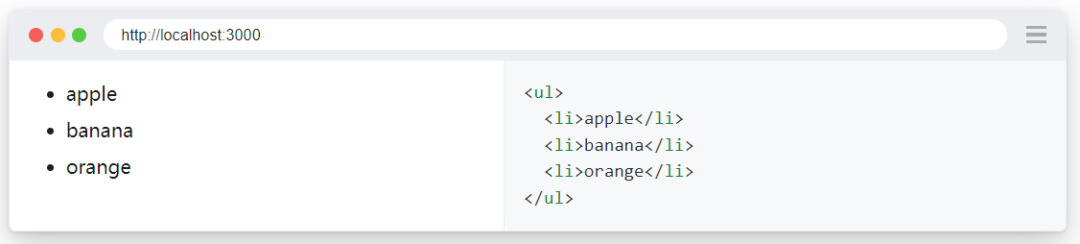
dom结构:
1、使用 count 断言
使用 count 断言确保列表有 3 个项目,示例代码如下:
expect(page.get_by_role("listitem")).to_have_count(3)
2、断言列表中的所有文本
断言定位器以查找列表中的所有文本,示例代码如下:
expect(page.get_by_role("listitem")).to_have_text(["apple", "banana", "orange"])
3、定位某个列表元素
使用 page.get_by_text() 方法按文本内容在列表中查找元素,示例代码如下:
page.get_by_text("orange").click()
也可以使用 locator.filter() 查找列表中的特定元素,示例代码如下:
page.get_by_role("listitem").filter(has_text="orange").click()
4、按下标定位指定元素
您有一个相同元素的列表,并且区分它们的唯一方法是顺序,则可以使用 locator.first、locator.last 或 locator.nth() 从列表中选择特定元素。
banana = page.get_by_role("listitem").nth(1)
expect(banana).to_have_text('banana')
5、链接筛选器定位元素
当您有具有各种相似性的元素时,使用 locator.filter() 方法选择正确的元素。还可以链接多个筛选器以缩小选择范,就是层级定位,个人感觉。DOM 结构
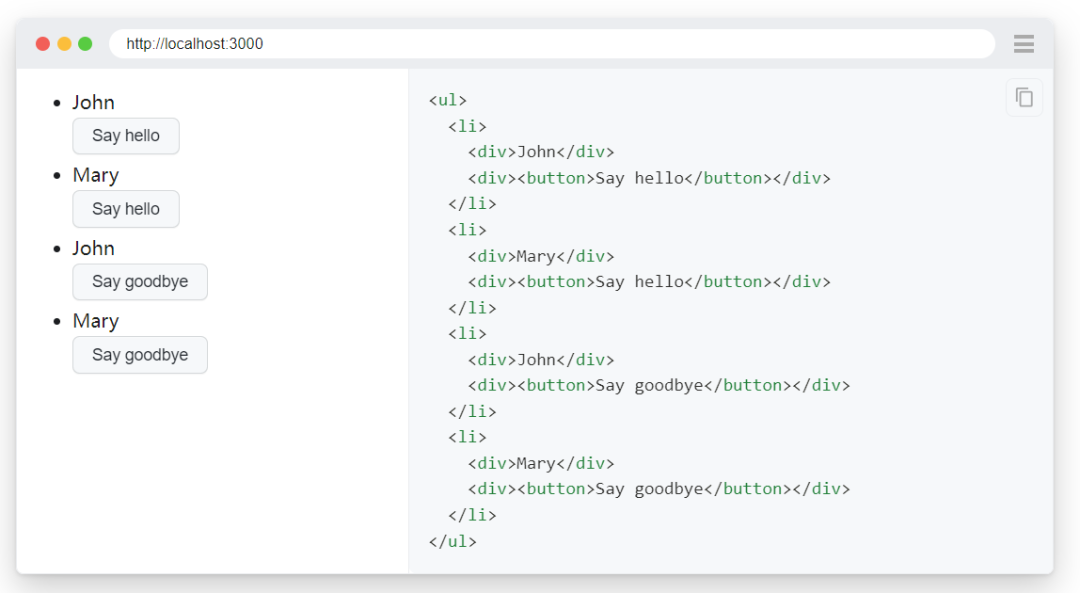
示例代码
row_locator = page.get_by_role("listitem")
row_locator.filter(has_text="Mary").filter(
has=page.get_by_role("button", name="Say goodbye")
).screenshot(path="screenshot.png")
6、遍历每个元素
对列表中的每个元素执行操作,示例代码如下:
for row in page.get_by_role("listitem").all():
print(row.text_content())
rows = page.get_by_role("listitem")
count = rows.count()
for i in range(count):
print(rows.nth(i).text_content())
7、Evaluate in the page在页面中评估
我觉得这个就是很ES6呀,示例代码如下:
rows = page.get_by_role("listitem")
# 很前端了吧
texts = rows.evaluate_all("list => list.map(element => element.textContent)")
8、检查定位元素的个数
定位元素如果出现定位多个元素,这个就很好用了,可以作为检验是否定位到唯一元素检测,示例代码如下:
print(page.get_by_role("button").count()) #2
