文献基本信息
- 标题:GroupViT: Semantic Segmentation Emerges from Text Supervision
- 作者:Jiarui Xu、Shalini De Mello、Sifei Liu、Wonmin Byeon、Thomas Breuel、Jan Kautz、Xiaolong Wang
- 单位:UC San Diego、NVIDIA
- 会议/期刊:CVPR
- 发表时间:2022年7月18日
- 代码:https://github.com/NVlabs/GroupViT
背景与意义
- LSeg虽然能够实现zero-shot的语义分割,但是训练方式并不是对比学习,没有将文本作为监督信号,因此还是需要有监督的分割图标注进行训练,而且由于语义分割的标注非常麻烦,因此分割领域的数据集都不大,LSeg用的7个数据集加起来可能也就一二十万个样本。
- 如何像CLIP一样,利用到文本来进行自监督训练呢?GroupViT就是语义分割领域像CLIP一样使用文本来自监督训练的代表工作之一。GroupViT通过文本自监督的对比学习来进行语义分割的训练,在推理阶段,可以实现zero-shot的推理。
- GroupViT的核心思想是利用了深度学习之前无监督分割的grouping思想。当时的做法大概是在确定某个中心点之后,不断向外发散,将接近的点都分到一个group中,最终发散完毕,得到分割结果。在GroupViT中的grouping是将ViT中的图像块token进行分配,分配到不同的语义类别token上。

研究方法与创新点
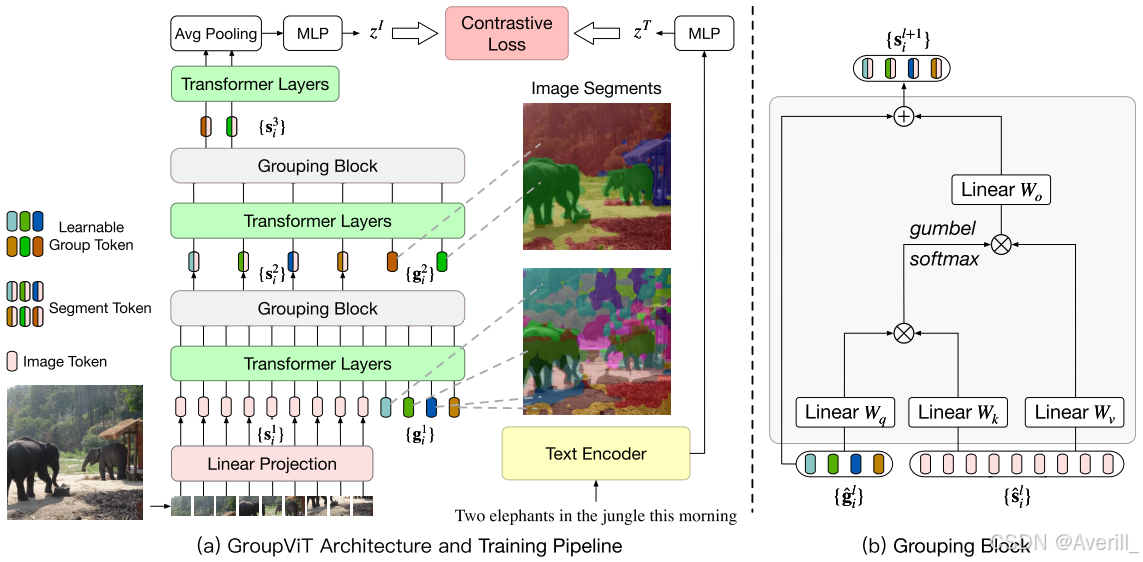
pipeline
训练过程
1. 将输入图像划分成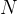
2. 对于两阶段类型的GroupViT:
(a) 在GroupViT的第一阶段:经过Transformer层操作后可以得到64个group token,然后在6层Transformer层后插入grouping块。
(b) 在GroupViT的第二阶段:grouping之后,都会得到8个segment token。
3. 对于一阶段类型的GroupViT:
(a) 在grouping块之前,将64个group token通过MLP-Mixer层映射成8个segment token。
4. 在每个grouping阶段,将图像token和一系列可学习的group token进行concat,一起输入到Transformer层里。
5. 然后grouping块将学到的group token和图像segment token作为输入,通过grouping块更新图像token,利用学到的group token将相似的图像token归并到一起,每经过一个grouping阶段,能够得到更大更少的图像segment。
- 如何归并?通过Gumbel-Softmax计算group token和segment token的相似度矩阵,group token作为查询,它的作用就是看看哪些segment可以归为一组,进行归并。
6. 在最后一个grouping阶段后,在所有的图像segment token上使用Transformer层,对其输出进行平均,并经过一个两层的MLP,获得最终的全局图像表示(最终的这个图像嵌入是所有segment token的平均嵌入),两层的MLP将视觉嵌入向量和文本嵌入向量映射到相同的隐空间。
7. 文本嵌入是最后一个输出token的嵌入。
8. 计算图像嵌入和文本嵌入的相似度(通过点乘),将匹配的图像-文本对作为正样本对,其他不匹配的图像-文本对,作为负样本对。
9. 除了原始的句子标签外,为每个图像生成额外的文本标签。随机从句子中选取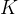
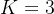
整体结构
- 在ViT基础上设计,使用双编码器结构。
- GroupViT用作图像编码器(ResNet),Transformer用作文本编码器(Transformer)。
- GroupViT有2种类型的结构:一阶段和两阶段。顾名思义,一阶段就是整个过程只有一个阶段,两阶段说明整个过程分成两个阶段,但最终得到的segment token的数量都为8个。
损失函数
为了学习视觉表示,通过图像-文本对进行训练,设计对比损失:
- 图像-文本损失。
- 带文本提示的多标签对比损失。
zero-shot迁移(即推理过程)
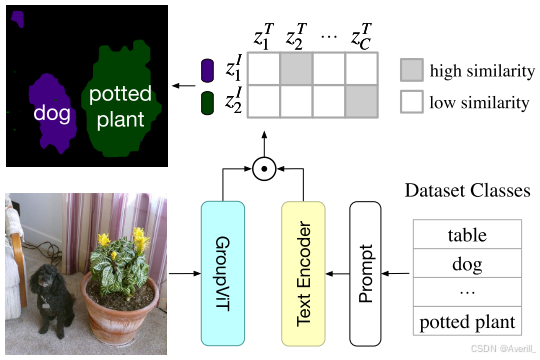
由于GroupViT能够自动将图像分组成一个个的segment,所以可以很容易的zero-shot迁移到语义分割任务上,而不需要微调。
流程
- 测试图像输入到GroupViT,不对最后的输出segment使用平均池化,每个segment token对应输入图像的任意形状的区域,分别获得每个segment的嵌入。
- 为了将图像的区域与segment对应上,计算每个segment token的嵌入和所有类别的文本嵌入之间的相似度。
训练数据集
- CC12M和YFCC。
研究结论
- GroupViT与baseline方法比起来确实有提升,而且GroupViT是第一个用文本做监督信号的工作,还可以做zero-shot的推理。
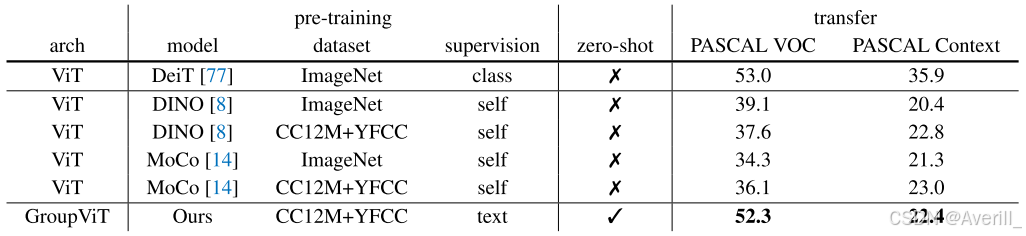
- 但是有监督的模型,如DeepLabV3plus,其mIou已经达到了87左右,比GroupViT高了30多个点,还有很大的提升空间。
存在的问题
- 现在GroupViT的结构更倾向于一个图像编码器,没有很好的利用dense prediction特性。
- 背景类,在做zero-shot推理时最大的相似度有时也比较小,本文为尽可能提高前景类分割性能,所以设置了一个相似度阈值,比如对PASCAL数据集,阈值设置为0.9/0.95,即group嵌入与文本的相似度必须超过0.9且是取得最大的那个,才能说grouping嵌入属于这一类,如果都没有超过0.9,即被认为是背景类,不同数据集的阈值设置不同。
启发与思考
- 可以看出,CLIP学不到很模糊的概念,如背景,因此针对此局限型,在设计模型需要额外的处理。