一、认识正则表达式
- 什么是正则表达式
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表
示法、规则表达式、常规表示法,是计算机科学的一个概念 - 正则表达式的作用
正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正
则表达式通常被用来检索、替换那些符合某个模式的文本 - 正则表达式的特点
灵活性、逻辑性和功能性非常强;
可以迅速地用极简单的方式达到字符串的复杂控制
如何在python中使用正则表达式----findall方法
python中,要使用正则表达式,需要导入re模块,基本格式如下:
re.findall(pattern, string, flags=0)
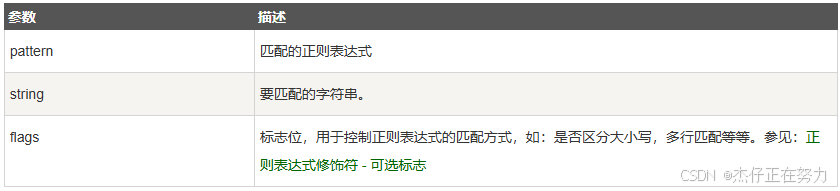
函数参数说明
flags可选值如下

举例,使用findall()方法
import re
str = "hello,my name is jie"
result = re.findall("jie",str)
print(result)
打印结果
['jie']
在python中使用正则表达式----match方法
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
import re
str = "hello,my name is jie"
# result = re.findall("jie",str)
# print(result)
match = re.match("hello",str)
print(match.group(0))
hello
要获取匹配的结果,可以使用group(n),匹配结果又多个的时候,n从0开始递增
当匹配结果有多个的时候,也可以使用groups()一次性获取所有匹配的结果
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配
import re
s = 'hello world hello'
result = re.search('hello', s)
print(result.group(0))
二、使用正则表达式匹配单一字符
- 使用正则,匹配字符串中所有的数字
import re
str = "12hellowordhello12"
result = re.findall("\d",str)
print(result)
打印结果
['1', '2', '1', '2']
- 使用正则,匹配字符串中所有的非数字
import re
str = "12hellowordhello12"
result = re.findall("\D",str)
print(result)
打印结果
['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'd', 'h', 'e', 'l', 'l', 'o']
- 使用正则匹配换页符
import re
str = "12hellowordhello12" + chr(12)
result = re.findall("\f",str)
print(result)
打印结果
['\x0c']
- 使用正则,匹配换行符
import re
str = "hello word my name is jie"
result = re.findall("/n",str)
print(result)
打印结果
[]
三、正则表达式之重复出现数量匹配

- 匹配0次到无限次
import re
s = "hello world helloo hell"
print(re.findall('hello*', s))
['hello', 'helloo', 'hell']
- 匹配一次或多次
import re
s = "hello world helloo hell"
print(re.findall('hello+', s))
['hello', 'helloo']
- 匹配零次或一次
import re
s = "hello world helloo hell"
print(re.findall('hello?', s))
['hello', 'hello', 'hell']
- 匹配n次
import re
s = "hello world helloo hell helloo hellooo helloo helloo"
print(re.findall('hello{2}', s))
['helloo', 'helloo', 'helloo', 'helloo', 'helloo']
- 匹配至少n次
import re
s = "hello world helloo hell helloo hellooo helloo helloo"
print(re.findall('hello{2,}', s))
['helloo', 'helloo', 'hellooo', 'helloo', 'helloo']
- 匹配n次以上,m次以下
import re
s = "hello world helloo hell helloo hellooo helloo helloo"
print(re.findall('hello{2,3}', s))
['helloo', 'helloo', 'hellooo', 'helloo', 'helloo']
四、使用正则表达式匹配字符集

- 如果是连续的范围,可以使用横杠-
import re
str = "110,120,130,230,250,160"
result = re.findall("1[1-9]0",str)
print(result)
['110', '120', '130', '160']
- 表示不是某范围之内的,可以使用^取反
import re
str = "110,120,130,230,250,160"
result = re.findall("1[^1-9]0",str)
print(result)
[]
五、正则表达式之边界匹配

- 匹配整个字符串开头
import re
str = "hello jiejie"
result = re.findall("^he",str)
print(result)
['he']
- 匹配整个字符串的结尾位置
import re
str = "hello jiejie e e e"
result = re.findall("e$",str)
print(result)
['e']
- 匹配单词开头
import re
str = "hello jiejie hel"
result = re.findall(r'\bhe',str)
print(result)
['he', 'he']
六、正则表达式之组
- 什么是组
将括号:() 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用
- 捕获组(Capturing Groups):
- 使用圆括号 () 定义的组被称为捕获组
- 捕获组可以捕获匹配的部分,并可以在后续的处理中引用这些捕获的内容
- 非捕获组(Non-Capturing Groups):
- 使用 (?:…) 定义的组被称为非捕获组
- 非捕获组不会捕获匹配的部分,仅用于分组和逻辑处理
- 假设我们有一个字符串,包含一些日期格式,如 “2023-10-01”,我们想分别捕获年、月和日
import re
# 捕获组示例
text1 = "Today's date is 2023-10-01."
pattern1 = r'(\d{4})-(\d{2})-(\d{2})'
match1 = re.search(pattern1, text1)
if match1:
year = match1.group(1)
month = match1.group(2)
day = match1.group(3)
print(f'Year: {year}, Month: {month}, Day: {day}')
# 输出结果
Year: 2023, Month: 10, Day: 01
代码解析
- text1:输入字符串,包含日期。
- pattern1:正则表达式模式,用于匹配日期格式。
- (\d{4}):匹配四位数字(年份),并将其捕获为第一个组。
- (\d{2}):匹配两位数字(月份),并将其捕获为第二个组。
- (\d{2}):匹配两位数字(日期),并将其捕获为第三个组。
- re.search(pattern1, text1):在 text1 中搜索与 pattern1 匹配的第一个子串。
- match1.group(1):获取第一个捕获组(年份)。
- match1.group(2):获取第二个捕获组(月份)。
- match1.group(3):获取第三个捕获组(日期)。
- print(f’Year: {year}, Month: {month}, Day: {day}'):打印捕获的年、月、日。
- 假设我们有一个字符串,包含一些电话号码,格式为 “123-456-7890”,我们想匹配这种格式,但不需要捕获每个部分
import re
text = "Phone number: 123-456-7890."
pattern = r'(?:\d{3}-){2}\d{4}'
match = re.search(pattern, text)
if match:
print(f'Matched phone number: {match.group(0)}')
# 输出结果
Matched phone number: 123-456-7890
- text2:输入字符串,包含电话号码。
- pattern2:正则表达式模式,用于匹配电话号码格式。
- (?:\d{3}-):匹配三位数字后跟一个连字符,但不捕获这个组(非捕获组)。
- {2}:前面的非捕获组重复两次。
- \d{4}:匹配四位数字。
- re.search(pattern2, text2):在 text2 中搜索与 pattern2 匹配的第一个子串。
- match2.group(0):获取整个匹配的子串(电话号码)。
- print(f’Matched phone number: {match2.group(0)}'):打印匹配的电话号码。
- 假设我们有一个字符串,包含一些重复的单词,我们想找到这些重复的单词
import re
text = "This is a test test of repeated repeated words words."
pattern = r'\b(\w+)\b\s+\1\b'
matches = re.findall(pattern, text, re.IGNORECASE)
if matches:
print(f'Repeated words: {matches}')
# 输出结果
Repeated words: ['test', 'repeated', 'words']
- text3:输入字符串,包含重复的单词。
- pattern3:正则表达式模式,用于匹配重复的单词。
- \b:单词边界。
- (\w+):匹配一个或多个字母或数字,并将其捕获为第一个组。
- \b:单词边界。
- \s+:匹配一个或多个空白字符。
- \1:反向引用第一个捕获组,确保匹配的单词相同。
- \b:单词边界。
- re.findall(pattern3, text3, re.IGNORECASE):在 text3 中查找所有与 pattern3 匹配的子串,忽略大小写。
- matches3:包含所有匹配的重复单词。
- print(f’Repeated words: {matches3}'):打印所有重复的单词。
- 假设我们有一个字符串,包含一些日期格式,如 “2023-10-01”,我们想分别捕获年、月和日,并使用命名组
import re
text = "Today's date is 2023-10-01."
pattern = r'(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})'
match = re.search(pattern, text)
if match:
year = match.group('year')
month = match.group('month')
day = match.group('day')
print(f'Year: {year}, Month: {month}, Day: {day}')
# 输出结果
Year: 2023, Month: 10, Day: 01
- text4:输入字符串,包含日期。
- pattern4:正则表达式模式,用于匹配日期格式。
- (?P\d{4}):匹配四位数字(年份),并将其捕获为名为 year 的组。
- (?P\d{2}):匹配两位数字(月份),并将其捕获为名为 month 的组。
- (?P\d{2}):匹配两位数字(日期),并将其捕获为名为 day 的组。
- re.search(pattern4, text4):在 text4 中搜索与 pattern4 匹配的第一个子串。
- match4.group(‘year’):获取名为 year 的捕获组。
- match4.group(‘month’):获取名为 month 的捕获组。
- match4.group(‘day’):获取名为 day 的捕获组。
- print(f’Year: {year}, Month: {month}, Day: {day}'):打印捕获的年、月、日。
总结:
- 捕获组:使用 () 定义,可以捕获匹配的部分
- 非捕获组:使用 (?:…) 定义,仅用于分组和逻辑处理
- 反向引用:使用 \n 引用第 n 个捕获组
- 命名组:使用 (?P…) 定义,可以按名称引用捕获组
七、正则表达式之贪婪与非贪婪
贪婪匹配
默认情况下,大多数量词都是贪婪的,这意味着它们会尽可能多地匹配字符。例如:
- *:匹配前面的表达式零次或多次
- +:匹配前面的表达式一次或多次
- ?:匹配前面的表达式零次或一次
- {m,n}:匹配前面的表达式至少 m 次,最多 n 次
假设我们有一个字符串,包含一些 HTML 标签,我们想提取标签内的内容
import re
text = '<div>Hello</div><div>World</div>'
pattern = r'<div>(.*)</div>'
matches = re.findall(pattern, text)
print(matches)
# 输出结果
['Hello</div><div>World']
在这个例子中,.* 是贪婪的,它会尽可能多地匹配字符,因此匹配结果是从第一个 < div>到最后一个< /div>之间的所有内容
非贪婪匹配
非贪婪匹配(也称为懒惰匹配)是指量词会尽可能少地匹配字符。非贪婪匹配可以通过在量词后面加上 ? 来实现。例如:
- *?:匹配前面的表达式零次或多次,但尽可能少地匹配
- +?:匹配前面的表达式一次或多次,但尽可能少地匹配
- ??:匹配前面的表达式零次或一次,但尽可能少地匹配
- {m,n}?:匹配前面的表达式至少 m 次,最多 n 次,但尽可能少地匹配
import re
text = '<div>Hello</div><div>World</div>'
pattern = r'<div>(.*?)</div>'
matches = re.findall(pattern, text)
print(matches)
# 输出结果:
['Hello', 'World']