每日一题:魔法王国游历问题
简介:本题难度较大,需要具备一定二叉树基本知识,具体可参考博文:C++二叉树深度探索:DFS函数详解与应用实例
C++二叉树三种遍历全解析及其进阶使用:前序遍历的前是什么前。此外,此题无法通过简单的深度搜索策略解答,解题过程很有趣。可以先行思考一下。
第一部分:题目描述与分析
题目描述
魔法王国有 n 个城市,编号为 0 到 n-1,城市之间的道路连接构成一棵树。小易从 0 号城市出发,最多可以行动 L 次,每次行动可以走到一个相邻的城市。目标是计算小易最多能游历多少个城市(每个城市只计算一次)。
输入说明
- 第一行输入两个整数
n和L:n表示城市数量(2 ≤ n ≤ 50)。L表示小易最多可以行动的次数(1 ≤ L ≤ 100)。
- 第二行输入
n-1个整数parent[i]:parent[i]表示(i+1)号城市的父节点是parent[i],即(i+1)号城市与parent[i]号城市之间有一条边。
分析
- 城市之间的连接构成一棵树,树的性质决定了从根节点(
0号城市)到任意节点的路径唯一。 - 小易的行动次数有限,需要最大化访问城市的数量。
- 关键在于计算树的高度(最长路径),并结合行动次数
L计算最大访问城市数。
第二部分:解题过程
解题思路
- 树的表示:使用邻接矩阵
adj表示树结构。 - 计算树的高度:通过递归遍历树,计算从根节点到最远叶子节点的路径长度。
- 游历策略:
- 如果
L小于树的高度减1,则最多访问L + 1个城市。 - 如果
L大于等于树的高度减1,则先遍历最长路径,再利用剩余步数访问其他分支。
- 如果
- 公式总结:最大访问城市数为
min(min(L + 1, h + (L + 1 - h) / 2), n),其中h为树的高度。
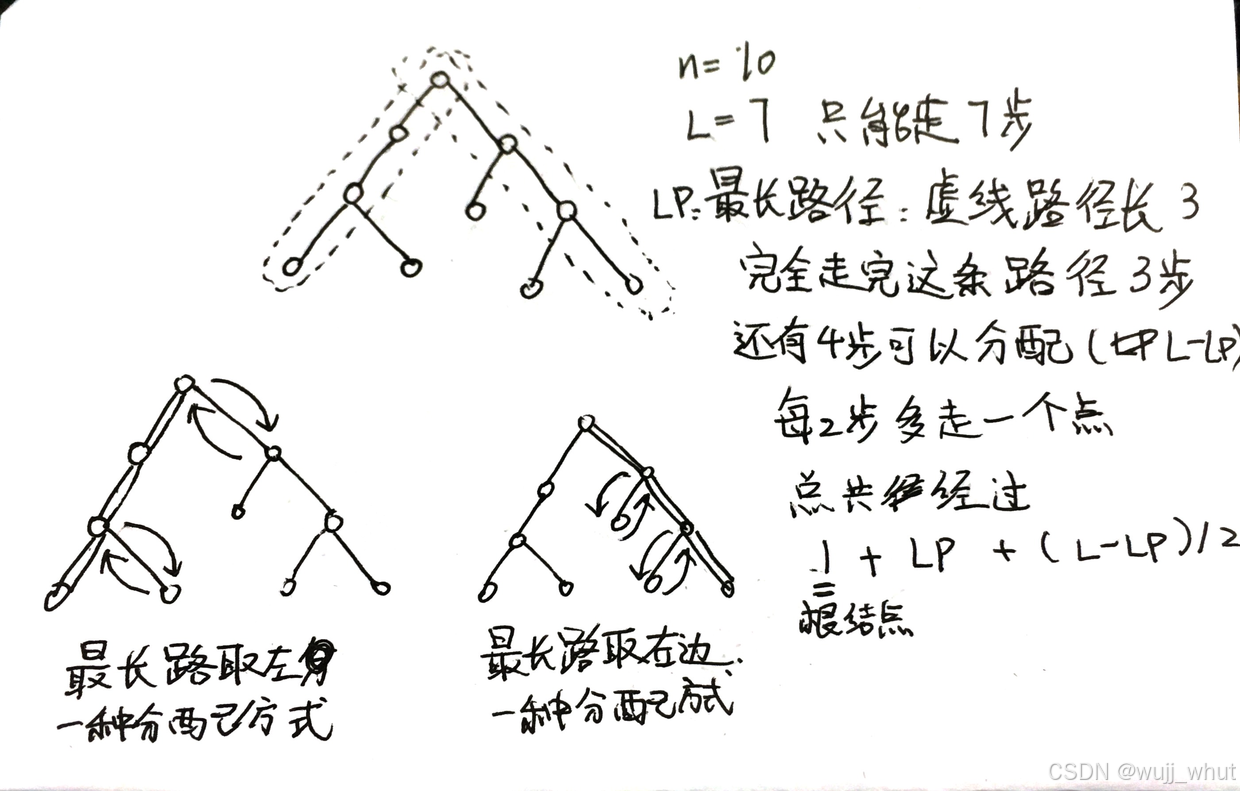
代码实现
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int n; // 城市数量
// 递归计算树的高度(节点数)
int height(bool adj[], int node) {
int maxLen = 0;
for (int i = 0; i < n; ++i) {
if (adj[node * n + i]) { // 存在边
int temp = height(adj, i);
if (temp > maxLen) {
maxLen = temp;
}
}
}
return maxLen + 1; // 当前节点的高度是子树最大高度加1
}
int main() {
int L;
cin >> n >> L;
bool* adj = new bool[n * n];
memset(adj, false, sizeof(bool) * n * n);
// 构建邻接矩阵
for (int i = 1; i < n; ++i) {
int parent;
cin >> parent;
adj[parent * n + i] = true;
// adj[i * n + parent] = true; 为什么这里不能标记为真。(修正)
}
int h = height(adj, 0); // 树的高度(节点数)
int result = min(min(L + 1, h + (L + 1 - h) / 2), n);
cout << result << endl;
delete[] adj;
return 0;
作者:霍七
链接:https://www.nowcoder.com/exam/test/85908306/submission?pid=6910869
来源:牛客网
}
语法知识小节
-
memset:用于初始化内存块。例如:memset(adj, false, sizeof(bool) * n * n);将
adj数组的所有元素初始化为false。 -
maxLen:用于记录最大值。例如:maxLen = max(maxLen, temp);更新
maxLen为当前最大值。 -
min:用于取最小值。例如:int result = min(a, b);返回
a和b中的较小值。 -
adj数组:邻接矩阵,用于表示图的连接关系。例如:adj[parent * n + i] = true;表示
parent和i之间有边。 -
递归:函数调用自身。例如:
int height(bool adj[], int node) { // ... int temp = height(adj, i); // ... }递归计算子树的高度。
第三部分:大佬思路分享
大佬思路一:树上动态规划与贪心结合
原本以为是树上 dp ,其实是贪心。
画个图可以知道,可把 parent[i] 当作 (i+1) 的父亲节点(因为 parent[i] 是可以重复的)。之前看漏了 parent[i] 的范围限制了父节点标号比子节点小 这个条件,我用了 链式前向星 来建图。
建好图之后,就可以从树根扩散出每个节点所在最长树链的长度,选出最长的一条树链,记其长度为 maxLen 。
分类讨论:
若 L ≤ maxLen ,显而易见得结果;
若 L > maxLen ,意味着可以往回走,要知道越短的树链往回走的代价越低。如果从末端往回走,消耗的代价非常高,最坏情况是较短的树链都连接在最远的树根上,整条最长链都要回走;如果已经知道最终步数会有剩余,则可以先消耗富余的步数走短链,最后才走最长链;
继续对 rest = L - maxLen 进行讨论:
若树链上存在某个节点拥有另一条子链,其长度 x 必定小于或等于该祖先到原链末端的长度,考察树链上每个节点到叶子的一条最短子链:
当 x > rest/2 可以在中途预先用掉 rest 步而不影响要走的 maxLen 最长链,可达城市增加 rest/2 个;
当 x ≤ rest/2 可以在中途预先用掉 2x 步而不影响要走的 maxLen 最长链,可达城市增加 x 个;
若所有的 x 总和 sum(x) ≤ rest/2 说明富余的步数足够把最短链到次最长链都走一遍,可达城市为全部 n 个。
本小节讨论可知 rest/2 决定了能多走的城市数量,总共能走 min(n, 1 + rest/2 + maxLen) 个城市。
- 使用:在树结构中,通过贪心算法来寻找最长路径,而不是传统的动态规划方法。通过构建图并从树根扩展,计算每个节点的最长树链长度。
- 优点:这种方法能够有效地减少计算复杂度,避免了多次重复计算,特别是在处理大规模数据时,能够显著提高效率。同时,贪心策略使得在某些情况下能够快速得出结果,尤其是在步数较少的情况下。
#include <stdio.h>
#include <string.h>
#define MAXN 55
#define MAXM 55
// 更新最大值的辅助函数
inline void getMax(int& n, int x) {
n < x && (n = x);
}
// 更新最小值的辅助函数
inline void getMin(int& n, int x) {
n > x && (n = x);
}
// 边的结构体
struct Edge {
int to; // 边的目标节点
int next; // 下一个边的索引
} edge[MAXM];
int cnt; // 边的计数器
int head[MAXN], len[MAXN]; // head数组用于存储每个节点的边,len数组用于存储每个节点的深度
// 初始化函数
void init() {
memset(head, 0xff, sizeof(head)); // 将head数组初始化为-1
}
// 添加边的函数
void addEdge(int u, int v) {
edge[cnt].to = v; // 设置边的目标节点
edge[cnt].next = head[u]; // 将当前边的下一个边指向u的当前头
head[u] = cnt++; // 更新u的头为当前边的索引,并增加边的计数
}
int n, L; // n为节点数,L为步数
// 读取输入的函数
void read() {
int parent; // 父节点
scanf("%d%d", &n, &L); // 读取节点数和步数
for (int i = 1; i < n; ++i) {
scanf("%d", &parent); // 读取每个节点的父节点
addEdge(parent, i); // 添加边
}
}
// 深度优先搜索遍历树的函数
void walk(int u) {
for (int i = head[u]; ~i; i = edge[i].next) { // 遍历u的所有边
len[edge[i].to] = len[u] + 1; // 更新子节点的深度
walk(edge[i].to); // 递归遍历子节点
}
}
// 处理逻辑的主函数
void work() {
walk(0); // 从根节点开始遍历
int maxLen = 0; // 初始化最长链长度
for (int i = 0; i < n; ++i) {
getMax(maxLen, len[i]); // 更新最长链长度
}
if (L <= maxLen) { // 如果步数小于等于最长链长度
printf("%d\n", L + 1); // 输出可达城市数量
} else {
int res = n; // 初始化可达城市数量为n
getMin(res, maxLen + (L - maxLen) / 2 + 1); // 更新可达城市数量
printf("%d\n", res); // 输出可达城市数量
}
}
// 主函数
int main() {
init(); // 初始化
read(); // 读取输入
work(); // 处理逻辑
return 0; // 返回0表示程序正常结束
作者:EugeneZheng
链接:https://www.nowcoder.com/exam/test/85908306/submission?pid=6910869
来源:牛客网
}
大佬思路二:广度优先搜索(BFS)
题目经过抽象之后,意思是在一个树中进行遍历,经过指定步数,可以获取最长经过节点树量的路径。如果把这个树按照根节点进行悬挂,可能更好理解一些。虽然有些答案是从低向上生长,但是我还是重建了树,采用悬挂树来做的。
从这个根节点开始遍历,先判断左树深度大还是右树深度大,先遍历树深度大的那个节点。直到步数用完为止。
树的深度通过后序遍历很容易求出来,结果发现这样的答案只能通过60%。
45 73
0 0 0 1 0 0 3 5 6 8 7 9 1 10 1 2 15 6 8 11 14 17 8 14 3 21 23 3 21 15 12 5 21 31 11 13 7 17 20 26 28 16 36 26
错在这个用例上了。这个正确答案是41,通过简单的贪心算法只能得到39个城市。
后来看了解析也是看不太懂。总之之后看到正确答案中是求出来深度后直接获得最终答案。
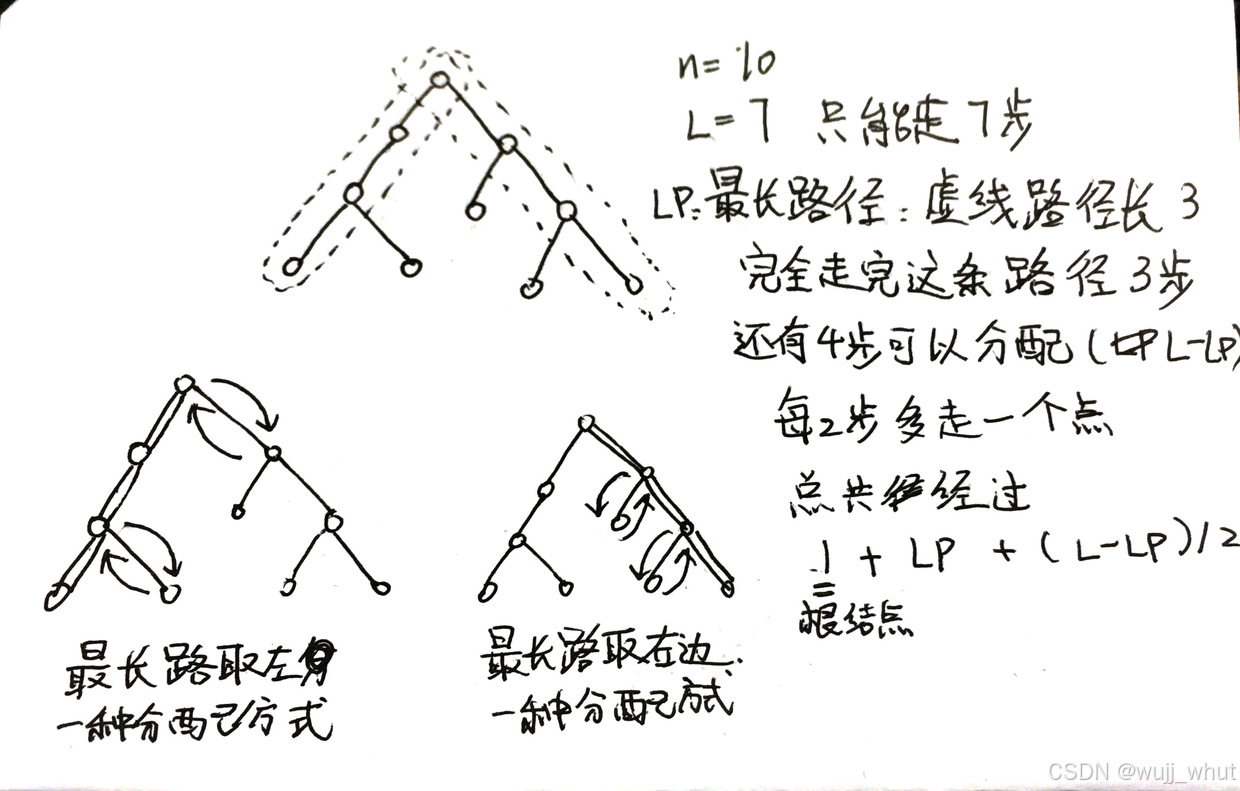
假设我们已经求出了每一个节点的最大深度,用deep[i]来表示,树的最下面一层的深度是1。
显然,根节点到任意一个节点的最长路径=deep[0]-1。
以这条路径为基础,我们可以额外访问一些节点。但是每次访问完这些节点的时候,我们必须回来这个路径。这一来一回,每次访问一个节点都必须额外走两步,访问两个节点就必须走4步。
看图就容易明白一些:
#include <vector>
#include <iostream>
using namespace std;
vector<vector<int> > tree;
vector<int> deep;
void calc_deep(int i)
{
int max_deep = 0;
for(auto j:tree[i])
{
calc_deep(j);
max_deep = max(deep[j], max_deep);
}
deep[i] = max_deep + 1;
}
int main()
{
int n, L;
cin >> n >> L;
/* 建立树 */
tree.resize(n);
deep.resize(n);
for(int i=0;i<n-1;i++)
{
int num;
cin >> num;
tree[num].push_back(i+1);
}
/* 计算深度 */
calc_deep(0);
int long_path = deep[0] - 1;
if(long_path > L) cout << L + 1;
else cout << 1 + long_path + (L - long_path)/2;
作者:linanwx
链接:https://www.nowcoder.com/exam/test/85908306/submission?pid=6910869
来源:牛客网
- 使用:利用广度优先搜索算法遍历树的每一层,记录每个节点的深度和路径长度,从而找到最短路径或最长路径。
- 优点:BFS能够保证找到最短路径,适用于寻找最优解的场景。它的层次遍历特性使得在处理树结构时,可以更直观地理解节点之间的关系,并且在某些情况下,BFS的实现比深度优先搜索(DFS)更简单,尤其是在需要处理大量节点时,能够有效避免栈溢出的问题。
普通版思路:深度搜索(DFS)
只能跑6/10,在第七个案例超时1S限制。回头看大佬2ms的速度,确实思路很重要。经过vscode验证,此案例一分钟都跑不完。虽然思路很普通,但是深度搜索和递归的意识需要掌控。
45 73
0 0 0 1 0 0 3 5 6 8 7 9 1 10 1 2 15 6 8 11 14 17 8 14 3 21 23 3 21 15 12 5 21 31 11 13 7 17 20 26 28 16 36 26
#include <iostream>
#include <vector>
#include <set>
using namespace std;
void dfs(int city, int depth, int L, const vector<vector<int>>& tree, set<int>& visited, int& count ,int& result,vector<int>& road) {
if (depth > L) {
set<int> uniqueCities(road.begin(), road.begin() + depth);
result = max(result, (int)uniqueCities.size());
return;
}else{
road[depth] = city;
depth = depth + 1;
for (int neighbor : tree[city]) {
if (visited.find(neighbor) == visited.end()) {
visited.insert(neighbor); // 标记为已访问
}
dfs(neighbor, depth , L, tree, visited, count, result, road);
visited.erase(neighbor); // 回溯,取消标记
}
}
}
int maxCities(int n, int L, const vector<int>& parent ,vector<int>& road) {
vector<vector<int>> tree(n);
for (int i = 1; i < n; i++) {
tree[parent[i - 1]].push_back(i);
tree[i].push_back(parent[i - 1]);
}
set<int> visited;
int count = 0;
int result = 0;
dfs(0, 0, L, tree, visited, count,result,road);
return result;
}
int main() {
int n, L;
cin >> n >> L;
vector<int> parent(n - 1);
vector<int> road(L+1); // 使用std::vector,大小为L
for (int i = 0; i < n - 1; i++) {
cin >> parent[i];
}
cout << maxCities(n, L, parent,road) << endl;
return 0;
}
总结
本文通过树的高度计算和贪心策略,解决了魔法王国游历问题。同时分享了动态规划、BFS 和贪心算法等大佬思路,帮助读者深入理解问题本质。希望这篇文章对大家有所帮助!