目录
HTTP协议概述
HTTP就是目前使用最广泛的Web应用程序使用的基础协议,例如,浏览器访问网站,手机App访问后台服务器,都是通过HTTP协议实现的,HTTP是HyperText Transfer Protocol的缩写,翻译为超文本传输协议,它是基于TCP协议之上的一种请求-响应协议。
当浏览器希望访问某个网站时,浏览器和网站服务器之间首先建立TCP连接,且服务器总是使用80端口和加密端口443,然后,浏览器向服务器发送一个HTTP请求,服务器收到后,返回一个HTTP响应,并且在响应中包含了HTML的网页内容,这样,浏览器解析HTML后就可以给用户显示网页了。一个完整的HTTP请求-响应如下:
GET / HTTP/1.1
Host: www.sina.com.cn
User-Agent: Mozilla/5 MSIE
Accept: */* ┌────────┐
┌─────────┐ Accept-Language: zh-CN,en │░░░░░░░░│
│O ░░░░░░░│───────────────────────────>├────────┤
├─────────┤<───────────────────────────│░░░░░░░░│
│ │ HTTP/1.1 200 OK ├────────┤
│ │ Content-Type: text/html │░░░░░░░░│
└─────────┘ Content-Length: 133251 └────────┘
Browser <!DOCTYPE html> Server
<html><body>
<h1>Hello</h1>
...HTTP请求的格式是固定的,它是由HTTP Header和HTTP Body两部分构成。第一行总是请求方法 路径 HTTP版本 :例如, GET / HTTP/1.1 表示使用GET请求,路径是 /,版本是HTTP/1.1。后续的每一行都是固定的Header:Value格式,我们称为HTTP Header,服务器依靠某些特定的Header来识别客户端的请求,例如:
Host:表示请求的域名,因为一台服务器上可能有多个网站,因此有必要依靠Host来识别请求是发给哪个网站的;
User-Agent:表示客户端自身表示信息,不同的浏览器有不同的标识,服务器依靠User-Agent判断客户端类型是IE还是Chrome,是Firefox还是一个Python爬虫;
Accept:表示客户端接收能处理的HTTP响应格式,*/*表示任意格式,text/*表示任意文本,image/png表示PNG格式的图片;
Accept-Language:表示客户端接收的语言,多种语言按优先级排序,服务器依靠该字段给用户返回特定语言的网页脚本。
GET请求没用HTTP Body。只有HTTP Header,POST请求带有Body,以一个空行分隔。带Body的HTTP请求如下:
POST /login HTTP/1.1
Host: www.example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 30
username=hello&password=123456HTTP响应也是有Header和Body两部分组成,一个典型的HTTP响应如下:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 133251
<!DOCTYPE html>
<html><body>
<h1>Hello</h1>
...响应的第一行总是HTTP版本 响应代码 响应说明:例如:HTTP/1.1 200 OK 表示版本是HTTP/1.1,响应代码是200,响应说明是OK。客户端值依赖响应代码判断HTTP响应是否成功。
HTTP固定响应代码
1xx:表示一个提示性响应,例如101表示将切换协议,常见于WebSocket连接;
2xx:表示一个成功的响应,例如200表示响应成功,206表示值发送了部分内容;
3xx:表示一个重定向的响应,例如301表示永久重定向,303表示客户端该按指定路径重新发送请求。
4xx:表示一个因为客户端问题导致的错误响应,例如400表示因为Content-Type等各种原因导致的无效请求,404表示指定的路径不存在;
5xx:表示一个因为服务器问题导致的错误响应,例如500表示服务器内部故障,503表示服务器再试无法响应。
服务器总是被动地接收客户端的一个HTTP请求,然后响应它。客户端则根据需要发送若干个HTTP请求。
对于早期的HTTP/1.0协议,每次发送一个HTTP请求,客户端都需要先创建一个新的TCP连接,然后,收到服务器响应后,关闭这个TCP连接。由于建立TCP连接就比较耗时,因此,为了提高效率,HTTP/1.1协议允许在一个TCP连接中反复发送-响应,这样就能大大提高效率:
┌─────────┐
┌─────────┐ │░░░░░░░░░│
│O ░░░░░░░│ ├─────────┤
├─────────┤ │░░░░░░░░░│
│ │ ├─────────┤
│ │ │░░░░░░░░░│
└─────────┘ └─────────┘
│ request 1 │
│─────────────────────>│
│ response 1 │
│<─────────────────────│
│ request 2 │
│─────────────────────>│
│ response 2 │
│<─────────────────────│
│ request 3 │
│─────────────────────>│
│ response 3 │
│<─────────────────────│
▼ ▼因为HTTP协议是一个请求-响应协议,客户端在发送了一个HTTP请求后,必须等待服务器响应后,才能发送下一个请求,这样一来,如果某个响应太慢,它就会堵住后面的请求。所以,为了进一步提速,HTTP/2.0允许客户端在没有收到响应的时候,发送多个HTTP请求,服务器响应的时候,不一定按顺序返回,只要双方能识别那个响应对应那个请求,就可以做到并行发送和节后:
┌─────────┐
┌─────────┐ │░░░░░░░░░│
│O ░░░░░░░│ ├─────────┤
├─────────┤ │░░░░░░░░░│
│ │ ├─────────┤
│ │ │░░░░░░░░░│
└─────────┘ └─────────┘
│ request 1 │
│─────────────────────>│
│ request 2 │
│─────────────────────>│
│ response 1 │
│<─────────────────────│
│ request 3 │
│─────────────────────>│
│ response 3 │
│<─────────────────────│
│ response 2 │
│<─────────────────────│
▼ ▼浏览器向服务器发送请求并获得响应
public static void main(String[] args) {
//服务器监听端口
try (ServerSocket server = new ServerSocket(8888)) {
while(true) {
//获取客户端连接
Socket browserClient = server.accept();
// BufferedReader reader = new BufferedReader(new InputStreamReader(browserClient.getInputStream()));
// String line = null;
// while((line = reader.readLine())!=null) {
// System.out.println(line);
// }
//模拟服务器响应
try (BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(browserClient.getOutputStream()))){
writer.write("HTTP/1.1 200 OK");
writer.newLine();
writer.newLine();
writer.write("服务器返回一个相应!内容为:");
writer.write(UUID.randomUUID().toString());
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} 服务器获得请求:
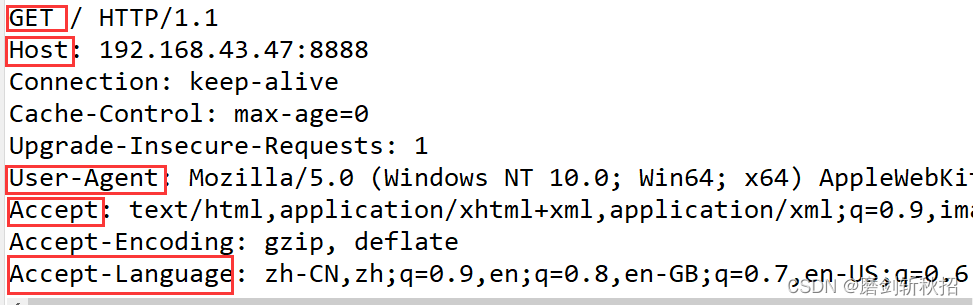
浏览器收到响应:

浏览器通过IP地址和端口号与服务器建立连接后,向服务器发送请求,服务器收到后向浏览器返回一个相应。
爬取网页内容
public static void main(String[] args) {
try {
// 统一资源定位符
URL url = new URL("http://www.baidu.com/index.html");
// 应用层:URLConnection,打开链接
URLConnection connection = url.openConnection();
System.out.println(connection);
System.out.println("HTTP连接类型:" + connection.getClass());
// 通过输入流,获取网页内容
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
当客户端与网页建立连接后,可用Url对象的openConnection()方法返回一个URLConnetion对象,然后通过此对象获得输入流来获取网页的源代码。
爬取网页图片
package x.cc;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Work7184 {
public static void main(String[] args) {
HttpURLConnection connection;
try {
URL imageUrl = new URL("https://movie.douban.com/");
connection = (HttpURLConnection) imageUrl.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.62");
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(connection.getInputStream(), StandardCharsets.UTF_8))) {
String line = null;
while ((line = reader.readLine()) != null) {
line = line.trim();
if (line.contains("jpg") && line.startsWith("<img") && line.contains("https://img")) {
System.out.println(line);
//提取图片的路径src、电影名称alt
String src = "",alt = "";
//解析生成Document对象
Document doc = Jsoup.parse(line);
//从Document中获取名称为img的所有标签元素(Elements)
//从所有代表img的Elements元素集合中获取第一个
Element imgElement = doc.getElementsByTag("img").first();
//获取img标签元素src属性和alt属性
src = imgElement.attr("src");
alt = imgElement.attr("alt");
URL resultUrl = new URL(src);
HttpURLConnection imageUrlConnection = (HttpURLConnection) resultUrl.openConnection();
try (BufferedInputStream in = new BufferedInputStream(imageUrlConnection.getInputStream());
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream("C:\\Users\\admin\\Desktop\\ABCD\\"+alt+".jpg"));){
byte[] buff = new byte[1024];
int len = -1;
while((len = in.read(buff))!=-1) {
out.write(buff,0,len);
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
当我们获得网页的内容后使用Jsoup解析html,Jsoup的parse()方法是返回一个Document对象,然后从Document中获取名称为img的所有标签元素Elements,然后从所有代表ima的Elements元素集合中获取第一个就是我们想要的Element对象。然后就可以获取img标签元素src属性和alt属性。然后创建出URL对象和HttpUrlConnection对象结合输入输出流就能获取网页中我们想要的图片。
