摘 要
车牌识别系统作为智能交通管理必不可缺的一子系统,它的系统主要分为四个重要部分:图像的预处理、车牌定位、字符分割和字符识别。在本次设计中,我们所采用的是一套基于MATLAB的车牌自动识别的方式,对于车牌的识别,它具有较强的识别能力,能有效地解决带有噪声和图像在不同条件下所带来的一些负面影响的问题。最后的设计结果也表明了MATLAB使车牌识别系统在运行上十分有效。
关键词:定位;分割;识别
Abstract
License Plate Recognition System is one of the important contens of moden Inteligent Transportation System.The system is made of image pretreament, license plate localization and character segmentation. In this time,we add MATLAB to LPRS. This new design with strong discrimination can solve some problems about image`s noise and ligting.The final result also show to us that use MATLAB to LPRS is great.
Key words:;localization ;segmentation; Transportation
1. 引言 1
1.1设计目的和意义 1
1.2 本课题研究背景 1
1.3 国内外车牌识别技术状况 2
1.4 设计原理 2
2. 车牌识别系统设计与实现 3
2.1 提出总体设计方案 3
2.2 图像预处理 4
2.2.1图像灰度化 4
2.2.2 图像边缘检测 5
2.3 车牌定位 7
2.3.1 灰度图像腐蚀 7
2.3.2 平滑图像、移除小对象 8
2.3.3 牌照区域的分割 9
2.4 字符分割 10
2.5字符的识别 12
3 总结 13
4 体会 14
5 参考文献 14
6 附录 16
1. 引言
1.1设计目的和意义
在这个经济迅速发展、科技水平也不断提高的时代中,人们对生活质量的要求也越来越高,用于代步的车辆也越来越多。对于来来往往行驶地车辆,如果没进行很好地管理就会使交通的秩序紊乱。对于监控跟管理车流、车辆使得车牌识别显得尤为重要。近年来,不管是国内还是国外,越来越多的人也加入了该系统的研究当中。基于MATLAB的车牌识别是一种智能管理的技术,运图像处理的方法,让车辆可以更好的进行管理。对于交通管理有着非常重要的意义。
1.2 本课题研究背景
随着计算机技术迅速发展的时代,一些自动化设备慢慢融入我们的现代生活之间,让人类生活、发展变得越来越完善。汽车仍然是我们生活中必不可取的代步工具,是人类舒适的移动的小家,但是它也有可能给生活带来一些负面影响,所以对于它的自动化管理也是一件非常重要的事情。
另外,智能交通系统,简称ITS(Intelligent Traffic System ),它是当今科技飞速发展的产物,在对车辆监控管理起到了重要的作用。ITS融合了现代先进计算机科学技术、自动化处理技术、数据通信技术等再在交通管理中体现出来,形成了一个准确、效率高的系统。
车牌识别系统已成为了智能交通管理系统中不可缺少的一部分。车牌识别系统能够对已经设定好的摄像机所拍摄的来往车辆图像所传来的图像进行识别和记录。一般应用于高速公路、隧道、十字路口、停车场等等。车牌识别系统的原理构成经过改造也可以应用于其他检测领域,但是对于目前车辆仍是目前的主要交通工具,所以在汽车识别的环节还是有着重要的研究意义。
1.3 国内外车牌识别技术状况
在这几年里,车牌识别系统在外国的一些国家当中已相当好的融入了他们的检测识别领域中,而我国发展进程还处于一个相对较低的位置,这很大程度是因国内车牌类型与外国存在着较大的差异,国外对车牌类型字符的类型有着相对比较规范的要求,而我国汽车牌照自身的特征具复杂性:
①汉字、英文字母、数字都同时存在。我国车牌车牌内字符不仅仅含有阿拉伯数字还有英文字母,并且有着我国特有的汉字,由于汉字书写笔画外观并不简单,所以对于它的识别难度远远大于阿拉伯数字跟英文字母。
②车牌格式多。我国车牌样式非常多,其中包括:民用车牌、大型货车车牌、医疗机构车牌、军队专用车牌、消防车牌等等,它们的格式采取的车牌字符类型也不同。
1.4 设计原理
该系统主要分为四个部分,分别是图像预处理、车牌定位、车牌字符分割、字符识别。
如下图1-1所示:
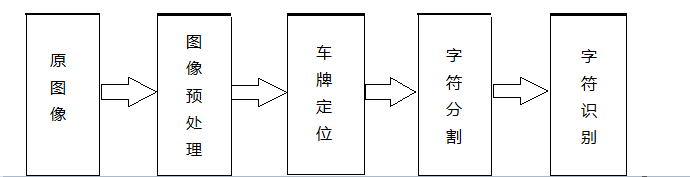
图1-1 牌照识别系统原理图
- 1.原图像:在应用领域上直接由摄像机等其他拍摄装置拍摄的图片。
- 2.图像预处理:将原RGB模式的原图像转为灰阶模式,对图像内物体进行边缘检测。
- 3.车牌定位:对经过预处理的灰度图像进行腐蚀、平滑得到车牌的主要区域。
- 4.字符识别:对车牌区域进行检测,寻找大一某个阈值的非连续块进而进行二值化切割,再对切割后的独立出来的字符进行匹配模式的识别。
2. 车牌识别系统设计与实现
2.1 提出总体设计方案
整个系统中对于车牌的位置的定位和车牌号码的字符识别最为重要。其中的车牌定位又分为图像图像灰度化、图像边缘检测和图像腐蚀;另外车牌号码的识别又由车牌号码的分割和单号码模块匹配结合。该系统的主要目的是将车牌部分通过对图像预处理后从原始图像中分离出来,再将车牌内车牌号的字符单个分离出来,再对单个字符进行模板匹配识别,所以车牌定位分离、字符定位、分离的结果在体统的识别过程中显得特别重要。
在对车牌定位之前,应对原始图像进行一些预处理前,为减少对后续定位、识别的影响,为图像具有较大的对比度和较大的清晰度,更好地运用于牌照分割和字符识别,应对原始图像进行一些处理。因为对于原始图像的来源主要是摄像机直接拍摄处理道路上行驶的车辆,加上车牌照本身的整洁程度、自然光的照射条件、摄像机镜头的光学畸变产生的噪声、拍摄时摄像机与车牌照的距离、车辆行驶的速度以及摄像头的拍摄角度,在这些负面的影响下有可能造成车牌照的图像清晰度不够、角度不正、等严重损坏影响对车牌字符识别的准确度。导致对于车牌的定位和字符分割的结果不准确。
车牌照识别的最终目的就是对车牌照上的文字进行识别和提取。系统运行的过程中需要对图像进行处理,同时也需要大量数据进行整合,所以需要高要求的处理器设备和内存。对于CPU要求的主频在600HZ及以上,内存在128MB及以上。
2.2 图像预处理
通常使用摄像头拍摄到的车辆会存在大量的噪省,所以在处理车牌照图像识别前要先对图像做一些预先的处理。由摄像机等所采集到的含车辆的图片的预处理是指将采集到的含车辆车牌的原图像亮度做一定的调整和去除图像本身的噪声处理,让图像变得更清晰,并保留图像本身的纹理构造和增强图像的颜色信息,尽可能减少对后面将要识别的区域纹理和颜色信息的噪声的影响,让后面的车牌定位的准确性有所提高
2.2.1图像灰度化
一张灰度图指的是它只包含了它本身固有的亮度而不含有它的色彩信息,像八九十年代前的黑白照片就是一张亮度连续变化的灰度图。把一张彩色的图像转为灰阶模式就是灰度化处理。一张彩色的图像都是由R、G、B三原色组成,图像的色彩信息会随着三原色的改变而改变。在计算机上,R、G、B的多少决定了这张图像的颜色,通常,R、G、B它们都各有256级亮度,用数字0到255组成。灰度化就是让原彩色图像的R、G、B相等的过程。
在对图像的灰度化过程,目前有比较主流的三条路径可以处理:
①取原图像亮度的高级:让转化后的RGB等于原图像RGB里的最高级,即:R=G=B=max(R、G、B)
这种路径处理的结果会使图像整体显得比较亮。
②取原图像亮度的平均值:让转化后的RGB等于原图像RGB三者的平均值,即:R=G=B=(R+G+B)/3
这种路径处理方法的结果是图像呈现的亮度会比较适中。
亮度取原图像色彩的加权平均值:原图像经过一定的权值,对其加权平均得到的RGB,即:R=G=B=(ωrR+ωgG+ωbB)/3
这里的ωr、ωg、ωb分别是RGB的加权值。ωr、ωg、ωb的值不一样所产生的灰度图亮度也不一样,这里根据人的眼睛都敏感度,ωr一般取0.299,ωg取0.587,ωb取0.144。
在我们采集的拍摄到的图像,由于地貌分析或者匹配的遥感图像不是同时获得的,或者不是同一波段的图像。这些差异是由于图像形成的时候的条件(如天气星狂、空气湿度、拍摄的角度、物体由于光照反射等)的不同,使得在我们所以处理的图像的领域上灰度等方面也会跟着不同,这样带来的负面影响是后面对字符识别会存在一定的不准确性。当形成图像在一定范围内的客观因素改变时,尽管我们肉眼看起来好像图像发生了很大的差异,但是图像在经过直方灰度校正后存在的车别却是不大。因此,对于实现图像灰度的均衡用直方图的灰度校正的方法是可行的。
在MATLAB里我们使用了它里面im2gray函数进行了灰度化处理。
处理效果如下图2:
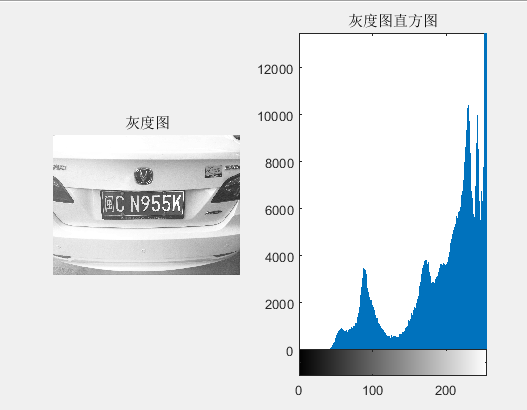
图2-1 车牌灰度图及灰度直方图
2.2.2 图像边缘检测
定位和分割的是识别系统技术主要板块,它的主要作用是图像经过预处理后得到灰度图像的照片后,以确定该图像中包含所要字符的特定位置。由于该点是原来的图像象是非常典型的一个子区域的,主要是周围的矩形横向确切的较高水平,相对原始图像也更侧重于的中心位置,并且灰度区域是完全不同的,所以边缘形检测是一个简单方案对于灰度图像检测图像分割。
图像边缘检测是根据一张图像上在一定区域上的像素都有一定的区别,不仅这样,图像里由拍摄的物体不一样,物体本身的轮廓特征也不一样。图像内物体边缘的灰度会存在着一定的差别。边缘检测就是利用了这个特征,将图像分为一小区域一小区域的像素块,再进行微积分处理或者二阶微分来确定边缘像素点。一阶微积分后的峰值就是图像内物体之间的边缘点;二阶微分图像的过零点处对应着图像的边缘点。有了这些数字图像的特征,我们在处理过程用就可以运用查分来取代倒数运算,在对图像采用一阶倒数运算的时候,因为其本身就有固定的方向性,所以就能根据他这个特性来确定他的连续的边缘。由于用一阶倒数也有一定的缺陷,我们首先要定义图像的梯度为梯度算子,这是一种较为普遍的一阶微分算法。图像梯度的最重要性就是梯度的趋向就是在图像灰度变化最大的区域上,它刚好可以体现出图像边缘上的灰度变化。经过这样的处理,我们可以很容易的将一张含有车牌照的大范围汽车的图像把车牌照相对较小部分区分开来,通过这样的检测可以大大降低了图像存在的噪声、分离出复杂环境中车牌照图像。也能大大改善在后面对车牌分割、字符识别的质量。
因为我们对车辆车牌拍摄一般采用固定摄像头,所以所采集的图像具有一定的惯性,我们可以知道所采取的车牌牌照一般都会在图像以水平的方向区域。在这个系统中我哦们采用的是Roberts边缘检测算子的方法进行图像车牌的提取。
由于在整体图像中,车牌部位是一个具有明显的特征部位,它突出了这些特征:近似水平的矩形区域;车牌里面的具体字符整体呈现出一个水平方向;在整体图象中的位置较为固定。有了这的。 些突出明显的特点,只要对它再进行一定程度的变换,使它在图像中呈现出其边缘是比较容易。
处理效果图如下图2-2:

图2-2 车牌边缘检测图
2.3 车牌定位
2.3.1 灰度图像腐蚀
图像腐蚀是一种形态学运算,它仅对二值图并且根据数学形态学集合方式而形成的到目前已经被广泛应用的数字图像处理的方法。图像腐蚀它的根本依据是:为了得到和衡量灰度图像中所要的对应物体形状,而用结构元素对灰度图进行勘测,找到图像中可以容纳下这个结构元素的位置以达到目的。图像腐蚀可以消除图像中小的而且对没有意义的“污点”,如果“污点”之间有着细小的接通,则可以选择较大的结构元素,把它们一起腐蚀掉。如果结构元素的值都是正的,则得到的图像会比输出图像亮。
腐蚀的原理是按图像领域中像素的最小值作为输出的像素而输出,在二值图像中,在一定区域内,只要存在一个像素点的值为零,则这个领域将以像素点全为零输出。这次系统使用了imrode()函数Car-Image-Erode=imerode(Car-Image-Bin,Se)
其数学定义为:
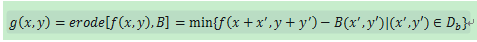
其中,g(x,y)为腐蚀后的灰度图像,f(x,y)为原灰度图像,B为结构元素。
腐蚀效果图如下图2-3:
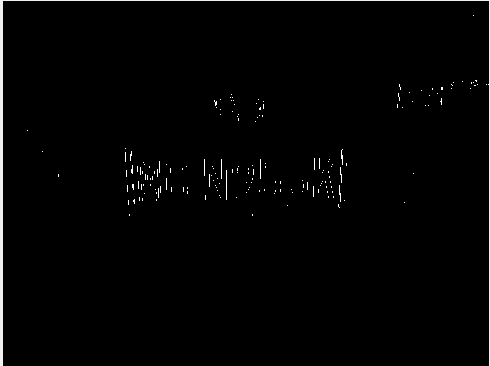
图2-3 灰度图腐蚀后效果图
2.3.2 平滑图像、移除小对象
为了保存并呈现出图像中有意义的信息且要消除噪声干扰,我们通常对图像采用平滑处理。
因为在频率范围内,噪声所在的点处于高频分量,所以可以通过低通滤波来减弱噪声。但在时间中,为了简化算法,可以求领域平均值的办法在空域中来减弱噪声的影响,这种方法就是图像平滑处理。
平滑的具体做法如下:
1.对被白像素围绕的黑像素进行填充;
2.图像内物体边缘的黑像素的凹凸也要进行填充;
3.对图像中单独的点进行消除;
4.对图像中白像素进行消除
此中,M 为领域中布包扣中间点象素点f(i,j) 外的所有像素总数,以4周围域M=4,8 周围域M=8。然而,周围像素平均值的平滑处理会导致图像部位内灰度值产生巨大的变化,会使得图像内物体边缘等变得不清晰。我们通常会根据具体方案设置一个适当的阈值在中心像素点以为其周围来减少平滑处理带来的负面影响。只有当当像素点大于我们设置的阈值时,该点才会被替换,当小于阈值时,该点将不会被改变。
效果如下图2-4:


图2-4 平滑、移除小对象效果图
2.3.3 牌照区域的分割
到这里要将车牌照从原图像分离出来,这里运用了彩色分离的方法。一般车牌照颜色会区别于车身或者其他颜色,所以这里我们就可以设定一个颜色以及设定一个阈值范围,再经过平滑的区域上再进行扫描车牌颜色所对应的灰度范围,来得到车牌的最终位置。
最终得到的车牌:

图2-5 定位到的车牌
得到了这张带有噪声的目标图像后,我们还要对图像进行再处理,这里我们最经常用到的方法是对图像二值化,再滤波。首先设置一个阈值,然后用这个阈值再讲图像划分为两个部分,再经过平均线性滤波的方法对图像像素进行滤波,再把这个像素值赋予整张图像作为其同意像素。
2.4 字符分割
字符分割、归一化
因为车牌本身字符之间的间隔较大,所以我们可以设置一个阈值,在对车牌进行扫描,如果存在有连续大于阈值的空白块,则将在这里从上到下进行分割。
对于分割出来的字符,我们还需要对其进行统一规格的设置,这有利于后面对字符的识别。
图2-6 字符分割与归一化流程图
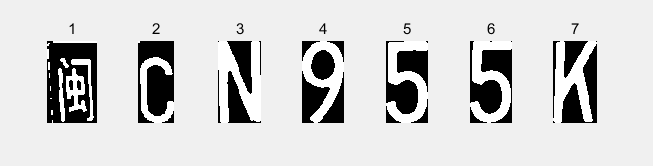
图2-7归一化处理后的七个字符图像
2.5字符的识别
图-8 字符识别流程图
字符识别的准确性直接决定了该系统是否可靠。在之前的研究中最经常被用于字符的识别主要有模板匹配法和神经网络识别法。在这次研究设计中我们采用的是模板匹配法进行识别,该方法是将分割出来的字符样本进行字符归一化处理,使图像大小与原先已经存储在计算机内的标准字符大小一致,再与标准字符进行一一对比,最后结果取差异最小的相对应的标准字符。这种模板匹配的方法相对比较快速、简单。但是对字符图像要求比较高,一旦图像有噪声或者亮度问题其结果就可以能存在差异。神经网络识别法,它是结合神经网络技术,依靠人的经验来取得字符的特征,再利用神经网络的辨别能力来对字符进行识别,这个方法得到的结果会比较准确,但技术要求较高。
对该系统使用的模板匹配的识别方法,它先依次提取需要识别的字符的二值图像上下左右四个点的像素点,想沿着图像中心方向提取周围像素点,计算出每个像素点与标准模板对应该坐标的像素点的相识度,其中相似度最高的标准字符图就作为需要的字符的对应字。也可以计算出原始图像一些特征像素点之间的距离,再计算出标准模板对应特征点的距离,再判断他们距离的差异。取最小差异的标准模板为结果。但是,由于原始字符在可能会由于拍摄的时候角度原因和图像经过处理后,图像像素点距离发生改变。所以,在对标准模板的设计时应根据实际拍摄角度等多做一些相对于的模板,让比较结果更为精确。

图2-9 最终识别显示结果
3 总结
在这次设计中我们主要完成了以下几个问题:一、怎样处理一张具有噪声的图像;二、在图像中如果定位到车牌所在的区域;三、怎样去分辨和识别车牌里的字符。有关于我们设计的车牌识别的研究领域中,虽然已经有了相当多的其他处理方式,但是我们还仍可以发现有这样的一种趋势:单纯的一种识别技术,对于识别出来的结果还是存在一点瑕疵,得出可能结果没那么准确。只有不断努力,将多种识别技术结合起来,才能更准确、有效地得出结果。所以在这次研究中我们也留意到这些并且做出了将多种算法反复实用结合,结合实际,综合分析。
根据查看前辈们的实践经验和结论,我们发现对车牌识别这块比较多地被实用主要有这些算法:1.边缘检测定位算法;2.利用哈夫变换进行车牌定位;3.色彩分割提取车牌等。经过自己的认真比较,我们最后采用了基于Roberts边缘检测算子方式。
对车牌内字符分割用得较多地是:1. 基于聚类分析的字符分割;2. 投影分割的方法;3.基于模板匹配的字符分割等。最常用的是投影分割,主要是针对在车牌定位,图像预处理后比较规则的车牌图像。优点是程序逻辑设计简单,循环执行功能单一,便于设计和操作,程序执行时间短。
字符识别的基本方法通常又三类:1.结构特征分析方法;2.模板匹配法;3.神经网络法。此处采用的是模板匹配的方法,即是将要识别的字符与事先构造好的模板进行比对,根据与模板的相似度的大小来确定最终的识别结果。
但是系统本身还存在许多不足,距离具体实用的要求仍有很大差距,但我却在这次课程设计中学到了很多知识。
5 参考文献
[1] 阮志毅,沈有建,刘凤玲. 基于数学形态学的模糊集理论在车牌字符识别中的运用[J]. 计算机工程与科学. 2016(03)
[2] 张瑞佳. 车辆牌照字符识别技术的研究与实现[D]. 吉林大学 2013
[3] 陈若珠,武艺玄. 基于车牌识别的图像预处理研究[J]. 工业仪表与自动化装置. 2015(04)
[4] 江进. 基于灰度化及边缘检测算法的车牌识别技术研究[J]. 现代计算机(专业版). 2014(01)
[5] 赵纪华,原瑞宏,沈滨,袁涛,谷新明. 基于模板匹配算法的枪械编号识别研究[J]. 计算机与数字工程. 2013(10)
[6] 蔡杰. 数字图像处理技术在车牌定位中的应用[J]. 辽东学院学报(自然科学版). 2014(04)
[7] 郑文光,王静波,翟葆朔,高爽. 基于图像处理技术的车牌识别系统的设计[J]. 电子技术与软件工程. 2015(22)
[8] 王健. 基于Matlab的车牌识别系统[D]. 吉林大学, 2015.
[9]王刚, 冀小平. 基于MATLAB的车牌识别系统的研究[J]. 电子设计工程, 2009, 17(11):72-73.
[10]王璐. 基于MATLAB的车牌识别系统研究[D]. 上海交通大学, 2009.
[11]刘忠杰, 宋小波, 何锋,等. 基于MATLAB的车牌识别系统设计与实现[J]. 微型机与应用, 2011, 30(14):37-40.
[12]袁卉平. 基于MATLAB的车牌识别系统的设计与研究[J]. 工业控制计算机, 2010, 23(10):73-74.
[13]陈宁宁, 苏坤. 基于MATLAB的车牌识别系统研究与实现[J]. 电子测试, 2013(11X):67-68.
[14]扶晓, 刘劲, 陈瑛琦. 基于Matlab汽车牌照识别系统研究[J]. 电脑编程技巧与维护, 2011(10):104-105
[15]徐航, 丁柏秀. 基于MATLAB的车牌识别系统的研究[J]. 通讯世界, 2015(12):315-316
6 附录
function [d]=main(jpg)
close all
clc
[filename,filepath]=uigetfile('.jpg','输入一个需要识别的车牌图像');
file=strcat(filepath,filename);
I=imread(file);
figure(1),imshow(I);title('原图')
I1=rgb2gray(I);
figure(2),subplot(1,2,1),imshow(I1);title('灰度图');
figure(2),subplot(1,2,2),imhist(I1);title('灰度图直方图');
%I1=medfilt2(I1);
%figure,imshow(I1);title('中值滤波');
I2=edge(I1,'roberts',0.15,'both');
figure(3),imshow(I2);title('robert算子边缘检测')
se=[1;1;1];
I3=imerode(I2,se);
figure(4),imshow(I3);title('腐蚀后图像');
se=strel('rectangle',[25,25]);
I4=imclose(I3,se);
figure(5),imshow(I4);title('平滑图像的轮廓');
I5=bwareaopen(I4,2000);
figure(6),imshow(I5);title('从对象中移除小对象');
[y,x,z]=size(I5);
myI=double(I5);
tic
Blue_y=zeros(y,1);
for i=1:y
for j=1:x
if(myI(i,j,1)==1)
Blue_y(i,1)= Blue_y(i,1)+1;
end
end
end
[temp MaxY]=max(Blue_y);
PY1=MaxY;
while ((Blue_y(PY1,1)>=5)&&(PY1>1))
PY1=PY1-1;
end
PY2=MaxY;
while ((Blue_y(PY2,1)>=5)&&(PY2<y))
PY2=PY2+1;
end
IY=I(PY1:PY2,:,:);
%%%%%% X方向 %%%%%%%%%
Blue_x=zeros(1,x);
for j=1:x
for i=PY1:PY2
if(myI(i,j,1)==1)
Blue_x(1,j)= Blue_x(1,j)+1;
end
end
end
PX1=1;
while ((Blue_x(1,PX1)<3)&&(PX1<x))
PX1=PX1+1;
end
PX2=x;
while ((Blue_x(1,PX2)<3)&&(PX2>PX1))
PX2=PX2-1;
end
PX1=PX1-1;
PX2=PX2+1;
dw=I(PY1:PY2-8,PX1:PX2,:);
t=toc;
%figure(17),subplot(1,2,1),imshow(IY),title('行方向合理区域');
%figure(17),subplot(1,2,2),imshow(dw),title('定位剪切后的彩色车牌图像')
imwrite(dw,'dw.jpg');
[fn,pn,fi]=uigetfile('dw.jpg','输入一个定位裁剪后的车牌图像');
I=imread([pn fn]);
jpg=strcat(filepath,filename);
a=imread('dw.jpg');
b=rgb2gray(a);
imwrite(b,'1.车牌灰度图像.jpg');
%figure(18);subplot(3,2,1),imshow(b),title('1.车牌灰度图像')
g_max=double(max(max(b)));
g_min=double(min(min(b)));
T=round(g_max-(g_max-g_min)/3);
[m,n]=size(b);
d=(double(b)>=T);
imwrite(d,'2.车牌二值图像.jpg');
%figure(18);subplot(3,2,2),imshow(d),title('2.车牌二值图像')
%figure(18),subplot(3,2,3),imshow(d),title('3.均值滤波前')
h=fspecial('average',3);
d=im2bw(round(filter2(h,d)));
imwrite(d,'4.均值滤波后.jpg');
%figure(9),subplot(3,2,4),imshow(d),title('4.均值滤波后')
% se=strel('square',3);
% 'line'/'diamond'/'ball'...
se=eye(2); % eye(n) returns the n-by-n identity matrix 单位矩阵
[m,n]=size(d);
if bwarea(d)/m/n>=0.365
d=imerode(d,se);
elseif bwarea(d)/m/n<=0.235
d=imdilate(d,se);
end
imwrite(d,'5.膨胀或腐蚀处理后.jpg');
%figure(18),subplot(3,2,5),imshow(d),title('5.膨胀或腐蚀处理后')
d=qiege(d);
[m,n]=size(d);
figure,subplot(2,1,1),imshow(d),title(n)
k1=1;k2=1;s=sum(d);j=1;
while j~=n
while s(j)==0
j=j+1;
end
k1=j;
while s(j)~=0 && j<=n-1
j=j+1;
end
k2=j-1;
if k2-k1>=round(n/6.5)
[val,num]=min(sum(d(:,[k1+5:k2-5])));
d(:,k1+num+5)=0;
end
end
% 再切割
d=qiege(d);
% 切割出 7 个字符
y1=10;y2=0.25;flag=0;word1=[];
while flag==0
[m,n]=size(d);
left=1;wide=0;
while sum(d(:,wide+1))~=0
wide=wide+1;
end
if wide<y1
d(:,[1:wide])=0;
d=qiege(d);
else
temp=qiege(imcrop(d,[1 1 wide m]));
[m,n]=size(temp);
all=sum(sum(temp));
two_thirds=sum(sum(temp([round(m/3):2*round(m/3)],:)));
if two_thirds/all>y2
flag=1;word1=temp;
end
d(:,[1:wide])=0;d=qiege(d);
end
end
[word2,d]=getword(d);
[word3,d]=getword(d);
[word4,d]=getword(d);
[word5,d]=getword(d);
[word6,d]=getword(d);
[word7,d]=getword(d);
subplot(5,7,1),imshow(word1),title('1');
subplot(5,7,2),imshow(word2),title('2');
subplot(5,7,3),imshow(word3),title('3');
subplot(5,7,4),imshow(word4),title('4');
subplot(5,7,5),imshow(word5),title('5');
subplot(5,7,6),imshow(word6),title('6');
subplot(5,7,7),imshow(word7),title('7');
[m,n]=size(word1);
word1=imresize(word1,[40 20]);
word2=imresize(word2,[40 20]);
word3=imresize(word3,[40 20]);
word4=imresize(word4,[40 20]);
word5=imresize(word5,[40 20]);
word6=imresize(word6,[40 20]);
word7=imresize(word7,[40 20]);
subplot(5,7,15),imshow(word1),title('1');
subplot(5,7,16),imshow(word2),title('2');
subplot(5,7,17),imshow(word3),title('3');
subplot(5,7,18),imshow(word4),title('4');
subplot(5,7,19),imshow(word5),title('5');
subplot(5,7,20),imshow(word6),title('6');
subplot(5,7,21),imshow(word7),title('7');
imwrite(word1,'1.jpg');
imwrite(word2,'2.jpg');
imwrite(word3,'3.jpg');
imwrite(word4,'4.jpg');
imwrite(word5,'5.jpg');
imwrite(word6,'6.jpg');
imwrite(word7,'7.jpg');
liccode=char(['0':'9' 'A':'Z' '闽鲁苏豫']);
SubBw2=zeros(40,20);
for I=1:7
ii=int2str(I);
t=imread([ii,'.jpg']);
SegBw2=imresize(t,[40 20],'nearest');
if I==1
kmin=37;
kmax=40;
elseif I==2
kmin=11;
kmax=36;
else I>=3
kmin=1;
kmax=36;
end
for k2=kmin:kmax
fname=strcat('字符模板\',liccode(k2),'.jpg');
SamBw2 = imread(fname);
for i=1:40
for j=1:20
SubBw2(i,j)=SegBw2(i,j)-SamBw2(i,j);
end
end
Dmax=0;
for k1=1:40
for I1=1:20
if ( SubBw2(k1,I1) > 0 | SubBw2(k1,I1) <0 )
Dmax=Dmax+1;
end
end
end
Error(k2)=Dmax;
end
Error1=Error(kmin:kmax);
MinError=min(Error1);
findc=find(Error1==MinError);
Code(I*2-1)=liccode(findc(1)+kmin-1);
Code(I*2)=' ';
I=I+1;
end
figure(8),imshow(dw),title (['车牌号码:', Code],'Color','b');