目录
一、概述
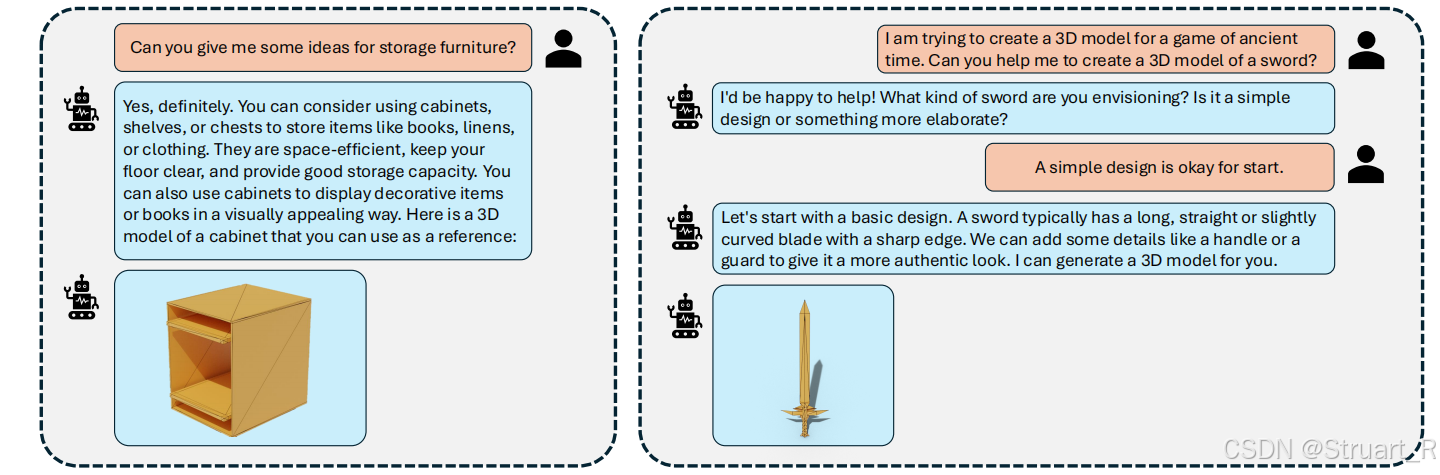
该论文首次提出了一个通过大语言模型(LLM)来生成3D对象的模型LLaMA-Mesh,扩展了在文本上预训练的LLM的能力,来生成一个3D Mesh,有效地统一了3D和文本,并且仍然保持了原有LLaMA的文本生成性能。
(1)将3D Mesh表示为纯文本形式,实现LLM与3D Mesh的直接集成,避免了量化带来的几何细节损失,使LLM能够直接处理和生成3D Mesh。
(2)构建了包含3D Mesh生成、理解和文本生成任务的有监督微调(SFT)数据集,使得预训练的LLM能够学习复杂的空间知识,实现文本到3D网格的统一生成。
(3)在微调LLM以进行3D Mesh生成的同时,也保持了模型在文本生成任务上的优秀性能,实现了两种模态的统一。
二、相关工作
1、LLMs到多模态
将LLM扩展到一个统一的模型处理和生成多模态信息,例如视觉和语言,近期的大模型工作包括多模态的理解视觉如Qwen,Blip,Vila等,使用视觉分词器来统一图像和文本的生成例如Emu3,Chameleon等。而该论文考虑修改分词器,来实现生成3D模型。
以往的LLM只有生成预定义对象的布局方式(类似于编辑),而本论文是第一个允许LLM直接生成3D Mesh作为OBJ文件。
2、3D对象生成
DreamFusion、Magic3D、ProlificDreamer等考虑使用SDS来实现文本到3D对象。
LRM、CRM、InstantMesh等考虑使用前馈方法无需测试是优化来生成3D对象。
但是这些方法通常将3D对象转变为数值场,并通过marching cubes或者其他类似变体来提取mesh,但不容易引入分词器作为离散标记。
3、自回归的Mesh生成
类似于PolyGen、MeshGPT、MeshXL等奖3D对象表示为一个标记坐标的离散序列,并使用自回归transformer来生成具有艺术性的对象。
MeshAnything、PivotMesh、EdgeRunner通过点云作为输入特征来优化限制,但这些工作都从0开始训练,缺乏语言能力。
三、LLaMA-Mesh

LLaMA-Mesh模型分为三个模块:将3D Mesh转换为文本,预训练带有3D对象多模态的LLaMA-Mesh,创建有监督的3D对话数据集。
1、3D表示
LLaMA-Mesh采用obj文件格式来表示3D网格模型,obj文件包含顶点(v)坐标和面(f)定义两个信息,如下图左侧的表示,顶点v就是x,y,z坐标,f就是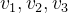
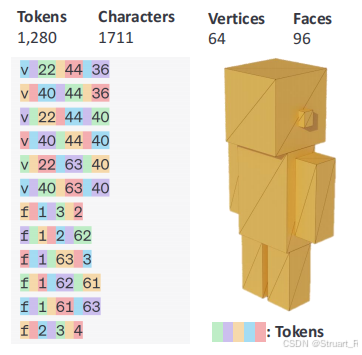
对于坐标存在浮点数的问题,由于超出LLM上下文,所以论文进行量化,通过定义一个固定的![[0,64]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUIwJTJDNjQlNUQ%3D)

2、预训练模型
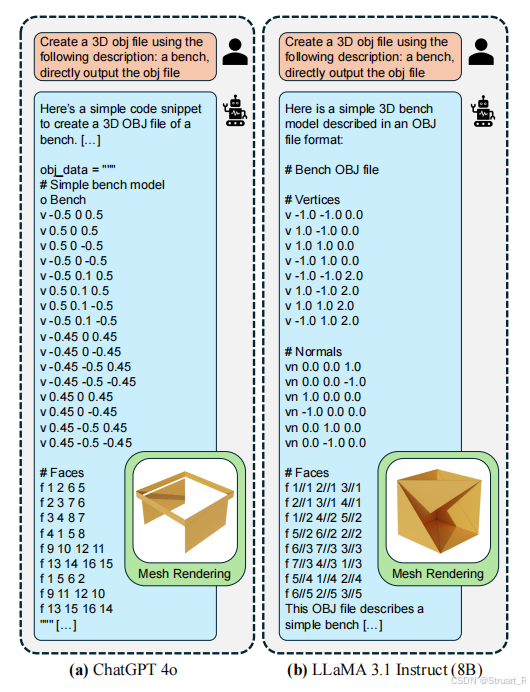
使用LLaMA3.1-8B-Instruct作为基础模型,但原有的模型效果不佳,缺少对3D对象的理解,所以我们考虑在自己创建的数据集上进行微调,实现模型能够学习OBJ格式的模式和语义,生成文本描述的有效3D网格。下图为ChatGPT 4o和LLaMA的预训练模型对3D OBJ文件的固有理解。
3、有监督的微调数据集
对于建立有监督微调(SFT)数据集用于训练,使用Objaverse数据集中的mesh,一个可描述的通用3D数据集。并且过滤Objaverse数据集选择最多500个面的网格,并且转换为Obj格式,并将顶点坐标量化到64个箱子。文本使用Cap3D来生成每个网格的文本描述,并在![[0^o,90^o,180^o,270^o]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUIwJTVFbyUyQzkwJTVFbyUyQzE4MCU1RW8lMkMyNzAlNUVvJTVE)
![[z,y,x]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUJ6JTJDeSUyQ3glNUQ%3D)
为了建立对话数据集,引入两种方法,基于规则的方法和基于LLM的增强。
基于规则的方法中设计了一些简单的模式,如用于理解3D模型:“(user) {obj} What is this?(assistant){caption}." 用于创造3D模型:“(user)Create a 3D model of {caption}.(assistant) {obj}” 对于每个对象随机选择一个模式,学习文本到3D表示之间的对应关系。
对于增强方法,我们设计了复杂对话,实现3D to text的交错对话。
这个对话包括了:3D模型创建和理解,数学理解,代码生成和物体的分解等工作。
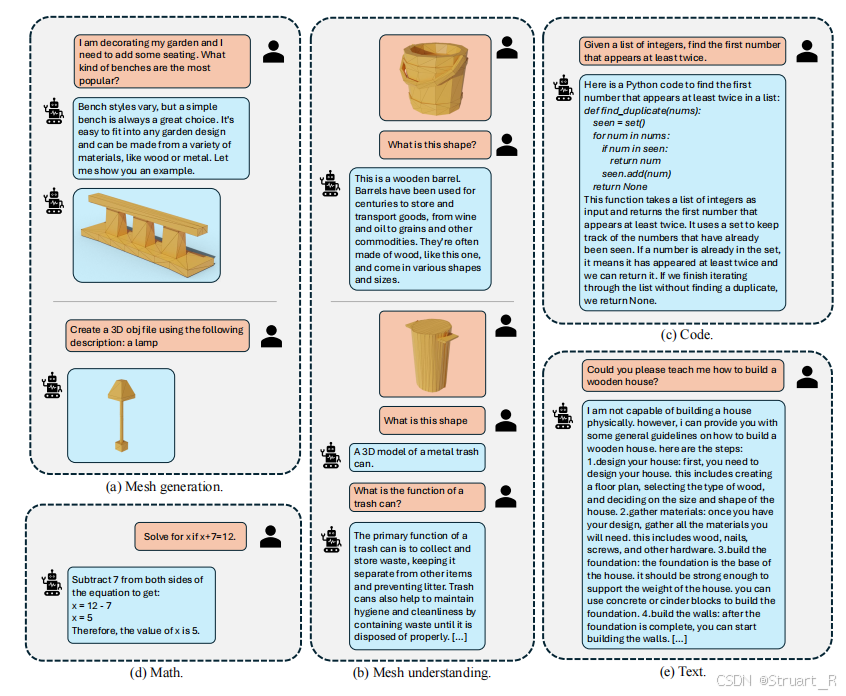
最后我们随机选择这两种方法,来随机构建对话,并且使用UltraChat创建通用对话数据集。
4、数据集演示

四、实验
1、生成的多样性
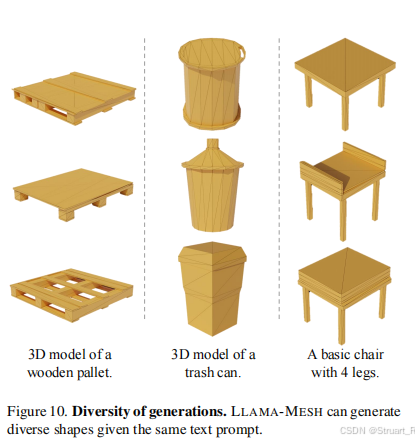
2、不同模型text-to-Mesh的比较
其实LLaMA-Mesh的生成还是很 抽象的,由于使用网格生成而导致对于过于形象的物体会产生失真。

3、通用语境的评估
再经过text-to-Mesh后,不可避免的就是对于原有的语境的性能下降,LLaMA-Mesh更适应对话3D对象问题,而对于原有的数学能力,常识推理等能力有所下降,但相比于LLaMA3.2(3B)更优,为什么不试8B?(hhhhh)
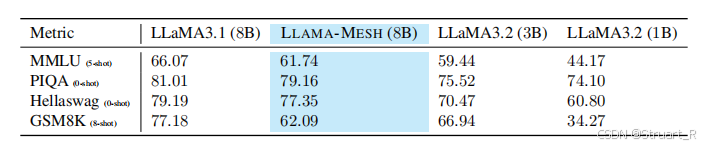
对于上面的测试Metric的解释:
- MMLU (Massive Multitask Language Understanding) 是一个评估模型一般知识的基准测试集。
- PIQA (Physical Intuition QA) 是一个评估模型常识推理能力的基准测试集。
- HellaSwag 是一个评估模型常识推理能力的基准测试集。
- GSM8K (Grade School Math) 是一个评估模型数学问题解决能力的基准测试集。
参考文献:LLaMA-Mesh