目录
一、概述
提出了StyleGaussian,一种新的3D风格化迁移技术,允许每秒10fps的速度,将任何风格即时传输到3D场景中。利用3DGS执行风格迁移,不会影响实时渲染能力和多视图一致性。
(1)提出了StyleGaussian,一种新颖的三维风格化迁移手段。
(2)设计了一种有效的特征渲染策略,可以在渲染高维特征中,将学习到的特征嵌入到冲减的三维高斯特征中。
(3)设计了一个基于KNN的3D CNN,可以在不影响多视图一致性的同时,解码3DGS格式为RGB。

二、相关工作
1、辐射场
辐射场是近年来在3D场景表示方面取得重大进展的技术。它们是一种函数,可以为任意3D坐标分配辐射(颜色)和密度值。像素的颜色是通过体积渲染聚合3D点的辐射而得到的。
辐射场在视觉和图形学的多个领域都有广泛应用,特别是在视图合成 、生成模型和表面重建等方面。它们可以通过多种方式实现,如MLP 、分解张量 、哈希表和体素等,许多研究都致力于提高它们的质量或渲染和重建速度 。其中,3DGS 因其快速重建能力、实时渲染性能和出色的重建结果而脱颖而出。它使用多个显式参数化的3DGS来建模辐射场,依靠光栅化而不是光线追踪来实现实时渲染。本文的工作就是建立在3DGS的优势之上,以实现沉浸式的3D编辑体验。
2、3D编辑
传统的3D表示如网格或点云,编辑它们的外观通常比较简单,因为网格有UV贴图,点对应图像中的像素。但是,辐射场编辑很有挑战,因为它们被隐式地编码在神经网络或张量的参数中。
因此,之前的研究采用基于学习的方法来编辑辐射场,通过图像、文本或其他形式的用户输入进行引导,包括变形、外观变化、移除、重照明和修复等。
这些方法大多依赖于测试时优化策略,需要对每次编辑进行耗时的优化过程。另一方面,一些方法以前馈方式实现3D场景的编辑。但是,这些方法的编辑速度仍然远远达不到交互速度。相比之下,我们的方法可以即时编辑场景的外观。
3、风格迁移
神经风格迁移(Neural Style Transfer)旨在渲染一个新的图像,将一个图像的内容结构与另一个图像的风格模式融合在一起。
早期的研究依赖于优化方法来对齐风格图像的VGG特征。后来的方法引入了前馈网络来近似这个优化过程,大大提高了风格迁移的速度。
更近期的工作将风格迁移扩展到3D领域,尝试对点云或网格进行风格化。但这些方法在渲染能力上通常落后于辐射场(radiance fields)。因此,有更多的研究集中在对辐射场进行风格化。一些方法通过优化实现了辐射场的风格迁移,提供了视觉上令人印象深刻的风格化,但需要耗时的优化过程,且泛化能力有限。另一些方法如HyperNet和StyleRF采用了前馈方式,但仍面临渲染速度慢或多视图一致性差的问题。
相比之下,本文提出的StyleGaussian方法可以实现即时的风格迁移和实时渲染,同时保持严格的多视图一致性。它通过设计高效的特征渲染策略和基于KNN的3D CNN解码器来实现这一目标。
三、StyleGaussian
首先给定一个重建好的3DGS,然后将VGG features嵌入到3DGS(e),然后给定一个style 图像,将当前的3DGS(e)transfer到3DGS(t),之后用一个基于KNN的3D CNN来解码一个带有风格的3DGS。
对于一般的3DGS参数都应该是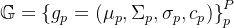
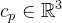
那么对于中间两步,特征嵌入和风格迁移中这个3DGS参数就有所变化,因为我们只改变颜色,而不改变几何结构,所以后续的特征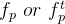
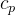
特征嵌入输出即
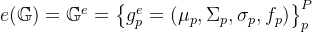
风格迁移输出即
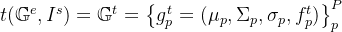
最终解码输出即
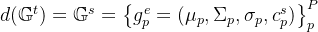

1、特征嵌入
输入多视角图像利用VGG网络的中间层进行提取特征,得到二维图像的VGG特征,并将VGG特征嵌入到一个辐射场中。
这一步的目的就是得到了一个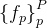
给定一个3DGS分布,然后分配到每个像素得到每个像素的3DGS参数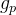
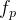
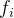
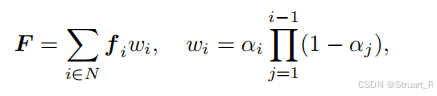
利用VGG网络的目的是,监督可学习参数 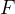


对于VGG网络的解释:使用了VGG网络的中间层特征(ReLU3_1和ReLU4_1层),应该是直接将多视图输入到VGG网络,然后输出这两层信息,但由于这两层输出out_channel是256维和512维,耗费计算资源和内存,所以论文中渲染了一个低维特征(32维),然后通过仿射变换T()将低维特征map到高维特征F上。
其中低维特征的解释不太清楚,他只提到用了一个高效的渲染策略,没有看代码,可能是直接将最后一层输出改为32channels。
对于仿射变换就是设计了两个可学习的参数A和b。
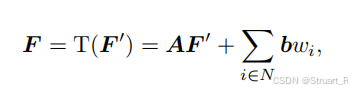
2、风格迁移
这里用到了一个AdaIN算法,来实现无参数的零样本训练的风格迁移。
风格迁移的目的就是得到一个注入参考图像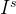
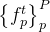
下面为计算公式,其中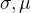

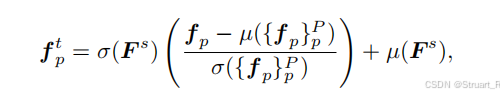
3、解码
based convolution
这一步的重点在于使用了KNN-based的卷积。
目的是通过特征信息
具体来说,首先设计一个3D CNN作为解码器,将风格迁移后的
对于每个GS 

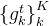
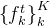

因为KNN引入到一个3D CNN中,那么对于神经网络来说也一定有权重和偏置,那么第一层的KNN-based CNN输出之后,就得到这个
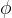
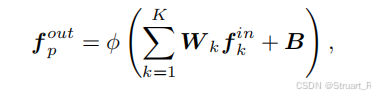
最后经过了多层 KNN-based CNN结构,最后一层channels数为3,输出得到
对于这一部分的监督,利用内容损失
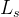
四、实验
1、不同backbone下的量化和定性指标

2、解码器设计上的测试
pointnet很显然,关注结构的解码没有意义,因为要解码的是颜色。
mlp很通用,可以处理,但是效果很拉。

3、内容损失平衡
这个λ就是风格损失的占比,越大越关注于风格。

4、风格平滑插值
这个实现不同风格之间的平滑转换。
他的做法是微调解码器,而不是从头训练,在一个已经训练好A风格的解码器下,再次训练另一个B风格的解码器。


参考项目:StyleGaussian: Instant 3D Style Transfer with Gaussian Splatting