简介
openpyxl是一个用于读取和编写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库。openpyxl以Python语言和MIT许可证发布。
openpyxl可以处理Excel文件中的绝大多数内容,包括图表、图像和公式。它可以处理大量数据,支持Pandas和NumPy库导入和导出数据。Openpyxl还支持自定义矩阵和PivotTable,以及通过API自动化Excel应用程序。
目录
1. 创建和打开工作簿
1.1. 创建工作表
- 创建一个新的工作表,并添加到工作簿中。可以通过index参数来指定插入工作表的位置,默认为在末尾添加。
语法
workbook.create_sheet(
title=None #可选参数,指定工作表的名称,默认为Sheet+数字(Sheet1)
index=None #可选参数,指定工作表的插入位置,从0开始计数。默认将工作表添加到末尾位置。
)示例
from openpyxl import Workbook
# 创建一个新的工作簿
workbook = Workbook()
# 创建一个 AAA 的工作簿,从第1个位置添加(索引从0开始)
wb_AAA = workbook.create_sheet('AAA', 0)
# 创建一个 BBB 的工作簿,默认添加到末尾
wb_BBB = workbook.create_sheet('BBB')
# 创建一个不指定名称的工作簿
wb_sheet = workbook.create_sheet()
# 查看所有的工作表名称
for i in workbook.worksheets:
print(i.title)
# 将这些表保存到磁盘
workbook.save('tmp.xlsx')结果
AAA
Sheet
BBB
Sheet1
如果表名已存在,则会报错
1.2. 保存Excel文件
- 保存工作簿为一个Excel文件,需要指定文件的路径和文件名。
语法
workbook.save('文件名')举例
from openpyxl import Workbook
# 创建一个新的工作簿
workbook = Workbook()
# 保存工作簿
workbook.save('tmp.xlsx')会默认创建一个sheet页

1.3. 关闭Excel工作簿
- 在处理完工作簿之后,应该使用close()方法将其关闭。这可以确保文件在使用后得以正常关闭,避免内存泄漏和其他问题。同时,关闭Excel文件还可以防止其他应用程序无法访问或编辑相同的文件。
语法
workbook.close()如果使用 with,则会自动关闭,无需手动操作
from openpyxl import Workbook
# 使用with语句打开Excel文件,并创建一个新的工作簿
with Workbook() as workbook:
worksheet = workbook.active
"""操作Excel文件"""
# 自动关闭Excel文件
1.4. 获取正在活动的表
- 获取或设置当前活动的工作表,可以通过该属性来切换不同的工作表或获取当前活动的工作表。
语法
# 设置一张活动的表
Workbook().active = [表名]
# 查看正在活动的表
print(Workbook().active)
#仅查看表名
print(Workbook().active.title)举例(如果没有活动的表,返回None。使用Workbook就会有一张默认的sheet表活动)
>>> from openpyxl import Workbook
>>> print(Workbook().active)
<Worksheet "Sheet">
>>> print(Workbook().active.title)
Sheet设置一张活动的表
>>> from openpyxl import Workbook
# 创建一个新的工作簿
>>> workbook = Workbook()
# 设置一张表为正在活动的表
>>> wb_AAA = workbook.create_sheet('AAA')
>>> workbook.active = wb_AAA
# 查看活动的表
>>> print(workbook.active.title)
AAA
1.5. 获取表名
- 返回工作簿中所有工作表的名称列表。
from openpyxl import load_workbook
# 打开工作簿
f = load_workbook('./tmp.xlsx')
# 查看工作簿中所有工作表名
print(f.get_sheet_names())如果在高版本出现了这样的提示

那么按照提示要求,将 get_sheet_names() 替换为 sheetnames 即可
from openpyxl import load_workbook
# 打开工作簿
f = load_workbook('./tmp.xlsx')
# 查看工作簿中所有工作表名
print(f.sheetnames)

1.6. 移除工作表
- 从工作簿中移除指定的工作表或命名范围。
语法
workbook.remove([表名])删除 AAA 表
>>> from openpyxl import Workbook
# 创建一个新的工作簿
>>> workbook = Workbook()
# 创建两个工作表
>>> AAA = workbook.create_sheet('AAA')
>>> BBB = workbook.create_sheet('BBB')
# 查看所有表名
>>> for i in workbook.worksheets:
>>> print(i.title)
Sheet
AAA
BBB
# 删除工作簿中的第二个工作表
>>> workbook.remove(AAA)
# 再次查看所有表名
>>> for i in workbook.worksheets:
>>> print(i.title)
Sheet
BBB
1.7. 复制工作表
- 将指定的工作表复制一份,并添加到工作簿中。可以使用这个方法来快速复制工作表,并进行一些定制化操作。
直接拷贝工作表,插入的最后面。名称为:[旧名称] + copy
from openpyxl import load_workbook
# 打开工作簿
f = load_workbook('./tmp.xlsx')
# 选择复制的工作表(AAA)
f_copy = f['AAA']
# 复制并插入表(新表为:[旧名]+copy)
ws = f.copy_worksheet(f_copy)
# 保存文件
f.save('./tmp.xlsx')
# 关闭文件
f.close()
拷贝工作表后重命名
from openpyxl import load_workbook
# 打开工作簿
f = load_workbook('./tmp.xlsx')
# 复制插入新的工作表,赋值给变量
f_copy = f.copy_worksheet(f['AAA'])
# 重命名工作表
f_copy.title = 'new_copyAAA'
# 保存文件
f.save('./tmp.xlsx')
# 关闭文件
f.close()
1.8. 添加数据到末行
自动追加到有数据的末行,从第1列开始追加
from openpyxl import load_workbook
# 打开工作簿
f = load_workbook('./tmp.xlsx')
# 选择需要追加的工作表
f_sheet = f['Sheet1']
# 追加数据
data = ['A', 'B', 'C', 'D']
f_sheet.append(data)
# 保存文件
f.save('./tmp.xlsx')
多行数据使用循环遍历的方式添加
from openpyxl import load_workbook
# 打开工作簿
f = load_workbook('./tmp.xlsx')
# 选择需要追加的工作表
f_sheet = f['Sheet1']
# 准备多行数据
data_list = [
['A', 'B', 'C', 'D'],
['E', 'F', 'G', 'H'],
[1, 2, 3, 4]
]
# 循环添加
for i in data_list:
f_sheet.append(i)
# 保存文件
f.save('./tmp.xlsx')

2. 写入和读取Excel
2.1. 设置表名
- 获取或设置工作表的名称。
title 只能获取已赋值的对象,查看表名 get_sheet_names 更合适
title 修改表名(将原 Sheet1 修改为 new_Sheet1)
from openpyxl import load_workbook
# 打开工作簿
f = load_workbook('./tmp.xlsx')
# 获取工作表对象
sheet = f['Sheet1']
# 修改工作表名称
sheet.title = 'new_Sheet1'
# 保存文件
f.save('./tmp.xlsx')
2.2. 写入数据
- 获取或设置工作表中指定单元格的数据、样式等信息。该方法需要指定行列索引,例如cell(row=1, column=1)表示获取第1行第1列的单元格数据。
语法
[工作表].cell(
row: #必选参数,指定单元格的行号
column: #必选参数,指定单元格的列号
value: #可选参数,单元格的值,默认值为None
coordinate: #可选参数,单元格的坐标,默认值为None。如果同时设置了row和column参数,那么coordinate参数会被自动计算。
)指定 某行、某列 写入数据。注意:这种方式会将指定文件的原有内容覆盖,工作表留一个Sheet1
import openpyxl
# 创建一个 工作簿
wb = openpyxl.Workbook()
# 获取工作表对象
ws = wb.active
# 第1行、1列:插入字符串
ws.cell(1, 1, 'Hello')
# 第1行、2列:插入数字
ws.cell(1, 2, 1)
# 第1行、3列:插入数字
ws.cell(1, 3, 10)
# 第1行、4列:插入公式
ws.cell(1, 4, '=B1+C1')
# 第1行、5列:设置格式
ws.cell(row=1, column=5, value='测试')
# 保存文件
wb.save('./tmp.xlsx')
向已有数据的文件中,写入指定内容
import openpyxl
# 打开一个工作簿
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
sheet = wb['Sheet1']
# 向文件中写入内容
sheet.cell(2, 1, 'abc') #第2行、1列
sheet.cell(2, 2, '无敌') #第2行、2列
# 保存文件
wb.save('./tmp.xlsx')
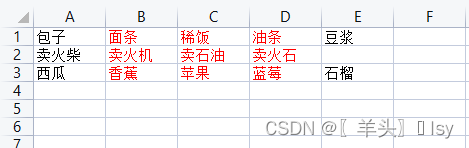
向某个工作簿插入多条数据
import openpyxl
# 打开一个工作簿
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
sheet = wb['Sheet2']
# 准备每行内容
data = [
['包子', '面条', '稀饭', '油条', '豆浆'],
['卖火柴', '卖火机', '卖石油', '卖火石'],
['西瓜', '香蕉', '苹果', '蓝莓', '石榴']
]
# 设置开始行、列
start_row = 2
start_col = 3
# 记录初始列
init_col = start_col
for data_list in data: #遍历这个列表
for value in data_list: #遍历列表中的列表,这才是要插入的数据
sheet.cell(row=start_row, column=start_col, value=value) #指定行、列,插入数据
start_col += 1 #每次遍历,列数+1
start_row += 1 #每次遍历一个列表,行数+1
start_col = init_col #每次遍历一个列表,列数回到初始值
# 保存文件
wb.save('./tmp.xlsx')
# 关闭文件
wb.close()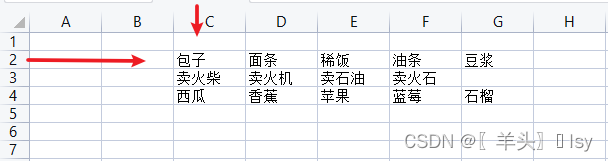
2.3. 插入空白行/列
- 分别用于在指定的行或列插入新的空白行或空白列。
插入空白行(原本行的数据会下移n行,n取决于插入的空白行数)
insert_rows(
[行号] #必选参数,指定插入的行号
[行数] #可选参数,指定插入n行空白,默认1
)# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 第2行插入1行空白行
wb_sheet.insert_rows(2)
# 第2行插入3行空白行
wb_sheet.insert_rows(2, 3)
# 保存文件
wb.save('./tmp.xlsx')
插入空白列(原本列的数据会右移n列,n取决于插入的空白列数)
insert_cols(
[列号] #必选参数,指定插入的列号
[列数] #可选参数,指定插入n列空白,默认1
)# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 第2列插入1列空白列
wb_sheet.insert_cols(2)
# 第2列插入3列空白列
wb_sheet.insert_cols(2, 3)
# 保存文件
wb.save('./tmp.xlsx')
2.4. 迭代读取指定行、列
语法
iter_rows(
min_row:要迭代的起始行号,默认值为1。
max_row:要迭代的最后行号,默认值为最大行号,即ws.max_row的值。
min_col:要迭代的起始列号,默认值为1。
max_col:要迭代的最后列号,默认值为最大列号,即ws.max_column的值。
values_only:默认为False,如果设置为True,则仅返回单元格的值,而不是单元格对象。
)表内容如图
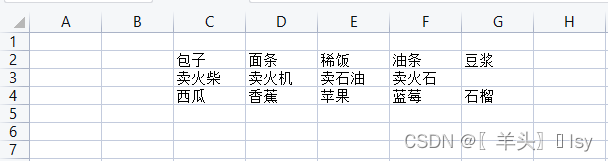
指定开始行、结束行和开始列、结束列
import openpyxl
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 指定读取 2-3 行,返回值(而非对象)
rows = wb_sheet.iter_rows(min_row=2, max_row=3, values_only=True)
# 遍历2-3行
for i in rows:
print(i)
# 指定读取 2-3 行和 3-4 列
rows = wb_sheet.iter_rows(min_row=2, max_row=3, min_col=3, max_col=4, values_only=True)
# 遍历2-3行,3-4列
for i in rows:
print(i)
2.5. 遍历所有数据行
- 分别返回一个生成器对象,用于遍历工作表中所有的行。
表内容如图
遍历所有存在数据的行(从第1行开始,无论第1行是否有数据)
import openpyxl
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 遍历所有有数据的行
for row in wb_sheet.rows:
# 再遍历这一行的所有值
for i in row:
# 输出单元格名和值
print(i.coordinate, i.value)
# 每行做一个间隔
print('-------------- 下一行 --------------')输出结果如下:
A1 None
B1 None
C1 None
D1 None
E1 None
F1 None
G1 None
-------------- 下一行 --------------
A2 None
B2 None
C2 包子
D2 面条
E2 稀饭
F2 油条
G2 豆浆
-------------- 下一行 --------------
A3 None
B3 None
C3 卖火柴
D3 卖火机
E3 卖石油
F3 卖火石
G3 None
-------------- 下一行 --------------
A4 None
B4 None
C4 西瓜
D4 香蕉
E4 苹果
F4 蓝莓
G4 石榴
-------------- 下一行 --------------
指定遍历第2行
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 遍历第2行
for i in wb_sheet[2]:
# 输出单元格名和值
print(i.coordinate, i.value)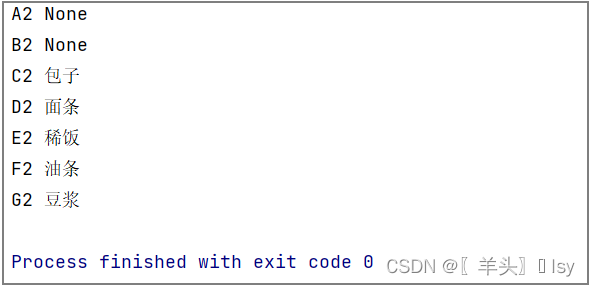
2.6. 遍历所有数据列
- 分别返回一个生成器对象,用于遍历工作表中所有的列。
表内容如图
遍历所有存在数据的列(从第1列开始,无论第一列是否有数据)
import openpyxl
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 遍历所有有数据的列
for col in wb_sheet.columns:
# 再遍历这一列的所有值
for i in col:
# 输出单元格名和值
print(i.coordinate, i.value)
# 每列做一个间隔
print('-------------- 下一列 --------------')输出结果
A1 None
A2 None
A3 None
A4 None
-------------- 下一列 --------------
B1 None
B2 None
B3 None
B4 None
-------------- 下一列 --------------
C1 None
C2 包子
C3 卖火柴
C4 西瓜
-------------- 下一列 --------------
D1 None
D2 面条
D3 卖火机
D4 香蕉
-------------- 下一列 --------------
E1 None
E2 稀饭
E3 卖石油
E4 苹果
-------------- 下一列 --------------
F1 None
F2 油条
F3 卖火石
F4 蓝莓
-------------- 下一列 --------------
G1 None
G2 豆浆
G3 None
G4 石榴
-------------- 下一列 --------------
2.7. 读取最大行号/列号
- 分别返回当前工作表中最大的行数和最大的列数,可以用来遍历整个工作表的数据。
语法
# 查看最后一行的行号
[工作表].max_row
# 查看最后一列的列号
[工作表].max_column
查看最后一行行号,输出最后一行的值
import openpyxl
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 获取最大行
max_rows = wb_sheet.max_row
print(f'存在数据的最大行为:{max_rows}')
# 通过行号遍历最后一行的数据
for i in wb_sheet[max_rows]:
print(i.coordinate, i.value)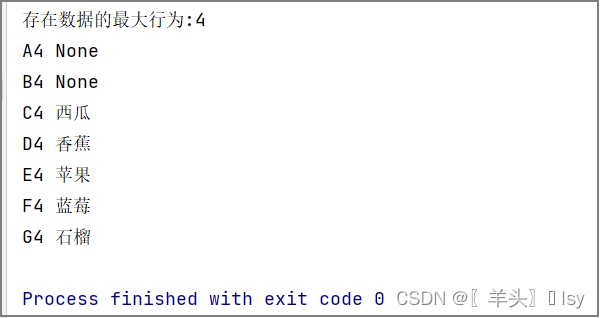
查看最后一列的列号
import openpyxl
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 获取最大行
max_col = wb_sheet.max_column
print(f'存在数据的最大列为:{max_col}')
2.8. 判断空行、列
openpyxl 中没有直接判断的方法,使用循环判断。判断图表如下:
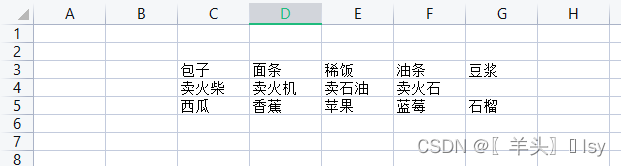
判断空行
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 获取最大行数、最大列数
max_row = wb_sheet.max_row
max_col = wb_sheet.max_column
# 通过行数、列数去遍历
for row in wb_sheet.iter_rows(max_row=max_row, max_col=max_col):
# 判断空行
if all(cell.value is None for cell in row):
print(f'第{row[0].row}行是空行')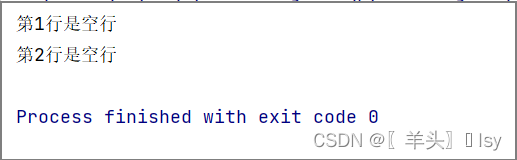
判断空列的方法与空行相似
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 获取最大行数、最大列数
max_row = wb_sheet.max_row
max_col = wb_sheet.max_column
# 通过行数、列数去遍历
for col in wb_sheet.iter_cols(max_row=max_row, max_col=max_col):
# 判断空列
if all(cell.value is None for cell in col):
print(f'第{col[0].column_letter}行是空列')
3. 设置Excel格式
3.1. 56种颜色代码
| 索引值 | 颜色名称 | 颜色代码 |
| 0 | 黑色 | 000000 |
| 1 | 白色 | FFFFFF |
| 2 | 红色 | FF0000 |
| 3 | 深红色 | 800000 |
| 4 | 黄色 | FFFF00 |
| 5 | 绿色 | 00FF00 |
| 6 | 深绿色 | 8000 |
| 7 | 蓝色 | 0000FF |
| 8 | 深蓝色 | 80 |
| 9 | 洋红色 | FF00FF |
| 10 | 深洋红色 | 800080 |
| 11 | 青色 | 00FFFF |
| 12 | 深青色 | 8080 |
| 13 | AutoCAD | FF9933 |
| 14 | 自定义1 | FF6600 |
| 15 | 自定义2 | FFCC00 |
| 16 | 棕色 | 993300 |
| 17 | 橄榄绿 | 333300 |
| 18 | 深橄榄绿 | 333333 |
| 19 | 深灰色 | 808080 |
| 20 | 浅灰色 | C0C0C0 |
| 21 | 橙色 | FF9900 |
| 22 | 蓝灰色 | 666699 |
| 23 | 白色网格 | F2F2F2 |
| 24 | 淡黄色 | FFFFCC |
| 25 | 亮绿色 | C8D531 |
| 26 | 光绿松石 | 99CCFF |
| 27 | 浅天蓝 | 99CC00 |
| 28 | 淡蓝色 | CCFFFF |
| 29 | 玫瑰色 | FF99CC |
| 30 | 薰衣草色 | CC99FF |
| 31 | 棕褐色 | CC9966 |
| 32 | 浅蓝色 | 99CCFF |
| 33 | 水绿色 | 00FFFF |
| 34 | 石灰色 | CCFF00 |
| 35 | 黄金色 | CC9900 |
| 36 | 天蓝色 | 0066CC |
| 37 | 杨李色 | CC99CC |
| 38 | 浅橙色 | FEBF00 |
| 39 | 鲜肉色 | FFBF00 |
| 40 | 深棕色 | 663300 |
| 41 | 橄榄褐色 | 333300 |
| 42 | 深红色 | 660000 |
| 43 | 暗黄色 | 999900 |
| 44 | 森林绿色 | 6600 |
| 45 | 绿松石色 | 3399FF |
| 46 | 蓝灰色 | 666699 |
| 47 | 蓝绿色 | 6699 |
| 48 | 灰色40 | 969696 |
| 49 | 灰色 25 | C0C0C0 |
| 50 | 天蓝色 | 0066CC |
| 51 | 茶色 | FFC000 |
| 52 | 深绿色 | 3300 |
| 53 | 浅绿色 | 00FFFF |
| 54 | 玫瑰红 | FFAFAF |
| 55 | 杨李色 | 800080 |
3.2. 设置字体属性
- 例如:字体名称、字号、颜色和是否加粗等。
语法
openpyxl.styles.Font(
name="Calibri" #字体名称(Arial、Calibri、Times New Roman、Verdana、Helvetica、Tahoma)
size=11 #字体大小
bold=False #是否加粗
italic=False #是否倾斜
underline="none" #下划线类型
color="000000" #字体颜色,红(FF0000)、橙(993300)、黄(FFFF00)、绿(00FF00)、青(00FFFF)、蓝(0000FF)、紫(CC99FF)
scheme="None" #字体下划线颜色方案
strike=False #删除线。
)设置单个单元格属性
import openpyxl
from openpyxl.styles import Font
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet1']
# 指定坐标A1,设置属性(颜色:红色)
wb_sheet['A1'].font = Font(color='FF0000')
# 指定坐标(1行2列)和(2行2列)为蓝色
wb_sheet.cell(row=1, column=2).font = Font(color='0000FF')
wb_sheet.cell(row=2, column=2).font = Font(color='0000FF')
# 保存文件
wb.save('./tmp.xlsx')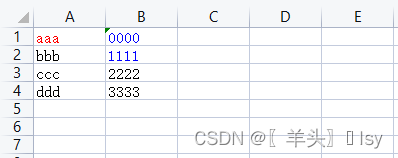
设置某个工作表所有存在数据的单元格属性
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 将工作表所有存在数据的单元格设置属性(获取最大行数、最大列数)
max_row = wb_sheet.max_row
max_col = wb_sheet.max_column
# 通过行数、列数去遍历
for row in wb_sheet.iter_rows(max_row=max_row, max_col=max_col):
# 遍历单个单元格
for cell in row:
# 设置属性(字体大小:18,字体加粗,字体删除线)
cell.font = openpyxl.styles.Font(size=18, bold=True,strike=True)
#保存文件
wb.save('./tmp.xlsx')
指定表格设置属性
import openpyxl
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet2']
# 指定开始行、结束行;开始列,结束列设置属性
start_row,end_row = 1,3 #1-3行
start_col,end_col = 2,4 #2-4列
# 通过行数、列数去遍历
for row in wb_sheet.iter_rows(min_row=start_row, max_row=end_row, min_col=start_col, max_col=end_col):
# 遍历单个单元格
for cell in row:
# 设置属性(字体颜色:红色)
cell.font = openpyxl.styles.Font(color='FF0000')
#保存文件
wb.save('./tmp.xlsx')
3.3. 设置填充属性
- 例如:填充类型、填充颜色、前景色、背景色等。
语法
openpyxl.styles.PatternFill(
fill_type #填充类型
fg_color #前景颜色
bg_color #背景颜色
start_color #开始颜色
end_color #结束颜色,仅在 fill_type 为 “gradient” 时有效
pattern_type #填充的图案类型,只有在 fill_type 为 “solid” 或 “light* / dark*” 等条纹填充时有效
)
填充类型包含:
none #不填充
solid #实心填充
mediumGray, darkGray, lightGray, black: 灰阶填充
darkHorizontal, darkVertical, darkDown, darkUp, darkGrid, darkTrellis,lightHorizontal, lightVertical, lightDown, lightUp, lightGrid, lightTrellis: 线条或块条纹填充
gray0625 #62.5% 灰阶填充
gradient #渐变填充
path #自定义填充
填充的图案类型包括:
none #无图案
solid #单色图案
gray0625 #62.5% 灰阶图案
mediumGray, darkGray, lightGray, black: 灰阶图案
darkHorizontal, darkVertical, darkDown, darkUp, darkGrid, darkTrellis, lightHorizontal, lightVertical, lightDown, lightUp, lightGrid, lightTrellis: 线条或块条纹图案
示例(设置背景色为绿色)
from openpyxl import load_workbook
from openpyxl.styles import PatternFill
wb = load_workbook('./tmp.xlsx')
wb_sheet = wb['Sheet1']
# 设置A1填充类型为实心填充,背景颜色为绿色
wb_sheet['A1'].fill = PatternFill(fill_type='solid', start_color='00FF00')
# 设置A2填充类型为条纹填充,背景颜色为红色,条纹颜色为黄色
wb_sheet['A2'].fill = PatternFill(fill_type='lightVertical', start_color='FF0000', end_color='FFFF00')
wb.save('./tmp.xlsx')
3.4. 设置对齐属性
- 例如:水平对齐方式、垂直对齐方式、自动换行等。
语法
openpyxl.styles.Alignment(
horizontal #水平对齐方式, 默认general(一般对齐)
vertical #垂直对齐方式
wrap_text #是否自动换行(True 或 False)
shrink_to_fit #是否缩小字体以适应单元格大小(True 或 False)
indent #缩进级别(0-255)
reading_order #读取顺序(1: 从左到右; 2: 从右到左)
)
水平对齐选项:
general #默认值,一般对齐
left #左对齐
center #居中对齐
right #右对齐
fill #填充对齐
justify #两端对齐
centerContinuous #连续居中对齐(仅限于分布居中)
distributed #分布对齐
垂直对齐选项:
top #上对齐
center #居中对齐
bottom #下对齐
justify #两端对齐
distributed #分布对齐
示例(设置单个单元格对齐方式)
from openpyxl import load_workbook
from openpyxl.styles import Alignment
wb = load_workbook('./tmp.xlsx')
wb_sheet = wb['Sheet1']
# 居中对齐
wb_sheet['A1'].alignment = Alignment(horizontal='center', vertical='center')
# 左对齐,自动换行,缩小字体以适应单元格大小
wb_sheet['A2'].alignment = Alignment(horizontal='left', vertical='top', wrap_text=True, shrink_to_fit=True)
# 分布对齐
wb_sheet['A3'].alignment = Alignment(horizontal='distributed', vertical='center')
wb.save('./tmp.xlsx')
示例(设置多个单元格对齐)
from openpyxl import load_workbook
from openpyxl.styles import Alignment
wb = load_workbook('./tmp.xlsx')
wb_sheet = wb['Sheet1']
# 设置单元格的对齐方式为居中
alignment = Alignment(horizontal='center', vertical='center')
# 设置开始行号和结束行号、开始列号和结束列号
start_rows,end_rows = 2,5
start_col, end_col = 2,5
# 采用遍历的方式分别对各个单元格设置对齐方式
for row in wb_sheet.iter_rows(min_row=start_rows, max_row=end_rows, min_col=start_col, max_col=end_col):
for cell in row:
# 为每个单元格设置对齐方式
cell.alignment = alignment
wb.save('./tmp.xlsx')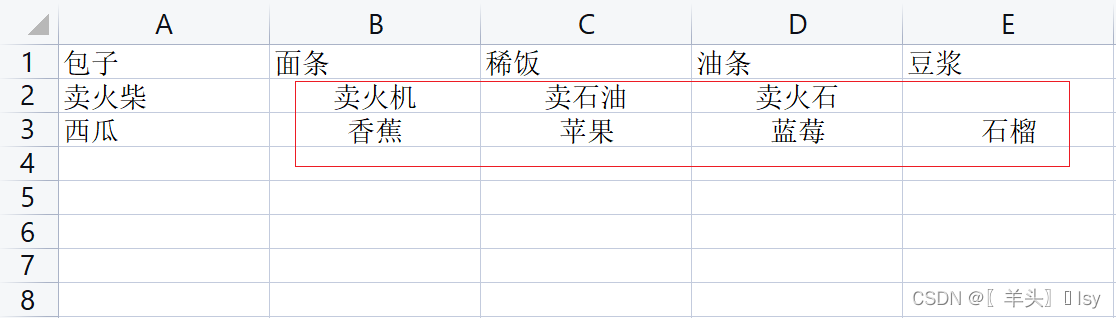
3.5. 设置边框属性
- 例如:边框样式、边框颜色、边框位置等。
语法
openpyxl.styles.Border(
left #左边框样式(参考下方选项)
right #右边框样式(参考下方选项)
top #上边框样式(参考下方选项)
bottom #下边框样式(参考下方选项)
diagonal #对角线样式(参考下方选项)
diagonal_direction #对角线方向(up: 对角线从下到上; down: 对角线从上到下)
diagonal_color #对角线颜色,同颜色规范
)
边框样式选项:
none #没有边框
thin #细边框
medium #中等边框
dashed #虚线边框
dotted #点线边框
thick #粗边框
double #双边框
hair #细边框,类似于毛发
mediumDashDot #中等虚线边框
dashDot #虚线点线边框
mediumDashDotDot #中等点线点线边框
dashDotDot #虚线点线点线边框
mediumDashed #中等虚线边框举例(设置单个单元格边框)
from openpyxl import load_workbook
from openpyxl.styles import Border,Side
wb = load_workbook('./tmp.xlsx')
wb_sheet = wb['Sheet1']
# 为 A1 单元格添加双线边框,颜色为红色
border = Border(
left=Side(style='double', color='FF0000'),
right=Side(style='double', color='FF0000'),
top=Side(style='double', color='FF0000'),
bottom=Side(style='double', color='FF0000')
)
wb_sheet['A1'].border = border
# 为 A2 单元格添加细虚线边框,颜色为蓝色
thin_border = Border(
left=Side(style='thin', color='0000FF'),
right=Side(style='thin', color='0000FF'),
top=Side(style='thin', color='0000FF'),
bottom=Side(style='thin', color='0000FF')
)
wb_sheet['A2'].border = thin_border
wb.save('./tmp.xlsx')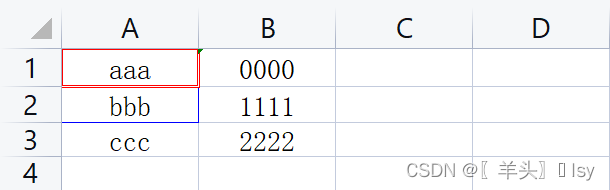
举例(设置多个单元格边框),使用遍历逐个设置边框
from openpyxl import load_workbook
from openpyxl.styles import Border,Side
wb = load_workbook('./tmp.xlsx')
wb_sheet = wb['Sheet1']
# 准备一个虚线边框模板,颜色为红色
thin_border = Border(
left=Side(style='thin', color='FF0000'),
right=Side(style='thin', color='FF0000'),
top=Side(style='thin', color='FF0000'),
bottom=Side(style='thin', color='FF0000')
)
# 设置开始行号和结束行号、开始列号和结束列号
start_rows,end_rows = 2,5
start_col, end_col = 2,5
# 采用遍历的方式分别对各个单元格设置边框
for row in wb_sheet.iter_rows(min_row=start_rows, max_row=end_rows, min_col=start_col, max_col=end_col):
for cell in row:
# 为每个单元格设置边框
cell.border = thin_border
wb.save('./tmp.xlsx')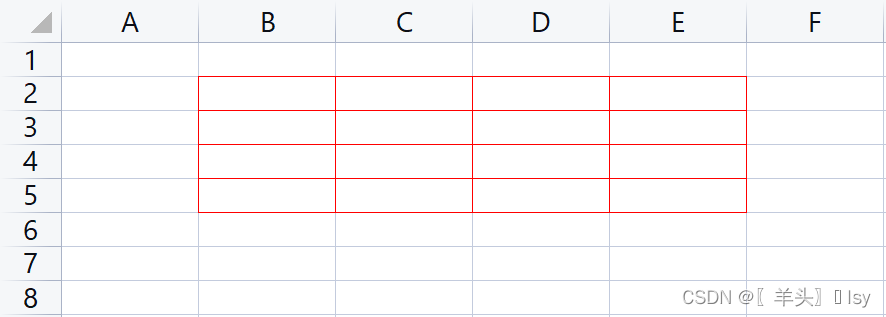
3.6. 合并单元格
- 分别用于合并指定区域中的单元格和取消已经合并的单元格区域。
合并单元格语法
worksheet.merge_cells(
range_string=None #指定要合并的单元格范围。例如:A1:A2
start_row=None #是合并范围的左上角单元格的行号。
start_column=None #是合并范围的左上角单元格的列号。
end_row=None #是合并范围的右下角单元格的行号。
end_column=None #是合并范围的右下角单元格的列号。
)- 当指定
range_string参数时,将自动计算另外4个参数。 - 如果同时指定了5个参数参数,则以
range_string参数为准。
取消合并单元格语法
worksheet.unmerge_cells(
range_string=None #指定要取消的合并单元格的范围。
start_row=None #是要取消的合并单元格的左上角单元格的行号。
start_column=None #是要取消的合并单元格的左上角单元格的列号。
end_row=None #是要取消的合并单元格的右下角单元格的行号。
end_column=None #是要取消的合并单元格的右下角单元格的列号。
)- 用法与合并单元格一致,不做举例说明
同一行合并(A1:B1,如果2个单元格都有数据,那么只保留A1;B1:A1 这种语法是错误的,合并行或列,必须从走往右、从上往下选择)
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet1']
# 指定A1和B1合并
wb_sheet.merge_cells('A1:B1')
# 保存文件
wb.save('./tmp.xlsx')
斜对行合并
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet1']
# 指定A1和B2合并(自动计算4个单元格)
wb_sheet.merge_cells('A1:B2')
# 保存文件
wb.save('./tmp.xlsx')
指定开始行、列和结束行列(自定义方法适用于遍历)
# 打开文件
wb = openpyxl.load_workbook('./tmp.xlsx')
# 指定工作表名
wb_sheet = wb['Sheet1']
# 指定开始行号、结束行号;开始列号、结束列号
wb_sheet.merge_cells(start_row=2, end_row=5, start_column=3, end_column=7)
# 保存文件
wb.save('./tmp.xlsx')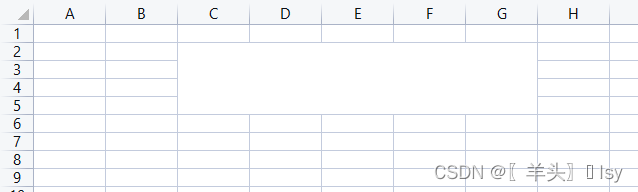
3.7. 设置组合样式
from openpyxl import load_workbook
from openpyxl.styles import Alignment,NamedStyle,Font,Border,Side,PatternFill
# 打开工作簿和对应的工作表
wb = load_workbook('./tmp.xlsx')
wb_sheet = wb['Sheet1']
# 定义一个名为 my_style 的样式对象
my_style = NamedStyle(name="my_style")
# 设置字体属性
my_style.font = Font(size=14, bold=True)
# 设置填充属性
my_style.fill = PatternFill(start_color='FFC7CE', end_color='FFC7CE', fill_type='solid')
# 设置边框属性
my_style.border = Border(left=Side(style='thin', color='000000'),
right=Side(style='thin', color='000000'),
top=Side(style='thin', color='000000'),
bottom=Side(style='thin', color='000000'))
my_style.alignment = Alignment(horizontal='center', vertical='center')
# 设置开始行号和结束行号、开始列号和结束列号
start_rows,end_rows = 1,3
start_col, end_col = 1,5
# 采用遍历的方式分别对各个单元格设置对齐方式
for row in wb_sheet.iter_rows(min_row=start_rows, max_row=end_rows, min_col=start_col, max_col=end_col):
for cell in row:
# 为每个单元格设置自定义的属性
cell.style = my_style
# 保存文件
wb.save('./tmp.xlsx')
# 关闭文件
wb.close()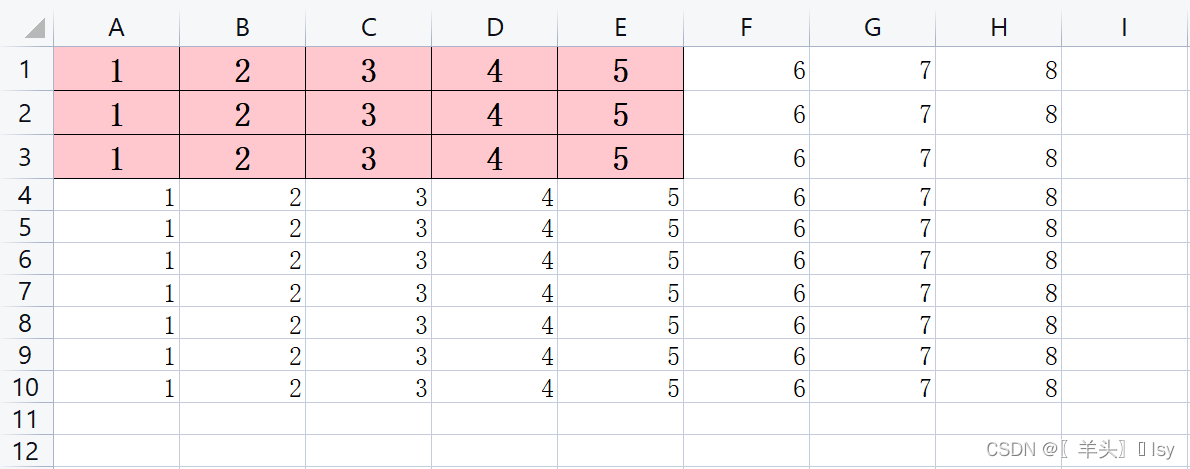
4. 其他方法
4.1. csv文件导入Excel
通过 pandas.read_csv 读取csv文件内容,语法如下
pandas.read_csv(
filepath_or_buffer #必选参数,指定文件
sep #可选参数,指定分隔符(默认逗号)
delimiter #可选参数,指定分隔符,与sep一样,可用任何长度的字符串作为分隔符。
skipinitialspace #可选参数,忽略分隔符后的空白,默认为False。
header #可选参数,指定第n行作为每列的列名(例如指定第2行,那么不会输出第1行)
names #可选参数,指定列名(例如:names=['AA','BB','CC','DD'],使用列表给每列取列名)
usecols #可选参数,通过索引指定列数( [0,1,2] 和 [0,2,1] 读取的结果一致,不会更改数据的顺序)
nrows #指定读取的行数(nrows=1 读取第2行)
skiprows #可选参数,指定跳过某行(skiprows=[0,2] 跳过1和3行)
skipfooter #可选参数,指定跳过尾部行数(skipfooter=2 跳过最后2行)
encoding #指定编码格式,默认为None,使用系统默认编码。
)通过 to_excel 保存到Excel文件,语法如下
to_excel(
excel_writer #指定工作簿名
sheet_name #指定工作表名
startrow #写入数据的起始行
startcol #写入数据的起始列。
float_format #精度设置。
columns #要写入的列,默认为None,表示写入所有列。
header #是否写入列名,默认为True。
index #是否写入索引,默认为True。
index_label #索引列的列名。
merge_cells #合并单元格。
encoding #指定编码格式,默认为None,使用系统默认编码。
)读取csv文件内容保存到Excel文件(如果存在该文件自动覆盖;如果不存在该文件自动创建)
import pandas
# 读取csv文件,指定分隔符
f = pandas.read_csv('./csv.txt', sep=',')
# 将csv文件内容覆盖到Excel,执行工作表名为AAA(默认为Sheet1)
f.to_excel('tmp.xlsx', index=False, sheet_name='AAA')
读取csv文件内容,保存到Excel指定一个新的Sheet
import pandas
# 读取csv文件
f = pandas.read_csv('./csv.txt', sep=',')
# 指定追加模式
with pandas.ExcelWriter('tmp.xlsx', mode='a') as w:
# 将追加一个工作表BBB到Excel文件,如果BBB存在则报错
f.to_excel(w, sheet_name='BBB', index=False)
读取csv文件内容,指定写入开始行(列)到Excel文件
import pandas
# 读取csv文件
f = pandas.read_csv('./csv.txt', sep=',')
# 指定追加模式
with pandas.ExcelWriter('tmp.xlsx', mode='a') as w:
# 指定工作表名(ccc),从第11行、4列开始写入数据
f.to_excel(w, sheet_name='CCC', index=False, startrow=10, startcol=3)
4.2. 画图
① 模块语法
matplotlib.pyplot 内置的方法
matplotlib.pyplot.[方法]
方法如下( plt 为 matplotlib.pyplot 的简称):
plt.title() #设置图表标题;
plt.xlabel() #设置x轴标签;
plt.ylabel() #设置y轴标签;
plt.grid() #添加网格线到图表中;
plt.legend() #在图表中添加图例;
plt.savefig() #将图表保存到指定的文件中。
plt.xticks() #设置x轴刻度标签;
plt.yticks() #设置y轴刻度标签;
plt.plot() #绘制折线图、散点图、条形图等;
plt.boxplot() #绘制箱体图;
plt.bar() #绘制垂直方向的条形图;
plt.hist() #绘制直方图;
plt.pie() #绘制饼图;
plt.imshow() #绘制图像;
plt.contour() #绘制等高线图;
plt.scatter() #绘制散点图;
plt.stem() #绘制干状图(即将每个点的值以线的形式展示);
plt.step() #绘制阶梯图;
plt.polar() #绘制极坐标图;
plt.subplots() #创建Figure对象和多个子图;
plt.semilogx() #以10为底的对数刻度绘制x轴;
plt.semilogy() #以10为底的对数刻度绘制y轴;
plt.loglog() #以10为底的对数刻度绘制x、y轴;
plt.fill() #填充两条曲线之间的区域;
plt.text() #在图表中添加文本注释;折线图语法(matplotlib.pyplot.plot)
matplotlib.pyplot.plot(
x #横坐标数组或一个可迭代对象;
y #纵坐标数组或一个可迭代对象;
c #散点图中点的颜色;
label #该图例标签的字符串;
linestyle #折线的样式;
linewidth #折线或线框的线宽;
marker #散点图的标记样式;
markersize #标记大小;
alpha #透明度;
edgecolors #散点或折线周围的颜色;
color #折线或线框的颜色;
markeredgecolor #标记边界的颜色;
markeredgewidth #标记边界的线宽;
markerfacecolor #标记内部的颜色;
linestyle #折线或线框的样式;
dash_capstyle #折线中间断点的样式;
dash_joinstyle #折线中间断点的连接样式;
solid_capstyle #线框起点或终点的样式;
solid_joinstyle #线框起点或终点在交叉区域的样式;
zorder #控制图层顺序,越大的值表示越靠近上层;
drawstyle #折线的绘制方式,可以是"steps-pre"、“steps-mid"或"steps-post”;
dashes #自定义折线的样式,例如[10, 5, 20, 5]表示线段长10,空隙长5,线段长20,空隙长5;
antialiased #抗锯齿效果,默认为True;
fillstyle #散点的填充样式,可以是"full"、“left”、“right"或"bottom”;
solid_joinstyle #线框起点或终点在交叉区域的样式;
visible #对象是否可见;
clip_on #是否将对象剪裁为轴范围内;
clip_path #剪裁路径;
markerfacecoloralt #用于面向未填充的标记的交替面颜色。
)柱状图语法(matplotlib.pyplot.bar)
matplotlib.pyplot.bar(
x #柱状图中每个柱的横坐标;
height #每个柱的高度;
width #每个柱的宽度,为浮点数或数组;
align #柱的对齐方式,可以是’center’、‘edge’、‘none’,分别表示居中对齐、边缘对齐和不对齐;
bottom #每个柱底部的高度;
log #是否使用对数坐标轴;
color #柱状的颜色,可以是单个颜色字符串,也可以是RGB或RGBA序列、灰度值或html字符串;
edgecolor #每个柱的边框颜色;
linewidth #每个边框的线宽;
hatch #每个柱填充的图案样式(纹理);
capsize #误差线末端箭头的长度;
error_kw #误差线相关参数:
elinewidth #误差线线宽;
capsize #误差线末端箭头的长度;
capthick #误差线末端箭头的厚度;
ecolor #误差线颜色。
align #对齐方式,可以是“edge”,“center”。
label #柱状图的标签;
alpha #透明度;
visible #是否可见;
zorder #控制图层顺序,越大的值表示越靠近上层;
tick_label #柱状图的刻度标签;
xerr #绘制误差线;
yerr #绘制误差线。
)颜色写法
red:红色
g:绿色
b:蓝色
c:青色
m:品红
y:黄色
k:黑色
w:白色。
② 折线图
Excel数据如下:
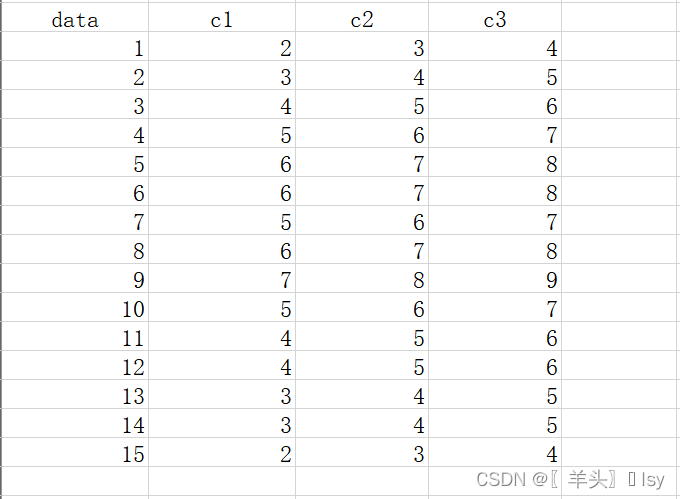
读取3列数据,绘制折线图
import pandas
import matplotlib.pyplot as plt
# 防止乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 读取Excel文件内容,如果读取csv文件,则使用pandas.read_csv
df = pandas.read_excel('./tmp.xlsx', sheet_name='AAA')
# 提取横坐标的数据(常见的:日期,时长)
x = df['data'].to_numpy()
# 通过列名(c1/c2/c3)提取画图的数据
y1 = df['c1'].to_numpy()
y2 = df['c2'].to_numpy()
y3 = df['c3'].to_numpy()
# 绘制折线图
plt.plot(x, y1, label='c1') # 指定纵坐标y1,并自定义图例标题为c1
plt.plot(x, y2, label='c2') # 指定纵坐标y2,并自定义图例标题为c2
plt.plot(x, y3, label='c3') # 指定纵坐标y3,并自定义图例标题为c3
plt.legend() # 显示图例标题
plt.xlabel('横坐标名称')
plt.ylabel('纵坐标名称')
plt.title('折线图标题')
plt.savefig('./aa.jpg') # 保存图片
plt.show() #查看图片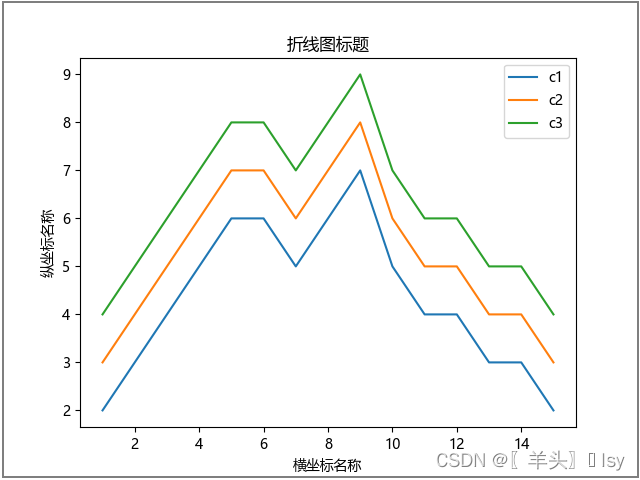
如果列名没有在第一行,那么在读取的时候直接跳过n行
# 读取Excel文件内容,header跳过前10行
df = pandas.read_excel('./tmp.xlsx', sheet_name='AAA', header=10)
增加属性(标记点、网格、跳过n行)
import pandas
import matplotlib.pyplot as plt
# 防止乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 读取Excel文件内容,如果读取csv文件,则使用pandas.read_csv
df = pandas.read_excel('./tmp.xlsx', sheet_name='AAA', header=40)
# 提取横坐标的数据(常见的:日期,时长)
x = df['data'].to_numpy()
# 通过列名(c1/c2/c3)提取画图的数据
y1 = df['c1'].to_numpy()
y2 = df['c2'].to_numpy()
y3 = df['c3'].to_numpy()
# 定义图表大小(长15,高8)
plt.figure(figsize=(15,8))
# 绘制折线图。label自定义图例名称,marker自定义标记样式,markersize指定标记大小
plt.plot(x, y1, label='c1', marker='o', markersize=3)
plt.plot(x, y2, label='c2', marker='o', markersize=3)
plt.plot(x, y3, label='c3', marker='o', markersize=3)
plt.legend() #显示图例标题
plt.grid() #显示网格线
plt.xlabel('横坐标名称')
plt.ylabel('纵坐标名称')
plt.title('折线图标题')
plt.savefig('./aa.jpg') # 保存图片
plt.show() #查看图片
③ 柱状图
多条柱状图重叠
import pandas
import matplotlib.pyplot as plt
# 防止乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 读取Excel文件内容
df = pandas.read_excel('./tmp.xlsx', sheet_name='AAA', header=40)
# 提取横坐标的数据(常见的:日期,时长)
x = df['data'].to_numpy()
# 通过列名(c1/c2/c3)提取画图的数据
y1 = df['c1'].to_numpy()
y2 = df['c2'].to_numpy()
y3 = df['c3'].to_numpy()
# 定义图表大小(长15,高8)
plt.figure(figsize=(15,8))
# 绘制折线图(label为自定义图例名称;width为柱状宽0-1;alpha为透明度0-1;edgecolor为边框颜色)
plt.bar(x, y1, label='c1', width=0.5, alpha=0.5, edgecolor='black')
plt.bar(x, y2, label='c2', width=0.5, alpha=0.5, edgecolor='black')
plt.bar(x, y3, label='c3', width=0.5, alpha=0.5, edgecolor='black')
plt.legend() # 显示图例标题
plt.xlabel('横坐标名称')
plt.ylabel('纵坐标名称')
plt.title('折线图标题')
# plt.savefig('./aa.jpg') # 保存图片
plt.show() #查看图片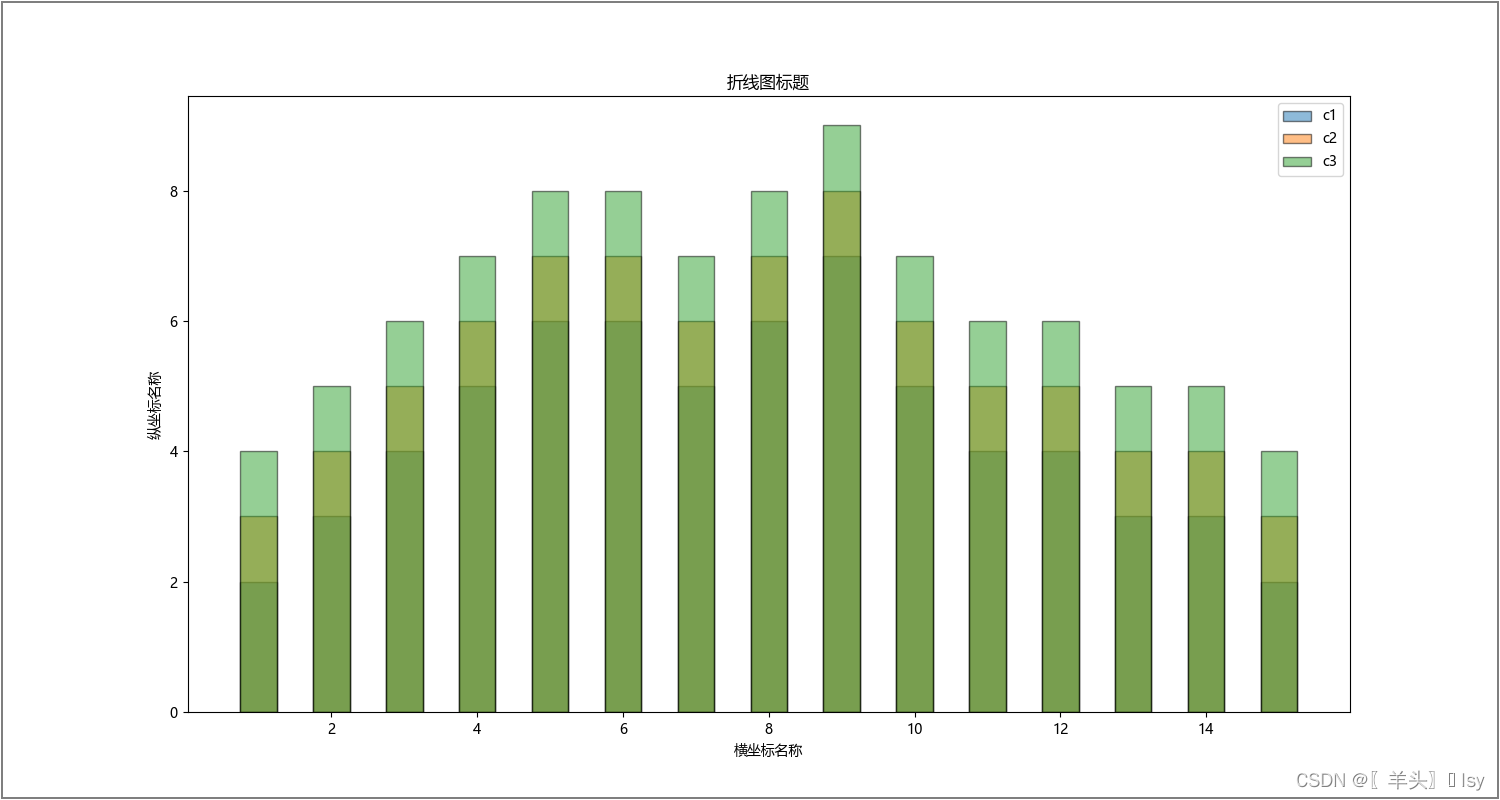
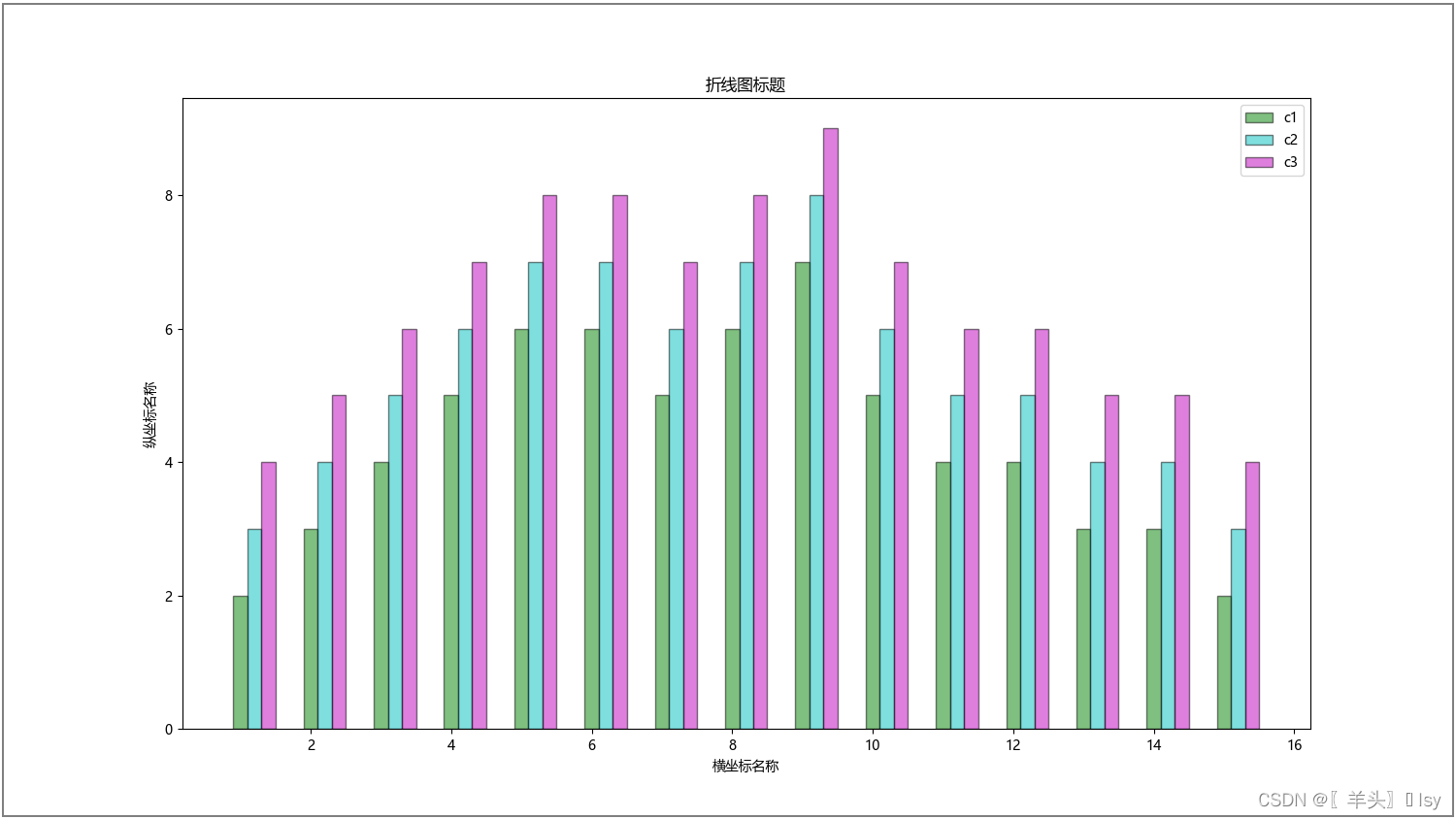
多条图形重叠颜色难以区分,让x轴+n(右移动n)
import pandas
import matplotlib.pyplot as plt
# 防止乱码
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 读取Excel文件内容
df = pandas.read_excel('./tmp.xlsx', sheet_name='AAA', header=40)
# 提取横坐标的数据(常见的:日期,时长)
x = df['data'].to_numpy()
# 通过列名(c1/c2/c3)提取画图的数据
y1 = df['c1'].to_numpy()
y2 = df['c2'].to_numpy()
y3 = df['c3'].to_numpy()
# 定义图表大小(长15,高8)
plt.figure(figsize=(15,8))
# 绘制折线图(label为自定义图例名称;width为柱状宽0-1;alpha为透明度0-1;edgecolor为边框颜色;color为柱状颜色)
plt.bar(x, y1, label='c1', width=0.2, alpha=0.5, edgecolor='black',color='g')
plt.bar(x+0.2, y2, label='c2', width=0.2, alpha=0.5, edgecolor='black',color='c')
plt.bar(x+0.4, y3, label='c3', width=0.2, alpha=0.5, edgecolor='black',color='m')
plt.legend() # 显示图例标题
plt.xlabel('横坐标名称')
plt.ylabel('纵坐标名称')
plt.title('折线图标题')
plt.savefig('./aa.jpg') # 保存图片
plt.show() #查看图片