先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上图为例:
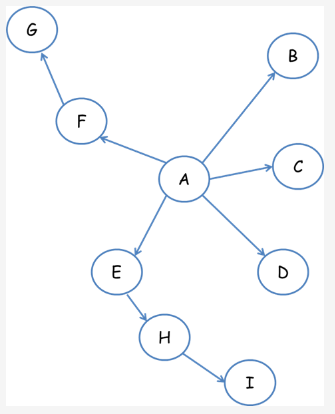
遍历路径:第一层:A-B-C-D-E-F,第二层:G-H,第三层:I
广度优先遍历策略会彻底遍历整个网络图,效率较低,但覆盖网页较广。
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数反映一个网页的内容受到其他人推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
而现实是网络环境存在各种广告链接、作弊链接的干扰,使得许多反向链接数反映的结果并不可靠。
4.Partial PageRank策略
Partial PageRank策略借鉴了PageRank算法的思想:对于已下载网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,然后将待抓取URL队列中的URL按照PageRank值的大小进行排列,并按照该顺序抓取页面。
若每次抓取一个页面,就重新计算PageRank值,则效率太低。
一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。而对于已下载页面中分析出的链接,即暂时没有PageRank值的未知网页那一部分,先给未知网页一个临时的PageRank值,再将这个网页所有链接进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。以下图为例:
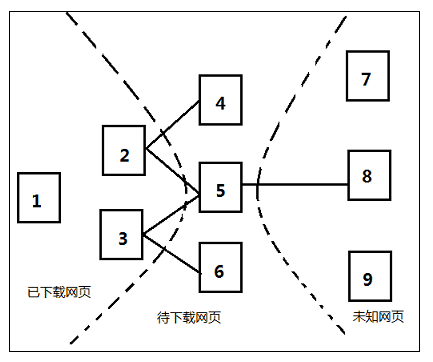
设k值为3,即每抓取3个页面后,重新计算一次PageRank值。
已知有{1,2,3}这3个网页下载到本地,这3个网页包含的链接指向待下载网页{4,5,6}(即待抓取URL队列),此时将这6个网页形成一个网页集合,对其进行PageRank值的计算,则{4,5,6}每个网页得到对应的PageRank值,根据PageRank值从大到小排序,由图假设排序结果为5,4,6,当网页5下载后,分析其链接发现指向未知网页8,这时先给未知网页8一个临时的PageRank值,如果这个值大于网页4和6的PageRank值,则接下来优先下载网页8,由此思路不断进行迭代计算。
5.OPIC策略
此算法其实也是计算页面重要程度。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数大小进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。待下载页面数多的网站优先下载。
二、爬虫的基本流程
首先简单了解关于Request和Response的内容:
Request:浏览器发送消息给某网址所在的服务器,这个请求信息的过程叫做HTTP Request。
Response:服务器接收浏览器发送的消息,并根据消息内容进行相应处理,然后把消息返回给浏览器。这个响应信息的过程叫做HTTP Response。浏览器收到服务器的Response信息后,会对信息进行相应处理,然后展示在页面上。
根据上述内容将网络爬虫分为四个步骤:
1.发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应。
常见的请求方法有两种,GET和POST。get请求是把参数包含在了URL(Uniform Resource Locator,统一资源定位符)里面,而post请求大多是在表单里面进行,也就是让你输入用户名和秘密,在url里面没有体现出来,这样更加安全。post请求的大小没有限制,而get请求有限制,最多1024个字节。
2.获取响应内容:如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML,Json字符串,二进制数据(如图片视频)等类型。
3.解析内容:得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是Json,可以直接转为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理。
在Python语言中,我们经常使用Beautiful Soup、pyquery、lxml等库,可以高效的从中获取网页信息,如节点的属性、文本值等。
Beautiful Soup库是解析、遍历、维护“标签树”的功能库,对应一个HTML/XML文档的全部内容。安装方法非常简单,如下:
#安装方法
pips install beautifulsoup4
#验证方法
from bs4 import BeautifulSoup
4.保存数据:如果数据不多,可保存在txt 文本、csv文本或者json文本等。如果爬取的数据条数较多,可以考虑将其存储到数据库中。也可以保存为特定格式的文件。
保存后的数据可以直接分析,主要使用的库如下:NumPy、Pandas、 Matplotlib。
NumPy:它是高性能科学计算和数据分析的基础包。
Pandas : 基于 NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。它可以算得上作弊工具。
Matplotlib:Python中最著名的绘图系统Python中最著名的绘图系统。它可以制作出散点图,折线图,条形图,直方图,饼状图,箱形图散点图,折线图,条形图,直方图,饼状图,箱形图等。
三、爬虫简单实例
运行平台: Windows
Python版本: Python3.7
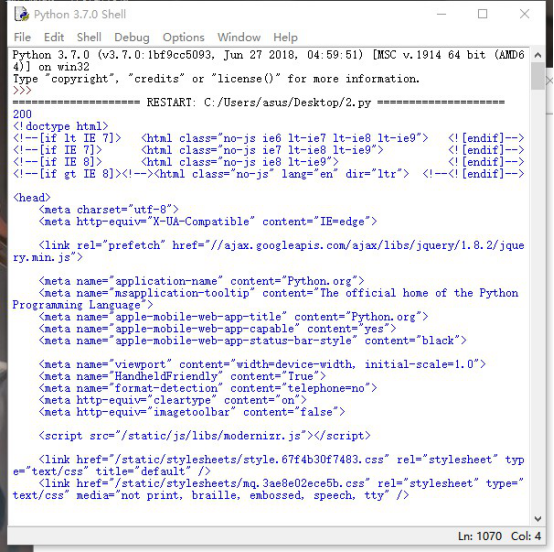
首先查看网址的源代码,使用google浏览器,右键选择检查,查看需要爬取的网址源代码,在Network选项卡里面,点击第一个条目可看到源代码。
第一部分是General,包括了网址的基本信息,比如状态 200等,第二部分是Response Headers,包括了请求的应答信息,还有body部分,比如Set-Cookie,Server等。第三部分是,Request headers,包含了服务器使用的附加信息,比如Cookie,User-Agent等内容。
上面的网页源代码,在python语言中,我们只需要使用urllib、requests等库实现即可,具体如下。
import urllib.request
import socket
from urllib import error
try:
response \= urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.read().decode('utf-8'))
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep='\\n')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
运行结果如下:
四、关于入门爬虫
在如今这个信息爆炸的大数据时代,数据的价值是可观的,而网络爬虫无疑是一个获取数据信息的便捷途径。合理利用爬虫爬取有价值的数据,可以为我们的生活提供不少帮助。
实际上,关于网络爬虫,我完全是一个新手,写下这篇博客的途中也同时在零基础学习。
首先,我了解到python3的语法是需要掌握的,因为要打好基础。不过python3语法很简洁,学起来应该不会过分吃力。
接着是python的各种库,目前接触的不多,像我这种还是从基础的库开始学习会比较好,比如urlib、requests。
在学习过程中也了解到现在很多大型企业在使用反爬虫机制,爬虫过程中可能会返回非法请求,需要使用代理防止封禁IP,爬取网页需要伪装成平时正常使用浏览器那样。这又是另外要解决的问题了。
总之,对于新手来说是需要一步一步花时间深入学习的,平时也得多加练习,毕竟学习之事并非一朝一夕就能促成,重要的是坚持吧。
这里给大家分享一份Python全套学习资料,包括学习路线、软件、源码、视频、面试题等等,都是我自己学习时整理的,希望可以对正在学习或者想要学习Python的朋友有帮助!
1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~
③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!
因篇幅有限,仅展示部分资料
2️⃣国内外Python书籍、文档
① 文档和书籍资料

最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
70)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-aPb3ryvg-1713177465380)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!