❤❤风吹向我吧❤❤
MPI是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI的目标是高性能,大规模性,和可移植性。MPI在今天仍为高性能计算的主要模型。 主要的MPI-1模型不包括共享内存概念,MPI-2只有有限的分布共享内存概念。 但是MPI程序经常在共享内存的机器上运行。在MPI模型周边设计程序比在NUMA架构下设计要好因为MPI鼓励内存本地化。
一、MPI安装及配置
1、检查是否安装好了编译器(显示目录则表示已安装)
本实践基于ubuntu系统,通过下面的命令,检查是否安装了MPI的编译器:
which gcc
which gfortan如果没安装使用apt-get install命令安装

2、下载MPI
我们可以直接通过linux命令下载所需要的软件,我们可以通过下述命令进行下载:
cd ~
mkdir mpi #创建文件夹
cd mpi
wget http://www.mpich.org/static/downloads/3.3.2/mpich-3.3.2.tar.gz #下载
tar -zxvf mpich-3.3.2.tar.gz #解压
cd mpich-3.3.2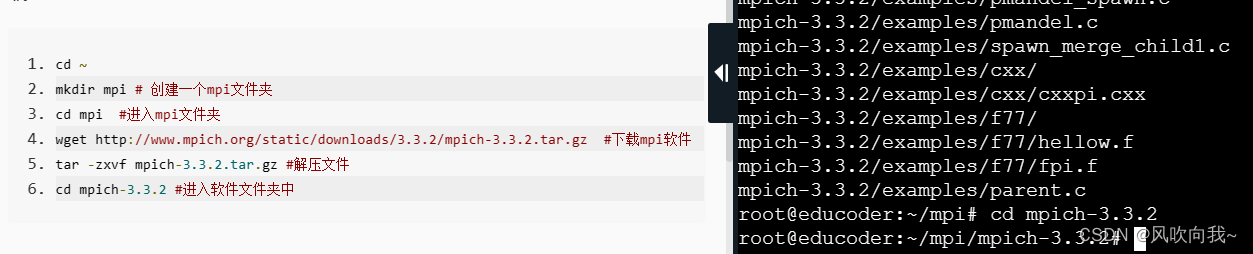
3、MPI安装
下载解压MPI后,这一步我们开始安装MPI,由于我们是源码安装,所以需要使用make进行编译:
./configure --prefix=/usr/local/mpich-3.3.2 #配置路径
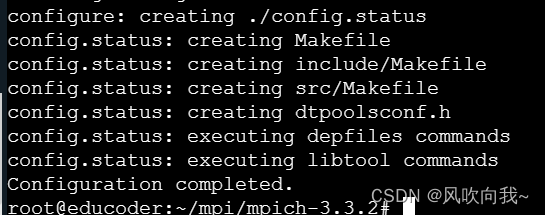
make编译

make install安装
4、环境配置
vim /etc/profile 进入vim编辑界面,添加以下代码(i进入插入模式,esc退出插入模式,:wq保存并退出
export PATH=/usr/local/mpich-3.3.2/bin:$PATH
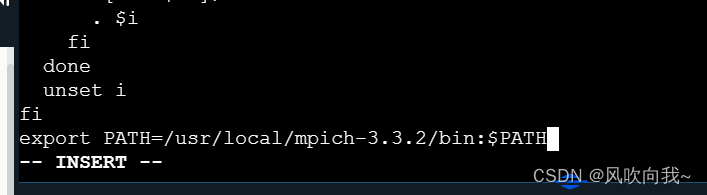
(必不可少❤❤❤)使用下面的命令,加载配置:
source /etc/profile
5、检查是否
使用which命令看是否安装并检查mpiexec的版本
which mpicc
which mpif90
mpiexec -version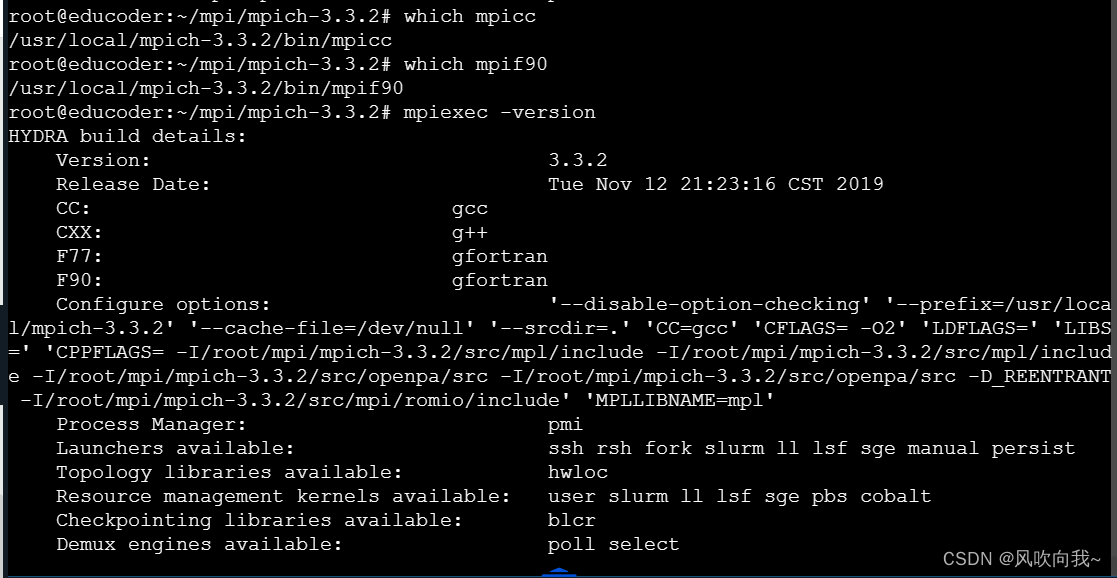
二、使用MPI运行“Hello World”
上面已经完成了MPI编译器的安装及环境配置,下面我们通过一个简单的例子熟悉MPI的用法
1、获取hellow可执行文件
进入解压目录下的examples,可以看到hellow.c源代码文件和hellow可执行文件,如果没有hellow,就需要编译hellow.c
cd ~/mpi/mpich-3.3.2/examples
mpicc -o hellow hellow.c
2、运行hellow文件
通过下面的命令运行hellow文件(4表示有4个进程),结果如图所示:
mpirun -np 4 ./hellow #其中的4便是4个进程
3、修改源代码并编译后运行
打开hellow.c的源码进行如下修改:
vim hellow.c 进入编辑模式,将以下内容写进代码里
char processorName[MPI_MAX_PROCESSOR_NAME];
int nameLength;
MPI_Get_processor_name(processorName, &nameLength);
printf("Hello world from processor %s, rank %d of %d\n", processorName, rank, size);
修改保存后,运行程序:
mpicc -o hellow hellow.c
mpirun -np 4 ./hellow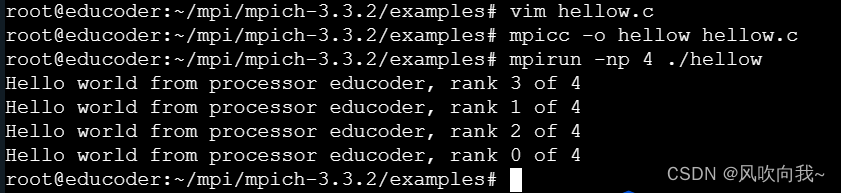
可以看到在源代码里每个MPI进程中打印“Hello from rank x of y”信息,其中x是进程的排名,y是进程的总数。
三、消息传递程序
编写程序send_recv_example.c:如果当前进程是进程0, 那么就初始化一个数字233, 然后把它发送给进程1。进程1会调用MPI_Recv去接收这个数字, 并打印出来。每个进程使用了666作为标签来指定消息。
1、编写消息传递程序
使用vim send_recv_example.c创建一个程序
vim send_recv_example.c程序内容如下:
#include<stdio.h>
#include<mpi.h>
int main(int argc, char *agrv[])
{
int rank;
int size;
int number = 233;
int tag = 666;
MPI_Init(0,0);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
if (rank == 0) {
MPI_Send(&number, 1, MPI_INT, 1, tag, MPI_COMM_WORLD);
} else if (rank == 1) {
MPI_Recv(&number, 1, MPI_INT, 0, tag, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("process 1 received number %d from process 0\n", number);
}
MPI_Finalize();
return 0;
}
运行结果:

2、编译程序并运行
使用下面命令对所写程序进行编译及运行。
mpicc -o send_recv_example send_recv_example.c
mpirun -np 2 ./send_recv_example❤❤以下作两个函数的解释 :
(1)MPI_Send
MPI_Seng(buffer, count, datatype, destination, tag, communicator)
第一个参数指明消息缓存的起始地址,即存放要发送的数据信息。
第二个参数指明消息中给定的数据类型有多少项,数据类型由第三个参数给定。
第三个参数是数据类型,要么是基本数据类型,要么是导出数据类型,后者由用户生成指定一个可能是由混合数据类型组成的非连续数据项。
第四个参数是目的进程的标识符(进程编号)。
第五个是消息标签。有时候 A 需要传递很多不同的消息给 B。为了让 B 能比较方便地区分不同的消息,MPI 运行发送者和接受者额外地指定一些信息 ID (正式名称是标签, tags)。当 B 只要求接收某种特定标签的信息的时候,其他的不是这个标签的信息会先被缓存起来,等到 B 需要的时候才会给 B。
第六个是参数标识进程和通信上下文,即通信域。通常,消息只在同组的进程间传递。但是MPI允许通过intercommunicators在组间通信。
(2)MPI_Recv
MPI_Recv(address, count, datatype, source, communicator, status)
第一个参数指明接收信息缓冲的起始地址,即存放接受消息的内存地址。
第二个参数指明给定数据类型可以被接收的最大项数。
第三个数据指明接收的数据类型。
四、乒乓程序
编写程序pingpong.c:这个程序是为2个进程执行而设计的。这两个进程一开始会根据我们写的一个简单的求余算法来确定各自的对手。ball一开始被初始化为0,然后每次发送消息之后会递增1。随着ball的递增,两个进程会轮流成为发送者和接受者。最后,当我们设定的limit被触发的时候,进程就停止了发送和接收。
1、编写乒乓球程序
使用vim pingpong.c命令,创建并编写程序,实现上述乒乓球传球过程程序。
vim pingpong.c代码如下:
#include<stdio.h>
#include<mpi.h>
void main(int argc, char *argv[])
{
MPI_Init(&argc,&argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
int ball = 0;
int partner = (rank + 1) % 2;
int limit = 10;
while(ball < limit)
{
if(rank == ball % 2)
{
ball++;
MPI_Send(&ball,1,MPI_INT,partner,0,MPI_COMM_WORLD);
printf("%d 向 %d 发出了第 %d 个球\n", rank, partner, ball);
}
else
{
MPI_Recv(&ball,1,MPI_INT,partner,0,MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
printf("%d 接到了第 %d 个球\n", rank, ball);
}
}
MPI_Finalize();
}
2、编译运行程序
对写好的程序进行编译和运行
mpicc -o pingpong pingpong.c
mpirun -np 2 ./pingpong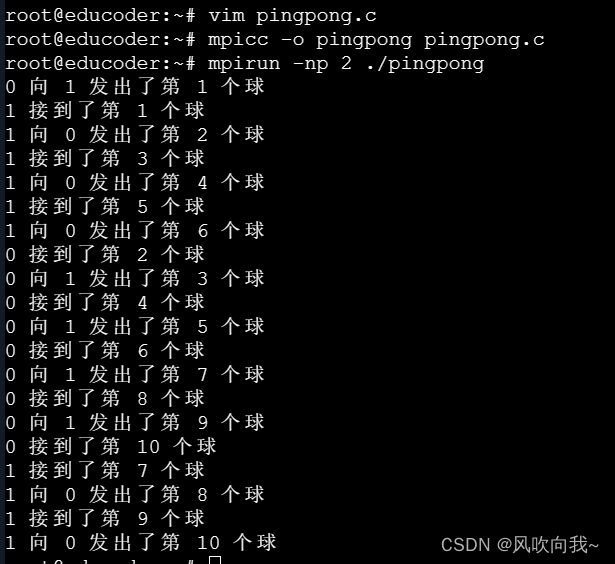
可以看到在这个乒乓球程序内,ball 一开始被初始化为0,然后每次发送消息之后会递增1。随着 ball 的递增,两个进程会轮流成为发送者和接受者。最后,当我们设定的 limit 被触发的时候(10),进程就停止了发送和接收。
五、环程序
编写程序loop.c:这个环程序在进程0上面初始化了一个值-1,赋值给token。然后这个值会依次传递给每个进程。程序会在进程0从最后一个进程接收到值之后结束。如你所见,我们的逻辑避免了死锁的发生。具体来说,进程0保证了在想要接受数据之前发送了token。其他的进程只是简单的调用MPI_Recv(从他们的邻居进程接收数据),然后调用MPI_Send(发送数据到他们的邻居进程)把数据从环上传递下去。MPI_Send和MPI_Recv会阻塞直到数据传递完成。因为这个特性,打印出来的数据是跟数据传递的次序一样的。
1、编写程序:
使用vim loop.c命令编写程序:
vim loop.c代码如下:
#include<stdio.h>
#include<mpi.h>
void main(int argc, char *argv[])
{
MPI_Init(&argc,&argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
int token;
if (rank == 0) {
token = -1;
MPI_Send(&token, 1, MPI_INT, (rank + 1) % size, 0, MPI_COMM_WORLD);
MPI_Recv(&token, 1, MPI_INT, size - 1, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("process %d received token %d from process %d\n", rank, token, size - 1);
} else {
MPI_Recv(&token, 1, MPI_INT, rank - 1, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Send(&token, 1, MPI_INT, (rank + 1) % size, 0, MPI_COMM_WORLD);
printf("process %d received token %d from process %d\n", rank, token, rank - 1);
}
MPI_Finalize();
}
2、编译运行程序
mpicc -o loop loop.c
mpirun -np 8 ./loop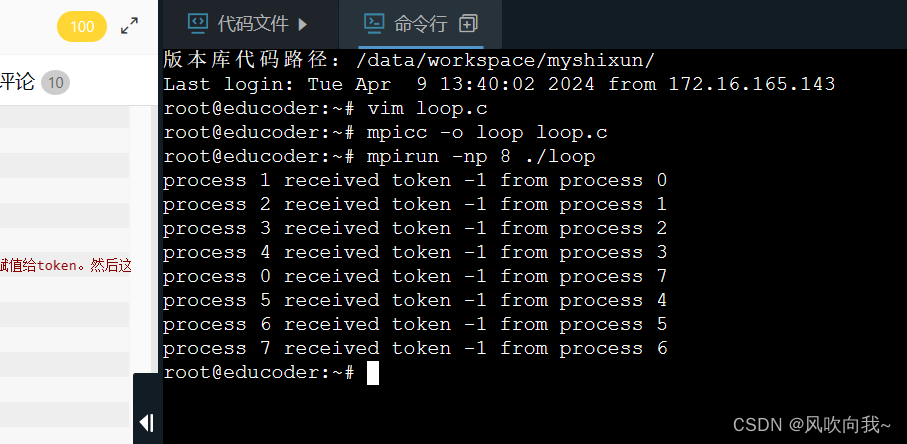
环程序就是在进程0上面初始化了一个值-1,赋值给 token。然后这个值会依次传递给每个进程。程序会在进程0从最后一个进程接收到值之后结束。具体来说,进程0保证了在想要接受数据之前发送了 token。所有其他的进程只是简单的调用MPI_Recv(从他们的邻居进程接收数据),然后调用MPI_Send(发送数据到他们的邻居进程)把数据从环上传递下去。MPI_Send和MPI_Recv会阻塞直到数据传递完成。因为这个特性,打印出来的数据是跟数据传递的次序一样的。
六、求Π值
串行程序实现:循环进行了n次, 每次计算都是独立的过程。如果用m个进程, 每个进程的循环次数可以减少到n/m次。
1、求π值得算法分析
下面的并行程序就是实现把独立循环拆解到多个进程上。
for (i=1; i<=n; i++)
{
sum += f((i-0.5)/n);
}
sum = sum / n;2、求微分程序编写
使用vim pi.c创建求微分的程序
vim pi.c以1、5、10个进程为例, 把500000000次循环计算分配给这些进程。每个进程计算的循环次数都是以总进程数为差的等差数列。rank不一样, 就不会产生重复计算。计算完后, 每个进程的sum仅包括自己的求和结果。用MPI_Send和MPI_Recv来把结果汇总比较麻烦, 这里采用规约函数。 MPI_Reduce(&temp, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,MPI_COMM_WORLD); 可以理解为在通信域MPI_COMM_WORLD中, 将各进程的MPI_DOUBLE型变量的起始地址(&temp)和长度(1)发送到缓冲区, 并执行MPI_SUM操作, 将结果返回至进程0的地址(&pi)。其实就是, 将每个进程的结果求和, 最终结果存入进程0的变量pi。
代码如下:
#include<stdio.h>
#include<mpi.h>
#include<time.h>
double f(double x)
{
return 4.0/(1.0+x*x);
}
void main(int argc, char *argv[])
{
clock_t begin, end;
double time;
begin = clock();
MPI_Init(&argc,&argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
printf("process %d of %d\n", rank, size);
int n = 500000000;
double sum = 0.0, x;
int start = rank * n / size;
int end_idx = (rank + 1) * n / size;
for (int i = start; i < end_idx; i++)
{
x = (i + 0.5) / n;
sum += f(x);
}
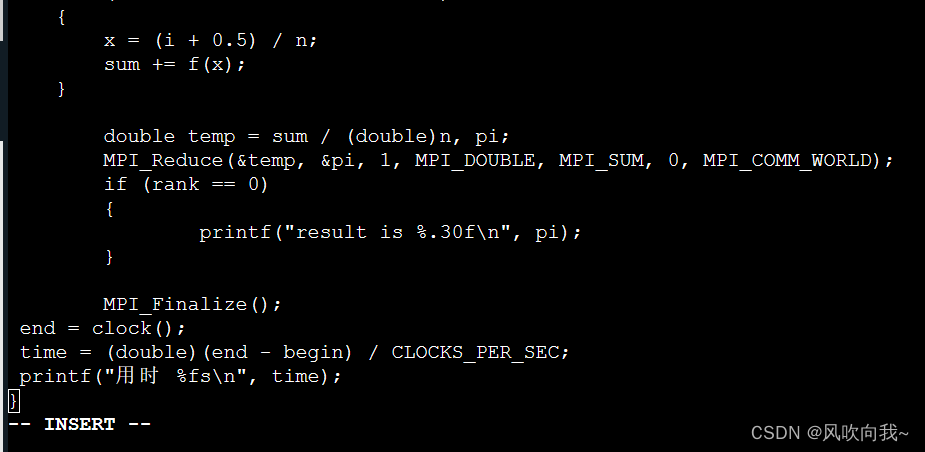
double temp = sum / (double)n, pi;
MPI_Reduce(&temp, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0)
{
printf("result is %.30f\n", pi);
}
MPI_Finalize();
end = clock();
time = (double)(end - begin) / CLOCKS_PER_SEC;
printf("用时 %fs\n", time);
}
2、编译运行程序
mpicc -o pi pi.c
mpirun -np 1 ./pi
mpirun -np 5 ./pi
mpirun -np 10 ./pi

规约函数MPI_Reduce:
它将每个进程的数据进行规约操作,并将结果发送到指定的进程。常见的规约操作包括求和、求最大值、求最小值等。每个进程将贡献数据发送给规约操作的目标进程,然后目标进程执行规约操作,并将结果返回给所有进程。
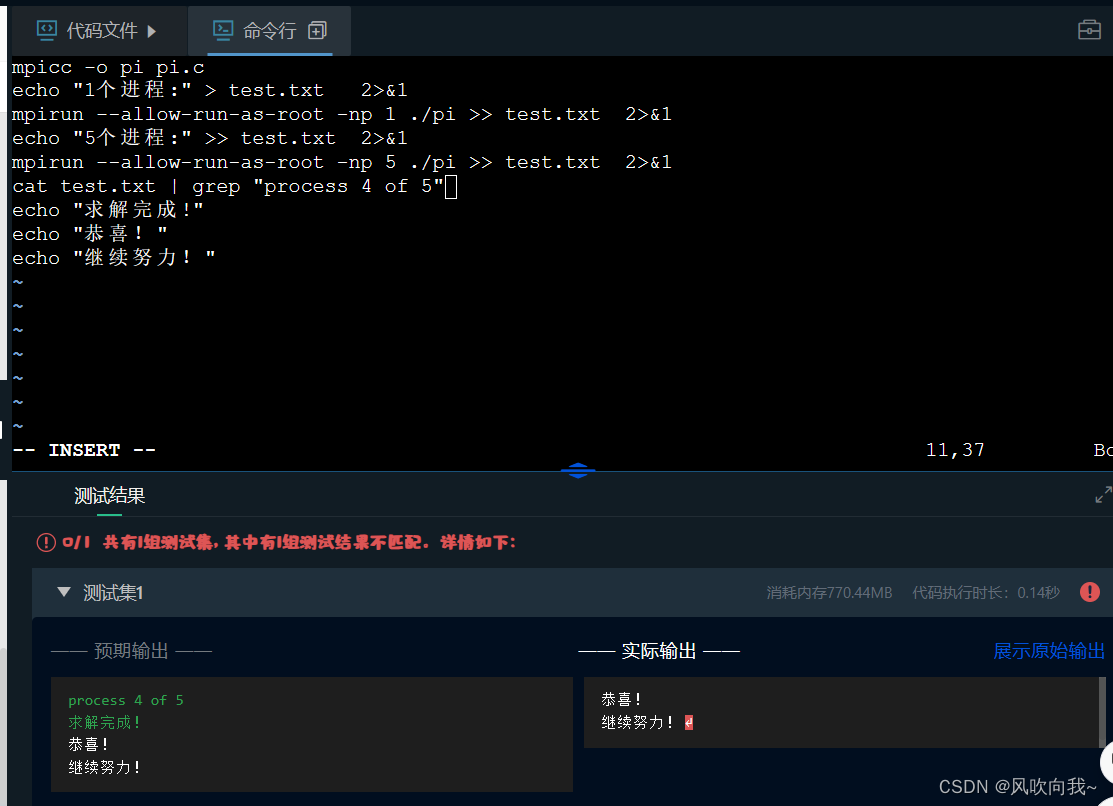
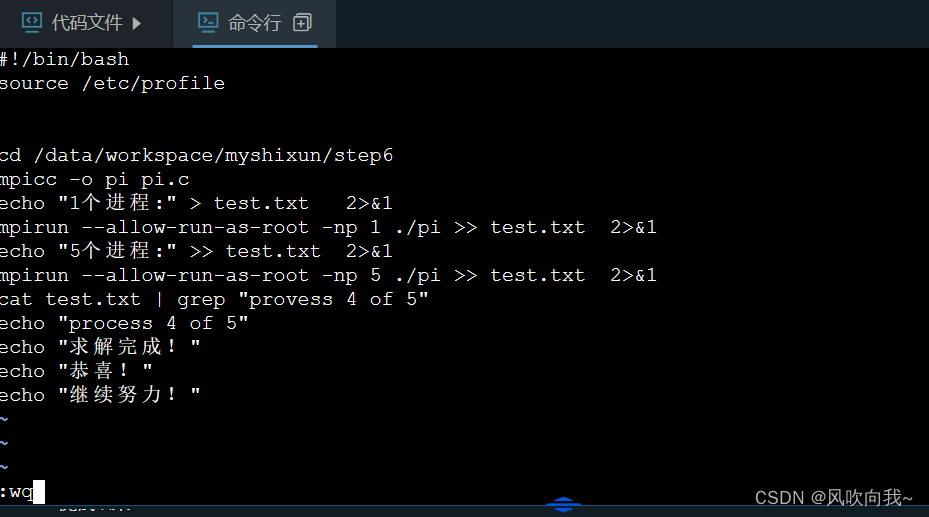
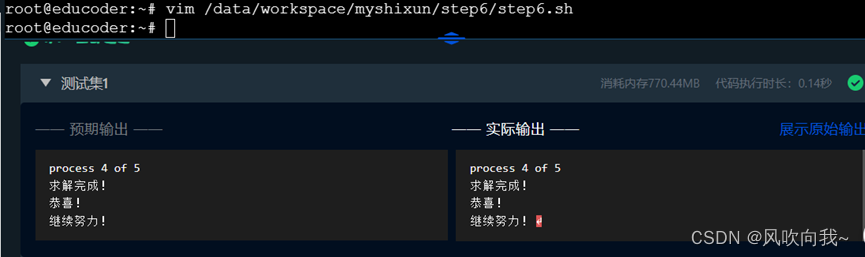
ps:这里评测系统有点bug,可按照下面方法自行修改
❤❤风吹向我吧❤❤