1、图像分割基础
1.1、任务说明及常用数据集
目标检测:将不同种类框起来
语义分割:能够反应不同种类的形状出来
实例分割:代表同种类的物体也能识别清楚,精确分割每个实例

semantic labels 语义标签
常用数据集



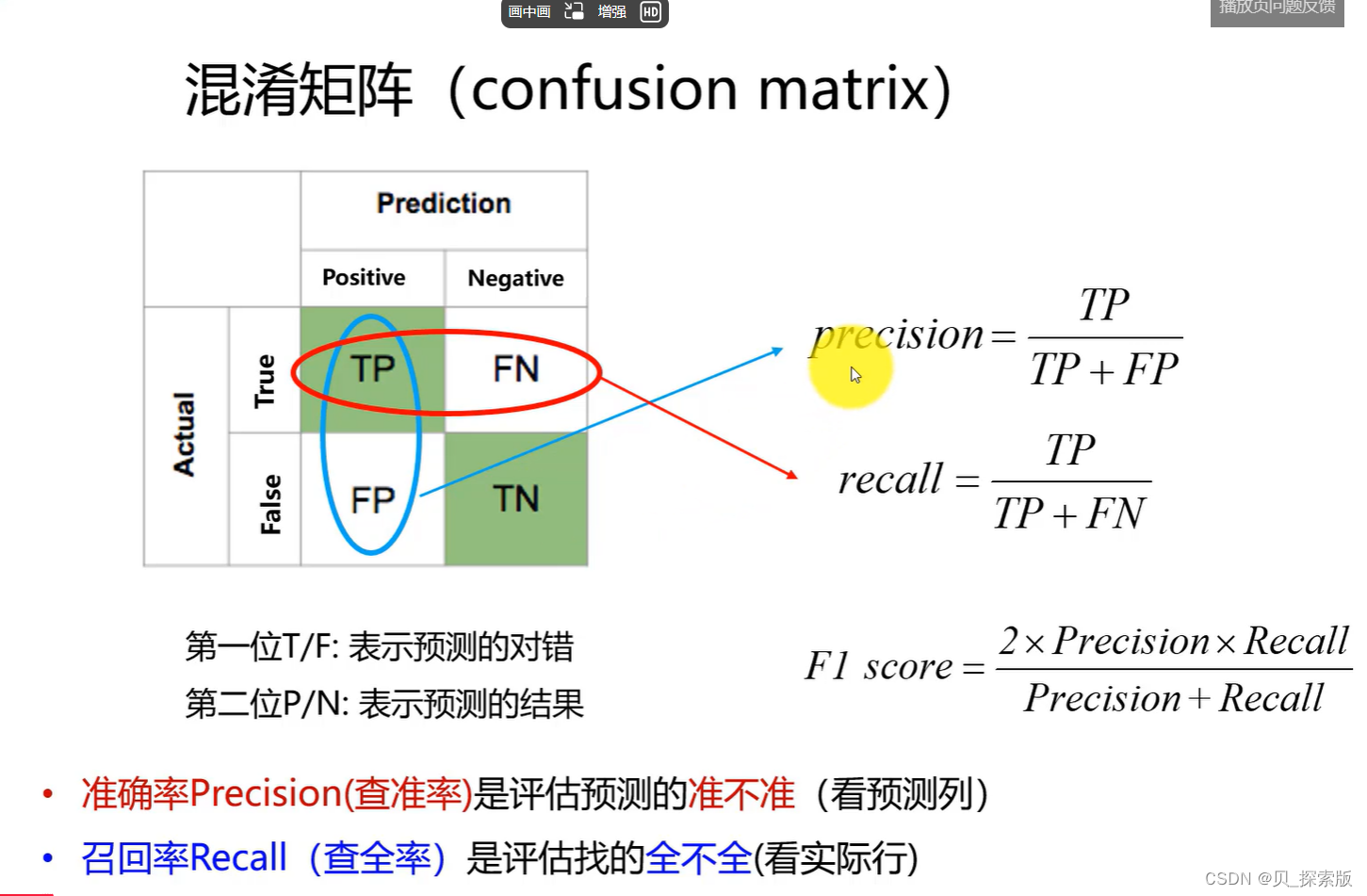
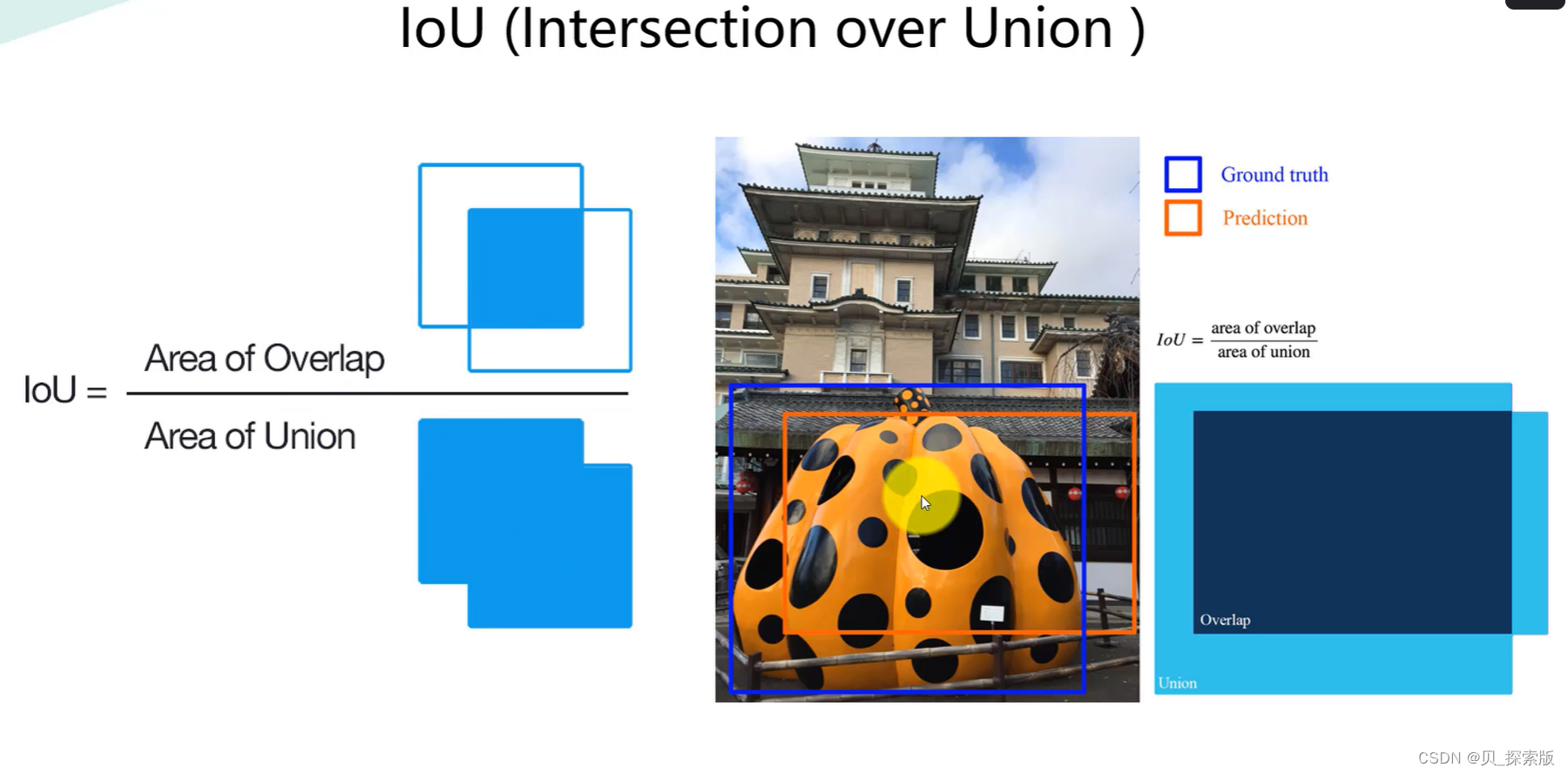
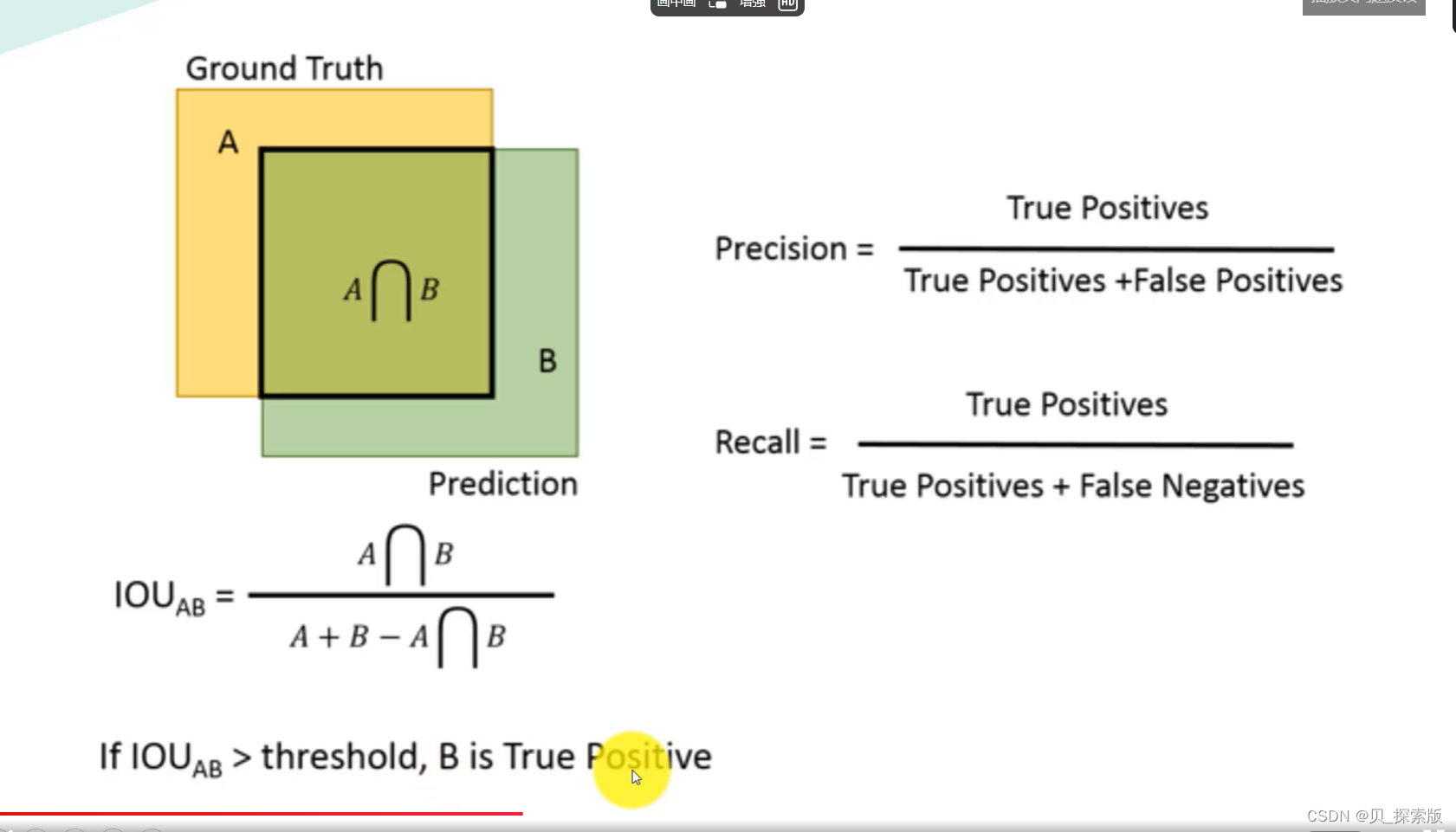
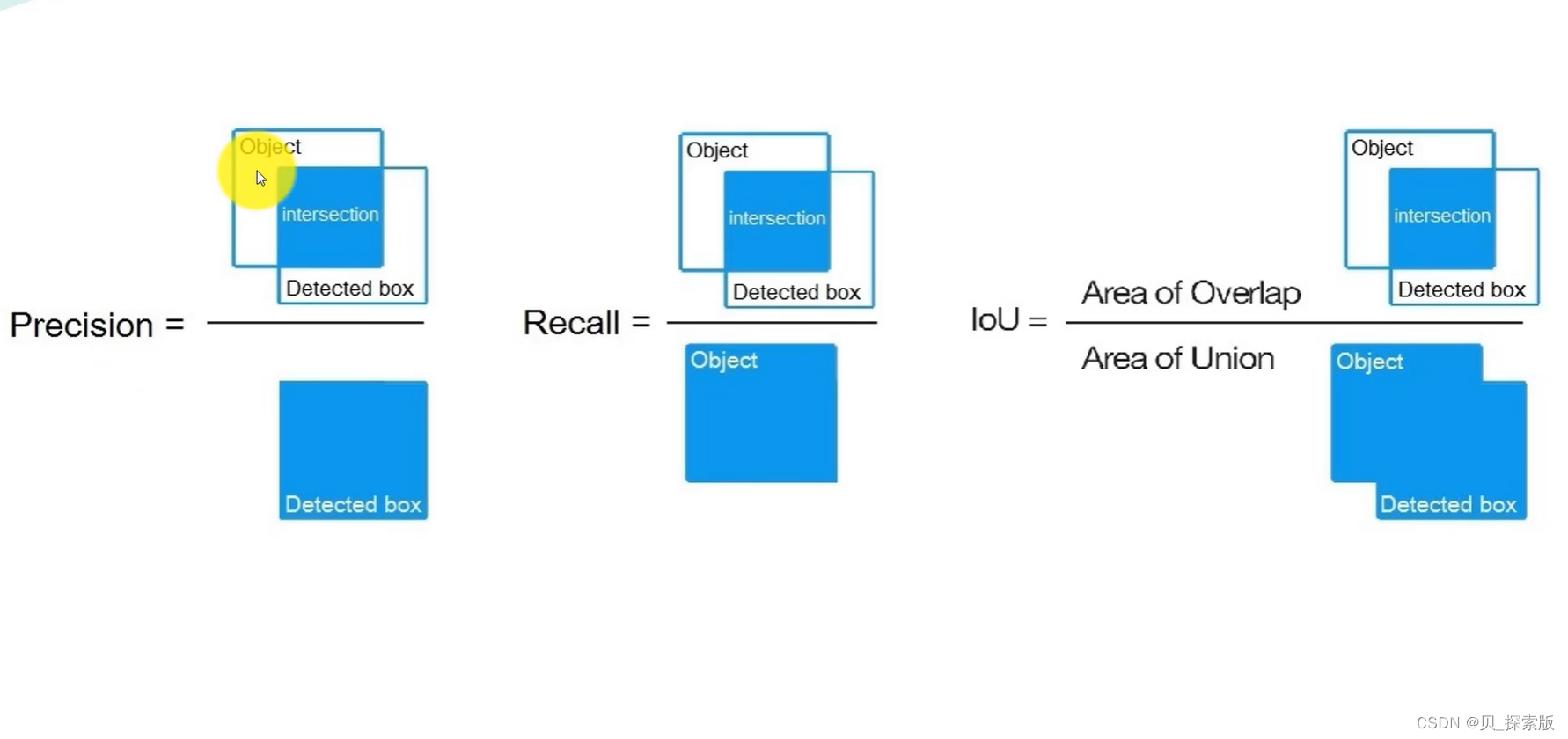
1.2、性能指标




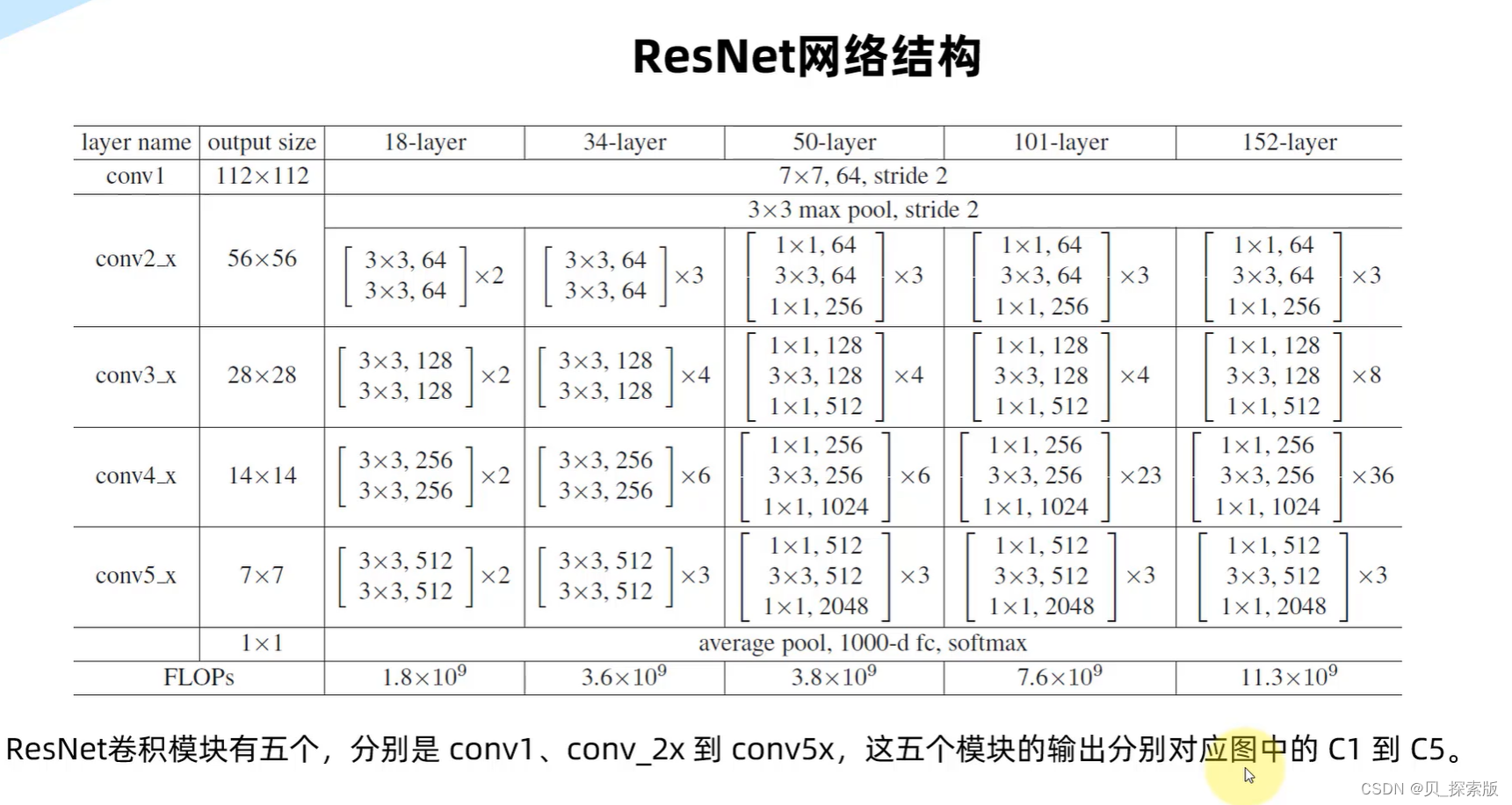
2、Yolov8网络
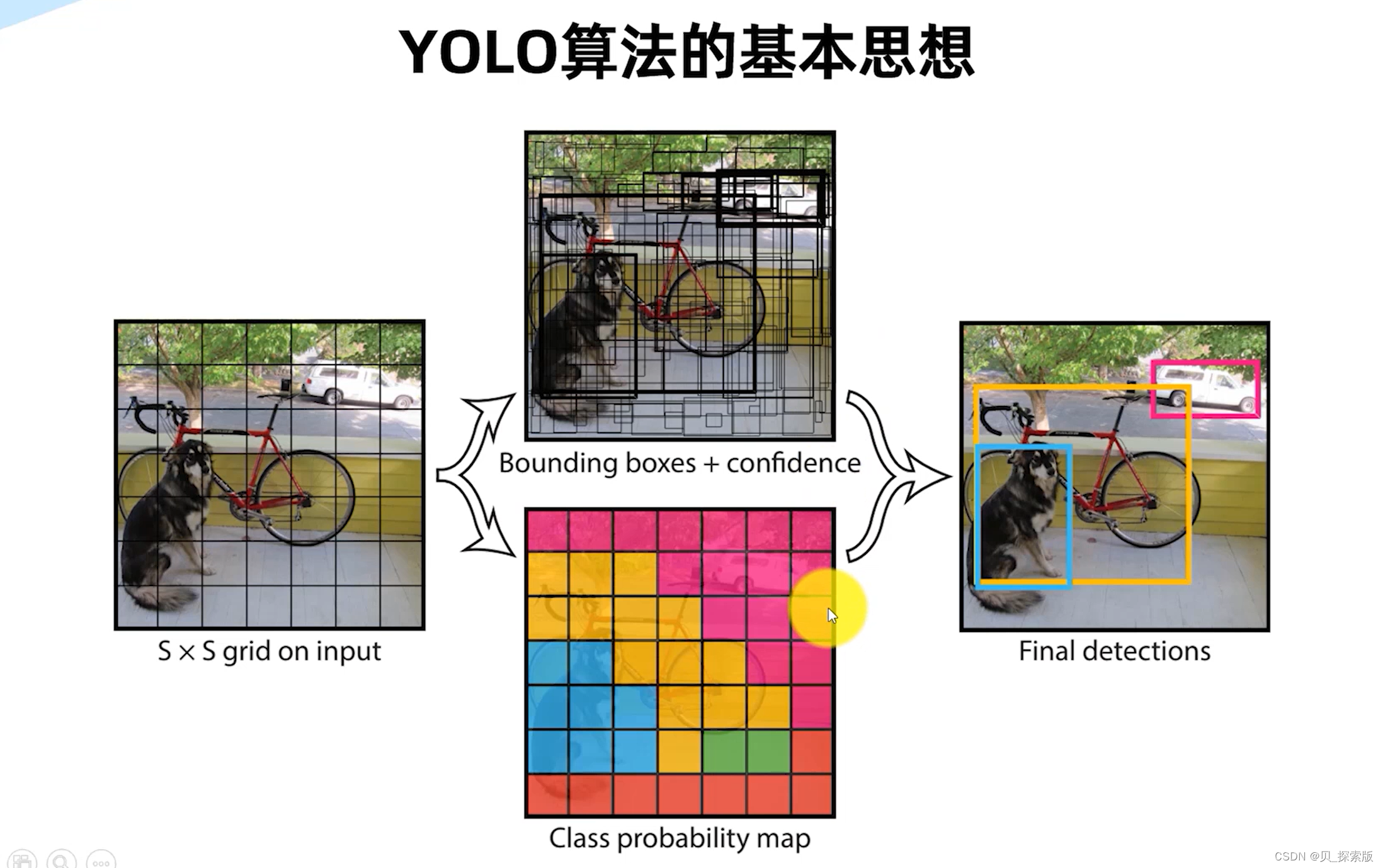


2.1、yolov8网络架构

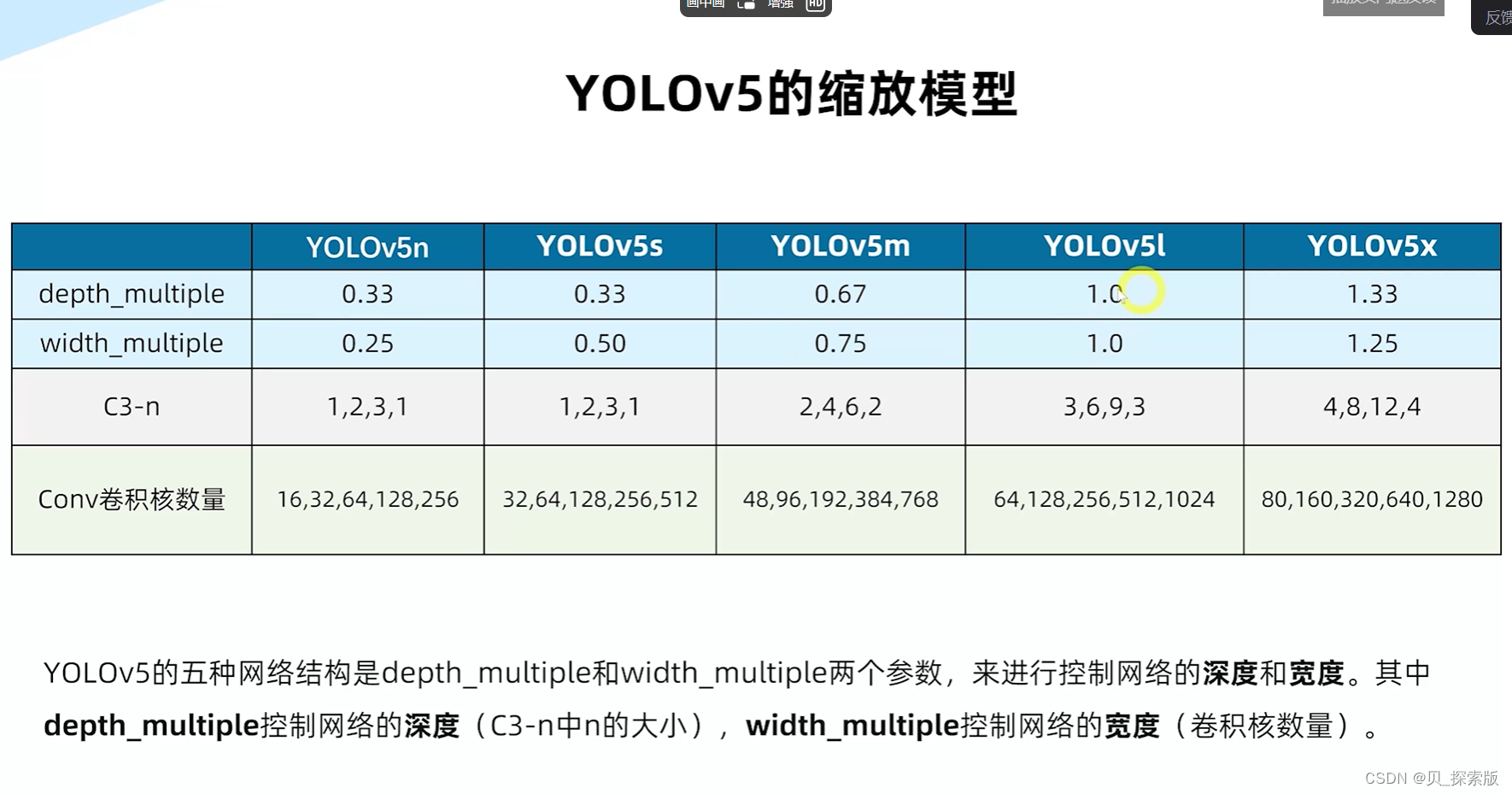
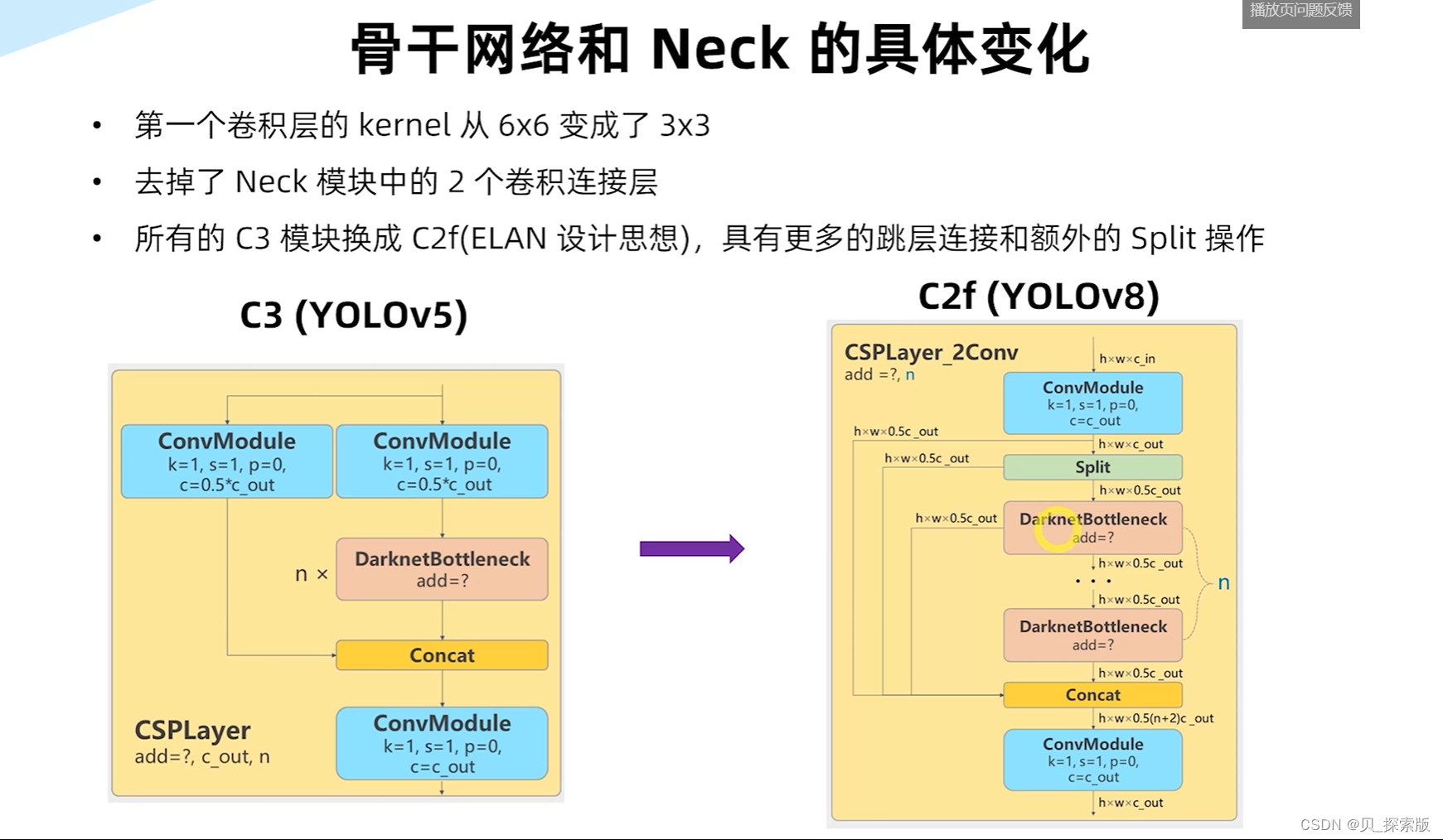
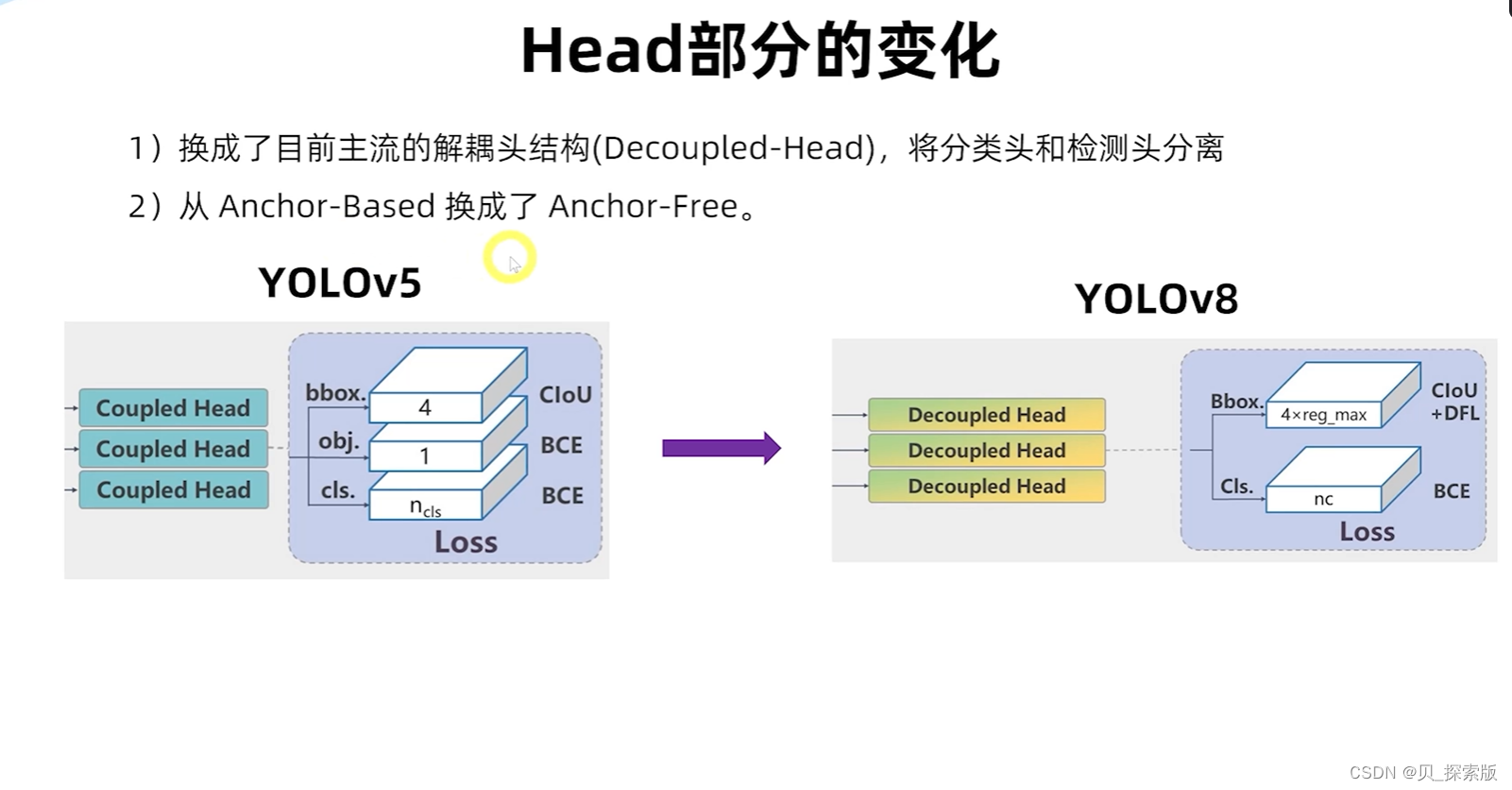
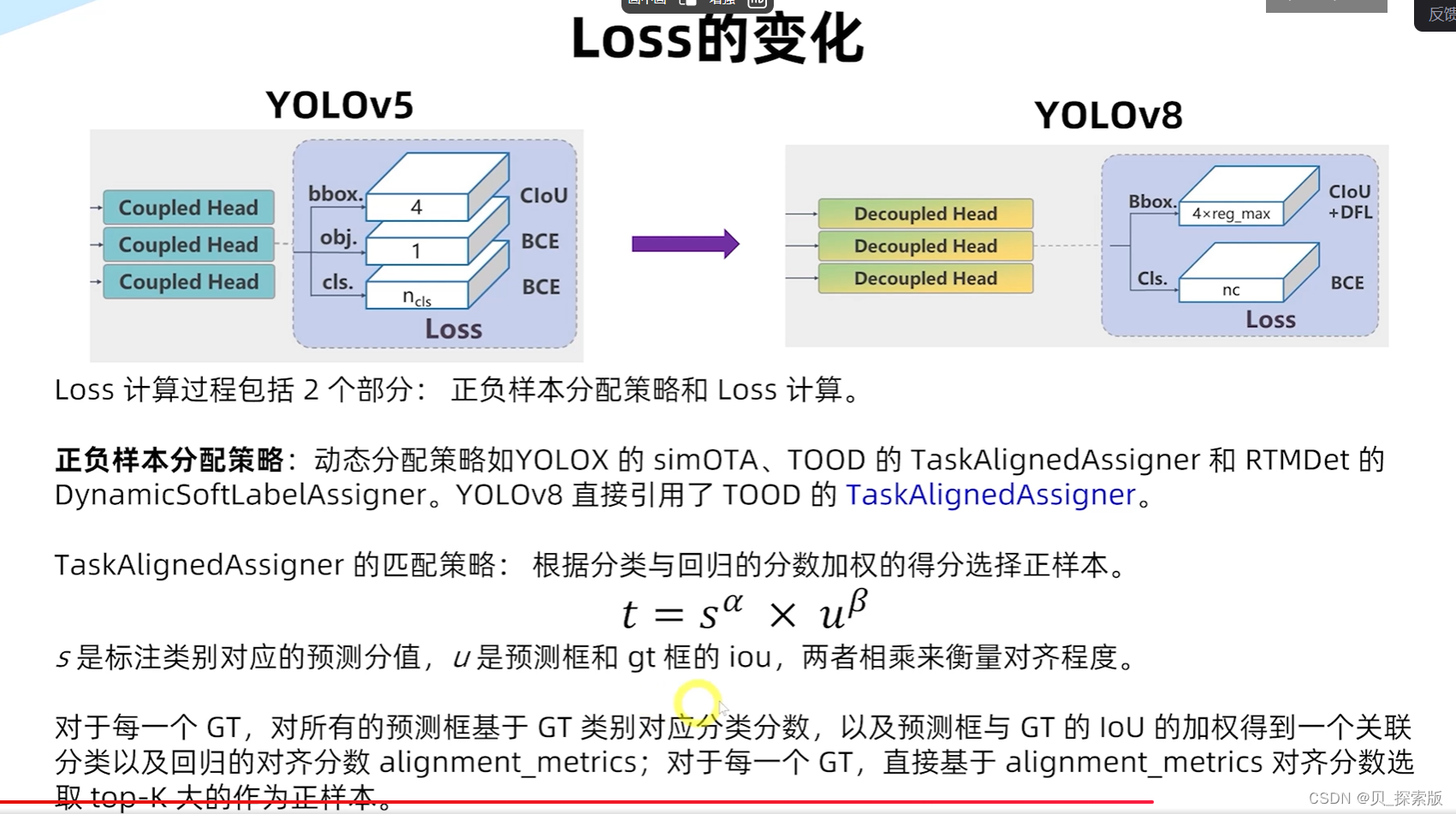
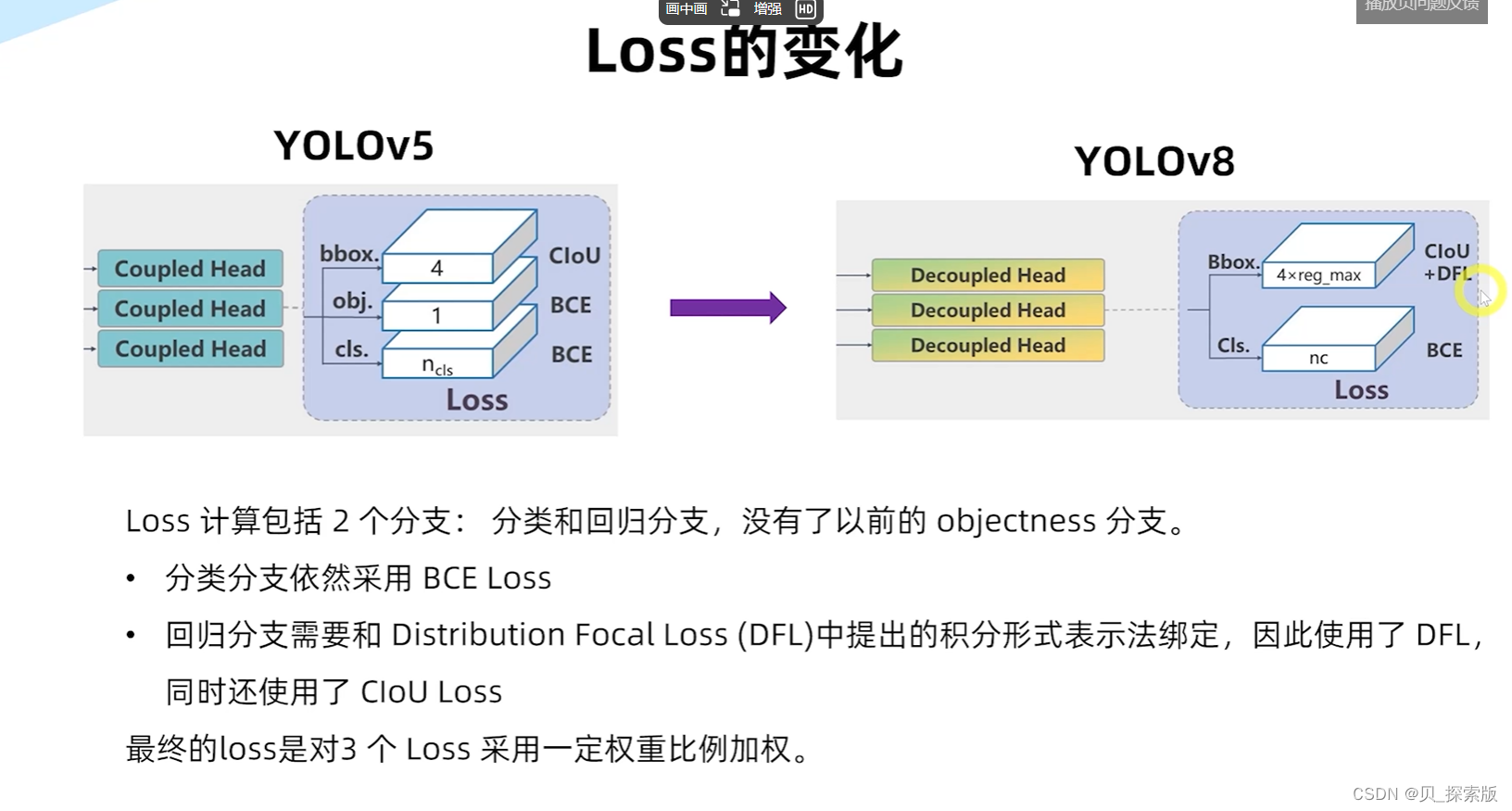
针对于边界框模糊的情况,设计DFL(distribution focal loss)
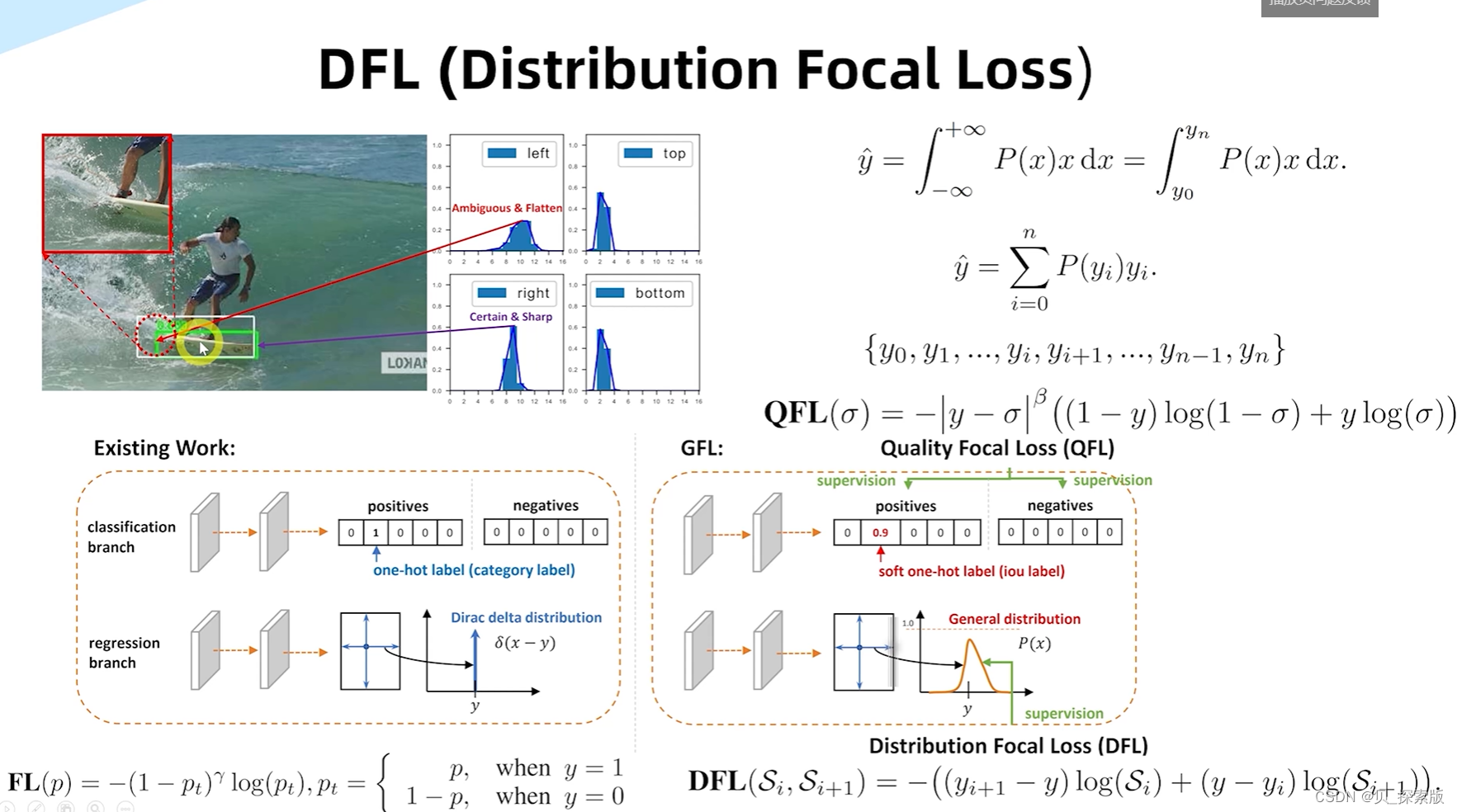

有利于性能的提升。
2.2、YOLACT实例分割
实例分割,也是目标检测,精度也高。抛弃显示定位步骤,全卷积模型,是一个实时的实例分割


五个级别骨干网,送到
protonet获得prototype
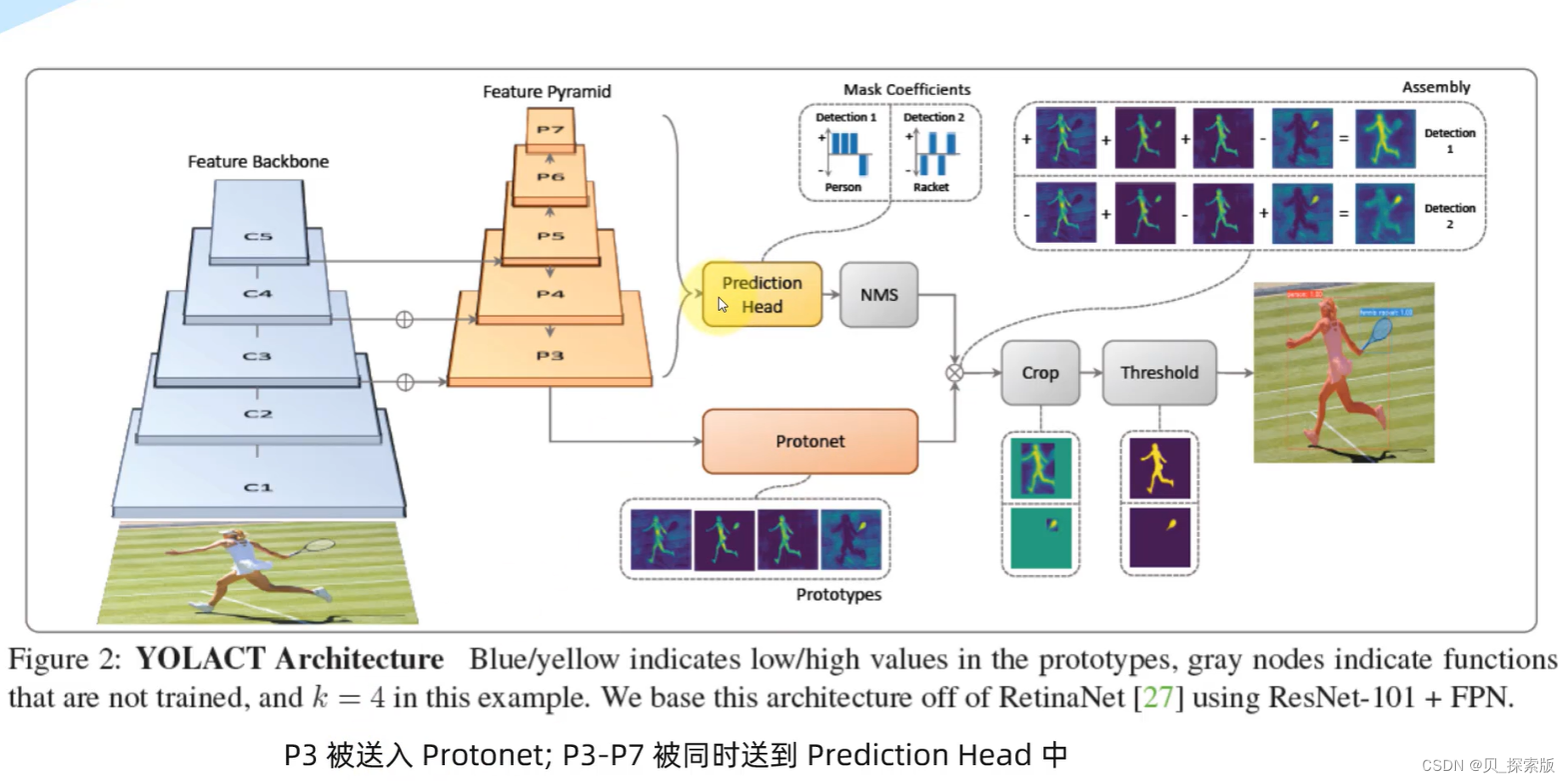
(1)获得
(2)对每个实例获得蒙版系数
产生实例的文本,




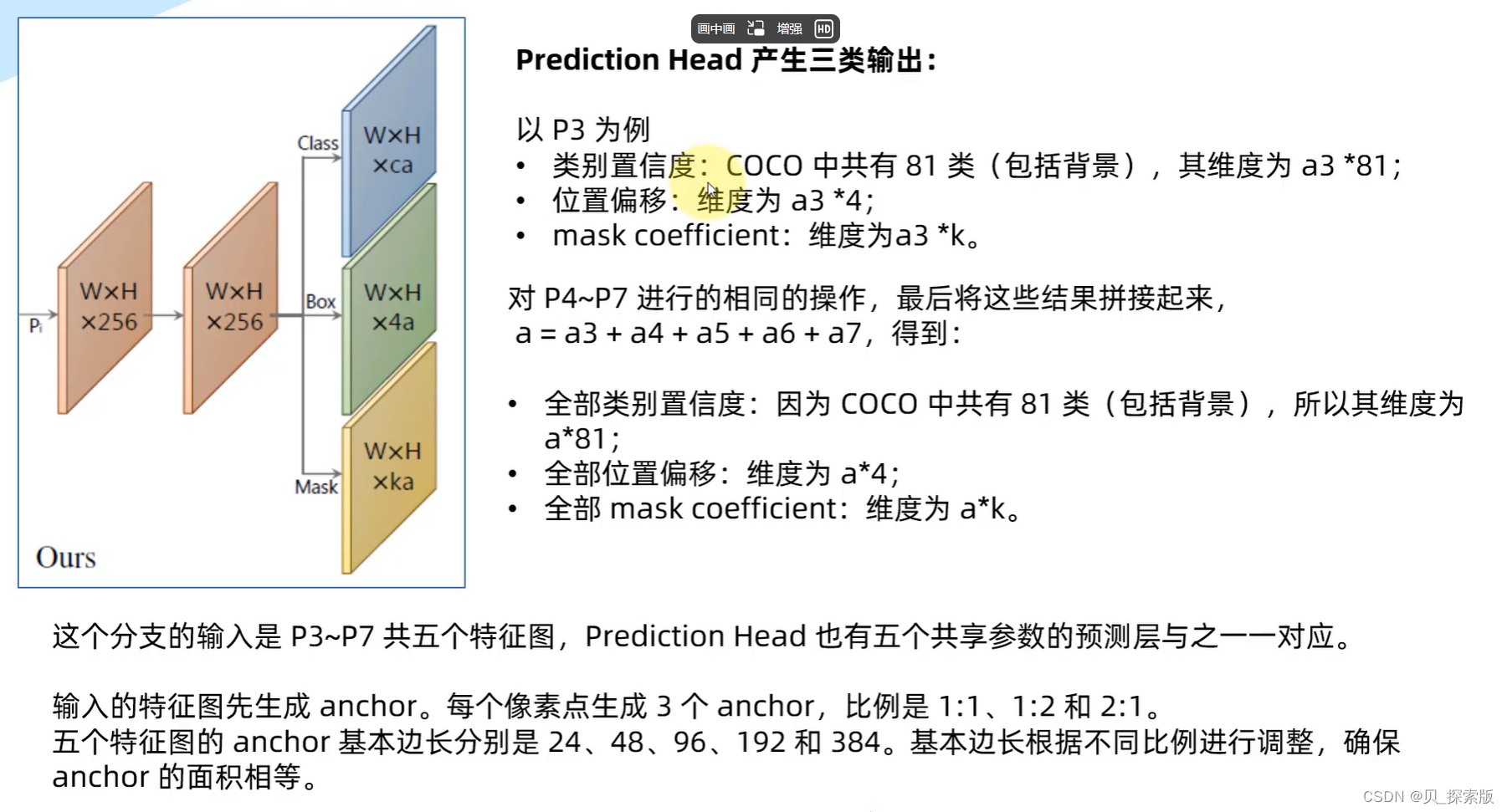

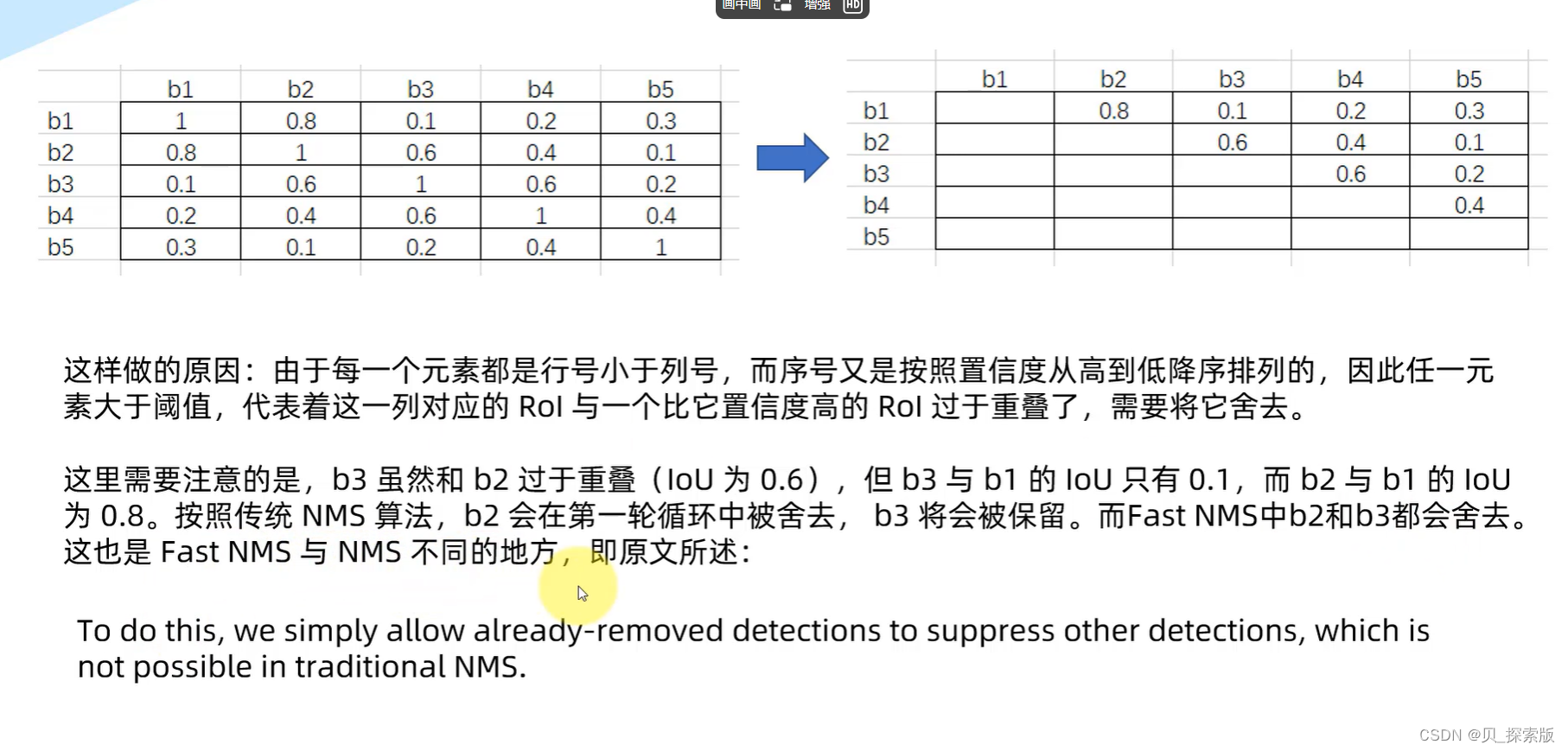




2.3、实例分割网络输出
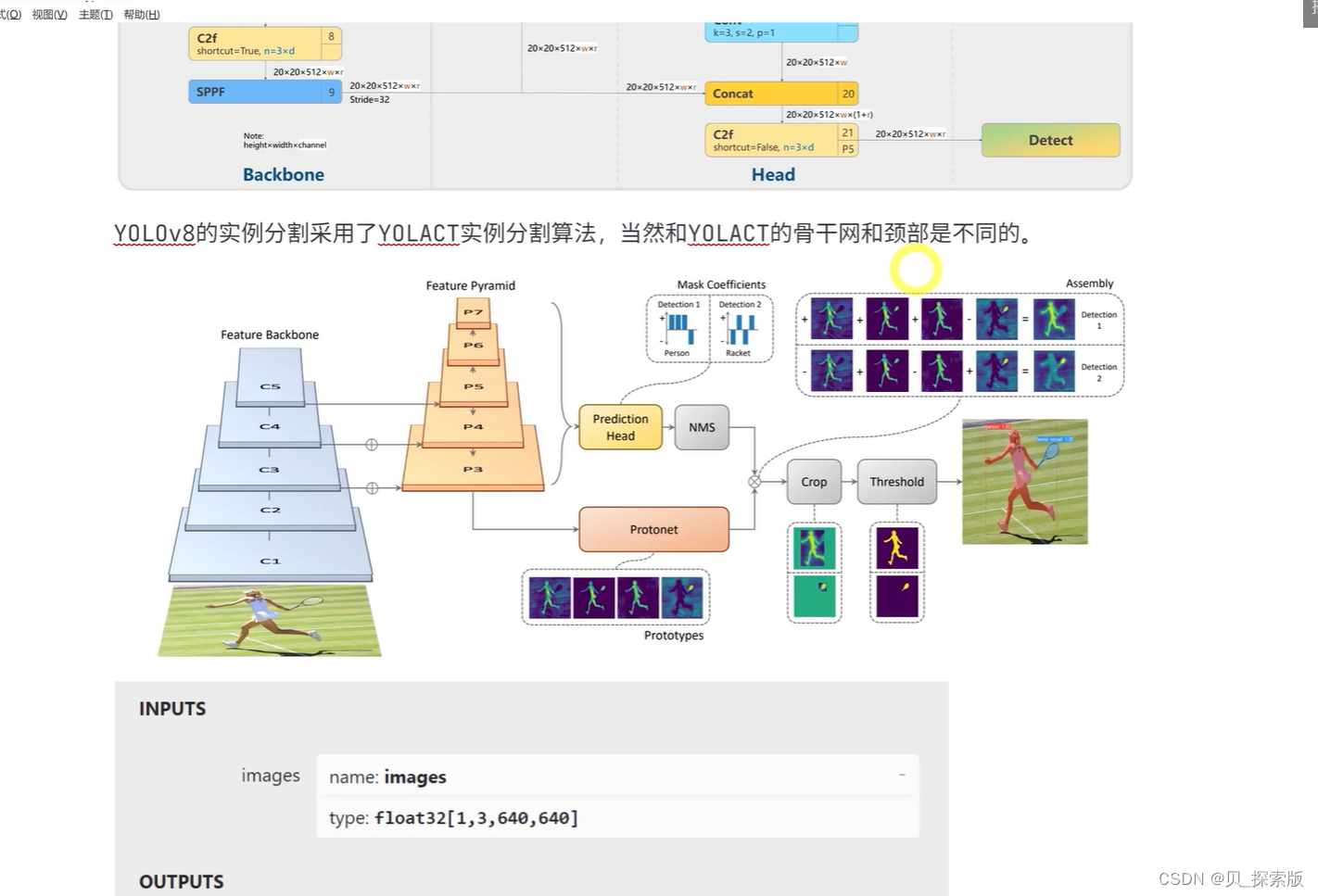
2.3.1、YOLACT




3、训练自己的数据集
3.1、服务器会连(有显卡别看)
3.2、单个图片检测、单个视频检测
首先直接在大文件夹创建新的demo_predict.py 即创建一个python文件,如图
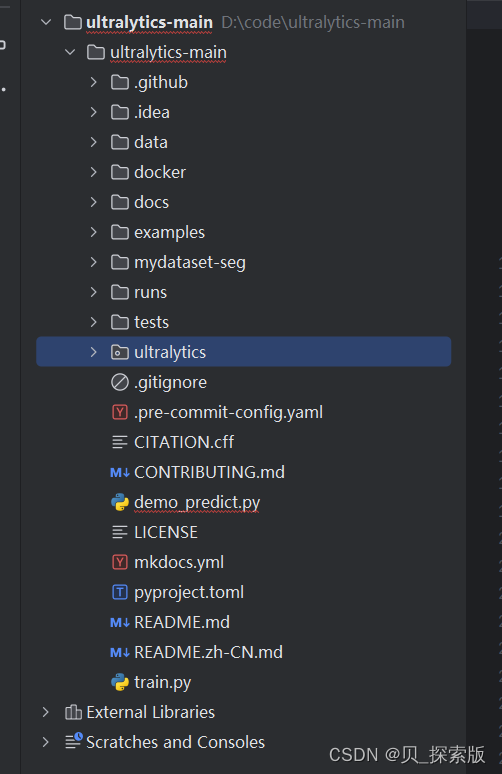
1、检测当前屏幕
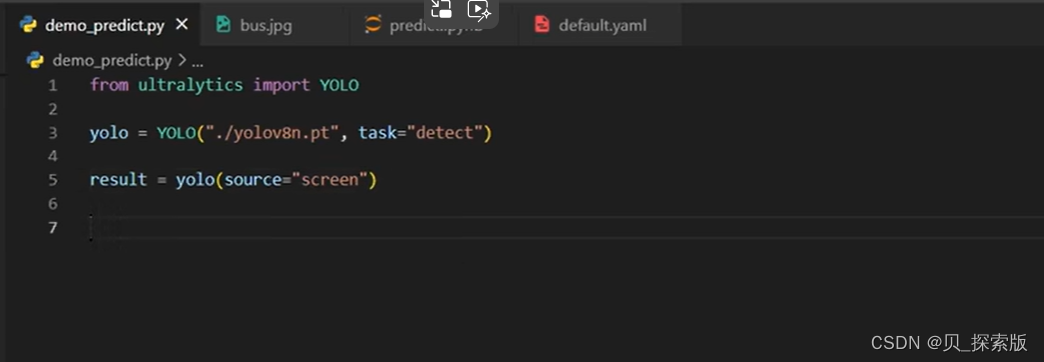
2、打开摄像头实时检测
# 扫描检测当前屏幕上面 # result = yolo(source="screen") # 打开摄像头检测 # result = yolo(source=0)
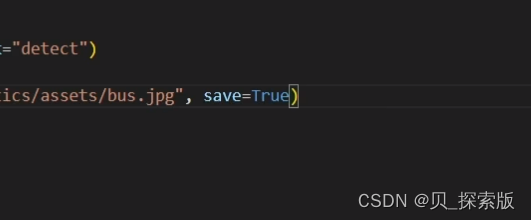
需要进行的操作,比如保存,save=True,需要改动在此处改想要进行的操作。
conf 分数越低画出来的框越多
iou 设置越高,出来越多
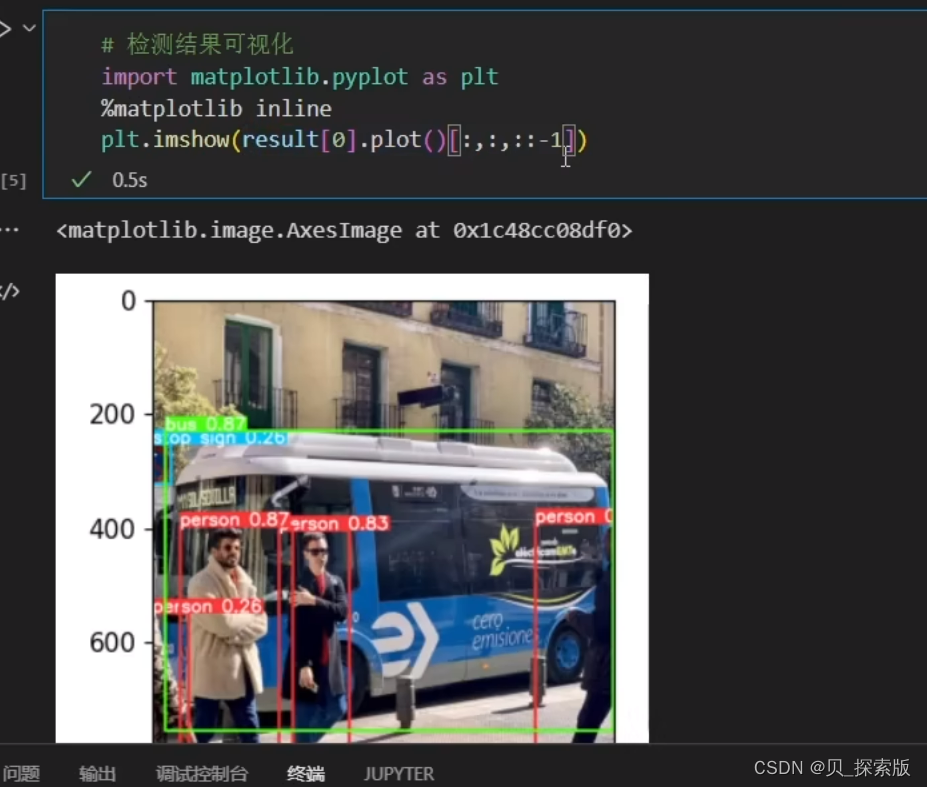
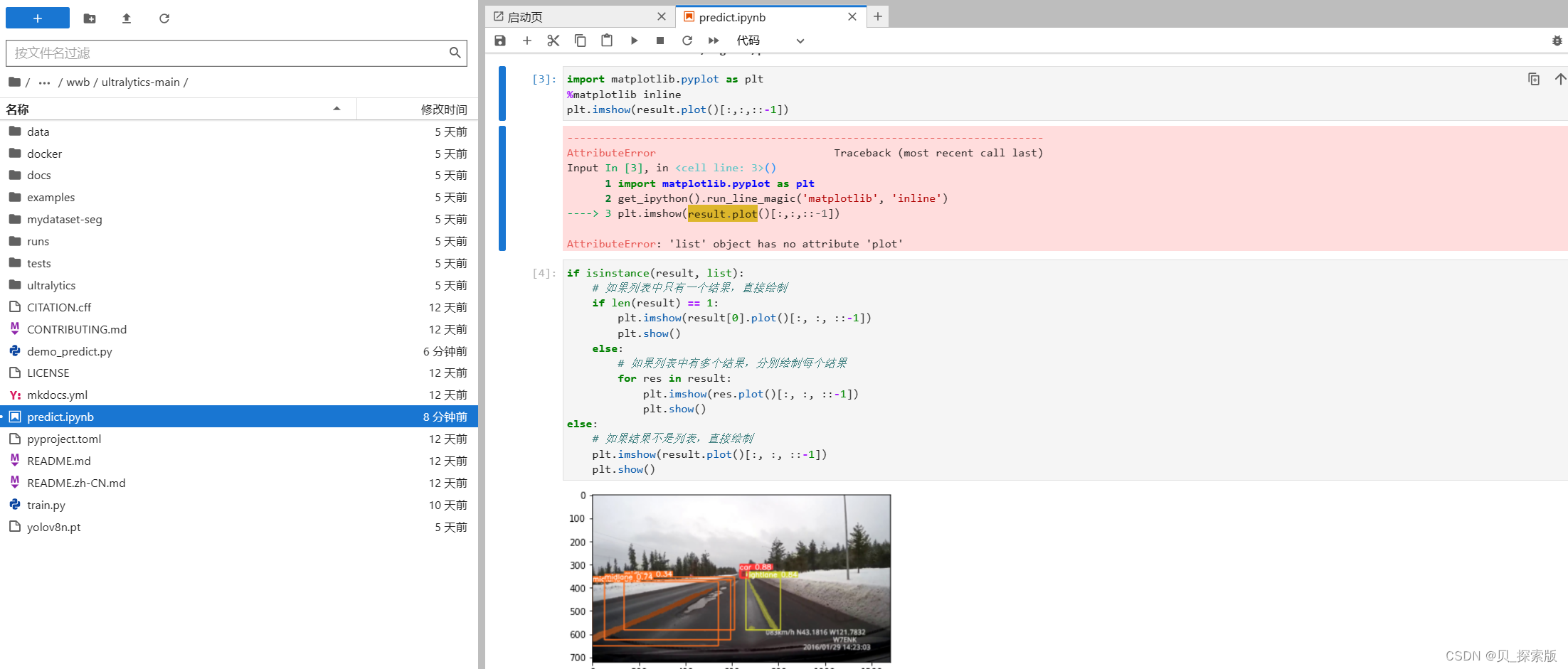
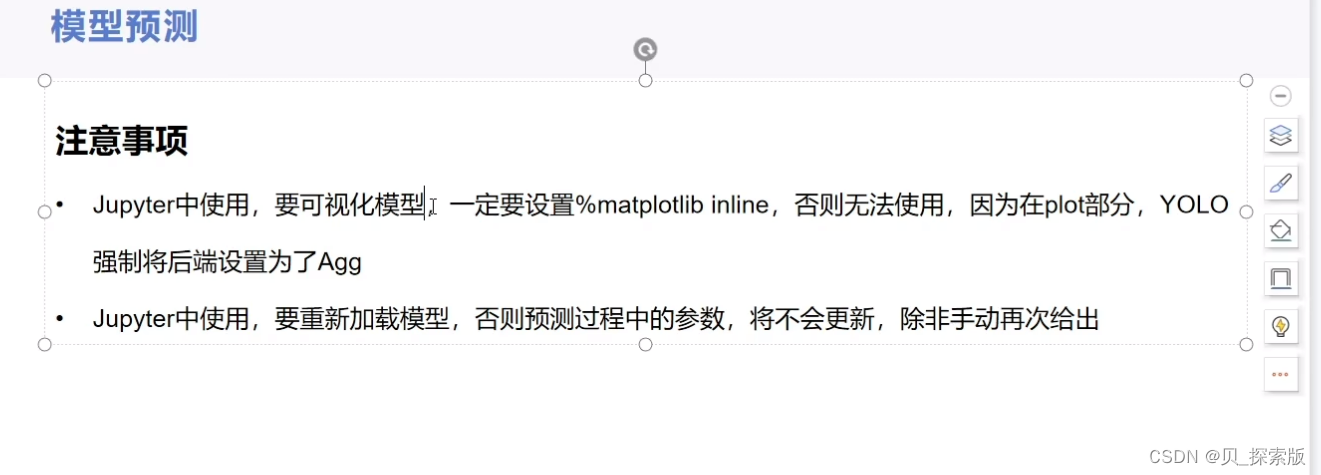
jupyter当中,plt。imshow(result[0].plot()[:,:,::-1])可以让图片输出格式正常
绝对路径,相对路径
调用服务器要使用相对路径 ./当前文件夹/文件夹下的目录
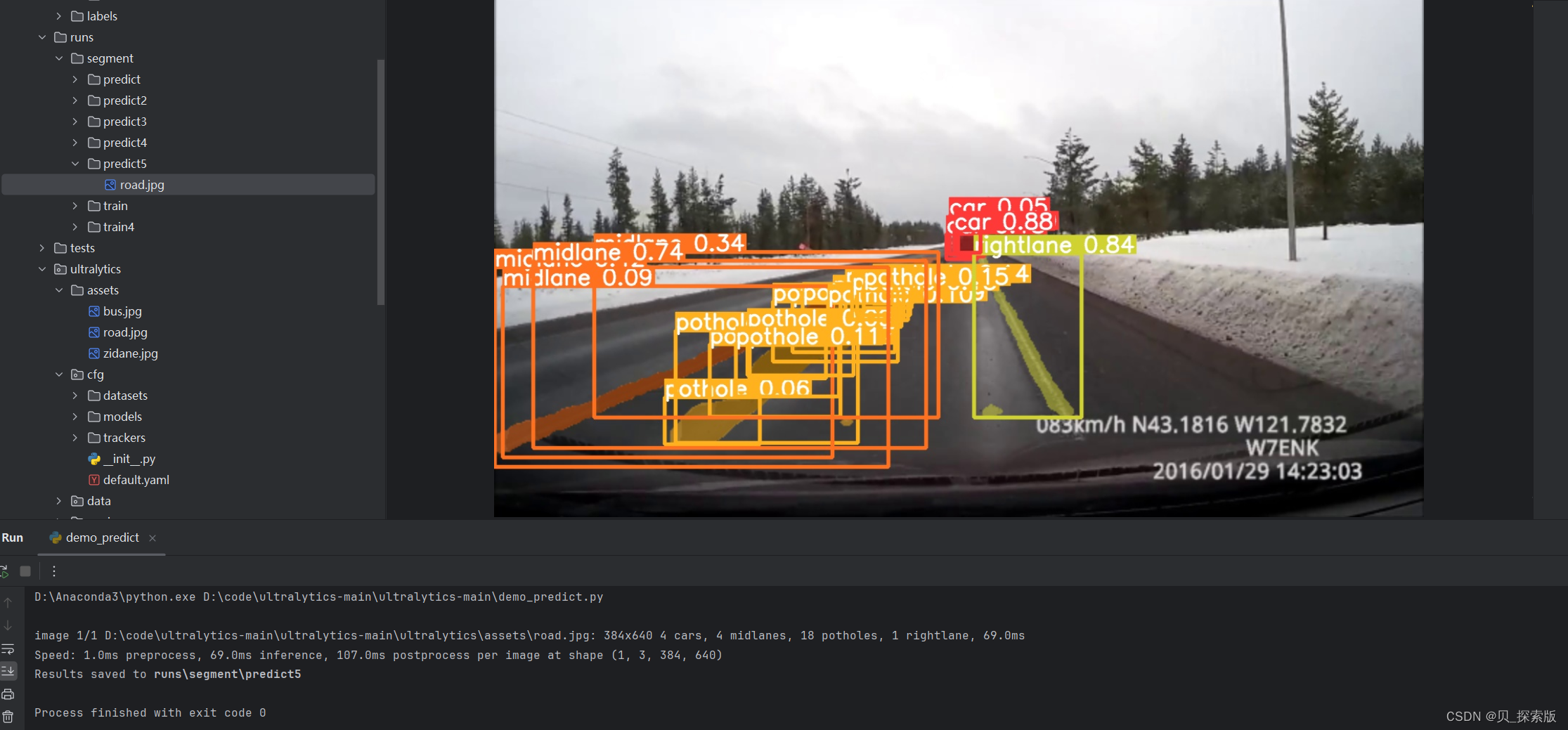
result = yolo(source="./ultralytics/assets/road.jpg",save=True,conf=0.2)绝对路径是在本地中用的,从D盘到
result = yolo(source="D:\\code\\ultralytics-main\\ultralytics-main\\ultralytics\\assets\\road.jpg",save=True,conf=0.2)3.3、Labelimg
本人没有显卡,租云端服务器,直接在cpu安装的yolov8 和 labelimg
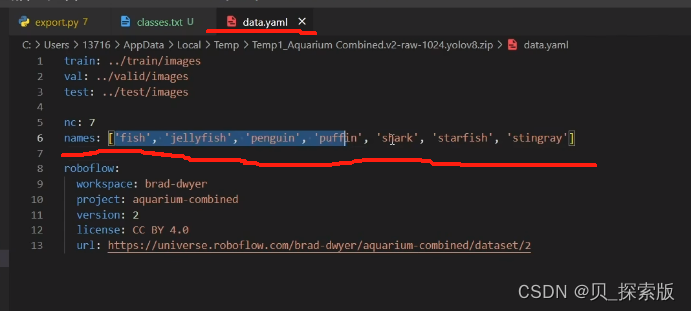 3.4、数据集格式
3.4、数据集格式

模型训练前准备:整理数据集,对于直接在网络上下载的数据集而言,有的不太规范,比如没有train 和 val 等等分类
首先在图片里面,修改文件夹名称,images,然后在里面创建 train 和val 分出一部分 放在train ,剩下的部分塞到val里面。
1、务必放在datasets里面!没有就创建,然后将刚刚准备的数据集放入
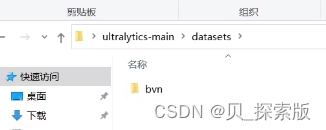
2、第二配置 描述文件,从 ultralytics 里面 assets 按照这里面的配置,可以将文件copy一份放在外侧,然后对文件进行修改
3、视频里光改了yolo.bvn 其中path没有直接从根目录里面,而是在assets 下面的bvn 直接写bvn
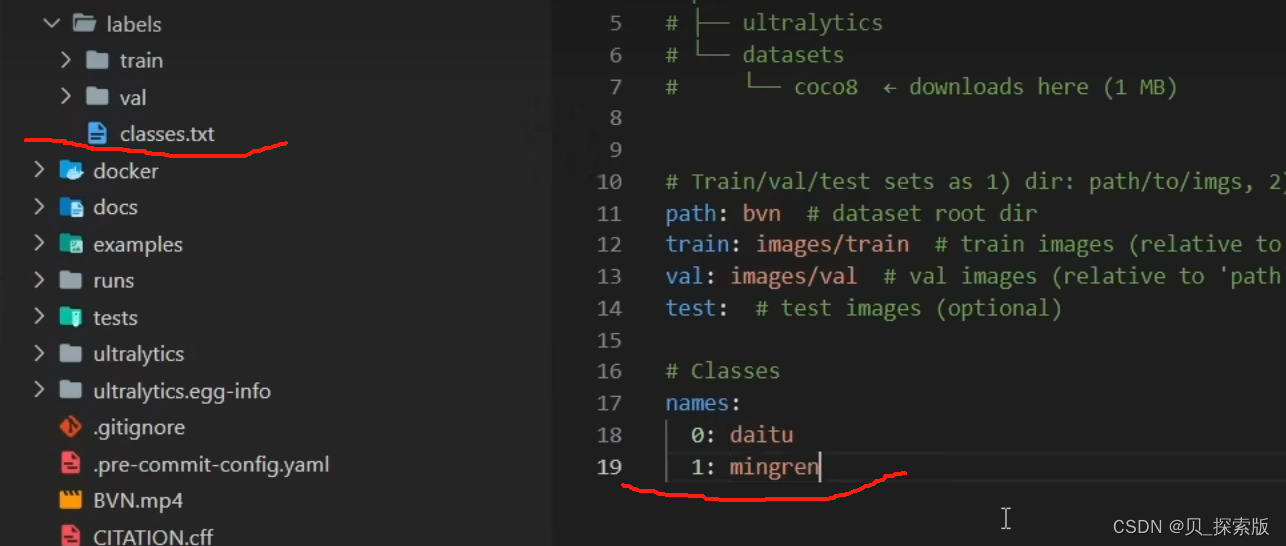
4、需要修改的部分是data 改成刚刚的yaml文件 另一个区别是mode从predict 改成了train

epochs代表训练多少轮
batche=16 就可以
这是基于命令行的方式进行启动!在终端上输入这一行代码
还有一种启动基于代码的

记住切换解释器,选yolov8解释器
第二行是加载模型

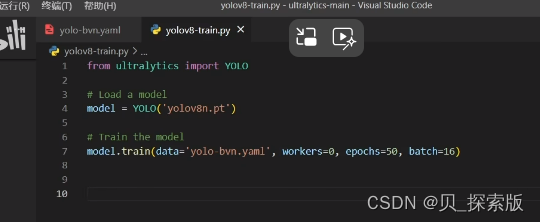
windows上面是在代码上workers要变成0 否则上面那张图运行不出来。
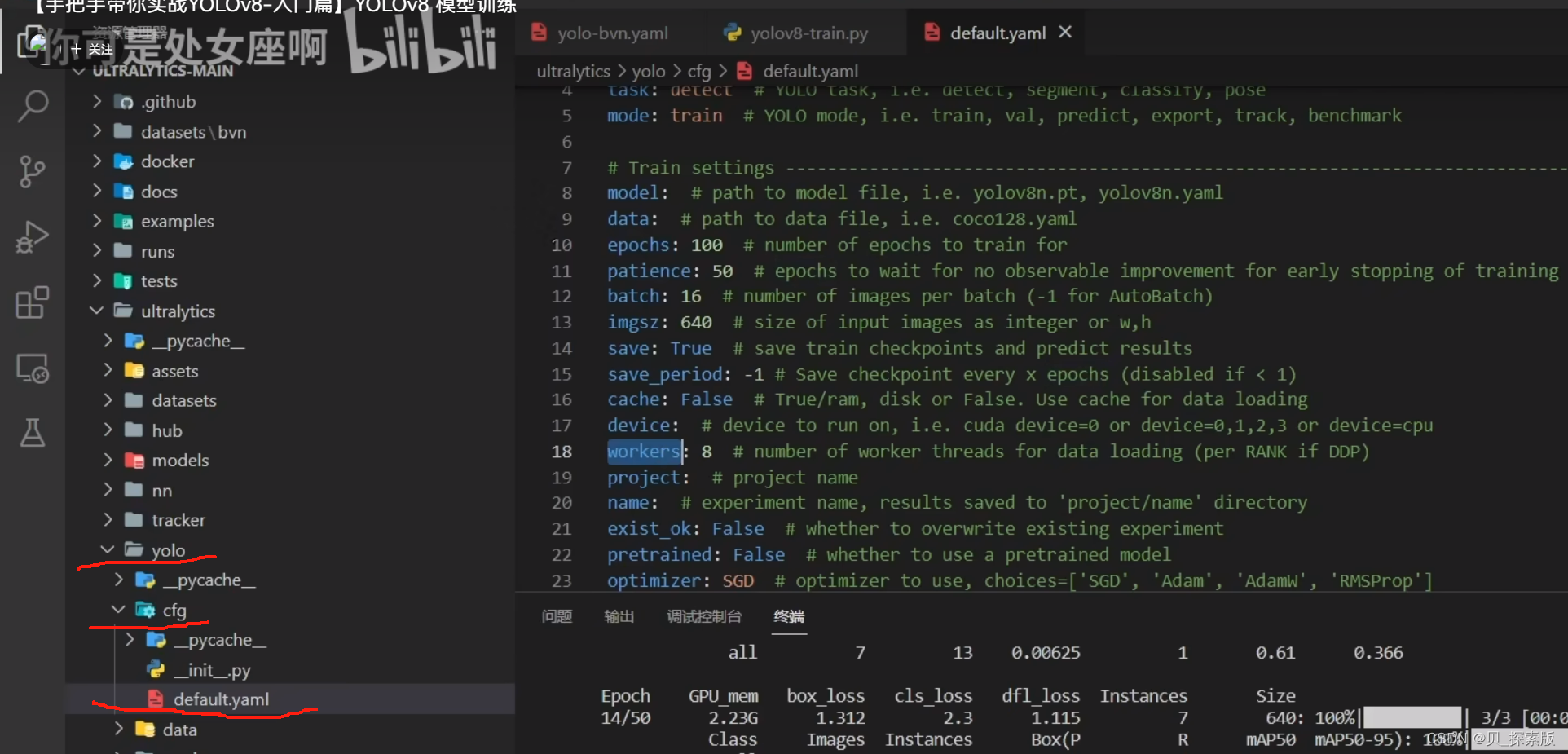
每次从这个地方加载参数但是可以copy一份用于平常训练,直接在copy的上面改
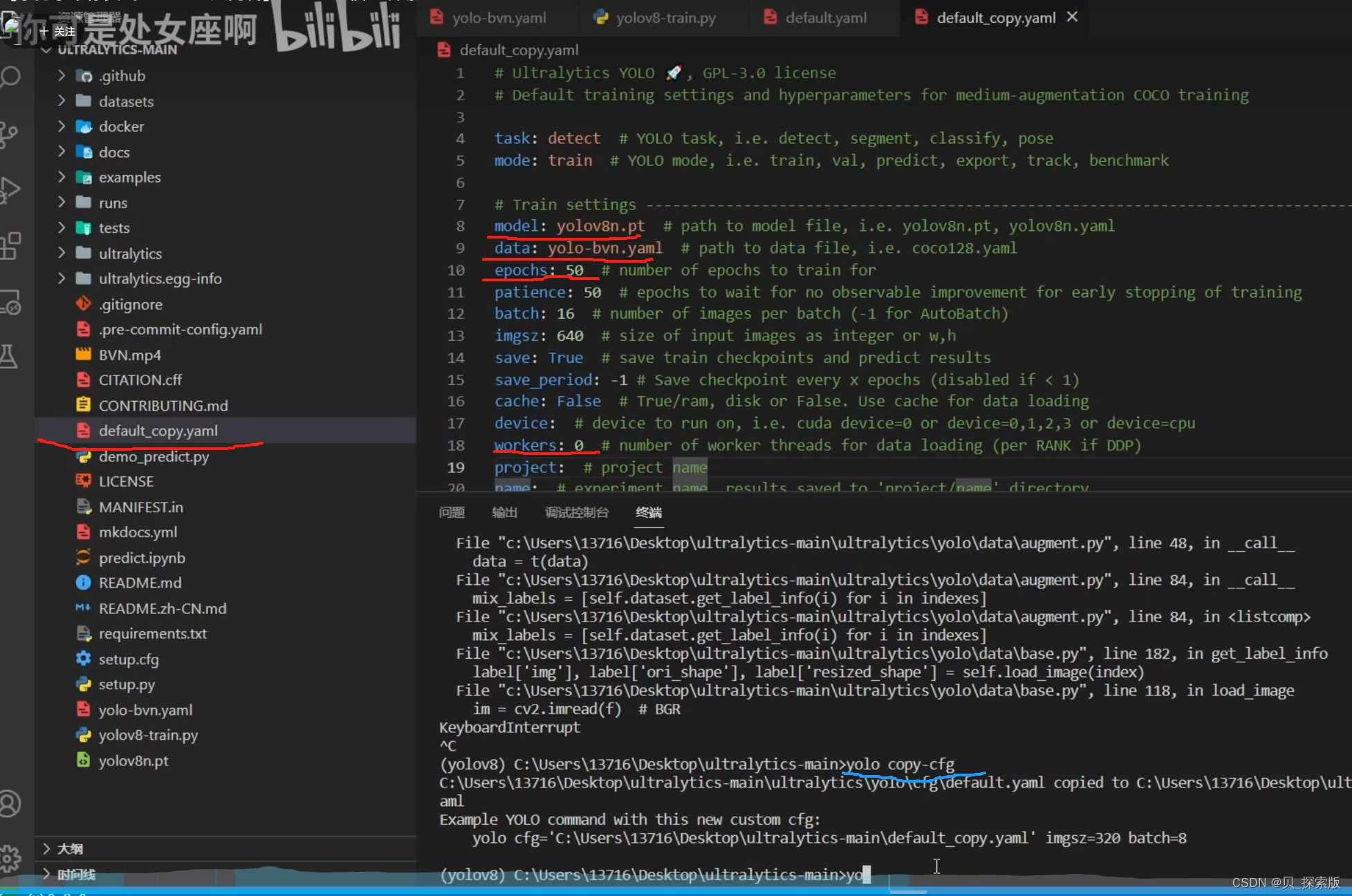
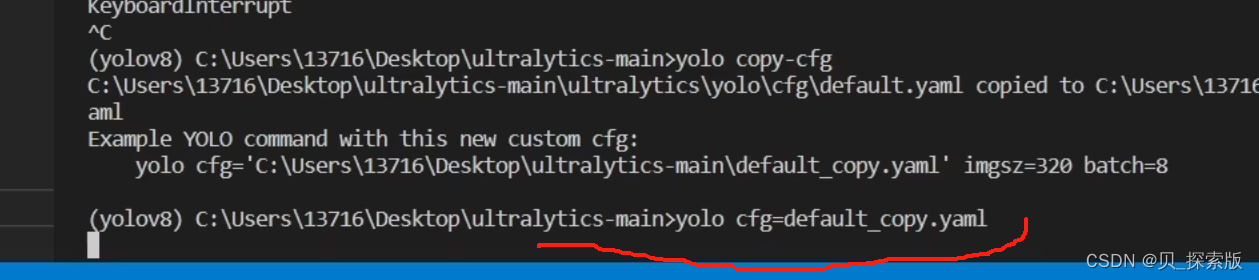
5、结果存在runs里面train里面,如果不想要这个值,可以根据 results.csv 进行自行绘制
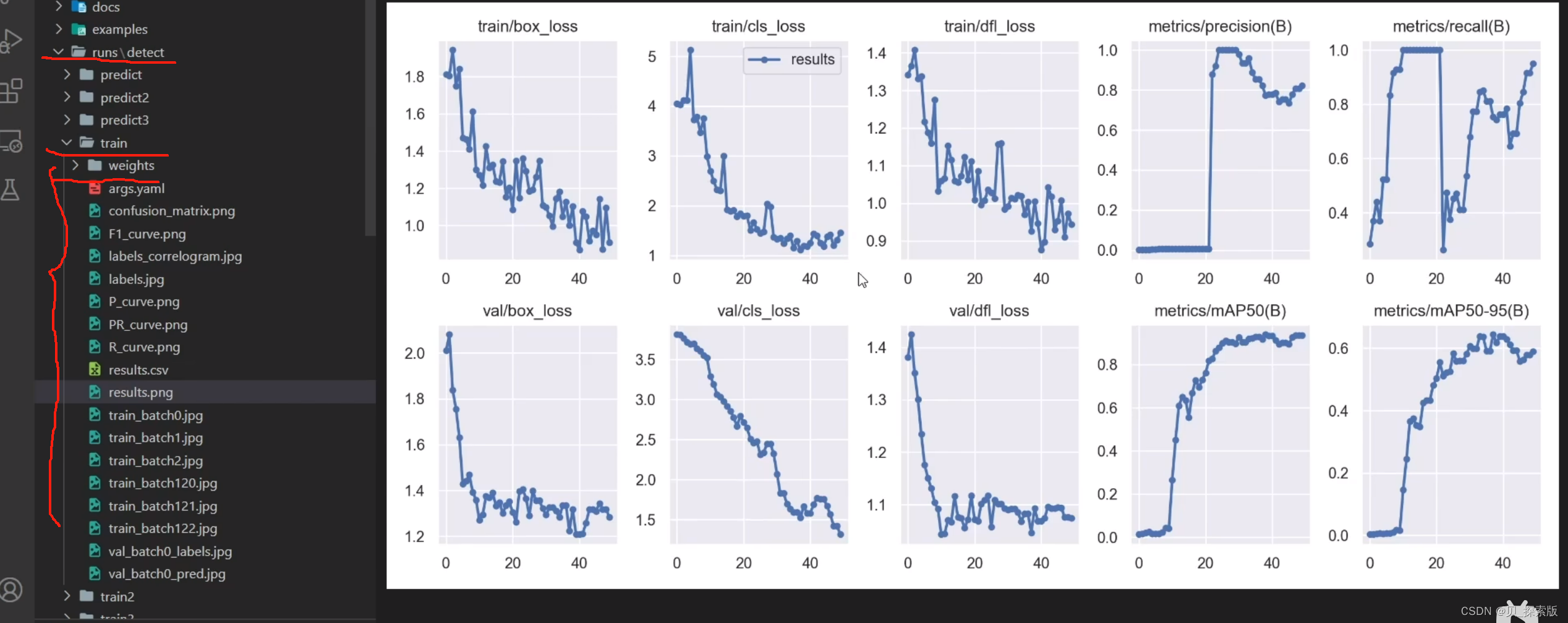
6、模型会存在 weights 里面
7、接下来可以使用 predict 对于我们训练的模型,检测一下什么效果
用这句话直接对于视频进行一个检测

注意点

yaml文件就放在想跑的根目录下面,然后数据集就放在根目录下的datasets 再根据自己的数据据名称给他包一层就可以了 datasets/bvn
path 的yaml要从我们包的那一层写起会少很多问题


4、实战及问题
由于本人是边练边写经验,每次打开csdn的草稿都太卡了 ,这期间调试也遇见了很多很多问题,多次崩溃发疯扭曲爬行后阅读百十篇帖子最终得到了解决,会另外开新的帖子,把遇到的问题以及解决方案全部分享出来,这里不再赘述。