目录
5、grep -m 1 多个匹配只取第一个匹配到的(数字几就取前几次匹配到的截至)
5、使用grep配合使用“^”(行首)表示以什么为开头、“$”(行尾)以什么为结尾
6、“\+” 一次以上,使用的使egreo,就不需要加“\”
10、{n,} #匹配前面的字符至少n次,<=n,n可以为0
4.3使用模式进行查询(使用文本方式寻址,格式:/筛选条件/)
4.8 使用“r”读取允 许你将一个独立文件中的数据插入到数据流中
创建测试文件test.txt
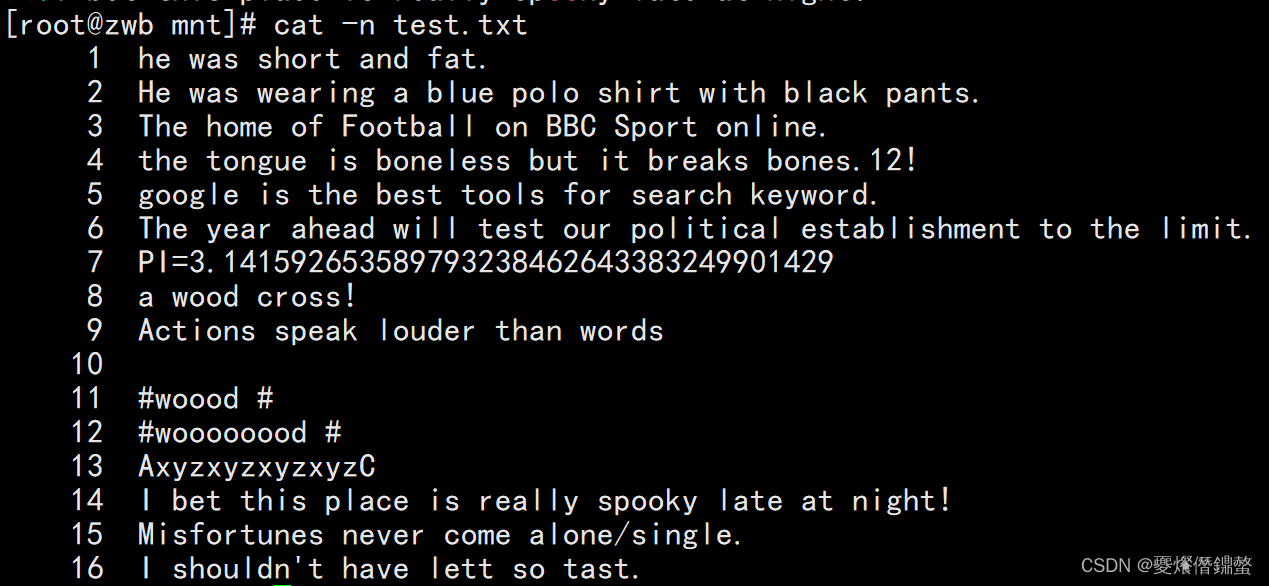
一、使用grep 进行查找特定字符
1、grep -n 表示显示行号
需求:使用grep查找含有the的行
grep -n "the" test.txt (-n:表示显示行号)

2、grep -i 表示不区分大小写
需求:使用grep不区分大小写查找含有the的行
grep -ni "the" test.txt (-ni 同-n -i :表示显示行号,且不区分the的大小写)

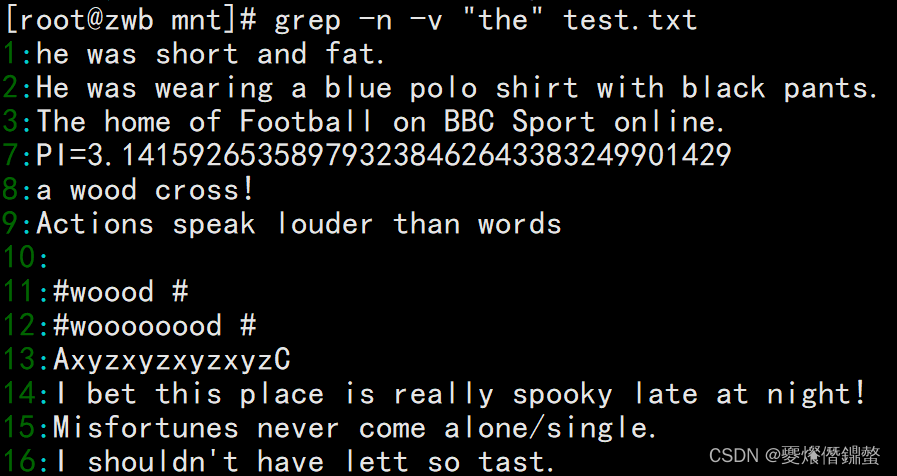
3、grep -v 表示取条件的相反内容
需求:使用grep反向查找不含the的行
grep -n -v "the" test.txt
4、grep -w 精准匹配,匹配整个单词

5、grep -m 1 多个匹配只取第一个匹配到的(数字几就取前几次匹配到的截至)

6、 grep -c 统计匹配到的行数

7、grep -A # after, 后#行

8、grep -B# before, 前#行

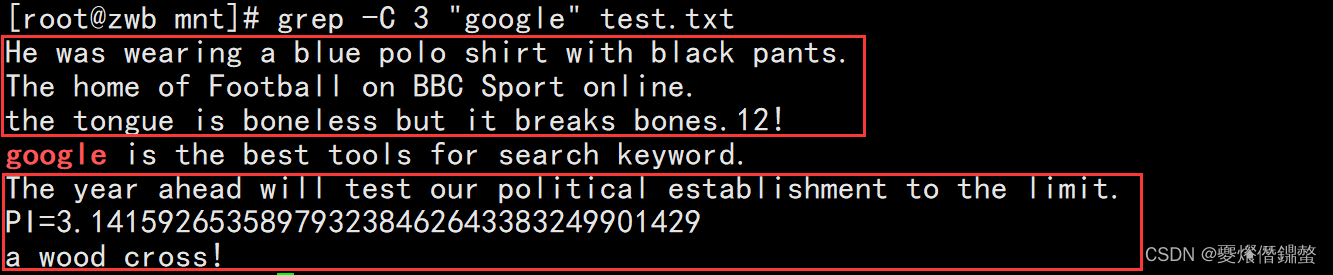
9、 -C # context, 前后各#行
10、-r 递归目录,但不处理软链接
11、-R 递归目录,但处理软链接
12、-o 仅显示匹配到的字符串
需求:显示出ens33网卡中的ip地址

二、利用grep 配合[ ] 来实现查找集合字符
^[a-z] 表示以小写字母开头
^[A-Z] 表示以大写字母开头
^[0-9]表示以数字开头
[^a-z] 表示某某前面不含小写字母
.................................
大白话:"^"在[ ]里面和外面的含义是不一样的,在外面表示以括号内的内容为行首,在里面表示对括号内的内容反向选择就是取反。
官方语言:“^”符号在元字符集合“[]”符号内外的作用是不一样的,在“[]”符号内表示反向选择,在“[]”符号外则代表定位行首。反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符
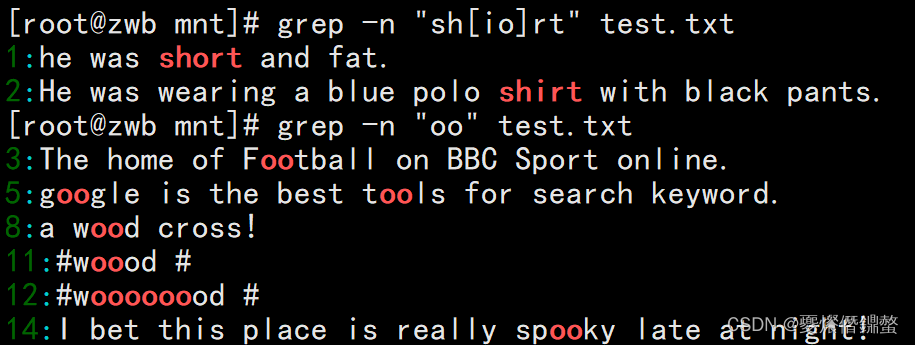
1、需求:想要查找“shirt”与“short”这两个字符串时
可以发现这两个字符串均包含“sh” 与“rt”,“[]”中无论有几个字符,都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”。
grep -n "sh[io]rt" test.txt

2、需求: 只查找包含重复单个字符“oo”时
[root@zwb mnt]# grep -n "sh[io]rt" test.txt
3、需求: 查找“oo”前面不是“w”的字符串。使用 “[^w]”来实现
[root@zwb mnt]# grep -n '[^w]oo' test.txt

解析:会发现11行和12行,也被匹配到了。此时,是这样的,11行有d三个"ooo",而我们过滤的是两个"oo",但他识别后两个“oo”时两个"oo"的前面就是o而不是w。12行同理。
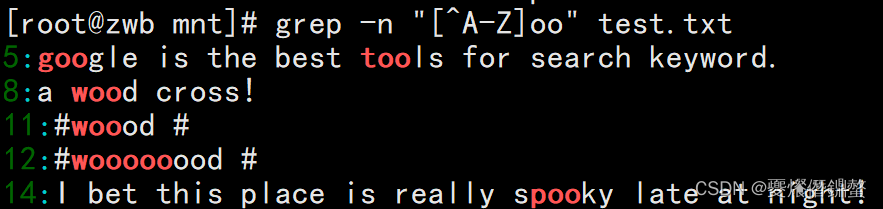
4、需求:若不希望“oo”前面存在小写字母,用[^a-z] 其中a-z表示小写字母,使用A-Z则表示大写,
[0-9]表示数字。
[root@zwb mnt]# grep -n "[^a-z]oo" test.txt

[root@zwb mnt]# grep -n "[^A-Z]oo" test.txt
[root@zwb mnt]# grep -n "[0-9]" test.txt

5、使用grep配合使用“^”(行首)表示以什么为开头、“$”(行尾)以什么为结尾
①需求:使用grep查找行首以the开头的。

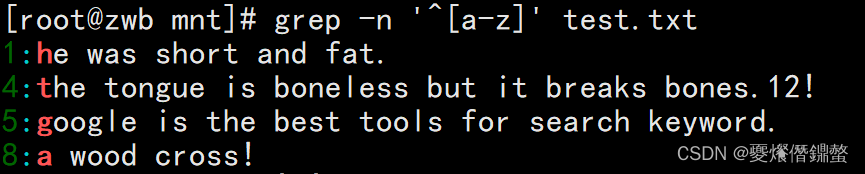
②查询以小写字母开头的行可以通过“^[a-z]”规则来过滤,查询大写字母开头的行则使用“^[A-Z]”规则,若查询不以字母开头的行则使用“^[^a-zA-Z]”规则。
[root@zwb mnt]# grep -n '^[a-z]' test.txt
[root@zwb mnt]# grep -n '^[^a-zA-Z]' test.txt

6、grep过滤查找空白行和点结尾
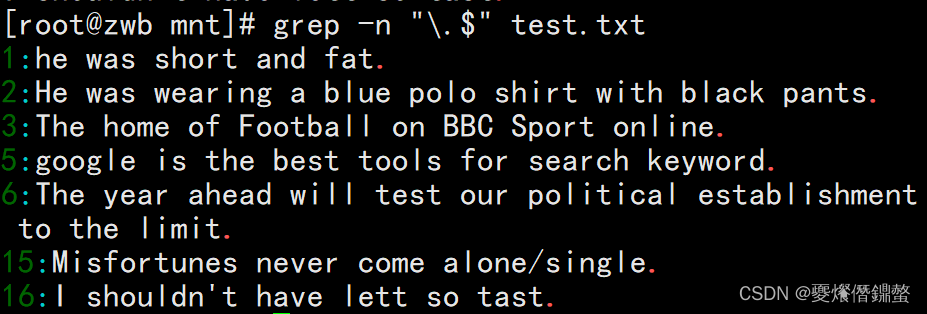
①需求:查询以小数点(.)结尾的行,小数点在正则中是元元素,具有特殊含义,用”\“,不进行转义。
[root@zwb mnt]# grep -n "\.$" test.txt
②使用grep查询空白行,"^$"
[root@zwb mnt]# grep -n "^$" test.txt

7、查找任意一个字符“.” 与重复字符“*”
在正则表达式中小数点(.)也是一个元字符,匹配任意一个字符,所以上面代表结束的点号时需要加“\”
“*”代表的是重复零个或多个前面的重复字符,例如:“o*”表示拥有零个(即为空字符)或大于等于一个“o”的字符,因为允许空字符。
①需求:grep 查找w和d之间有两任意字符的。
[root@zwb mnt]# grep "w..d" test.txt

②”o*“表示含义0个o或者多个o
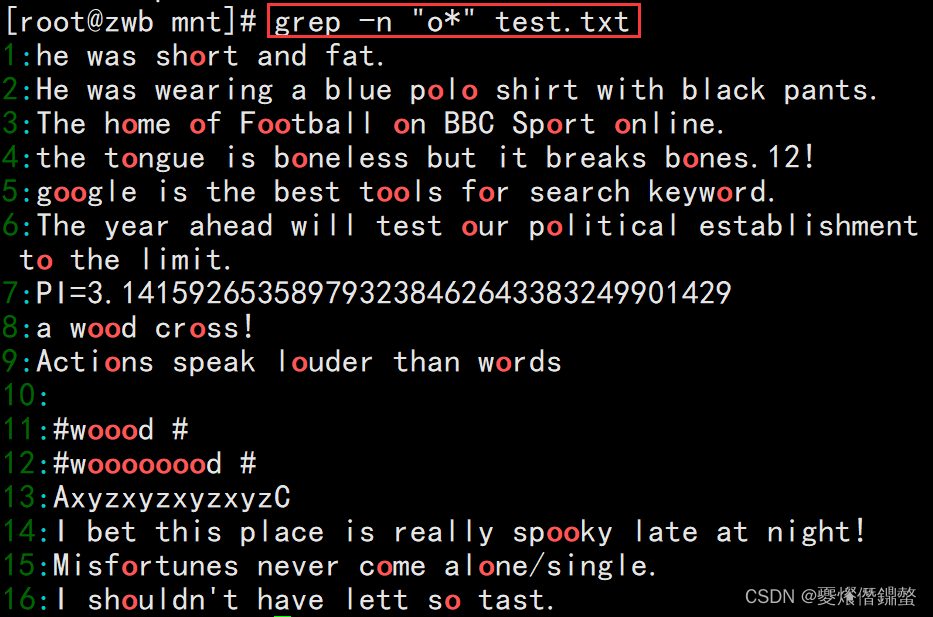
解析:表示含有0个o时,打印了所有。
②”oo*“表示第一o存在,第二个o后面有个*号,表示第二个o可以是一个o或者多个o。
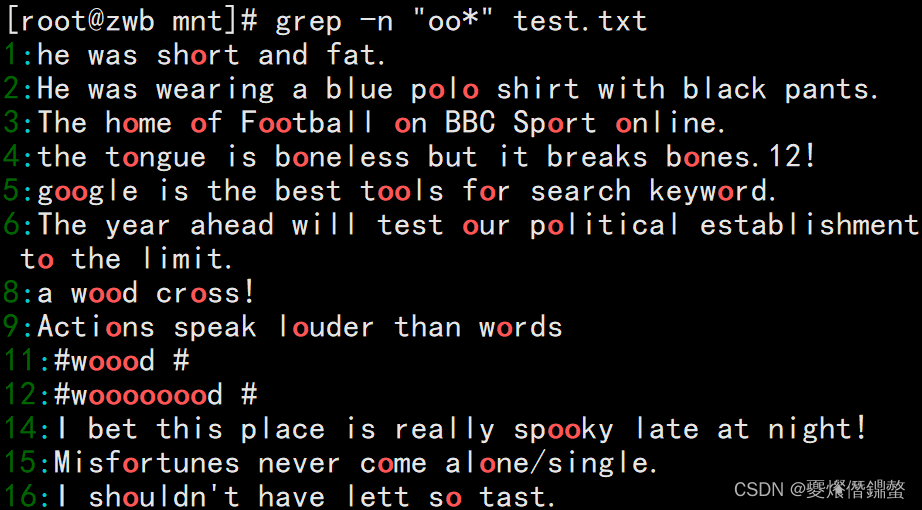
解析:文本中至少含有一个o
③”ooo*“表示第一o存在,第二个o存在,第三个o后面有个*号,表示第三个o可以是一个o或者多个o。
[root@zwb mnt]# grep -n "ooo*" test.txt

④ 查询以 w 开头 d 结尾,中间包含至少一个 o 的字符串。

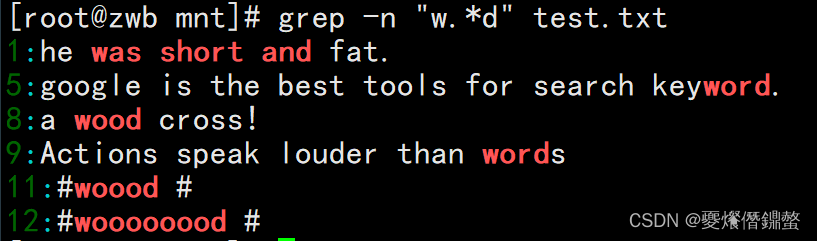
⑤ 查询以 w 开头 d 结尾,中间的字符可有可无的字符串
[root@zwb mnt]# grep -n "w.*d" test.txt
⑥查询任意数字所在行
[root@zwb mnt]# grep "[0-9][0-9]*" test.txt

8、查找连续字符范围“{}”
我们使用“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一个范围内的重复的字符串,用基础正则表达式中的限定范围的字符“{}”,因为“{}”在Shell中具有特殊意义,所以在使用“{}”字时,需要利用转义字符“\”,将“{}”字符转换成普通字符。
①查询两个 o 的字符
[root@zwb mnt]# grep -n "o\{2\}" test.txt

②查询以 w 开头以 d 结尾,中间包含 2~5