目标检测
文章目录
之前的章节中学习到的是图像分类模型,图像中只有一个主要物体对象,只需关注如何识别图像中的类别即可。然而,在通常的图片中,也有可能一张图片有多个物体,我们想要知道感兴趣的物体在图像中的具体位置以及对物体进行分类,在计算机视觉中这类任务称做目标检测或目标识别。
目标检测广泛应用在多个领域:无人驾驶,机器人…那么如何去定位一个目标的位置呢?
目标检测与边界框
边缘框(bounding box)
物体的位置通常用边缘框来表示,一个边缘框用四个数字定义,边界框是矩形的,一种表示方法由矩形左上角的以及右下角的 x x x和 y y y坐标决定,另一种常用的边界框表示方法是边界框中心的 ( x , y ) (x, y) (x,y)轴坐标以及框的宽度和高度。
目标检测的数据集存放,每行代表一个物体,依次按照图片文件名,物体类别,边缘框存放。
目标检测数据集
# 下载图像和csv标签文件的香蕉检测数据集
%matplotlib inline
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
#@save
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
# 读取数据集
#@save
def read_data_bananas(is_train=True):
"""读取香蕉检测数据集中的图像和标签"""
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),
# 其中所有图像都具有相同的香蕉类(索引为0)
targets.append(list(target))
# 将张量中的每个元素除以256,数据归一化
# unsqueeze(1) 在第一维(指第二维度)插入新维度,升级成一个二维变量
return images, torch.tensor(targets).unsqueeze(1) / 256
# 创建Dataset实例加载香蕉检测数据集
#@save
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)
# 为训练集和测试集返回两个数据加载器实例
#@save
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter
读取一个小批量,并打印其中的图像和标签的形状。图像的小批量的形状为(批量大小、通道数、高度、宽度),标签的小批量的形状为(批量大小, m m m,5),其中 m m m是数据集的任何图像中边界框可能出现的最大数量。
小批量计算虽然高效,但它要求每张图像含有相同数量的边界框,以便放在同一个批量中。通常来说,图像可能拥有不同数量个边界框;因此,在达到 m m m之前,边界框少于 m m m的图像将被非法边界框填充。这样,每个边界框的标签将被长度为5的数组表示。
边框数据在txt文本中如何存储:数组中的第一个元素是边界框中对象的类别,其中-1表示用于填充的非法边界框。数组的其余四个元素是边界框左上角和右下角的( x x x, y y y)坐标值(值域在0~1之间)。对于香蕉数据集而言,由于每张图像上只有一个边界框,因此 m = 1 m=1 m=1。
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape
--------------------------------------------------------
# batch[0]对应的是32张图片数据,batch[1]对应的是32个标签
(torch.Size([32, 3, 256, 256]), torch.Size([32, 1, 5]))
# 改变维度顺序由(B,C,H,W)改为(B,H,W,C),将通道数C移动到最后
# 图像归一化:像素值通常在0到255之间,将图像数据归一化到[0,1]的范围,使数据更容易收敛
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])
Q1:工业检测中的数据集非常小(近百张),除了数据增强外,还有什么好的方法
A1:可以使用迁移学习,在已经训练好的大模型上进行迁移学习
锚框
边框真实位置的存储,锚框对真实位置的猜测。
一类目标检测算法是基于锚框:首先提出多个被称为锚框的区域(边缘框),如果锚框中没有关注的物体,不断调整边缘框,预测从锚框到真实边缘框的偏移,选出锚框到真实box的最小偏移量,还可以预测锚框中是否有感兴趣的物体。
loU-交互比
loU用来计算两个框之间的相似度,0表示无重叠,1表示重合。越接近0代表重合性越低,越接近1代表重合度越高。
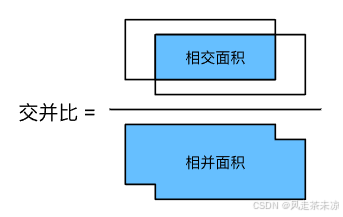
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ . J(\mathcal{A},\mathcal{B}) = \frac{\left|\mathcal{A} \cap \mathcal{B}\right|}{\left| \mathcal{A} \cup \mathcal{B}\right|}. J(A,B)=∣A∪B∣∣A∩B∣.
赋予锚框标号
赋予锚框标号,每个锚框,要么标注成背景,要么会关联上一个真实的边缘框。而在实际中往往会有大量的锚框对应大量的负类样本。
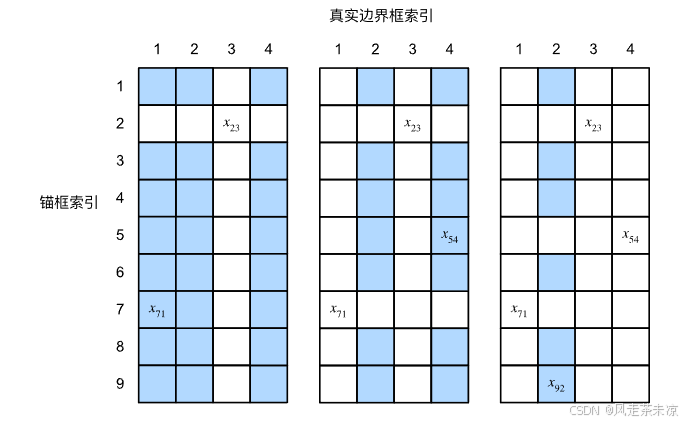
x向坐标代表每张图片的种类数,图中代表一张如片有4个类别的数据。y向坐标代表随机生成的9个锚框,而对应的(x,y)坐标则是该锚框的loU值,仔细想一下,每一个锚框只能对应一个类别,所以说一个锚框去找到与哪种类别loU值最大填入到该行中。接着找不在行2列3的最大值,直至每一个类别都有一个对应的锚框。
使用非极大值抑制(NMS)输出
赋予锚框标号在模型训练时使用,使用非极大值抑制(NMS)用在模型评估时使用。
每个锚框预测以一个边缘框,选中非背景类的最大预测值(它),去掉所有其它和它loU值大与 θ \theta θ的预测,重复上述过程直到所有预测要么被选中,要么被去掉,在下图中就是将0.8和0.7的框去掉。
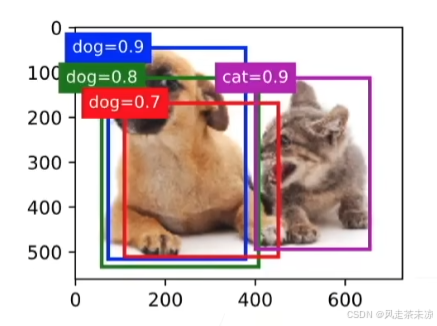
目标检测类算法有很多检测方法,现在大多数都利用锚框来进行目标检测。
锚框预测的步骤:首先生成大量锚框,并赋予标号,每个锚框作为一个样本进行训练,在预测时,使用NMS来去掉冗余的预测。
Q:做nms时过滤去除的手段
A:两种手段,第一种方法是将图片所有类别放在一起,取出每种类别相似度最大值,去掉相似度;第二种方法将每一个类别的锚框拿出来,按照预算值做排序,拿出预算值最大的锚框。两种做法都可以。
目标检测中的常用算法
R-CNN(区域卷积神经网络)
R-CNN也称做Regions with CNN features,首先从输入图像中选取若干(例如2000个)提议区域(如锚框也是一种选取方法),并标注它们的类别和边界框(如偏移量)。 然后,用卷积神经网络对每个提议区域进行前向传播以抽取其特征。 接下来,我们用每个提议区域的特征来预测类别和边界框。
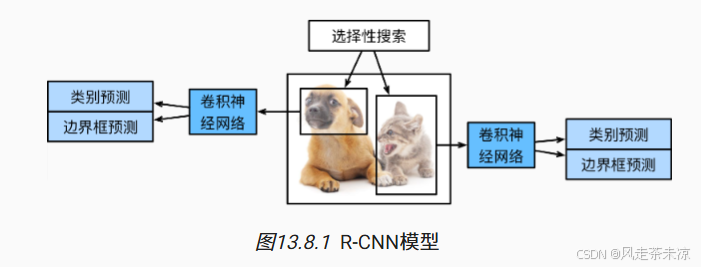
R-CNN包括一下四个步骤:
支持向量机处理分类问题,线性函数处理真实边界框,卷积神经网络抽取图像特征。
- 对输入图像使用选择性搜索选取多个高质量的提议区域。这些提议区域通常是在多个尺度下选取的,并有不同的形状和大小。每个提议区域都将被标注类别和真实边界框。
- 选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征;
- 将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别
- 将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性模型来预测真实边界框
劣势:R-CNN模型通过预训练的卷积神经网络有效地抽取了图像特征,但是它的速度很慢。如果有1张图片有上千个提议区域,这需要上千次的卷积神经网络的前向传播来执行目标检测,需要消耗极大的资源,这种庞大的计算量使得R-CNN无法在现实世界中广泛使用。
Fast R-CNN(快速的区域卷积神经网络)
R-CNN的改进,使用R-CNN一张图片有上千次卷积神经网络的前向传播,发现前向传播时会有可能会处理相同区域的特征,那么我们如何将特征抽取应用在相同的区域上而可以减少卷积神经网络的前向传播呢?Fast R-CNN正是解决了这一主要问题,就是使用整张图像上执行卷积神经网络的前向传播。
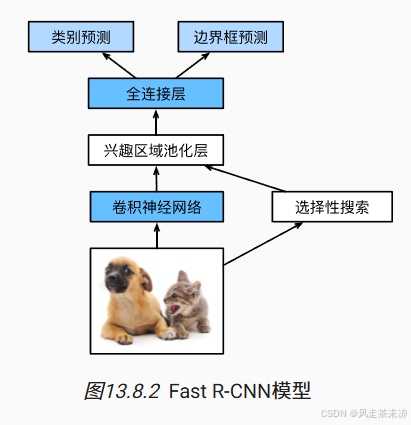
Fast R-CNN模型步骤:
- 与R-CNN相比,Fast R-CNN用来提取整张图片的特征,而不是各个提议区域的特征。此外,这个网络通常会参与训练。设输入一张图片,那么卷积神经网络的输出的形状记为 1 × c × h 1 × w 1 1 \times c \times h_1 \times w_1 1×c×h1×w1
- 与R-CNN相比,Fast R-CNN用来提取特征的卷积神经网络的输入是整个图像,而不是各个提议区域。此外,这个网络通常会参与训练。设输入为一张图像,将卷积神经网络的输出的形状记为 1 × c × h 1 × w 1 1 \times c \times h_1 \times w_1 1×c×h1×w1;
- 假设选择性搜索生成了 n n n个提议区域。这些形状各异的提议区域在卷积神经网络的输出上分别标出了形状各异的兴趣区域。然后,这些感兴趣的区域需要进一步抽取出形状相同的特征(比如指定高度 h 2 h_2 h2和宽度 w 2 w_2 w2),以便于连结后输出。为了实现这一目标,Fast R-CNN引入了兴趣区域汇聚层(RoI pooling):将卷积神经网络的输出和提议区域作为输入,输出连结后的各个提议区域抽取的特征,形状为 n × c × h 2 × w 2 n \times c \times h_2 \times w_2 n×c×h2×w2;
- 通过全连接层将输出形状变换为 n × d n \times d n×d,其中超参数 d d d取决于模型设计;
- 预测 n n n个提议区域中每个区域的类别和边界框。更具体地说,在预测类别和边界框时,将全连接层的输出分别转换为形状为 n × q n \times q n×q( q q q是类别的数量)的输出和形状为 n × 4 n \times 4 n×4的输出。其中预测类别时使用softmax回归。
兴趣区域(Rol)池化层
与普通池化层的区别,池化层可以通过设置汇聚窗口、填充和步幅大小来间接控制输出形状。而兴趣区域汇聚层实可以对每个区域的输出形状进行指定。
例如,指定每个区域输出的高和宽分别为
h
2
h_2
h2和
w
2
w_2
w2。对于任何形状为
h
×
w
h \times w
h×w的兴趣区域窗口,该窗口将被划分为
h
2
×
w
2
h_2 \times w_2
h2×w2子窗口网格,其中每个子窗口的大小约为
(
h
/
h
2
)
×
(
w
/
w
2
)
(h/h_2) \times (w/w_2)
(h/h2)×(w/w2)。
在实践中,任何子窗口的高度和宽度都应向上取整,其中的最大元素作为该子窗口的输出。因此,兴趣区域汇聚层可从形状各异的兴趣区域中均抽取出形状相同的特征。
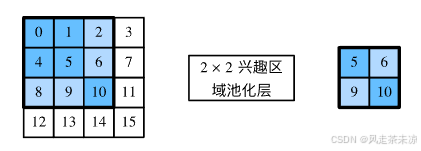
作为说明性示例,在 4 × 4 4 \times 4 4×4的输入中,我们选取了左上角 3 × 3 3\times 3 3×3的兴趣区域。对于该兴趣区域,我们通过 2 × 2 2\times 2 2×2的兴趣区域汇聚层得到一个 2 × 2 2\times 2 2×2的输出。请注意,四个划分后的子窗口中分别含有元素0、1、4、5(5最大);2、6(6最大);8、9(9最大);以及10。
代码实现
import torch
import torchvision
# 神经网络提取特征矩阵
X = torch.arange(16.).reshape(1, 1, 4, 4)
x = tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
# 生成两个提议区域
rois = torch.Tensor([[0, 0, 0, 20, 20], [0, 0, 10, 30, 30]])
rois.shape
# 特征矩阵是原图像高和宽的1/10,因此将两个提议区域的坐标按spatial_scale*0.1
# 映射到特征矩阵对应的(0,0,2,2)和(0,1,3,3)位置抽取相同形状的特征
torchvision.ops.roi_pool(X, rois, output_size=(2, 2), spatial_scale=0.1)
# 结果
# tensor([[[[ 5., 6.],
# [ 9., 10.]]],
# [[[ 9., 11.],
# [13., 15.]]]])
Faster R-CNN(更快的区域卷积神经网络)
Fast R-CNN可以有效的减少图片多次进入神经网络,加快训练速度;而Faster R-CNN相较于Fast R-CNN的区别,优化提议区域的选取,将选择性搜索替换为区域提议网络,从而减少提议区域的生成数量,并保证目标检测的精度。
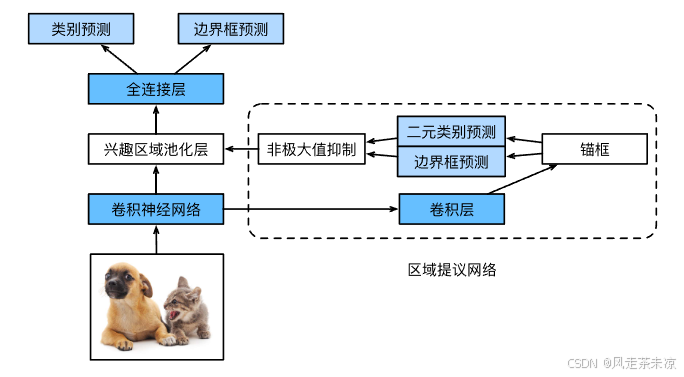
具体来说,区域提议网络的计算步骤如下:(高质量锚框)
- 使用填充为1的 3 × 3 3\times 3 3×3的卷积层变换卷积神经网络的输出,并将输出通道数记为 c c c。这样,卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为 c c c的新特征。
- 以特征图的每个像素为中心,生成多个不同大小和宽高比的锚框并标注它们。
- 使用锚框中心单元长度为 c c c的特征,分别预测该锚框的二元类别(含目标还是背景)和边界框。
- 使用非极大值抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
值得一提的是,区域提议网络作为Faster R-CNN模型的一部分,是和整个模型一起训练得到的。换句话说,Faster R-CNN的目标函数不仅包括目标检测中的类别和边界框预测,还包括区域提议网络中锚框的二元类别和边界框预测。作为端到端训练的结果,区域提议网络能够学习到如何生成高质量的提议区域,从而在减少了从数据中学习的提议区域的数量的情况下,仍保持目标检测的精度。
Mask R-CNN
相较于Faster R-CNN的提升,利用了像素级别的数据,将目标检测的数据精细化,更有效地利用像素级别的标注信息来提升目标检测的精度。
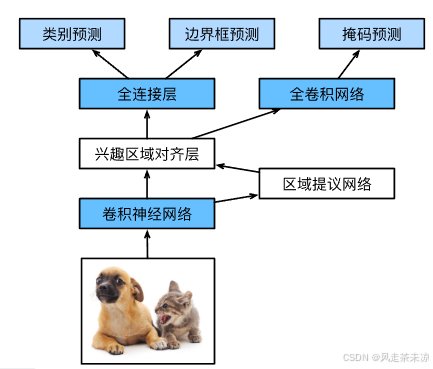
Mask R-CNN是基于Faster R-CNN修改而来。区别:将兴趣区域的池化层转化为了兴趣区域的对齐层,使用双线性插值来保留特征图上的空间信息,从而更适用于像素级预测。
兴趣区域对齐层的输出包含了所有与兴趣区域的形状相同的特征图。它们不仅被用于预测每个兴趣区域的类别和边界框,还通过额外的全卷积网络预测目标的像素级位置。兴趣区域的对其层对weight权值相较于兴趣区域池化层的划分更加精细,可以有效提高精度。
| 目标检测算法 | 优点和相较于上一代的改进 |
|---|---|
| R-CNN | 从图像选取若干提议区域,使用卷积神经网络对每个提议区域执行前向传播以抽取其特征,然后再用这些特征来预测提议区域的类别和边界框。 |
| Fast R-CNN | 对整个图像做卷积神经网络的前向传播;同时引入了兴趣区域汇聚层,从而为具有不同形状的兴趣区域抽取相同形状的特征 |
| Faster R-CNN | 将Fast R-CNN中使用的选择性搜索替换为参与训练的区域提议网络,这样后者可以在减少提议区域数量的情况下仍保证目标检测的精度。 |
| Mask R-CNN | 在Faster R-CNN的基础上引入了一个全卷积网络,从而借助目标的像素级位置进一步提升目标检测的精度。 |
- Faster R-CNN和Mask R-CNN是在求高精度场景下的常用算法
SSD(单发多框检测)
SSD也称作single stage detector,对每个像素生成多个以它为中心的锚框。对每个像素生成多个以它为中心的锚框,给定n种不同的尺寸和m个高宽比,那么生成n+m-1个锚框,选取n-m+1个组合。
为什么要选取n-m+1个组合而不是n*m个组合呢?
因为n*m个锚框生成的锚框数量较多,增大了计算量。为了降低计算的复杂度,有些方法会根据实际需要来缩减锚框组合数。具体来说:按不同尺度生成锚框时,可能只为最接近目标物体大小的框分配所有高宽比。或者,为最常用的高宽比分配所有尺度组合,而为其它高宽比选择少量尺度组合。
即最终生成的锚框数约为n-m+1,而并非 n × m n\times m n×m
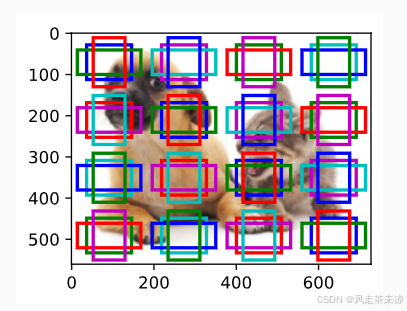
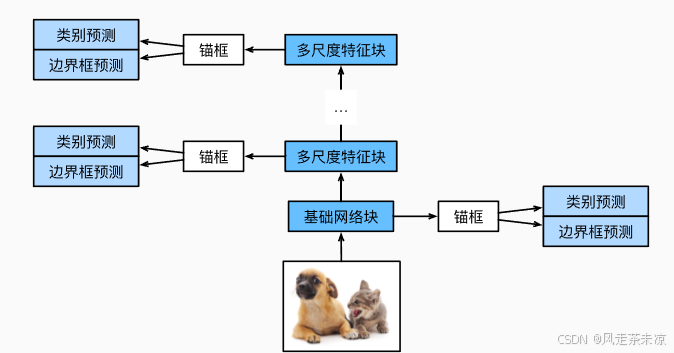
SSD单发多框检测,顾名思义一次进行多个锚框的检测,通过一个基础网络块提取到featuremap,对featuremap产生多个锚框,在对产生的这些锚框进行类别预测以及边界框预测。
通过多个卷积层块来减半高宽,例如:在经过基础网络块的处理后为64*64的图片比例,而到达卷积层后图片比例变为16*16。依次类推可知,越往上层走的卷积块生成的多尺度特征图较小,但有较大的感受野。在整个神经网络架构每段都会生成锚框,底部段来拟合小物体(感受野小),顶部段来拟合大物体(感受野大),同时对每个锚框预测类别和边缘框。
- SSD通过单神经网络来检测模型
- 以每个像素为中心的产生多个锚框;在多个段的输出上进行多尺度的检测
YOLO
口头禅:You Only Live Once(哈哈哈,你不要太有压力)->you look one(你只看一次)
SSD中锚框生成大量重叠,浪费了很多计算;所以说减少锚框重叠用来优化计算。
YOLO将图片均匀分成 S × S S \times S S×S个锚框,每个锚框预测B个边缘框(B指的是一张图片中的B种类别)。原始想法是这样子的(YOLOv3之前),后来的想法发生改变。利用聚类算法来计算某种类别的锚框形状,而这种锚框形状作为物体检测的一种先验知识来进行物体检测。
图像中的纵向线,是通过利用tricks提升的精度变化。