本教程将通过实验的形式,带领你快速完成YOLOv5从.pt到.rknn的格式转换。
注:格式转换共有两个步骤,为.pt->.onnx->.rknn
本次实验.pt->.onnx在window环境进行,并且默认读者搭建好了yolov5的相关环境。
.onnx->.rknn在Ubuntu虚拟机环境进行,并且默认读者搭建好了rknn_toolkit2环境。
1.1 下载yolov5程序。
在github上下载yolo官方的yolov5,版本可以为master或者6.0版本(均验证过)

下载解压后,程序如图

1.2 下载yolov5s.pt
在GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite移动至网页下方下载,也可以直接运行train.py下载(速度慢)

下载完成后,将.pt文件移动到yolov5程序文件夹。
1.3 修改export.py程序
改动1:

opset从17改为13(因为我使用时是用的13,可以不改试一下)
default从torchscript改为onnx
改动2:

修改代码
shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
为
shape = tuple(y[0].shape)
1.4 修改yolo.py

将程序修改为如下:(注意,训练模型时需要把yolo.py的改动还原)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
z.append(torch.sigmoid(self.m[i](x[i]))) # conv output
return z
1.5 运行export.py
运行时可能会提示你需要安装onnx库,用pip安装即可。

提示运行成功,可以在yolov5s.pt同级目录下找到yolov5s.onnx。
用Netron可以查看网络结构如下。
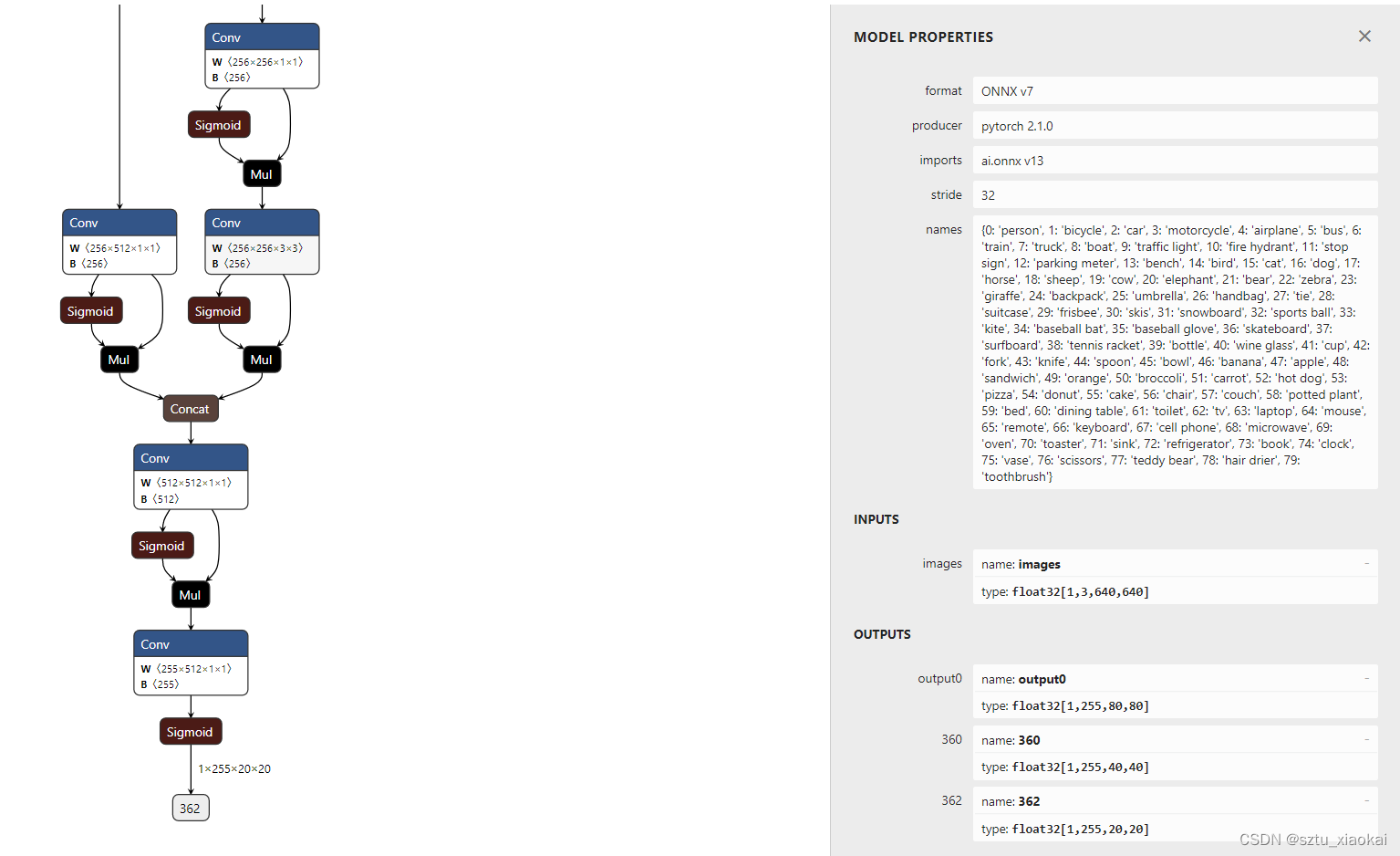
2. 将步骤1获取的onnx上传到Ubuntu虚拟机,修改下述变量。
import cv2
import numpy as np
from rknn.api import RKNN
ONNX_MODEL = 'yolov5s.onnx' # onnx模型的路径
RKNN_MODEL = 'yolov5s.rknn' # 导出的模型路径
IMG_PATH = 'image/bus.jpg' # 测试rknn模型的图片路径
DATASET = './datasets.txt' # 量化数据集(往下移,有介绍)
QUANTIZE_ON = True
OBJ_THRESH = 0.60 # 默认精度
NMS_THRESH = 0.10
IMG_SIZE = 640
# 类别名
CLASSES = ("person", "bicycle", "car", "motorbike ", "aeroplane ", "bus ", "train", "truck ", "boat", "traffic light", "fire hydrant", "stop sign ", "parking meter", "bench", "bird", "cat", "dog ", "horse ", "sheep", "cow", "elephant", "bear", "zebra ", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife ", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza ", "donut", "cake", "chair", "sofa", "pottedplant", "bed", "diningtable", "toilet ", "tvmonitor", "laptop ", "mouse ", "remote ", "keyboard ", "cell phone", "microwave ", "oven ", "toaster", "sink", "refrigerator ", "book", "clock", "vase", "scissors ", "teddy bear ", "hair drier", "toothbrush ")
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def process(input, mask, anchors):anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = input[..., 4]
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = input[..., 5:]
box_xy = input[..., :2]*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(input[..., 2:4]*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
boxes = boxes.reshape(-1, 4)
box_confidences = box_confidences.reshape(-1)
box_class_probs = box_class_probs.reshape(-1, box_class_probs.shape[-1])
_box_pos = np.where(box_confidences >= OBJ_THRESH)
boxes = boxes[_box_pos]
box_confidences = box_confidences[_box_pos]
box_class_probs = box_class_probs[_box_pos]
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score >= OBJ_THRESH)
boxes = boxes[_class_pos]
classes = classes[_class_pos]
scores = (class_max_score* box_confidences)[_class_pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
if score > OBJ_THRESH:
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 1)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
# pre-process config
print('--> Config model')
rknn.config(
# mean_values=[123.675, 116.28, 103.53],
# std_values=[58.395, 58.395, 58.395],
mean_values=[0, 0, 0],
std_values=[255, 255, 255],
quantized_dtype='asymmetric_quantized-8',
quantized_algorithm='normal', # mmse normal kl_divergence
quantized_method='channel', # layer channel
quant_img_RGB2BGR=False,
target_platform='rk3588',
float_dtype='float16',
optimization_level=3, # 0 1 2 3
remove_weight=False, # 去除权重信息以生成从模型
compress_weight=False,
inputs_yuv_fmt=None,
single_core_mode=False
)
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread(IMG_PATH)
cv2.imwrite('img0.jpg', img)
img0 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h0, w0 = img.shape[:2]
r = 640 / max(h0, w0)
if r != 1:
interp = cv2.INTER_AREA if r < 1 else cv2.INTER_LINEAR
img0 = cv2.resize(img0, (int(w0 * r), int(h0 * r)), interpolation=interp)
img0, ratio, (dw, dh) = letterbox(img0, new_shape=(IMG_SIZE, IMG_SIZE))
img1 = img0.reshape(1, 640, 640, 3)
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img1], data_format='nhwc')
# np.save('./onnx_yolov5_0.npy', outputs[0])
# np.save('./onnx_yolov5_1.npy', outputs[1])
# np.save('./onnx_yolov5_2.npy', outputs[2])
print('done')
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
print(input0_data.shape)
print(input1_data.shape)
print(input2_data.shape)
input0_data = input0_data.reshape([3, -1]+[80, 80])
input1_data = input1_data.reshape([3, -1]+[40, 40])
input2_data = input2_data.reshape([3, -1]+[20, 20])
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process(input_data)
img0 = cv2.cvtColor(img0, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(img0, boxes, scores, classes)
# show output
# cv2.imshow("post process result", img_1)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
cv2.imwrite('img1.jpg', img0)
rknn.release()
代码参考:https://blog.csdn.net/yangbisheng1121/article/details/128785690
注:datasets.txt如图,内容是用于协助量化的图片路径。
一般用摄像头现场的图片作为量化数据集,数量没有明确要求。

运行程序后,可以当前程序路径下多了两张图片。其中,img0.jpg为原图,img1.jpg为推理后的图片,同时在rknn路径下多了.rknn文件。


如果觉得模型的精度不达标,可以参考如下教程。
【AI深度学习推理加速器】——RKNPU2 从入门到实践(基于RK3588和RK3568)_哔哩哔哩_bilibili
如果教程对你有帮助,记得点赞。👍👍👍