文章目录
📚信号和噪声
- 噪声信号充斥着整个世界,凡是有信息传递的地方就有噪声。
- 举个例子✋,蛋蛋在地铁上遇到了一个他喜欢的女孩,但由于地铁的嘈杂环境,他需要采取一些策略来确保他的表白能够被女孩清晰地接收到。他采取的策略包括:
- 使用扩音器来提高声音的强度,这样可以改善信号与噪声的强度比,使得有效信号更容易被接收。
- 每个字清晰地说三遍,这样做增加了信息的冗余度,即使有些字因为噪声而没有被听清,女孩也能通过重复的部分理解他的意思。
- 结尾用手比画一个爱心,这是一种非语言的信号,可以作为关键信息的额外保护,确保即使语言信息受到干扰,这个关键信息也能被理解。
- 在实际通信中,这些策略可以与码率(Code rate)联系起来。码率定义为有效信息长度(information bits)与实际通信中传输的信息长度(channel use)的比值,可以反映冗余程度。
- Code rate=(information bits) / (channel use)
- 蛋蛋的策略中,每个字说三遍,相当于码率为1/3,这意味着冗余度较高,但同时也意味着即使在噪声环境下,信息的准确性也得到了保证。
- 香农指出,每一种实际的信息传输通道都有一个参数C。如果码率低于信道容量(Code rate < C),理论上信息传递的错误率可以趋近于0。如何趋近于0,就是纠错编码ECC要做的事情了。
📚通信系统模型
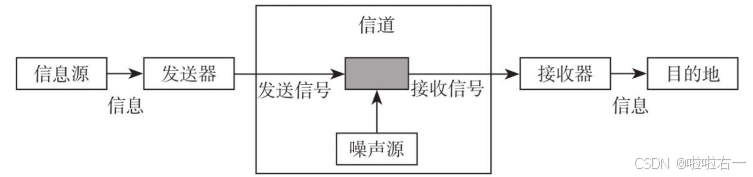
- 所有的信息传播都少不了通信系统。在一个完整的通信系统模型中,信息由信息源产生,由发送器发送出信号,通过包含噪声的信号传输通道到达接收器,再由接收器提取信息并发送到目的地。
- 上述例子中,蛋蛋心中所想就是信息源;发送器是神经和肌肉控制的嗓子;声音就是信号;嘈杂的车厢就是信道;女神的耳朵就是接收器,最终信息反映到女神大脑中形成信息。
- SSD存入和读出信息也是一个通信系统。信息是用户写入的原始数据,经过SSD后端的发送器处理后转化为闪存的指令,信号就是闪存上存储的电荷,电荷存储时会有自身泄漏问题,在读的过程中会受到周围电荷的影响,这是闪存的信道特性,最后数据通过SSD后端的读取接收器完成读取过程。
- 在二进制编码的系统中,有两种常见的信道模型——BSC(Binary SymmetricChannel,二进制对称信道)和BEC(Binary ErasureChannel,二进制擦除信道)。
- 一句话区分BSC和BEC:
- BSC出错:接收者收到的是0,但发送者可能发送的是1;同样,收到的是1,但发送者可能发送的是0;
- BEC丢位:接收者如果收到0(1),那么发送者发送的肯定是0(1);如果传输发生错误,接收者则接收不到信息。
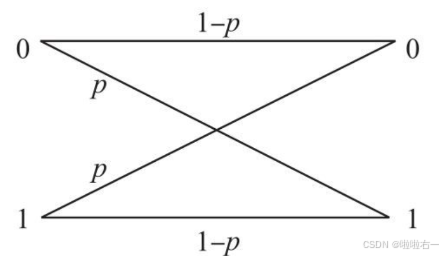
- ⭐️BSC模型
- 二进制信号由0、1组成,由于信道噪声的影响,0、1各有相同的概率p发生翻转,即0变1,1变0。信号仍然保持不变的概率为1-p。
- 例如一串二进制信号,在经过BSC模型后,原始信号101001101010变为111001111000。
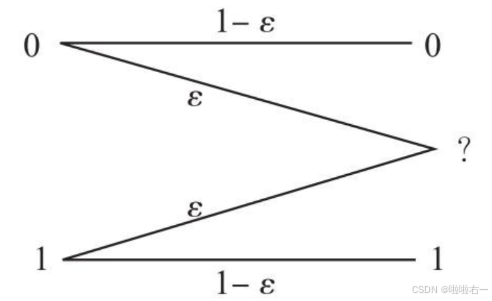
- ⭐️BEC模型
- 在信号传输中,无论是0还是1都有一定概率ε变为一个无法识别的状态。
- 例如一串二进制信号,在经过BEC模型后,原始信号101001101010变为1x10011x10x0(x表示未知状态)。
- SSD里的信道模型一般采用BSC,即认为闪存信号存在一定概率的位翻转。为了使信息从源头在经过噪声的信道后能够准确到达目的地,我们要对信息进行编码,通过增加冗余的方式保护信息。基本流程如下所示↓
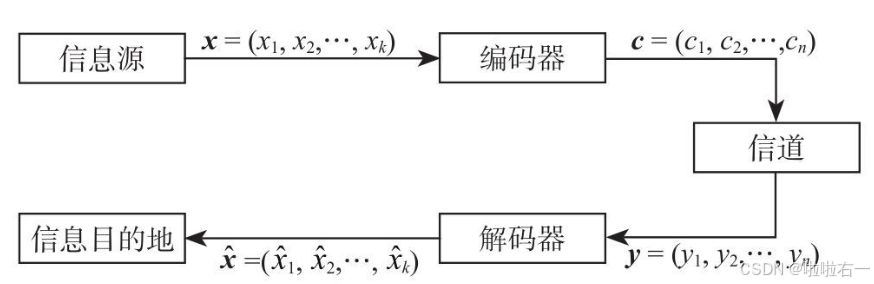
- 信息源发出的信息可用k位的信息x表示,经过编码器(encoder)转化为n位信号c。这个从k位到n位的过程叫编码过程,也是添加冗余的过程。
- 信号c的所有集合叫编码集合。发送器把信号发送出去,经过信道后,接收器收到n位信号y,经过解码器转成k位信息 ,这个过程是解码过程。
📚纠错编码的基本思想
- 纠错编码的核心设计思想是通过增加冗余信息,使原始信息的编码之间有足够大的区别。
🐇编码距离
- 举个例子✋:蛋蛋表白时的信息为“我喜欢你”四个字,为了防止女神听不到,他添加了冗余信息。
- 经过蛋蛋添加冗余后信息变为“我我我喜喜喜欢欢欢你你你”,其实女神收到的信号为(我我饿Txx欢花欢xx里),其中x为邻座大妈的霸气笑声。
- 在女神的词典中,有意义的语句全都列出来,发现跟蛋蛋发出声音最相似的就是:“我我我喜喜喜欢欢欢你你你”。女神的词典可以看成所有可能编码的集合,用编码距离衡量这个编码集合中容易混淆的程度。
- 这里的距离指的是汉明距离,即两个信号之间有多少位是不同的。
- 比如信号(0,1,1)与(0,0,0)的距离为2,(1,1,1)与(0,0,0)的距离为3。
- 一个编码集合里,大家不一定是均匀分布的,有些编码之间距离比较近,有些比较远,编码距离指的是最近的两个编码之间的距离。
- 解码的时候,一个最暴力的方法就是一一比较接收到的信号和所有有效编码之间的编码距离,选择编码距离最小的。所以编码距离的重要作用是指示编码纠错的位个数。
- 蛋蛋和阿呆住在不同的地方,相距为d。蛋蛋养了一群羊,阿呆也养了一群羊。羊会乱跑,显然只要羊跑的距离小于d/2,就可以判断羊属于蛋蛋还是阿呆。
- 所以对纠错码而言,编码距离为d,只要位翻转个数小于d/2,我们就可以根据“离谁近就归谁”的原则去纠错。
🐇线性纠错码的基石——奇偶校验
-
收钱的阿姨狐疑地拿起蛋蛋递过来的100元钱,迎着灯光仔细打量过后,又取出了紫外线灯从头到尾照了一下,终于把钱放进钱盒子里,找了蛋蛋99.5元。阿姨检查钞票的行为叫信号校验。
-
信号校验的基本模型是:对信号进行某种特定的处理后,如果得到期望的结果则校验通过,否则校验失败。
-
这里信号用y表示,特定的处理用H表示。H表示对信号y进行了处理。处理结果用CR表示。
-
在二进制的世界里,最基础的校验方法是奇偶校验(Parity-Check)。对于n位二进制信号来说:
- 例如长度为16的二进制数据1000100111011011,其中1的个数为9,故CR=1。
- 判断信号里的1的个数为奇还是偶,用异或(即xor)运算,符号为⊕,“相加不进位”。
-
利用奇偶校验可以构造最简单的校验码——单位校验码(single bit parity checkcode,SPC)。
- 把长度为n的二进制信息增加1位,即 y n + 1 y_n+1 yn+1变成y’,使得:CR=H(y’)=y1⊕y2⊕y3⊕…⊕yn⊕yn+1=0 (a)
- 现在y’构成了y的单位校验码。(a)又称奇偶校验方程。显然,y’中任意一个位如果发生位翻转,无论从0到1,还是从1到0,校验方程CR=1。SPC可以探知任意单位的翻转。
- 对于偶数个位翻转,SPC无法探知,而且校验方程无法知道位翻转的位置,所以无法纠错。
- 一个自然的想法是,增加SPC的个数,增加冗余的校验信息。同一个位被好几个校验方程保护,当它出现错误时就不会被漏掉。
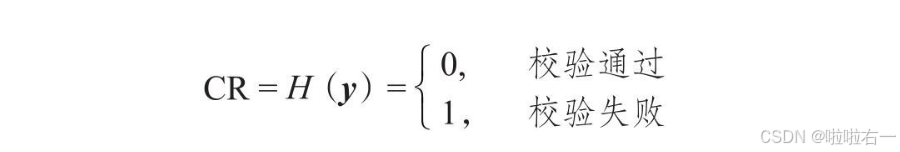
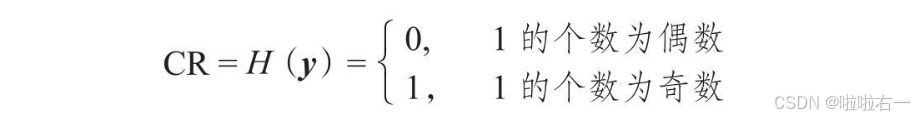
🐇校验矩阵H和生成矩阵G
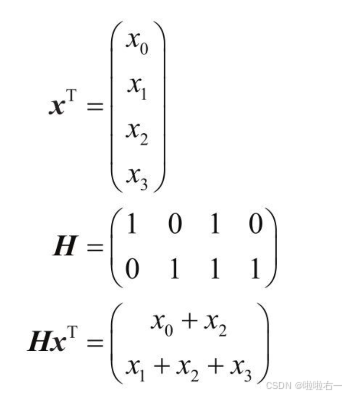
- 多个校验方程可以表示为校验矩阵H。有了H就可以确定所有正确的码字。对于所有 x = ( x 0 , x 1 , x 2 , x 3 , x 4 , x 5 … ) x=(x_0,x_1,x_2,x_3,x_4,x_5…) x=(x0,x1,x2,x3,x4,x5…),只要满足 H x T = 0 Hx^T=0 HxT=0,x就是正确的码字。如果不满足,则x不属于正确的码字,认为在传输的过程中x出现了错误。
- 举例:长度为4的信号,
x
=
(
x
0
,
x
1
,
x
2
,
x
3
)
x=(x_0,x_1,x_2,x_3)
x=(x0,x1,x2,x3),有两个校验方程:
x
0
+
x
2
=
0
x_0+x_2=0
x0+x2=0,
x
1
+
x
2
+
x
3
=
0
x_1+x_2+x_3=0
x1+x2+x3=0现在用+代替⊕:
- 所有满足奇偶校验方程的x组成了一个编码集合。一般来说,编码长度为 n n n位,有 r r r个线性独立的校验方程,则可以提供 k = ( n − r ) k=(n-r) k=(n−r)个有效信息位和r个校验位。
- 对于线性分组编码而言,原始信号u经过一定的线性变换可以生成纠错码c,完成冗余的添加。线性变换可以写成矩阵的形式,这个矩阵就是生成矩阵G,表示为c=uG。其中,c为n位信号,u为k位信号,G为k×n大小的矩阵。由H矩阵可以推导出生成矩阵G。
📚LDPC原理简介
🐇LDPC是什么
-
LDPC全称是Low Density Parity-Check Code,即低密度奇偶校验码,是目前最主流的纠错码。
-
LDPC的特征是低密度,也就是说校验矩阵H里面的1分布比较稀疏,比如:
-
LDPC又分为正则LDPC(regular LDPC)和非正则LDPC(irregular LDPC)编码。正则LDPC保证校验矩阵每行有固定J个1,每列有固定K个1;非正则LDPC没有上述限制。

🐇Tanner图
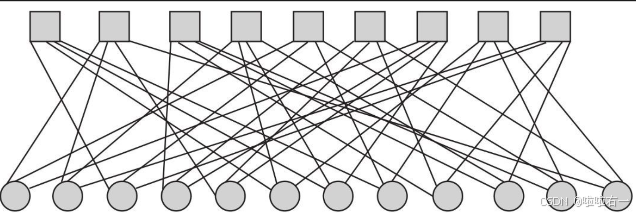
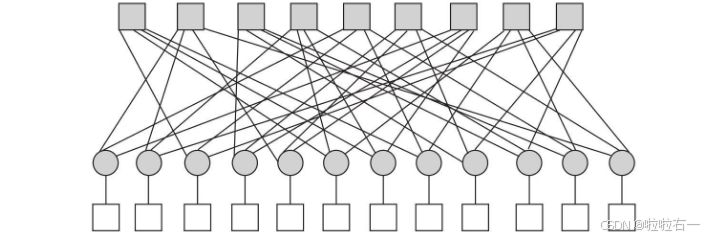
- H矩阵可以直观地表示为Tanner图。Tanner图由节点和连线组成。节点有两种,一种叫b节点(bit node),另一种叫c节点(check node)。假设信号编码长度为n,其中每一个位用一个b节点表示。校验方程个数为r,每一个校验方程用一个c节点表示。
- 如果某个b节点 b i b_i bi参与了某个c节点 c j c_j cj的校验方程,则用连线把b节点 b i b_i bi和c节点 c j c_j cj连起来。b节点用圆形表示,c节点用方块表示。
- 下图是一个典型的正则LDPC的Tanner图。
📚LDPC解码
- LDPC的解码方法有硬判决解码(hard decisiondecode)和软判决解码(softdecision decode)两种。
- 一种经典的硬判决算法——Bit-flipping算法,以及一种软判决算法——和积信息传播算法。
🐇Bit-flipping算法
-
Bit-flipping算法的核心思想:如果信号中有一个位参与的大量校验方程都校验失败,那么这个位有错误的概率很大。
-
校验矩阵的稀疏性把信号的位尽量随机地分散到多个校验方程中去。Bit-flipping算法运用消息传递方法,通过不断迭代达到最终的纠错效果。
-
Bit-flipping解码算法如下:给定一个n位信号 y = ( y 1 , y 2 , … . y n ) y=(y_1,y_2,….y_n) y=(y1,y2,….yn),校验矩阵H。画出H矩阵对应的Tanner图。n位信号对应n个b节点,r个c节点。
- ①每个b节点向自己连接的c节点发送自己是0还是1。初始是第 i i i个位发送初始值 y i y_i yi。
- ②每个c节点收到很多b节点的信息,每个c节点代表一个校验方程。
- 如果方程满足,c节点将每个b节点的消息原封不动地发送回去。
- 如果校验失败,c节点将每个b节点发来的消息取反后,发送回去。
- ③每个b节点跟好多c节点相连,b节点收到所有来自c节点的消息后,采用投票法来更新这一轮输出的消息。参加投票的包含每个位的初始值。投票的原则是少数服从多数。
- ④ b节点更新好后,停止条件:所有的校验方程满足或者迭代次数超过上限。如果停止条件不满足,则需要转到步骤1继续迭代。
-
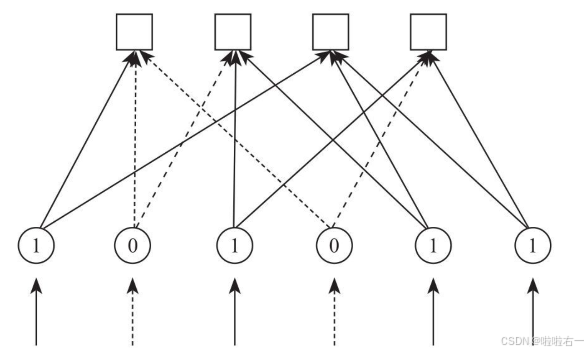
举个例子✋:输入信号y=(1, 0, 1, 0, 1,1)
-
【步骤1】后,实线箭头表示传递的信息为1,虚线箭头表示传递的信息为0。
-
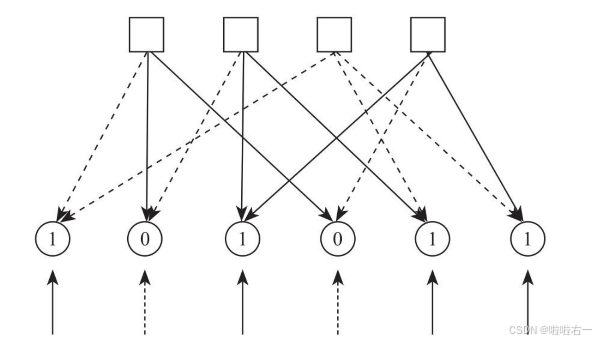
【步骤2】,c节点给各个b节点发回消息。满足校验方程的c节点原封不动返回消息,不满足则取反返回。
-
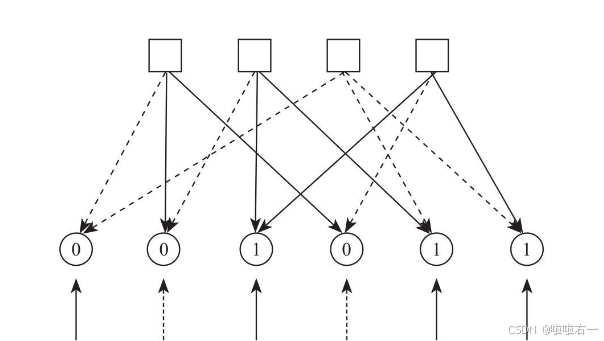
【步骤3】,用投票法表决并更新b节点的值。
-
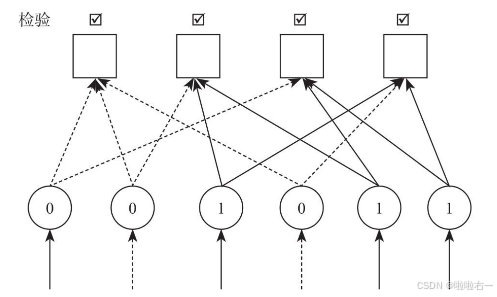
【步骤4】,重新检查节点,发现校验方程满足条件,结束。
-
-
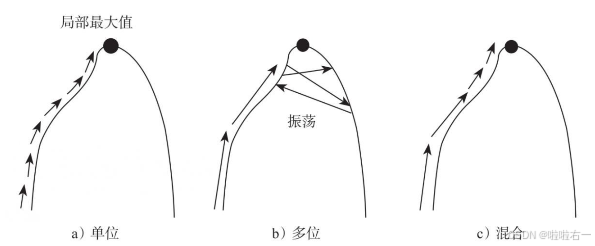
Bit-flipping算法有很多细节值得讨论。其中一个问题是:b节点更新时,一次更改一个还是一次更改多个,或者两者结合?因为校验矩阵的结构,如果同时改变很多b节点的话,可能无法收敛。这时可以将梯度下降法应用到Bit-flipping算法中。通过构造目标函数(目标函数包括校验方程最小误差,以及与原信号最大相似)来更新b节点。最终的结论是:
- 每次单个位翻转的收敛性好,但是处理比较慢;
- 翻转多个的话会导致收敛性振荡,但是速度快;
- 一个中间方案是,先进行多个位翻转,等校验方程失败的个数小到一定程度后,再进行单个位翻转。
🐇和积信息传播算法
-
和积信息传播算法(sum-productmessage passing,简称和积算法),是贝叶斯网络、马尔可夫随机场等概率图模型中用于推断的一种信息传递算法,目前广泛应用于人工智能和信息处理领域,而它的一个非常经典的应用就是LDPC。
-
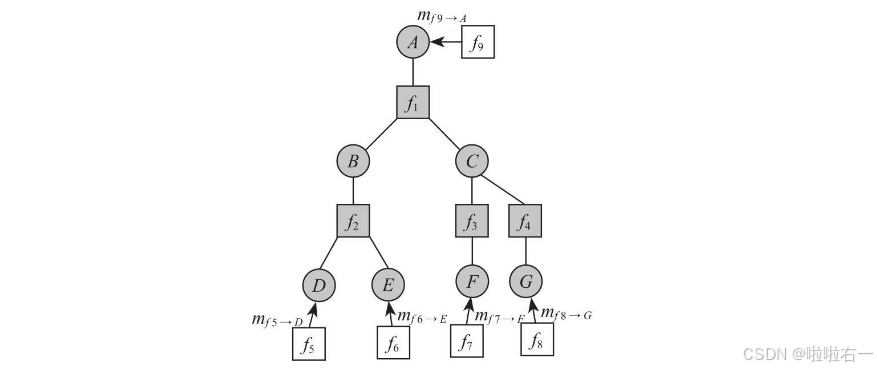
如下图所示,每个涂色方块表示一个c节点,代表一个校验方程,而校验方程是一种非常简单的约束方程。举个例子✋:
- 每个圆圈表示与b节点对应的 X i X_i Xi,而与之前Tanner图不同的是每个b节点都有唯一的观察约束节点(用空心方块表示)与之绑定。
- 观察约束节点负责提供 P ( X i ∣ Y i = y i ) P(X_i|Y_i=y_i) P(Xi∣Yi=yi),所以约束方程 f Y ( X i ) = P ( X i ∣ Y i = y i ) f_Y(X_i)=P(X_i|Y_i=y_i) fY(Xi)=P(Xi∣Yi=yi)。
- 我们的目的是求得每一个边缘概率 P ( X i ) P(X_i) P(Xi)。最终的 P ( X i ) = K f ( X i ) P(X_i)=Kf(X_i) P(Xi)=Kf(Xi),K为归一化因子。如果 f ( X i = 1 ) < f ( X i = 0 ) f(X_i=1)<f(X_i=0) f(Xi=1)<f(Xi=0),那么输出 X i X_i Xi为0,否则输出1。
-
✋假定Tanner图是一棵树,对于任意 X i X_i Xi,为了方便称为A,我们把它当成根节点。通过消息传播的方法, P ( A ) P(A) P(A)可用如下方法求得:
-
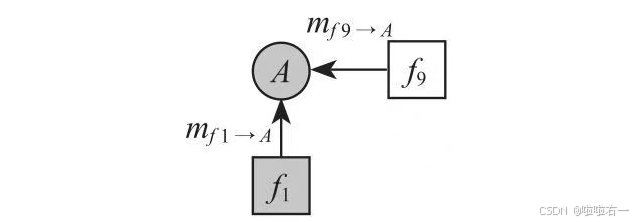
①从各个叶子节点往根节点传播消息。5个m都是从信道得来的,比如 m f 9 → A = f 9 ( A ) = P ( A ∣ Y A = y A ) m_{f_9→A}=f_9(A)=P(A|Y_A=y_A) mf9→A=f9(A)=P(A∣YA=yA)。
-
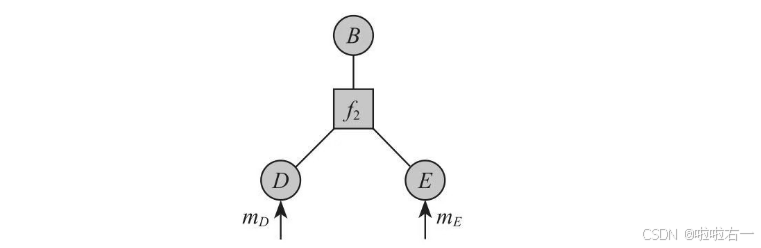
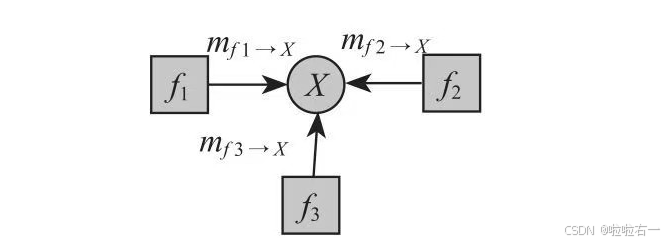
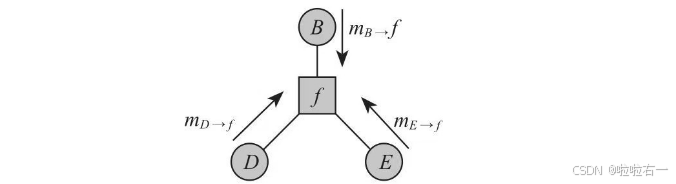
②消息传播到B节点后,由B节点继续向根节点方向传播,进入下一个约束方程的范围。穿过约束方程后,原来的消息被汇聚成新的消息,如果有两个约束方程连到同一个B节点,则消息相乘后继续传播。如下图: m B = ∑ D , E f 2 ( B , D , E ) m D m E m_B=∑_{D,E}f_2(B,D,E)m_Dm_E mB=∑D,Ef2(B,D,E)mDmE。
-
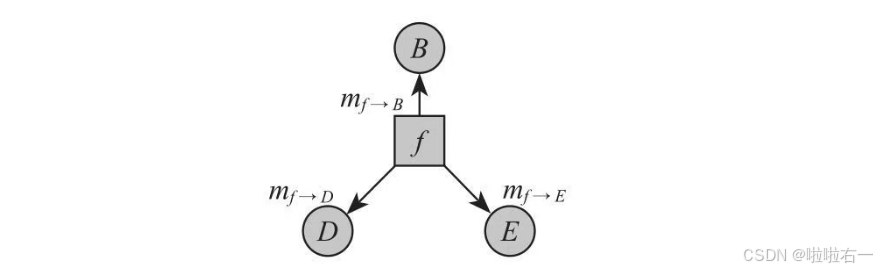
③继续传播,直到所有的消息最终传到A。 P ( A ) = m f 9 → A m f 1 → A P(A)=m_{f9→A}m_{f_1→A} P(A)=mf9→Amf1→A这样就求得了P(A),同理其他所有的边缘分布都可以求出来。
-
-
观察发现,消息传播的算法其实可以并行化,只需要更改一下算法。
-
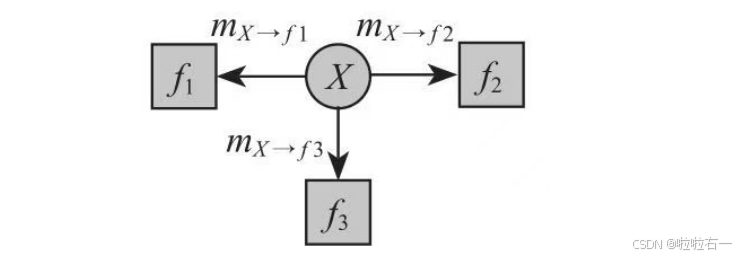
为了同时求出所有边缘分布,每个B节点对消息进行路由。把每个约束方程的方向当成根节点,把不是这个方向传来的所有消息相乘之后送出去。收到消息时如下图所示。
-
X节点发送消息,如下图所示。
-
要实现并行,还要满足如下条件:
-
同理每个c节点(用约束方程f来表示c节点)也要针对不同的可能路径进行计算。
-
c节点往各个b节点发送的消息为:
-
最终,经过多次迭代(深度最大为因子图中最大深度树的2倍),得到所有节点的边缘概率P。算法结束。
-

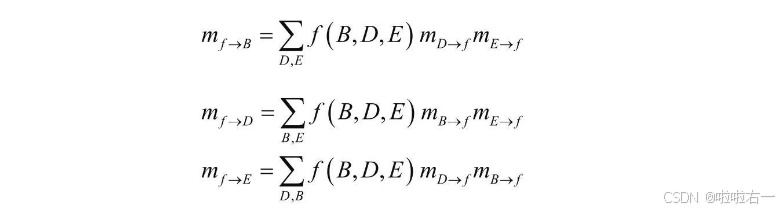
值得讨论的是,前边的算法假定Tanner图是无环的,每一个节点都可以拉出一棵树来。在现实中,这个假定是不成立的,但是该算法也有不错的表现,不过环对纠错的成功与否有着很大的影响。
📚LDPC编码
- LDPC是一种以解码为特点的编码,由于LDPC的性质主要由H矩阵决定,一般要先确定H矩阵后,再反推生成矩阵G。
- H矩阵构建的时候,应当注意:
-
(1)保持稀疏。每行每列里1的个数要固定,或者接近固定。
-
(2)考虑生成矩阵的计算复杂度。
-
(3)保持随机性。减少H矩阵里小环的个数。
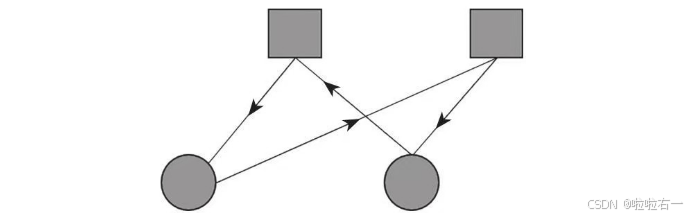
- 上图展示了一个长为4的小环(b节点、c节点和连线组成的环)。显然这两个b节点共同参与了两个相同的校验方程。我们称之为双胞胎。对Bit-flipping而言,假如它们之间有一个错误,我们将无法对错误进行定位。对和积算法而言,环越长,BP算法效果越好。
-
📚LDPC纠错码编解码器在SSD中的应用
- 随着NAND闪存技术的快速发展,一个NAND闪存单元可以存储的信息位数越来越多,为了进一步提高闪存存储密度,NAND闪存制造工艺也从2D平面技术全面切换到3D立体堆叠技术。
- 存储密度的提高极大地降低了闪存单位成本,同时也带来了更多的性能缺陷:闪存单元的错误概率增加,可擦写次数也逐渐降低。这就给SSD主控的ECC编解码单元设计带来了极大的挑战。
- SSD主控的纠错码由最初采用的BCH码,逐步进化到2K LDPC。然而对TLC和QLC来说,2K LDPC的纠错能力也已无法满足企业级SSD对数据可靠性的要求,因此4K LDPC成为主流选择。
- 🔥在未来,随着NAND闪存存储密度进一步增加,期待出现一种全新的X-ECC技术来提供更强大的纠错能力。这里X代表着一种智能、多维的混合解码算法技术。
- 在SSD主控芯片中实现高性能LDPC纠错码技术需要综合考虑以下几个方面:纠错能力、面积、功耗以及吞吐量。
-
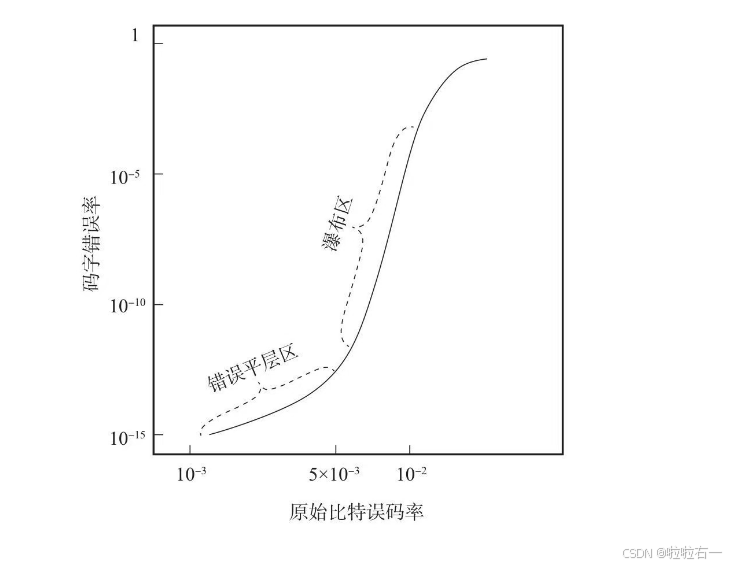
首先,在纠错能力方面,为了保证SSD的数据可靠性,避免盘内数据丢失和损坏,SSD中不可修复的错误比特率(UBER)和平均故障间隔时间(MTBF)都需要满足极高的要求。LDPC纠错码还需关注错误平层(Error Floor)的出现。
- 简单来说,随着信噪比的提升,误码率曲线先经过瀑布区后下降速率突然放缓,很难继续快速下降,这时候就到达错误平层。为了保证满足当下数据可靠性的需求,LDPC解码器的错误平层需要码字错误率(CFR)保持在10-11以下。
- 通常降低错误平层的方法可以分为两大类,一类是在构建LDPC校验矩阵时减少陷阱集或者停止集的产生,另一类是在解码算法中对错误平层采用特殊的处理方法。在SSD控制器中,这两种方法通常是结合使用的。
-
随着主机接口和闪存接口的速率不断提高,对SSD数据处理速率的要求也越来越高。
- 为了支撑SSD高速的数据读写访问,SSD主控中的纠错编解码模块需要提供对应甚至更高的数据吞吐率。
- 为了在满足数据吞吐率要求的同时让设计更具可扩展性,通常在主控中会使用多个ECC核来并行处理数据,然而如英韧科技的PCIe 4.0主控多核技术的应用会带来额外的系统同步控制复杂度。因此,🔥掌握多核高效协同技术是保证主控技术快速迭代并适配更高速应用场景的关键之一。
-
随着SSD工作温度的升高,整体性能会下降。如果SSD控制器能耗太大,散热不佳,热量积累会导致系统温度超过SSD的正常工作温度,进而引发各种问题。
- 🔥SSD控制器的能耗控制(包括LDPC编解码模块)也是设计过程中值得关注的一个方面。
- LDPC作为一种递归迭代算法,在设计中可以考虑🔥优化迭代收敛算法,即用更少的迭代次数完成解码。在这类思路的指引下,控制器就能在满足性能需求的前提下减少功耗。
-
从面积角度来看,基于对ECC解码算法的优化,进行控制器设计时需要仔细分析内部处理的字段、字长,按需设计位宽,以求在满足性能要求的前提下节省芯片面积。
-
- 综上所述,设计出一个高速(数据处理速率)、高效(高纠错能力,低错误平层)、低能耗、低复杂度的4K LDPC纠错码编解码器至关重要,这是主控芯片中决定数据可靠性、完整性及SSD使用寿命的关键技术。
- ⭐️开发一个好的纠错引擎需要关注的地方:
- 纠错码核心技术完全自主可控。这集中体现在性能优异的LDPC校验矩阵和解码算法上。
- 和国际NAND原厂开展QLC方面的研发合作,并将4KLDPC纠错能力可以完全覆盖QLC NAND。
- 节省芯片面积,节省功耗。优化工作主要包括如下两方面:
- 针对对不同的功耗、复杂度和吞吐率等的需求,研发多种不同性能的LDPC解码专利算法。
- 在电路设计方面,采用在某些电路不工作时降低或者关闭时钟频率的方法来降低功耗。
- 降低延时。
- 当LDPC硬判决解码失败后,可以采用重读机制调整读电压从NAND中再获取一次硬判决信息,从而提高硬判决的解码成功率。
- 当所有重读都被尝试并且失败后,软读取以及软解码会被采用。
- 兼容性强,可以通过软件程序动态配置,能够灵活适配各种闪存颗粒。
- 延长SSD使用寿命。在闪存生命周期内的不同阶段,选用不同的LDPC编码。
- 面向未来。设计现有的SSD控制器中的LDPC纠错码编解码模块时,要考虑未来升级的接口协议。
- 参考书籍:《深入浅出SSD:固态存储核心技术、原理与实战》(第2版)