指针是C语言中精妙的齿轮。
一、地址与指针
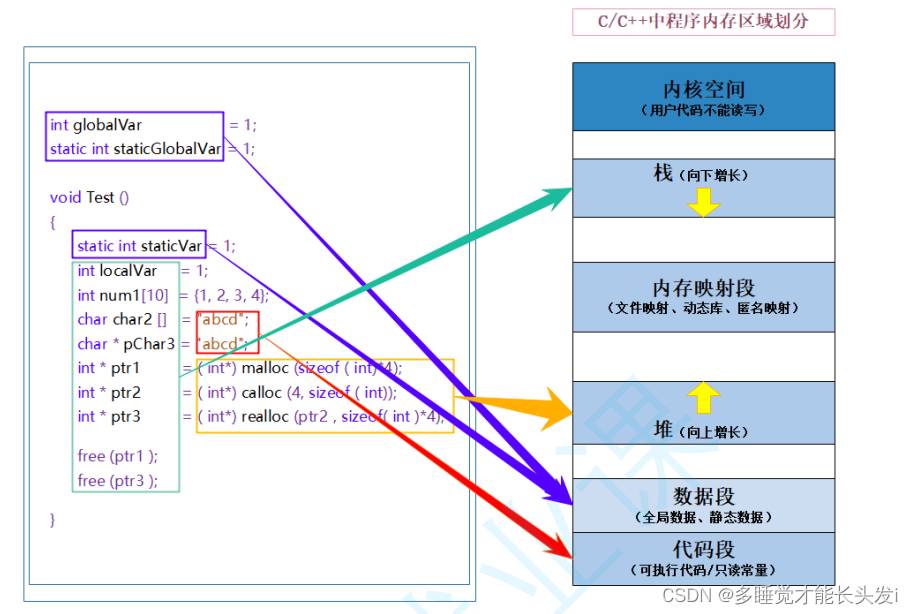
(一)程序内存
1、对象与地址
内存中的一个个存储单元(字节)都有自己的位置编号——内存地址,如同地球上的每一片土地都有自己的经纬度。
在C程序中,每一个操作对象(object)也有自己的位置编号。
C程序创建、销毁、访问和操作对象。
C中的对象是执行环境中数据存储的区域,其内容可以表示值(值是当对象解释为特定类型时,对象内容的含义)。
每个对象都具有以下属性:
- 大小(可以用sizeof确定)
- 对齐要求(可由_Alignof确定)(C11起)
- 存储持续时间(自动、静态、分配、线程本地)
- 生命周期(等于存储持续时间或临时)
- 有效类型
- 值(可能不确定)
- 可选地,表示此对象的标识符。
对象由声明、分配函数、字符串文字、复合文字以及返回结构或与数组成员联合的非左值表达式创建。
在寻常意义上,一般称此为变量,变量名(标识符)起到映射内存地址的作用,编译器通常使用符号表(symbol table)(或符号字典)来管理和查找有关程序中使用的变量、函数和其他符号的信息。
1.符号表:
符号表是一种数据结构,用于存储有关程序中使用的每个符号(如变量、函数、类型)的信息。此信息包括:
- 符号名称
- 符号的类型(例如,整数、浮点数、指针、函数)
- 存储符号的内存位置(地址)
- 范围(符号可见且可访问的地方)
- 其他相关属性,具体取决于语言和编译器。
2.编译过程:
- 词法分析:在词法分析阶段(或扫描阶段),编译器识别源代码中的所有符号,例如变量名、函数名和关键字。
- 符号表填充:当编译器扫描代码时,它用遇到的每个符号的条目填充符号表。这包括为变量分配内存地址、注册函数名称及其入口点以及记录类型信息。
- 语义分析:在语义分析和中间代码生成等后续阶段,编译器使用符号表执行检查(例如类型检查)并将源代码转换为较低级别的表示。
3.内存地址解析:
当编译器遇到变量引用(标识符)时,它会在符号表中查找相应的条目以确定其内存地址,然后使用此地址生成机器代码指令,在运行时访问或操作变量的值。
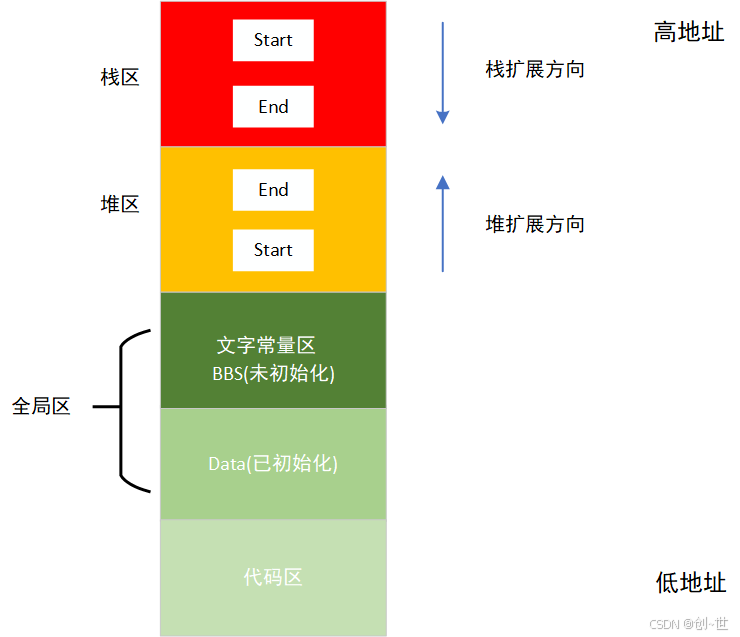
2、内存五区
在程序中定义的这些对象往往具有不同的存储期,由于其存储期的不同,它们被划分进程序内存的不同区域。程序内存,以C为例,通常分为五个区域。
不同的人有不同的版本,但是基本上都是这几个区域
- 代码区(Code Segment/Text Segment):
- 存储CPU执行的机器指令。
- 通常是只读和共享的(在多进程环境下),以防止程序意外修改自己的代码。
- 全局区(Global Segment):
- 存放全局变量和静态变量(包括静态局部变量和全局静态变量)。
- 初始化的全局变量和静态变量放在全局数据区,未初始化的全局变量和静态变量放在BSS段(Block Started by Symbol Segment)。BSS段在程序开始时被初始化为零或空指针。
- 全局区的数据在程序的整个运行期间都存在。
- 栈区(Stack Segment):
- 用于存储局部变量、函数参数和返回地址等信息。
- 栈是一种后进先出(LIFO)的数据结构,每当函数被调用时,栈就会增加一块内存用于存储局部变量等信息;函数执行完毕后,相应的栈内存就会被释放。
- 栈的大小是有限制的,如果栈的使用超过了它的限制,就会发生栈溢出(Stack Overflow)。
- 堆区(Heap Segment):
- 用于动态内存分配,如通过
malloc、calloc、realloc等函数分配的内存。 - 堆区的大小不固定,程序员可以根据需要动态地申请和释放内存。
- 堆区的内存分配和释放需要程序员手动管理,如果管理不当(如忘记释放内存),就可能导致内存泄漏。
- 用于动态内存分配,如通过
- 常量区:
- 用于存储常量字符串和其他常量数据。
- 常量区也是只读的,以防止程序意外修改常量数据。


3、地址的访问形式
直接访问(直接寻址)
对一个变量的直接访问就是可以直接到达变量的内存地址,并对变量进行值等方面的改变。前面我们涉及到的大部分变量是此类。
间接访问(间接寻址)
间接访问就是通过一个变量去访问另一个变量,与普通变量不同的是,这个间接的变量的值是另一个变量的内存地址,这次本次要探讨的目标。

(二)指针变量
指针变量是一个变量,与其他变量的区别仅仅是,其它变量的内容是值,而指针的内容是一个内存地址。
指针指的是内存地址,指针变量的值是某一个内存地址。在通常情况下指针往往说的是指针变量。
1、定义与声明
一般性的指针变量定义语法如下:
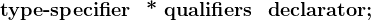
其中,
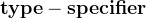
在 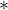
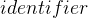
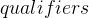
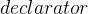
对于声明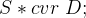
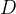
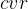
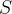
示例
float *p; // p是一个非常量指针, 指向->float类型
float **pp; // p是一个非常量指针,指向->指向float类型的指针类型
int n;
const int * pc = &n; // pc是一个非常量指针,指向->const int类型
int * const cp = &n; // cp是一个常量指针,指向->int类型
const int * const cc = &n; // cc是一个常量指针,指向->const int类型
int * const * pcp = &cp; // pcp是一个非常量指针,指向->指向int类型的常量指针 指针类型判断小技巧:从右往左看,从右开始的第一个
由于无论指针的指向类型如何,其值始终应该被解释为一个内存地址,也即仅仅和系统能够表示的地址大小有关,所以在现代计算机系统中,最常见的指针大小是4字节(32位系统)或8字节(64位系统),但是具体指针的大小依赖于编译器与具体实现,如笔者的操作系统为64位,但是指针大小显示为4位。

2、指针解引用与取地址符
指针解引用(Dereference,*)与取地址符(Address of,&)是一对互反操作运算符,也就是说,一般情况下,两者结合将互相取消对方的操作,也即空操作(neither one is evaluated)。
下面说明各自的语法
(1)取地址符
取地址符,在前面的
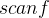
| 语法形式 | 说明 |
|---|---|
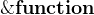 | 取一个函数的地址 |
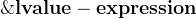 | 取一个对象的地址 |
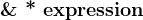 | 特例,无操作 |
![\textbf{ \& expression[ expression ] }](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUN0ZXh0YmYlN0IlMjAlNUMlMjYlMjBleHByZXNzaW9uJTVCJTIwZXhwcmVzc2lvbiUyMCU1RCUyMCU3RA%3D%3D) | 除了数组到指针的转换和加法之外,不采取任何操作 |
下面说明第二种,第一和第四后面展开。
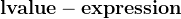
示例
int a = 10;
char b = 'a';
double c = 3.14;
int * ap = &a;
char * bp = &b;
double * cp = &c;
printf("a = %d, b = %c, c = %f\n", a, b, c);
printf("ap = %p, bp = %p, cp = %p\n", ap, bp, cp);
printf("a的地址 %p, b的地址 %p , c的地址 %p\n", &a, &b, &c);

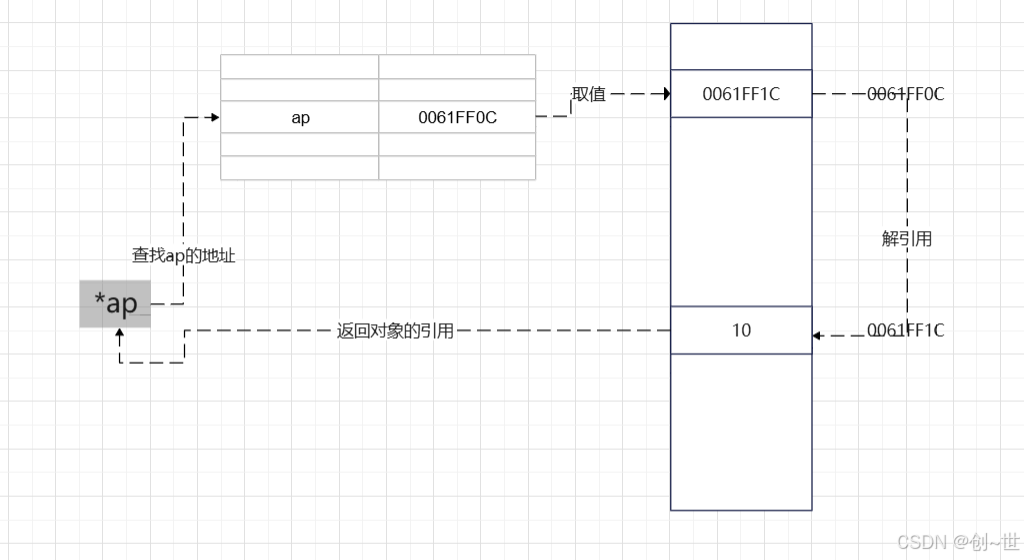
(2)解引用
解引用运算符,在指针定义时作为一个声明式的作用,这点和数组下标运算符很像,事实上在后面可以看到它们的关系很密切。
| 语法 | 说明 |
|---|---|
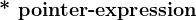 | 如果指针表达式是指向函数的指针,则结果是该函数的函数指示符。 如果指针表达式是指向对象的指针,则结果是指定对象的左值表达式。 |
对于第一种,后面展开,而对于第二种,解引用即在某种程度上是一次间接寻址的过程:
int a = 10;
char b = 'a';
double c = 3.14;
int * ap = &a;
char * bp = &b;
double * cp = &c;
printf("a = %d, b = %c, c = %f\n", a, b, c);
printf("a的值:%d, b的值:%c, c的值:%f\n", *ap, *bp, *cp);

以
(三)指向与限制
一个有具体指向的指针是好的,它能够为我们提供访问对象的选择,不知道指针指向何处则具有潜在风险,无法确定击落点的导弹,威力大,反而有害。同时指针不应该总是具有改变的能力,允许访问对象不意味着就可以修改对象,指针需要限制。
1、初始化与赋值问题
不使用未初始化或未赋值的变量,这点对于指针尤其重要。相比使用于未赋值的普通变量,使用未赋初值(初始化)的指针变量(野指针)要危险的多。
int * ap;
printf("ap的地址:%p, ap的值:%p\n", &ap, ap);

2、悬空指针
在某些时候,我们想要提前声明指针,但是尚且不能、不想为其指定具体的指向。这时候需要将指针悬空。即赋空值,不指向任何单元
对于一个指针变量p,可以有
p = NULL; // 常量NULL,通常被定义为0
p = 0; // 数字0
p = '\0'; // ASCII 值为0的字符3、const与指针
在定义指针时,可以使用const关键字修饰指针,在前面,我们知道const修饰的变量是read-only的,这点在指针上有异曲同工之处。
以下为三种可能的修饰
1)常量指针:
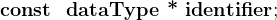
根据分解规则,我们可以知道指针指向的类型为常量,所以这时候通过指针当然不能修改常量——不能通过指针修改所指向的内容。不过,这并不意味着赋值的数据类型只能是常量。
通常这种指针用来当作函数参数,避免被调函数内部修改所指向内容的值;
int x = 5;
int y = 6;
const int * ptr = &x;
*ptr = 10; // 错误,不能通过常量指针修改所指内容
x = 10; // 正确
ptr = &y; // 正确,因为ptr本身就是变量2)常量指针变量:
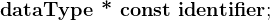
根据分解规则,const修饰指针本身,即指针本身是常量,不可更换指向,指针所指向的内存不允许改变,所以必须要初始化;
int x = 5;
int y = 6;
int * const ptr = &x;
*ptr = 10; // 正确,可以通过指针修改所指内容
x = 10; // 正确
ptr = &y; // 错误,因为ptr本身是常量3)指针常量:
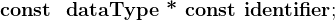
指针兼有上面两种指针的特点,即既是常量指针,又是常量指针变量;
int x = 5;
int y = 6;
const int * const ptr = &x;
*ptr = 10; // 错误,不能通过常量指针修改所指内容
x = 10; // 正确
ptr = &y; // 错误,因为ptr本身是常量4、void与指针
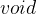
指向任何类型对象的指针都可以隐式转换为指向void的指针,反之亦然:
int n=1,*p=&n;
void * pv=p;//int*到void*
int* p2=pv;//void*到int*
printf("%d\n",*p2);//打印1指向void的指针用于传递未知类型的对象,这在通用接口中很常见
(四)指针运算
1、地址运算
指针变量也是变量,和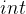
| 运算符 | 说明 |
|---|---|
| = | 赋值操作,不允许赋值原始值,应该通过左值表达式 |
| +、- | 加或减去某个整数,不允许两个指针变量相加,允许相减 |
| ++、-- | 自增与自减 |
| >、<、==、!= | >、<表示两个指针的前后顺序,==、!=表示两个指针是否指向同一处 |
注意:地址运算的基本单位是指针所指向类型的大小,比如当指针指向int类型时,+1意味着地址值+4
#include<stdio.h>
int main(int argc, char const *argv[])
{
int integer = 1;
//int * ap = 2; // 错误
int * bp = &integer; // 正确
int * cp = bp; // 正确
int diff = bp - cp; // 正确
//int sum = bp + cp; // 错误
int equal = bp == cp; // 正确
printf("diff: %d\n", diff);
printf("equal: %d\n", equal);
printf("before plus address: %p\n", bp);
printf("after plus address: %p\n", ++bp);
return 0;
}

2、指针的值与域
C的指针的值是一个地址,准确来说是指向的对象的首地址,它只能标识一个字节位置,但是指针却可以通过类型标识对象的完整位置(即所占所有空间字节的位置),我称之为域。
指针的每次移动操作都是以指定的指向类型的大小字节数移动,就像一个齿轮一样

3、大端与小端存储
对于一个简单的程序如下

你会发现先定义的变量内存地址是更高的,这可能有些迷惑,就比如笔者当时就以为,变量的地址不应该是随着变量的增加而地址变大吗?就比如从编号1到99。不过,在计算机内存中,情况不是我想的那样,如果读者还记得这两个变量,是在内存的哪个空间存储就会明白,变量从上往下放置就是会这样。而这种存储方式也涉及到所谓的大小端存储模式。
大端存储(Big-endian)和小端存储(Little-endian)是计算机科学中数据在内存中存储的两种不同方式。
大端存储(Big-endian):
- 在大端存储模式下,数据的高字节(或称作高位、最重要字节)被存储在内存的低地址处,而数据的低字节(或称作低位、最不重要字节)存储在高地址处。
- 这种方式的一个好处是它直接对应于人类通常书写数值的方式,例如十六进制数0x1234,在大端模式下,内存中的布局就是0x12在前(低地址),0x34在后(高地址)。
小端存储(Little-endian):
- 在小端存储模式下,数据的低字节存储在内存的低地址处,而高字节存储在高地址处。
- 这种方式与人们直观阅读数字的习惯相反,但对于某些特定的计算机体系结构,其内存访问效率更高,因为很多现代处理器都是以字节为单位获取数据,且经常处理的是最低有效字节。
4、程序内存大探险
在前面,我们了解到程序的内存划分,相同存储期的对象都是放在一块区域,并且可能是顺序存放,也就是说它们的地址是挨着的,这意味着如果我得到指向其中一个对象的指针,那么就有可能仅仅使用这一个指针得到其它的对象。如对于以下的程序,可以辅助说明指针的用法与程序内存的一角。
以下程序模拟‘me’如何通过指针得到看似没有关系的‘ticks’,有兴趣的读者可以深入试试,不过操作需谨慎。
#include<stdio.h>
int main(int argc, char* argv[])
{
int tickts[] = {43, 2, 23, 17, 6, 434, 82, 93, 30, 11}; // 对应房间里面的票
printf("open the door\n");
int room[] = {1, 5, 3, 34, 3, 6, 9, 8, 19, 10}; // 各个房间对应的钥匙
printf("A array of rooms\n");
int key = 9;
int me;
printf("I'm at %p, the key is at %p\n", &me, &key);
printf("the room the range from %p to %p\n", &room[0], &room[9]);
printf("the tickets range from %p to %p\n", &tickts[0], &tickts[9]);
} 简单测试一下,可以知道这些变量就是紧靠着的:

好,现在,看如何移动,拿到ticks:


注:本程序操作在实操过程中,出现了一些“幽灵现象”,诸如指针操作++,
二、指针与数组
通过之前的指针操作,可以发现,指针和数组的操作很类似,比如:
![array\left [ n \right ] \Rightarrow get \ the \ nth \ elements \ of \ array](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9hcnJheSU1Q2xlZnQlMjAlNUIlMjBuJTIwJTVDcmlnaHQlMjAlNUQlMjAlNUNSaWdodGFycm93JTIwZ2V0JTIwJTVDJTIwdGhlJTIwJTVDJTIwbnRoJTIwJTVDJTIwZWxlbWVudHMlMjAlNUMlMjBvZiUyMCU1QyUyMGFycmF5)
如果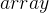
(一)数组指针
这里的数组指针是
int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* array_ptr = array; 当此赋值发生时,将进行名为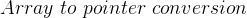
![int* array\_ptr = array; \Rightarrow int * array\_ptr = \&array[0];](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9pbnQ%3D*%20array%5C_ptr%20%3D%20array%3B%20%5CRightarrow%20int%20*%20array%5C_ptr%20%3D%20%5C%26array%5B0%5D%3B)
转换为数组第一个元素的非左值指针。对于字符串常量也是如此,字符串会首先转换为字符数组。
下面做一个验证
int array[] = { 5, 3, 1, 2, 4 };
int * pti = array;
char string[] = "Hello World";
char* str = string;
printf("The head address of array: %p - %p - %p\n", pti , &array[0], array);
printf("The head addreess of string: %p - %p - %p\n", str, &string[0], string);
注意,我没有使用对数组名使用取地址符,这说明数组名是指针。那么我们应该就可以如下互操作。
printf("The first element of the array is: %d - %d - %d\n", *pti, pti[0], *array);
printf("The third element of the array is: %d - %d - %d\n", *(pti + 2), pti[2], array[2]);
printf("The first character of the string is: %c - %c - %c\n", str[0], *str, *string);
printf("The third character of the string is: %c - %c - %c\n", *(string + 2), 2[str], str[2]);

结果确实如此,那么它们是什么关系呢?我们慢慢讲
(二)下标与解引用
回顾下标的语法:
![\textbf{pointer-expression [ integer-expression ]}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUN0ZXh0YmYlN0Jwb2ludGVyLWV4cHJlc3Npb24lMjAlNUIlMjBpbnRlZ2VyLWV4cHJlc3Npb24lMjAlNUQlN0Q%3D)
![\textbf{integer-expression [ pointer-expression ]}](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUN0ZXh0YmYlN0JpbnRlZ2VyLWV4cHJlc3Npb24lMjAlNUIlMjBwb2ludGVyLWV4cHJlc3Npb24lMjAlNUQlN0Q%3D)
文档是这么说的
If pointer-expression is an array expression, it undergoes lvalue-to-rvalue conversion and becomes a pointer to the first element of the array.
如果指针表达式是一个数组表达式,它会经历左值到右值的转换,并成为指向该数组第一个元素的指针。
也即
(三)数组名与指针
虽然经过上面的分析,我们知道数组名就类似于指针,可以和指针一样操作,但是,也不是可以随意操作,因为数组名所代表的指针是指针常量,所以不能如下操作,数组名是不可更改指向的指针常量。

正因为数组名和指针如此统一,所以C提供有一种特殊的复合字面量(Compound literals)可以创建数组
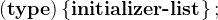
如
![int* pti = (int[\ ])\left \{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 \right \};](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9pbnQ%3D*%20pti%20%3D%20%28int%5B%5C%20%5D%29%5Cleft%20%5C%7B%201%2C%202%2C%203%2C%204%2C%205%2C%206%2C%207%2C%208%2C%209%2C%2010%20%5Cright%20%5C%7D%3B)
这将创建一个无名的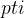
int* pti = (int[]){1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
printf("The size of pti: %d\n", sizeof(pti));
pti++;
printf("The second element of the array: %d\n", pti[1]);
pti[3] = 100;
printf("The fourth element of the array: %d\n", pti[3]);

(四)行指针与列指针
行指针:指向数组行的指针(a pointer that points to an array of pointers),这意味着,指针的域为数组一整行,而不是单独的元素,这通常指向二维数组。
![dataType \ (*identifier)[size];](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9kYXRhVHlwZSUyMCU1QyUyMCUyOCppZGVudGlmaWVyJTI5JTVCc2l6ZSU1RCUzQg%3D%3D)
dataType ( * 指针变量名)[n]; // n代表数组的列数,以便此指针可以按行移动。同样的,使用数组赋值时也将发生隐式转换
int array[][3] = { {1, 2, 3}, {4, 5, 6}, {7, 8, 9} };
int (*pti2)[3] = array;![int \ (*pti2)[3] = array; \Rightarrow int (*pti2)[3] = \&array[0];](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9pbnQ%3D%20%5C%20%28*pti2%29%5B3%5D%20%3D%20array%3B%20%5CRightarrow%20int%20%28*pti2%29%5B3%5D%20%3D%20%5C%26array%5B0%5D%3B)
不过,不是第一个数组元素,一个二维数组的第一个元素是一个一维数组。
列指针,伴随着行指针而来,以下先结合一张图表辅助说明

1、行指针的实质
定义与类型
- 行指针是指向数组(特别是二维数组中的一行)的指针。在C语言中,二维数组可以被看作是一个一维数组的数组,其中每个元素都是一个一维数组(即行)。因此,行指针的实质是指向这种一维数组的指针。
- 例如,对于二维数组
int a[3][4];,a本身可以被视为一个指向包含4个int元素的数组的指针(即行指针)。但是,在表达式中,a的类型会被视为int (*)[4],即指向一个包含4个int的数组的指针。
访问方式
- 要通过行指针访问二维数组中的元素,需要对指针进行两次解引用操作。首先,解引用行指针以获得一行的地址,然后再次解引用以获得该行中特定位置的元素。
- 例如,
*(a + i)会获得第i行的地址(即一个指向包含4个int的数组的指针),而*(*(a + i) + j)则会获得第i行第j列的元素的值。
2、列指针的实质
列指针的实质是指向二维数组中某个特定元素的指针,其类型为指向该元素类型的指针。例如,在int a[3][4];中,列指针的类型将是int *。
访问方式
- 列指针通过简单的解引用操作即可访问其指向的元素。但是,在二维数组的上下文中,通常需要先通过行指针定位到特定的行,然后再通过列偏移量来访问特定的元素。
- 例如,
a[i][j]可以看作是首先通过a + i定位到第i行的地址(即行指针),然后通过*(a + i) + j定位到第j个元素的地址(即列指针),最后通过解引用*(*(a + i) + j)来访问该元素的值。然而,在实际编程中,我们通常会直接使用a[i][j]这种更简洁的语法。
(五)指针数组
所谓指针数组是指数组元素是指针的数组。例如
#include <stdio.h>
int main() {
int a = 10;
int b = 20;
int c = 30;
// 创建一个指针数组,每个元素都是int类型的指针
int *ptrArray[3];
// 初始化指针数组,让每个元素指向不同的整数
ptrArray[0] = &a;
ptrArray[1] = &b;
ptrArray[2] = &c;
// 打印指针数组中每个指针所指向的值
for (int i = 0; i < 3; i++) {
printf("Element %d points to: %d\n", i, *ptrArray[i]);
}
return 0;
}字符串数组
字符串数组是一个数组,其元素是字符串。在C语言中,字符串本质上是一维字符数组,通常以空字符 (`\0`) 结尾。因此,字符串数组实际上是一个指针数组,其中的每个元素都指向一个字符串的起始位置。
#include <stdio.h>
int main() {
// 创建一个字符串数组
char *stringArray[] = {"Hello", "World", "C Programming"};
// 打印字符串数组中的每个字符串
for (int i = 0; i < 3; i++) {
printf("%s\n", stringArray[i]);
}
return 0;
} 在上述字符串数组的例子中,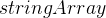
(六)多级指针
C语言中的多级指针,也称为链式指针或指针的指针,是指一个指针变量所存储的不是直接的数据值,而是另一个指针的地址。这种结构允许我们通过一系列的指针间接地访问和操作数据,非常适用于构建复杂的数据结构,如链表、树和图等。
首先,回顾一下一级指针。一级指针是C语言中常见的指针类型,它直接指向一个变量(或数组、结构体等的元素)的地址。
int a = 10;
int *p = &a; // p 是一个指向 int 类型变量的指针1、二级指针(指针的指针)
二级指针,也称为指针的指针,是指向指针的指针。它存储的是一个指针变量的地址,而不是直接的数据地址。
int a = 10;
int *p = &a; // p 是一级指针,指向 int 类型的变量 a
int **pp = &p; // pp 是二级指针,指向 p(一个指针) 在这个例子中,pp 是一个二级指针,它存储了 p 的地址,而 p 存储了 a 的地址。所以,通过 pp,我们可以间接地访问 a 的值。
2、三级及更多级指针
类似地,可以定义三级指针、四级指针等,它们分别是指向二级指针、三级指针等的指针。
int a = 10;
int *p = &a;
int **pp = &p;
int ***ppp = &pp; // ppp 是三级指针,指向 pp(一个二级指针)(七)可变长数组(VLA)
1、什么是VLA
可变长数组(Variable-length arrays),指的是那些大小不固定的数组,即在数组声明定义中
![\textbf{dataType identifier[expression]};](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUN0ZXh0YmYlN0JkYXRhVHlwZSUyMGlkZW50aWZpZXIlNUJleHByZXNzaW9uJTVEJTdEJTNC)
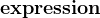
int n = 1;
label:;
int array[n];
printf("The Address of array: %p sizeof array %d\n", array, sizeof(array));
if( n < 10){
n++;
goto label;
}

由于
同时,让我们看看
int n = 2;
label:;
char array[n];
printf("The distance between n and array is %ld\n", (char *)&n - array);
if( n < 10){
n++;
goto label;
}
printf(" n = %p address=%p\n", &n, array);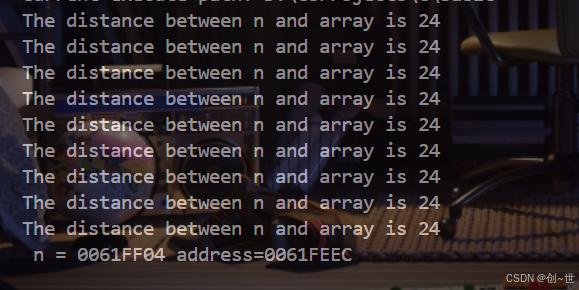
扩大

下面看看什么时候会发生后移:


就目前来看,可以发现当数组的尾巴离前面变量只有8个字节时就会后移首地址16个字节,虽然目前很难说为什么会这样,但是,这避免了数组大小的变换对在数组前面就声明并定义的变量,或者说分配了栈地址(在这里而言)的变量产生覆盖影响。如果是一个定长数组,可以检测,与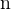
int n = 2;
lebel:;
char array[10];
printf("The distance between n and array is %ld\n", (char *)&n - array);
printf(" n = %p address=%p\n", &n, array);

2、定义与声明问题
如果编译器将宏常量 STDC_NO_VLA 定义为整数常量 1,那么可变长度数组(VLA)和可变修改类型(VM 类型)将不受支持。(自 C11 起)(直到 C23)如果编译器将宏常量 STDC_NO_VLA 定义为整数常量 1,那么具有自动存储持续时间的 VLA 对象将不受支持。对于具有分配存储持续时间的 VM 类型和 VLA 的支持是强制要求的。
可变长度数组及其衍生类型(例如指向它们的指针等)通常被称为“可变修改类型”(VM)。任何可变修改类型的对象只能在块作用域或函数原型作用域中声明。
函数声明形参中的VLA,如下:
![\textbf{void func(int n, int array[n])};](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUN0ZXh0YmYlN0J2b2lkJTIwZnVuYyUyOGludCUyMG4lMkMlMjBpbnQlMjBhcnJheSU1Qm4lNUQlMjklN0QlM0I%3D)
我们可能会这样写,
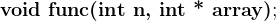
但同时也支持
![\textbf{void func(int n, int array[*])};](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUN0ZXh0YmYlN0J2b2lkJTIwZnVuYyUyOGludCUyMG4lMkMlMjBpbnQlMjBhcnJheSU1QiolNUQlMjklN0QlM0I%3D)
如果大小为“*”,该声明是针对未指定大小的可变长度数组(VLA)。这样的声明可能仅出现在函数原型作用域中,并声明一个完整类型的数组。实际上,在函数原型作用域中的所有 VLA 声明符都被视为表达式被替换为*
可变长度数组(VLA)必须具有自动或分配的存储持续时间。指向可变长度数组的指针可以具有静态存储持续时间,但可变长度数组本身不可以。任何可变修改类型(VM)都不可以具有链接。
#include <stdio.h>
#include <stdlib.h>
void func() {
int n = 5;
int vla[n]; // 可变长度数组,具有自动存储持续时间
static int *ptr_to_vla; // 指向可变长度数组的指针具有静态存储持续时间
// 错误示例:可变长度数组不能具有静态存储持续时间
// static int vla_static[n];
// 错误示例:可变修改类型不能具有链接
// extern int vla_extern[n];
}
int main() {
int size = 10;
int *allocated_vla = (int *)malloc(size * sizeof(int)); // 分配的可变长度数组
// 进行一些操作
free(allocated_vla);
return 0;
}3、未知大小数组
如果数组声明符中的表达式被省略,它将声明一个大小未知的数组。除了在函数参数列表中(在这种情况下,此类数组会被转换为指针)以及有初始化器可用时,这种类型是不完整的类型(请注意,使用 * 作为大小声明的未指定大小的可变长度数组是完整类型)(自 C99 起)
例如:
#include <stdio.h>
// 外部声明一个未知大小的数组
extern int arr1[];
// 结构体中使用未知大小的数组作为灵活数组成员
struct myStruct {
int num;
int arr2[];
};
// 函数参数列表中,未知大小的数组会被转换为指针
void func(int arr3[]) {
printf("Size of pointer in function: %zu\n", sizeof(arr3));
}
int main() {
// 未知大小的数组且有初始化器,此时类型是完整的
int arr4[] = {1, 2, 3};
printf("Size of arr4: %zu\n", sizeof(arr4));
struct myStruct *s = malloc(sizeof(struct myStruct) + sizeof(int) * 5);
int i;
for (i = 0; i < 5; i++) {
s->arr2[i] = i + 1;
}
func(arr4);
return 0;
}三、指针与函数
(一)函数参数与返回
指针作为函数参数允许函数接收和操作内存地址。通过传递指针,函数可以读取或修改指针所指向的数据。这使得函数能够更加灵活地操作数据,并且可以在函数之间共享和传递数据。
1、指针作为参数
例如,以下是一个使用指针作为参数的函数示例:
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
} 在上面的例子中,swap函数接收两个指向整数的指针作为参数。通过传递指针,函数能够交换两个整数的值。
2、指针函数
指针函数是指返回指针类型的函数。指针函数通常用于返回数组、结构或其他数据类型的地址。
例如,以下是一个返回整数数组指针的指针函数的示例:
int * get_array() {
static int values[] = {1, 2, 3, 4, 5};
return values;
} 在上面的例子中,get_array函数返回一个指向整数数组的指针。由于使用了static关键字,该数组在函数调用之间保持其值。
(二)函数指针
函数指针是指向函数的指针变量。为什么指针可以指向函数,这就要提到函数的定义了:
A function is a C language construct that associates a compound statement (the function body) with an identifier (the function name).
函数是一种C语言构造,它将复合语句(函数体)与标识符(函数名称)相关联。
这句话说得就很干脆, 函数包括一系列的指令,当它经过编译后,在内存中会占据一块内存空间,该空间有一个首地址,指针变量可以存储这个地址。
一个函数指针的一般性定义如下:
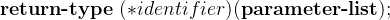
如
int (*fp)(int); // fp 是一个指向 返回类型为int,参数列表为(int)赋值也很简单
void f(int);
void (*pf1)(int) = &f;
void (*pf2)(int) = f; // 和 &f 一样,因为会自动转换为上一种A pointer to function can be initialized with an address of a function. Because of the function-to-pointer conversion, the address-of operator is optional:
指向函数的指针可以用函数的地址初始化。由于函数到指针的隐式转换,取地址运算符是可选的
通过使用函数指针,可以间接调用函数,并可以在运行时动态地选择要调用的函数。
例如,以下是一个使用函数指针的示例:
#include <stdio.h>
void say_hello() {
printf("Hello!\n");
}
int main() {
void (*func)() = say_hello; // 定义函数指针类型
func(); // 通过函数指针调用函数
return 0;
} 在上面的例子中,我们定义了一个名为func的函数指针,并将其指向say_hello函数。然后,通过使用func()的形式调用该函数,实际上是通过函数指针间接调用了say_hello函数。
(三)函数指针数组
与函数不同,指向函数的指针是对象,因此可以存储在数组中、复制、分配、作为参数传递给其他函数等。
一个函数指针数组的一般性定义如下,同样的size可以省略(如果有初始化的话);
![\textbf{return-type} \ (*identifier[size])(\textbf{parameter-list})](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT8lNUN0ZXh0YmYlN0JyZXR1cm4tdHlwZSU3RCUyMCU1QyUyMCUyOCppZGVudGlmaWVyJTVCc2l6ZSU1RCUyOSUyOCU1Q3RleHRiZiU3QnBhcmFtZXRlci1saXN0JTdEJTI5)
{kind=link}
#include <stdio.h>
// 声明几个函数,它们都具有相同的签名
void functionA() { printf("Function A\n"); }
void functionB() { printf("Function B\n"); }
void functionC() { printf("Function C\n"); }
int main() {
// 定义一个函数指针数组,每个元素都是指向无参数且返回void类型的函数的指针
void (*functionPointers[3])() = {functionA, functionB, functionC};
// 调用数组中的不同函数
for (int i = 0; i < 3; ++i) {
functionPointers[i](); // 注意这里使用了()来调用函数
}
return 0;
}
(四)函数调用栈
函数调用栈(Call Stack),也称为运行时栈(Runtime Stack),是在程序执行期间由操作系统或运行时环境维护的一个重要数据结构。它用于跟踪函数调用的历史,管理局部变量和函数参数,并保存返回地址,从而使得函数调用能够正确地进行和返回。
1、主要功能
1. 函数调用记录:每当一个函数被调用时,一个新的栈帧(Stack Frame)会被创建并压入栈顶,这个栈帧包含了函数的局部变量、函数参数、返回地址以及可能的其他信息(如函数状态寄存器)。
2. 局部变量和参数存储:函数的局部变量和传入的参数被存储在对应的栈帧中,这使得每个函数调用都有自己的独立空间,避免了变量之间的冲突。
3. 返回地址保存:调用一个函数时,返回地址(即调用者函数中紧跟在函数调用指令后的下一条指令的地址)会被保存在栈帧中。当被调用的函数执行完毕后,控制流会回到这个返回地址继续执行。
4. 函数返回:当一个函数执行完毕时,它的栈帧从栈中弹出(Popped),控制权返回到上一个函数(即调用者函数)继续执行。这个过程一直持续直到程序结束或到达主函数的退出点。
2、工作原理
当一个函数被调用时,以下步骤会发生:
1. 压入新的栈帧:为即将执行的函数创建一个新的栈帧,其中包括:
- 局部变量的空间
- 函数参数
- 返回地址
- 可能还有其他上下文信息,如保存的寄存器值。
2. 执行函数体:函数开始执行,使用栈帧中的局部变量和参数。
3. 函数返回:函数执行完毕后,清理栈帧中的数据,恢复之前的上下文,并跳转到保存的返回地址继续执行。
3、栈溢出
由于函数调用栈是有限大小的,如果递归调用太深或局部变量占用的空间太大,可能会导致栈溢出(Stack Overflow),这是一种常见的运行时错误。当栈空间耗尽时,新压入的栈帧会覆盖已存在的数据,导致程序崩溃或不稳定行为。
假设有一个简单的递归函数用于计算阶乘:
unsigned long long factorial(unsigned int n) {
if (n == 0)
return 1;
else
return n * factorial(n - 1);
} 每次调用 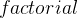
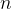
(五)参数可变函数
在之前的一些编程中,我们见过,也用过一类特殊的函数,它们的形参中有一个特殊的省略号,在之前的仿函数宏,我们知道这意味着若干个函数实参的占位符。对于这一类的函数,称之为变参函数(Variadic function)
Variadic functions are functions that may be called with different number of arguments.
变参函数是可以使用不同数量的参数调用的函数。
(一)快速使用
要使用可变参数功能,需要包含stdarg.h头文件,该文件提供了实现可变参数功能的函数和宏,常用的宏包括:
va_start(ap, last_arg):用于初始化可变参数列表。ap是一个va_list类型的变量,last_arg是最后一个固定参数的名称(也就是可变参数列表之前的参数)。该宏将ap指向可变参数列表中的第一个参数。va_arg(ap, type):获取可变参数列表中的下一个参数。ap是一个va_list类型的变量,type是下一个参数的类型。该宏返回类型为type的值,并将ap指向下一个参数。va_end(ap):结束可变参数列表的访问。ap是一个va_list类型的变量。该宏将ap置为NULL。-
va_copy (va_list dest, va_list src ):(C99 标准)制作可变参数函数参数的副本(函数宏)。
-
va_list :保存 va_start 、va_arg 、va_end 和 va_copy 所需的信息(类型定义)。
以下是一个计算平均值的可变参数函数示例代码:
#include <stdio.h>
#include <stdarg.h>
double average(int num,...)
{
va_list valist;
double sum = 0.0;
int i;
// 为 num 个参数初始化 valist
va_start(valist, num);
// 访问所有赋给 valist 的参数
for (i = 0; i < num; i++)
{
sum += va_arg(valist, int);
}
// 清理为 valist 保留的内存
va_end(valist);
return sum / num;
}
int main()
{
printf("average of 2, 3, 4, 5 = %f\n", average(4, 2, 3, 4, 5));
printf("average of 5, 10, 15 = %f\n", average(3, 5, 10, 15));
} 在上述代码中,average函数接受一个整数num和任意数量的整数参数。函数内部使用va_list类型的变量va_list来访问可变参数列表。在循环中,每次使用va_arg宏获取下一个整数参数,并累加到sum中。最后,在函数结束时使用va_end宏结束可变参数列表的访问。
(二)原理
变参函数实现的原理,其实通过上面的例子也略知一二:
-
栈的使用
当函数被调用时,参数会按照从右到左的顺序被压入栈中。对于变参函数,固定参数按照正常方式压栈,而可变参数则依次紧跟在固定参数之后。 -
va_list类型和相关宏stdarg.h头文件中定义了va_list类型用于表示参数列表。va_start宏用于初始化va_list变量,使其指向第一个可变参数。它通过获取最后一个固定参数的地址,并根据这个地址和机器的架构(参数在栈中的存储方式)来确定可变参数的起始位置。va_arg宏用于从参数列表中获取下一个参数。它根据当前的位置和指定的参数类型,从栈中取出相应大小的数据,并将位置指针向前移动。va_end宏用于清理va_list相关的资源。
一般而言,那些可变参数都是统一的数据类型方便获取,如果使用指针,则一个可能的实现如下:
#include <stdio.h>
#include <stdarg.h>
// 计算可变参数的和
int sum(int count,...) {
va_list args;
va_start(args, count);
int total = 0;
int *ptr = &count + 1; // 跳过固定参数 count
for (int i = 0; i < count; i++) {
total += *ptr++; // 通过指针获取参数值并累加
}
va_end(args);
return total;
}
int main() {
int result = sum(3, 10, 20, 30);
printf("Sum: %d\n", result);
return 0;
}致读者:
关于指针,本文可能只是触及到其表面,毕竟关于此方面都有人出一本书。但是无论如何,指针都不是高深莫测的一样东西,它只是足够灵活,正如整个系统中精细的齿轮,转动庞大的功能体系......