
活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。
学习日记
目录
一、BeautifulSoup4概述
BeautifulSoup是python解析html非常好用的第三方库
1、BeautifulSoup4概念总结
BeautifulSoup库也称bs4库,是Python用于网页分析的第三方库,用来快速转换被抓取的网页。
BeautifulSoup可以把网页转换为一颗DOM树。
BeautifulSoup提供一些简单的方法以及类Python语法来查找、定位、修改一棵转换后的DOM树,还能自动将送进来的文档转换为Unicode编码。
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库。
它通过转换器实现文档导航,查找,修改文档的方式。
2、BeautifulSoup4使用对象
BeautifulSoup将HTML文档转换成一个树形结构,每个结点都是对象,可以归纳为4种类型:Tag、NavigableString、BeautifulSoup、Comment
Tag,HTML中的一个标签。
NavigableString,用于操纵标签内部的文字,标签的string属性返回NavigableString对象
BeautifulSoup,表示的是一个文档的全部内容,大部分时候可以把它看作是一个特殊的Tag。
Comment,一个特殊类型的NavigableSting对象,它的内容不包括注释符号。
3、安装和导入
win+r+cmd
pip install beautifulsoup4
form bs4 import BeautifulSoup
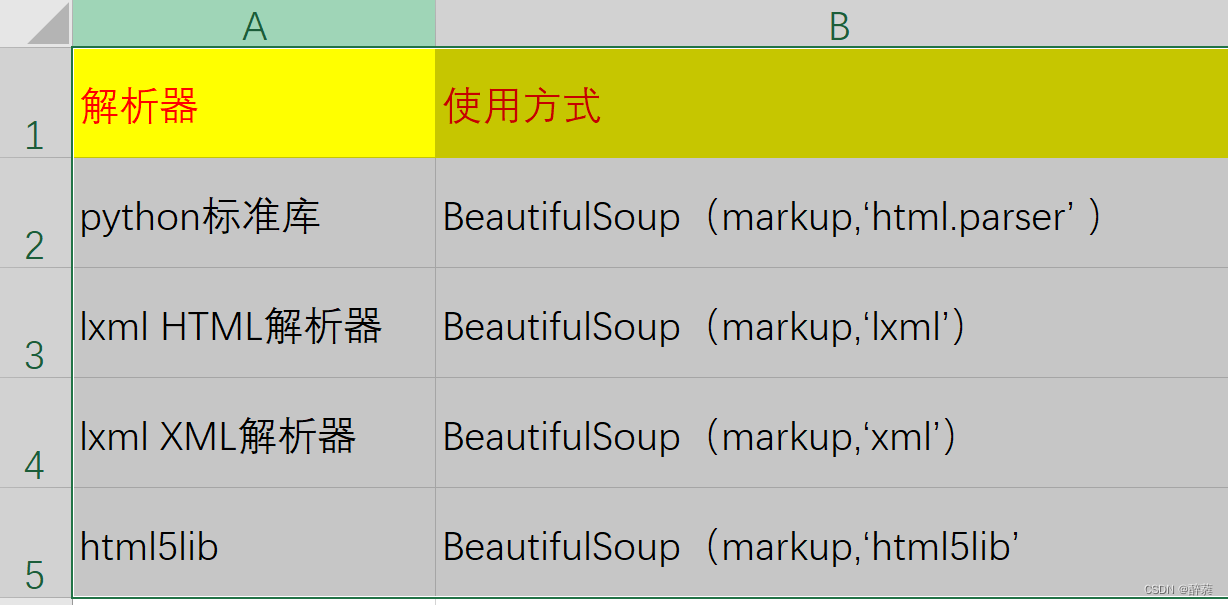
4、解析库

二、遍历文档树
1、contents
获取Tag的所有子节点,返回一个list
# tag的.content 属性可以将tag的子节点以列表的方式输出 print(bs.head.contents) print(bs.head.contents[1])
2、children
获取Tag的所有子节点,返回一个生成器
for child in bs.body.children: print(child)
三、搜索文档树
1、find_all()方法
搜索Tag的所有子结点
find_all(name,attrs,recursive,text,**kwargs)name:名字为name的标签。
attrs:按照Tag标签属性值检索,采用字典形式。
recursive:如果只想搜索Tag的直接子结点,可以使用参数recursive=False。
text:通过text参数可以搜索文本字符中内容。 limit:限制返回结果的数量。
2、find()方法
find()返回符合条件的第一个Tag,参数含义与find_all()方法相同
find(name,attrs,recursive,text)
即当我们要取一个值的时候就可以用这个方法t = bs.div.div # 等价于 t = bs.find("div").find("div")
3、CSS选择器筛选
CSS的选择器用于选择网页元素。在bs4中,也可以利用类似的方法来筛选元素。
soup.select()返回类型是列表
通过标签名查找
print(bs.select('title')) print(bs.select('a'))
通过类名查找
print(bs.select('.mnav'))
通过id查找
print(bs.select('#u1'))
获取内容
t_list = bs.select("title") print(bs.select('title')[0].get_text())
四、基本使用
1、基本使用
from bs4 import BeautifulSoup #导入BeautifulSoup4库 soup = BeautifulSoup("<html>hello python</html>") #得到文档的对象 print(soup)结果:
<html><body><p>hello python</p></body></html>
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')#设置解析器,传递需要解析的html文档
soup.prettify()#格式化代码
soup.title.string#查看title标签内的文本
2、标签选择器
soup.title#返回title标签
type(soup.title) #返回<class 'bs4.element.Tag'>一个类变量
soup.head#返回head标签
soup.p#返回p标签,只返回第一个p标签,如果有多个只能输出第一个
3、获取名称
soup.title.name #返回title 最外层标签的名称4、获取属性
html = '''<p class="title" name="a">paragraph</p>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')
soup.p.attrs['name'] #返回a
soup.p['name']] #返回结果同上
5、 获取内容
html = '''<p class="title" name="a">paragraph</p>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')
soup.p.string #返回paragraph
6、嵌套选择
html = '''<head><p class="title" name="a">paragraph</p><head>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')
soup.head.p.string #返回paragraph
soup.head.p.attrs['name'] # 返回a
7、子节点和子孙节点
html = '''<head><p class="title" name="a">paragraph</p><head>'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')
soup.head.contents #返回所有子节点列表
the = soup.head.children
for i,children in enumerate(the):
print(i,children) # 返回一个iterable 必须使用for循环遍历出来
soup.head.descendants #获取所有的子孙节点,返回类型是iterable object
8、获取父节点和祖先节点
soup.a.parent #获取并输出父节点全部内容
soup.a.parents #获取祖先节点
9、获取兄弟节点
soup.a.next_siblings
soup.a.previous_siblings