为什么要评估?
在进行数据分析时,尤其是在使用像sklearn这样的机器学习库建立模型后,模型评估的重要性不言而喻。模型评估不仅是对模型性能的一次全面检验,更是确保模型在实际应用中能够达到预期效果的关键步骤。
首先,模型评估有助于我们了解模型的性能表现。通过评估,我们可以知道模型在训练集和测试集上的准确率、精确率、召回率等指标,从而判断模型是否达到了预期的分类或预测效果。
其次,模型评估有助于我们进行模型优化。在评估过程中,我们可能会发现模型在某些特定情况下表现不佳,如对于某些类别的分类效果较差或对于某些特征的预测能力较弱。这些信息可以指导我们进行模型调整,如修改模型参数、增加特征或改变特征处理方式等,以提升模型的性能。
此外,模型评估还有助于我们进行模型选择。在实际应用中,我们通常会尝试多种不同的模型来解决同一个问题。通过评估各种模型的性能,我们可以选择出最适合当前任务的模型。这不仅可以提高解决问题的效率,还可以确保我们使用的模型是最优的。
最后,模型评估还有助于我们确保模型的泛化能力。一个好的模型不仅应该在训练集上表现良好,还应该在未见过的数据上具有良好的性能。通过评估模型在测试集上的表现,我们可以对模型的泛化能力有一个大致的了解,从而判断模型是否能够在实际应用中稳定地发挥作用。
1.模型建立
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from IPython.display import Image
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 一般先取出X和y后再切割,有些情况会使用到未切割的,这时候X和y就可以用,x是清洗好的数据,y是我们要预测的存活数据'Survived'
data = pd.read_csv('clear_data.csv')
train = pd.read_csv('train.csv')
X = data
y = train['Survived']
# 对数据集进行切割
# stratify参数分层抽样,保证数据划分均匀,防止全是某一类的数据
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
# 默认参数逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train, y_train)2.模型评估
- 交叉验证(cross-validation)是一种评估泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。在交叉验证中,数据被多次划分,并且需要训练多个模型。
- 最常用的交叉验证是 k 折交叉验证(k-fold cross-validation),其中 k 是由用户指定的数字,通常取 5 或 10。
- 准确率(precision)度量的是被预测为正例的样本中有多少是真正的正例
- 召回率(recall)度量的是正类样本中有多少被预测为正类
- f-分数是准确率与召回率的调和平均
1.交叉验证 :
leg.将数据分为五等分,一份作测试集其他四份作训练集,交叉验证不同划分情况的预测效果。
from sklearn.model_selection import cross_val_score
lr = LogisticRegression(C=100)
# cv参数决定交叉数据集这么划分
scores = cross_val_score(lr, X_train, y_train, cv=10)
# k折交叉验证分数
scores
# 平均交叉验证分数
print("Average cross-validation score: {:.2f}".format(scores.mean())) 

2.混淆矩阵
- 计算二分类问题的混淆矩阵
- 计算精确率、召回率以及f-分数
混淆矩阵也叫误差矩阵,是表示精度评价的一种标准格式。
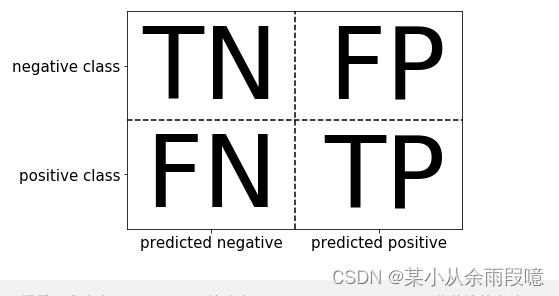
- TN表示负的类.....
- 负的类预测为负的类,则就是Ture负类(真的负类)..
- 同理,正的的类预测为负的类,则就是False负类(假的负类)..
- 与医学中的假阳性和假阴性一样划分原理
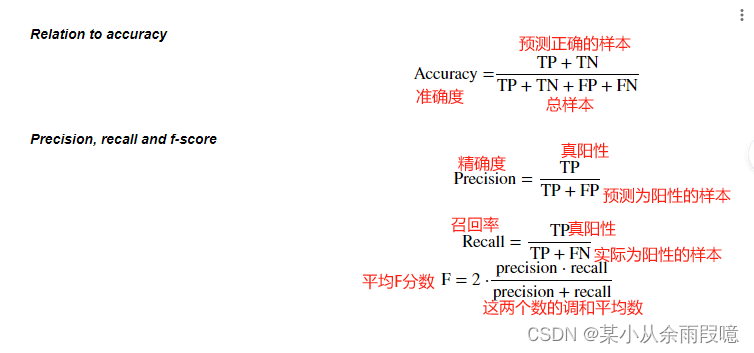
例子:
多分类问题时多元混淆矩阵二分化,只需要将矩阵划分为正确预测和没有正确预测的。
from sklearn.metrics import confusion_matrix
# 训练模型
lr = LogisticRegression(C=100)
lr.fit(X_train, y_train)
# 模型预测结果
pred = lr.predict(X_train)
# 混淆矩阵
# 0死亡,1幸存
confusion_matrix(y_train, pred, labels=[0,1])
from sklearn.metrics import classification_report
# 分类报告
# 精确率、召回率以及f1-score
print(classification_report(y_train, pred))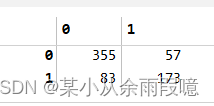
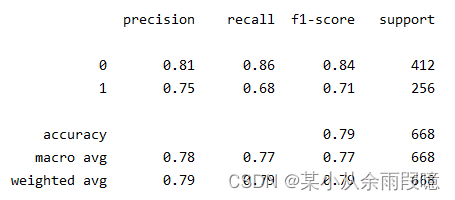
死亡人数355+57人,其中成功预测355人,错误预测为存活的57人。
3.ROC曲线
(ROC曲线)接受者操作特性曲线,是指在特定刺激条件下,以被试在不同判断标准下所得的虚报概率P(y/N)为横坐标,以击中概率P(y/SN)为纵坐标,画得的各点的连线。
横轴:虚惊率,纵轴:击中率。因此图像右上凸越好。
- ROC曲线在sklearn中的模块为
sklearn.metrics - ROC曲线下面所包围的面积越大越好
绘制一条ROC曲线:
from sklearn.metrics import roc_curve
# roc_curve,使用函数
# lr.decision_function逻辑回归中的参数
# 返回的是array,一些值,需要再画出来
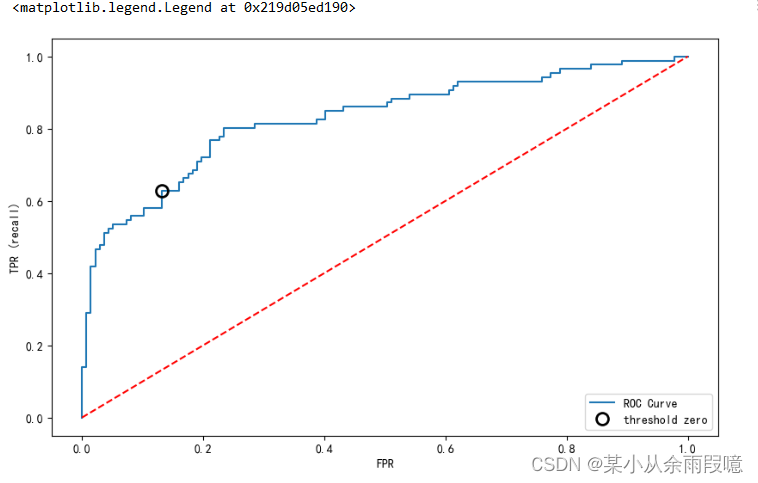
fpr, tpr, thresholds = roc_curve(y_test, lr.decision_function(X_test))
# 画图
plt.plot(fpr, tpr, label="ROC Curve")
# False Positive Rate
plt.xlabel("FPR")
# Ture Positive Rate
plt.ylabel("TPR (recall)")
# 找到最接近于0的阈值(最优点)
# 判断正负类的边界值
# 对参数thresholds求绝对值,然后找到最接近0的,并保存坐标
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2)
# 对角线
plt.plot([0, 1], [0, 1],'r--')
plt.legend(loc=4)在这里我加了对角线:
绘制多条ROC曲线:
# 多个模型,多条ROC曲线
from sklearn.metrics import roc_curve, auc
# 调参后的模型
lr2 = LogisticRegression()
lr2.fit(X_train, y_train)
lr_pred2 = lr2.predict(X_train)
rfc2 = RandomForestClassifier(n_estimators=100, max_depth=5)
rfc2.fit(X_train, y_train)
rfc2_pred2 = rfc2.predict(X_train)
# RandomForestClassifier 类并没有decision_function 这个属性或方法。
fpr, tpr, thresholds = roc_curve(y_test, lr.decision_function(X_test))
fpr2, tpr2, thresholds2 = roc_curve(y_test, lr2.decision_function(X_test))
# 使用predict_proba来获取概率估计
fpr3, tpr3, thresholds3 = roc_curve(y_test, rfc2.predict_proba(X_test)[:,1])
# 计算 ROC AUC
roc_auc = auc(fpr, tpr)
roc_auc2 = auc(fpr2, tpr2)
roc_auc3 = auc(fpr3, tpr3)
# 画图
plt.plot(fpr, tpr, label='ROC curve1 (area = %0.3f)' % roc_auc)
plt.plot(fpr2, tpr2, 'm', label='ROC curve1 (area = %0.3f)' % roc_auc2)
plt.plot(fpr3, tpr3, 'y', label='ROC curve1 (area = %0.3f)' % roc_auc3)
plt.plot([0, 1], [0, 1],'r--')
# False Positive Rate
plt.xlabel("FPR")
# Ture Positive Rate
plt.ylabel("TPR (recall)")
# 添加图例,不需要传递任何参数
plt.legend()
plt.show()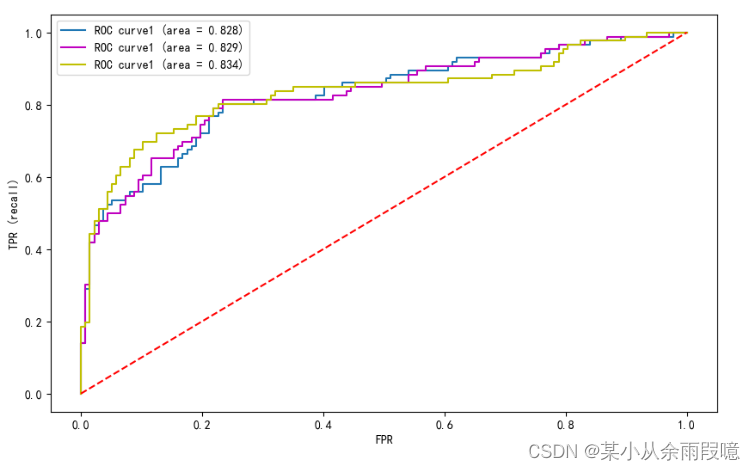
在这个过程中遇到三个问题,
1、RandomForestClassifier函数没有decision_function 这个属性或方法;
解决:使用predict_proba函数来获取概率估计
fpr3, tpr3, thresholds3 = roc_curve(y_test, rfc2.predict_proba(X_test)[:,1])
2、画图时图例无法显示
解决:添加图例,不需要传递任何参数
plt.legend() plt.show()
3、多曲线画图时根据视频用的另一个函数plt_roc_curve,我的sklearn.metrics里没有,可能是版本的问题。