1.Pandas中认识缺值和查看缺失值
处理缺失值的函数汇总

import pandas as pd
import numpy as np
# 1.认识缺失值
# 系统默认的缺失值None和np.nan:无论建立时传递的是np.nan、None在Series和DataFrame对象中都是NaN
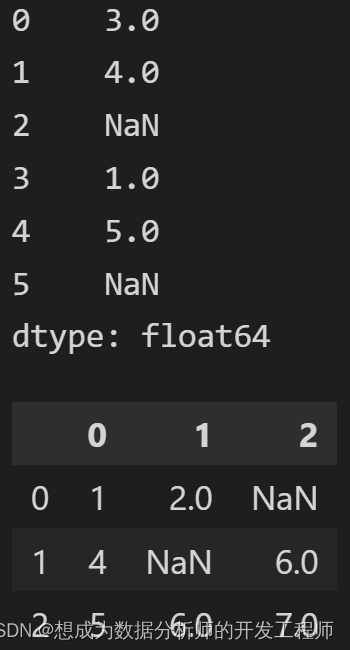
data = pd.Series([3,4,np.nan,1,5,None])
print(data)
df = pd.DataFrame([[1,2,None],[4,np.nan,6],[5,6,7]])
df
# 2.缺失值查看info
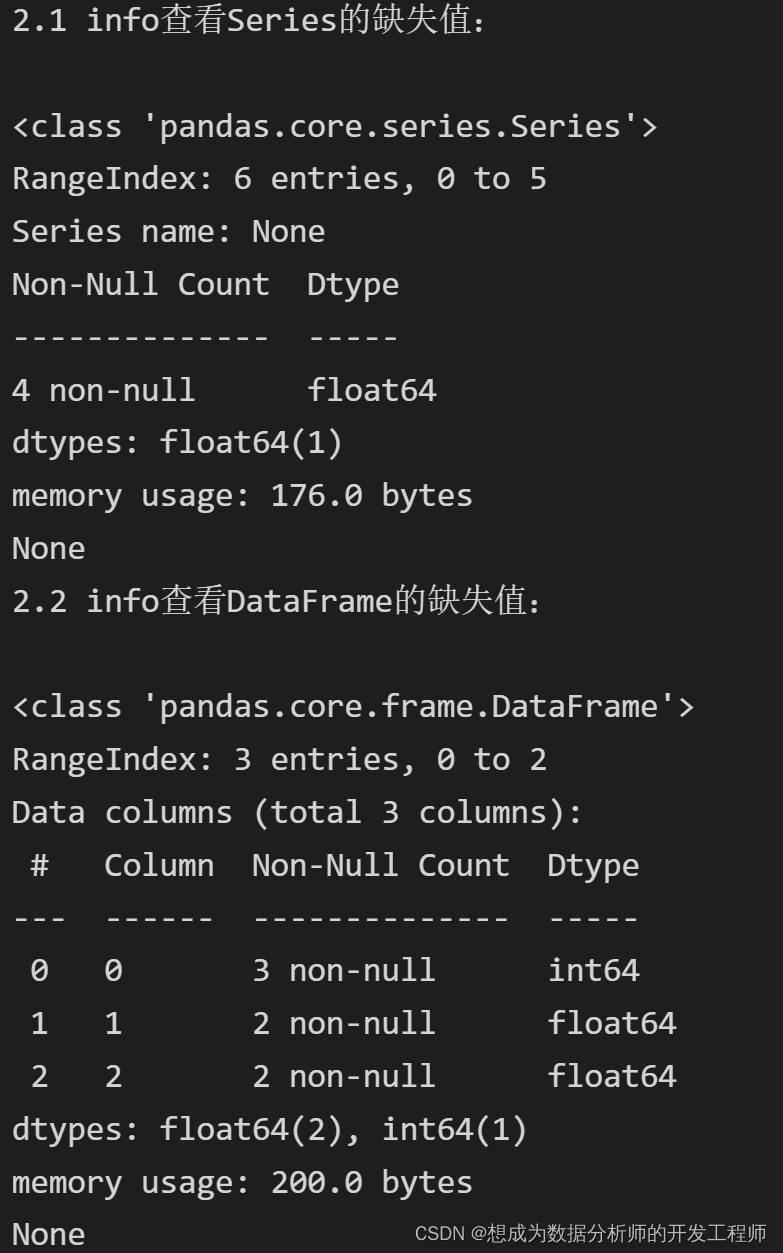
# 2.1 info查看Series的缺失值
print("2.1 info查看Series的缺失值:\n")
print(data.info())
# 2.2 info查看DataFrame的缺失值
print("2.2 info查看DataFrame的缺失值:\n")
print(df.info())
# 3.获取所有缺失值
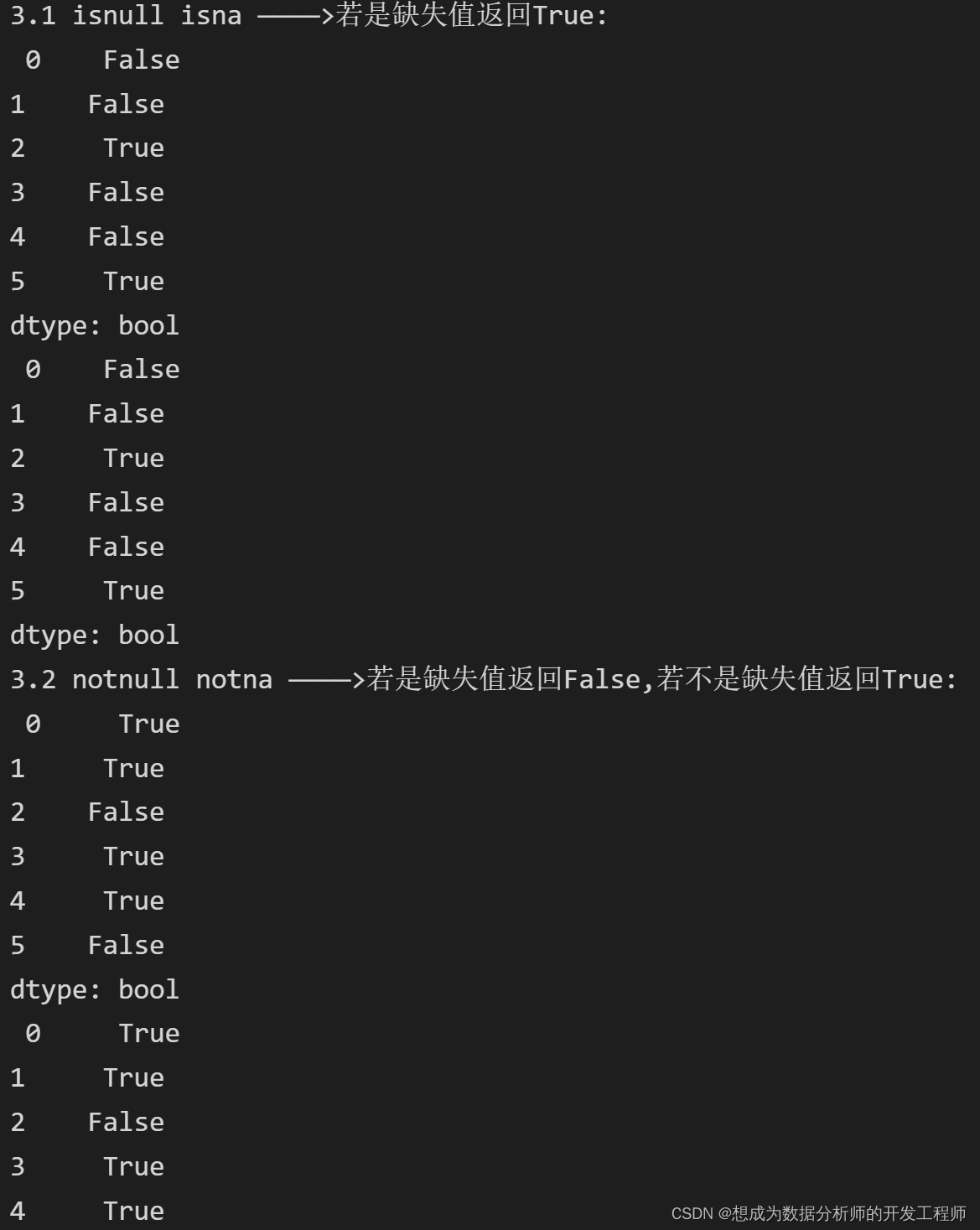
# 3.1 isnull isna ————>若是缺失值返回True,若不是缺失值返回False
print("3.1 isnull isna ————>若是缺失值返回True:\n",data.isnull(),'\n',data.isna())
# 3.2 notnull notna ————>若是缺失值返回False,若不是缺失值返回True
print("3.2 notnull notna ————>若是缺失值返回False,若不是缺失值返回True:\n",data.notnull(),'\n',data.notna())
# 3.3 获取缺失值/非空值的位置
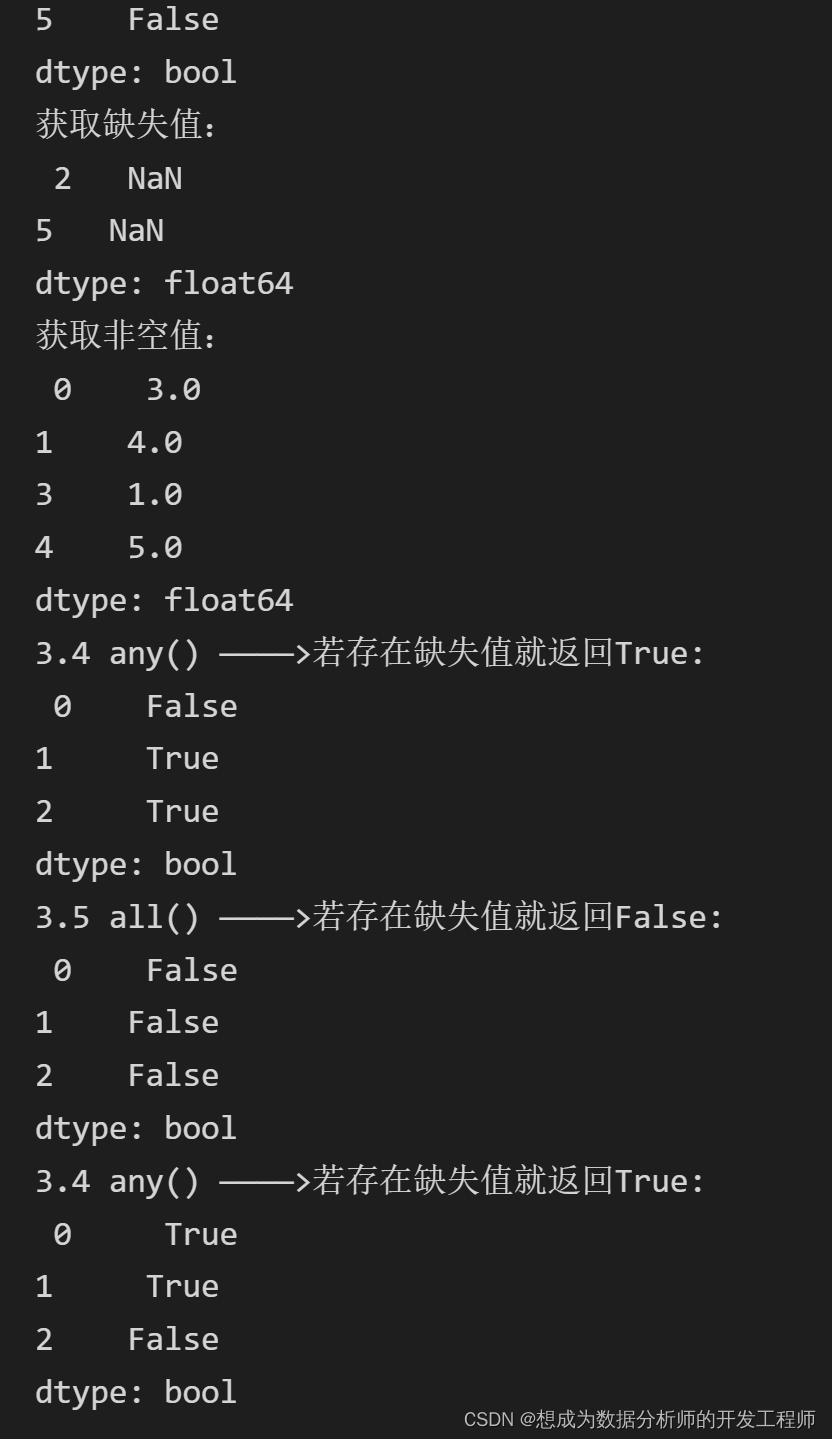
print('获取缺失值:\n',data[data.isnull()])
print('获取非空值:\n',data[data.notna()])
# 3.4 any() ————>若存在缺失值就返回True:默认检测列中是否含有缺失值
print('3.4 any() ————>若存在缺失值就返回True:\n', df.isna().any())
# 3.5 all() ————>若存在缺失值就返回False:默认检测列中是否含有缺失值
print('3.5 all() ————>若存在缺失值就返回False:\n', df.isna().all())
# 3.6 any() ————>若存在缺失值就返回True:检测行
print('3.4 any() ————>若存在缺失值就返回True:\n', df.isna().any(axis=1))
# 3.7 查看缺失值具体位置
df[df.isna().any(1)]

2.Pandas填充缺失值
调用fillna()方法对数据表中的所有缺失值进行填充,在fillna()方法中输入要填充的值。还可以通过method参数使用前一个数和后一个数来进行填充。
df.fillna(
value :用于填充缺失值的数值,也可以提供
dict/Series/DataFrame 以进—步指明哪些索引/列会被替换 不能使用 list
method = None :有索引时具体的填充方法,向前填充,向后填充等
limit = None :指定了 method 后设定具体的最大填充步长,此步长不能填充
axis : index (0), columns (1)
inplace = False
)
import pandas as pd
import numpy as np
# 1.一维数组Series对象的缺失值填充
data = pd.Series([3,4,np.nan,1,5,None])
print('原数据:')
print(data)
# 1.1 以0进行填充
print('以0进行填充')
print(data.fillna(0))
# 1.2 以前一个数值进行填充
print('以前一个数值进行填充')
print(data.fillna(method='ffill'))
# 1.3 以后一个数值进行填充
print('以后一个数值进行填充')
print(data.fillna(method='bfill'))
# 1.4 先按照前一个,再后一个填充(在末尾的数值或者开头的缺失值,可能无法被填充到)
print('先按照前一个,再后一个填充')
print(data.fillna(method='bfill').fillna(method='ffill'))


# 2.二维数组DataFrame对象缺失值填充
df = pd.DataFrame([[1,2,np.nan],[4,np.nan,6],[5,6,7]])
print('原数据:')
print(df)
# 2.1 以0进行填充
print('以0进行填充')
print(df.fillna(0))
# 2.2 以本列的上一行数值进行填充
print('以本列的上一行数值进行填充')
print(df.fillna(method='ffill'))
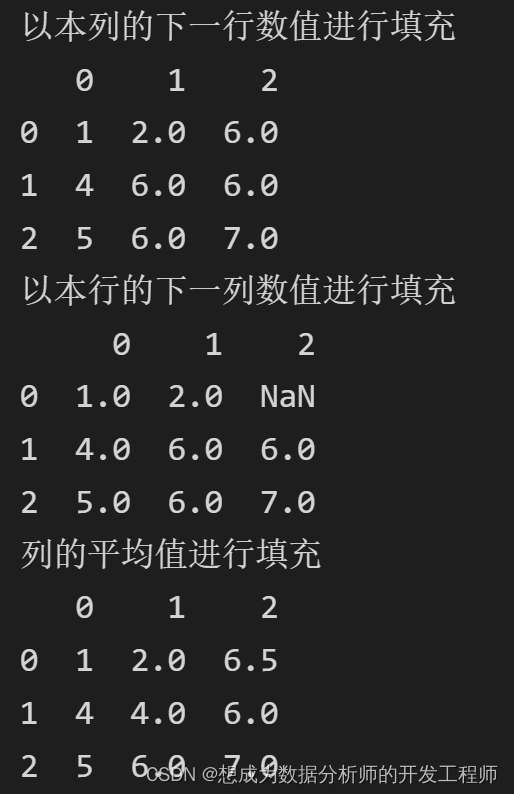
# 2.3 以本列的下一行数值进行填充(默认是以列为准aixs=0)
print('以本列的下一行数值进行填充')
print(df.fillna(method='bfill'))
# 2.4 以本行的下一列数值进行填充
print('以本行的下一列数值进行填充')
print(df.fillna(method='bfill',axis=1))
# 2.5 列的平均值进行填充
for i in df.columns:
df[i] = df[i].fillna(np.nanmean(df[i]))
print('列的平均值进行填充')
print(df)

3.Pandas删除缺失值
调用dropna()方法删除缺失值,dropna()方法默认删除含有缺失值的行,也就是只要某一行有缺失值就把这一行删除。如果想按列为单位删除缺失值,需要传入参数axis=’columns’。
import pandas as pd
import numpy as np
df = pd.DataFrame([[1,2,np.nan],[4,np.nan,6],[5,6,7]])
print('原数据:')
print(df)
# 删除缺失值:dropna 默认是以行为单位进行删除,默认存在缺失值,删除一整行
'''
df.dropna(
axis = 0 : index (0), columns (1)
how = any : any、all
any :任何一个为 NA 就删除
all :所有的都是 NA 删除
thresh = None :删除的数量阈值,
int
subset :希望在处理中包括的行/列子集
inplace = False :
)
'''
# 默认以行为单位删除
print("默认以行为单位删除")
print(df.dropna())
# 以列为单位进行删除
print("以列为单位进行删除")
print(df.dropna(axis=0))
# 行中所有为空值时才进行删除
print('行中所有为空值时才进行删除')
print(df.dropna(how='all'))
# 默认情况,只要存在就删除一行
print('默认情况,只要存在就删除一行')
print(df.dropna(how='any'))

4.Pandas数据查重
标识出重复行的意义在于进一步检査重复原因,以便将可能的错误数据加以修改
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
pd.options.display.max_rows = 4
# 1.Duplicated:True为不是重复数据,False为是重复数据
# 1.1默认对比每一行是否存在完全相同的数据
# df.duplicated()# 查看每一行是否存在
print('查看全部数据是否存在完全相同的')
print(df.duplicated().any())
# 1.2对比指定列中的行是否存在完全相同的数据
print('对比指定列中的行是否存在完全相同的数据')
print(df.duplicated(['开设','课程']))
# 1.3 对比指定列中的行是否存在完全相同的数据,直接删除数据
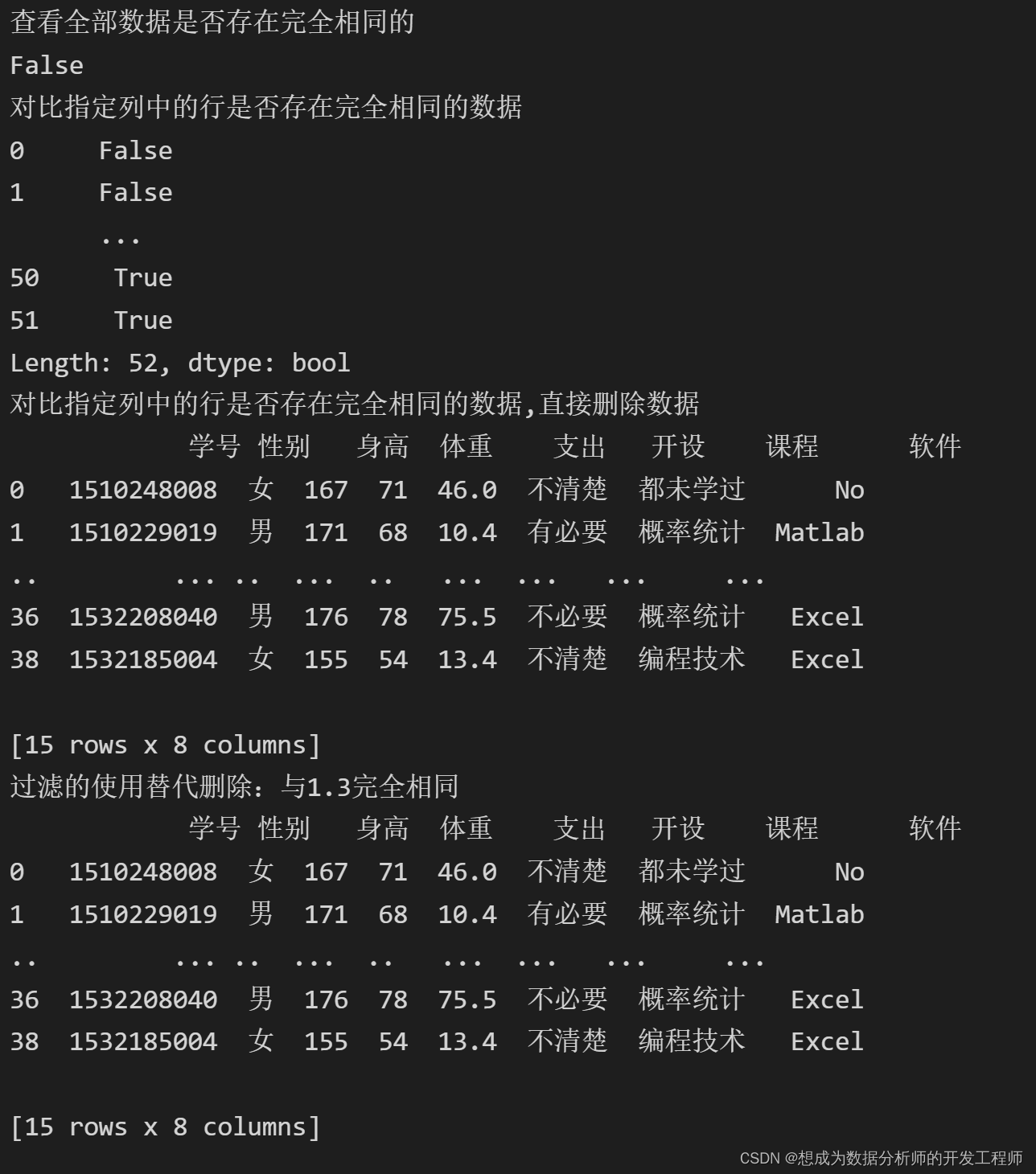
print('对比指定列中的行是否存在完全相同的数据,直接删除数据')
print(df.drop_duplicates(['开设','课程']))
# 1.4 过滤的使用替代删除:与1.3完全相同
print('过滤的使用替代删除:与1.3完全相同')
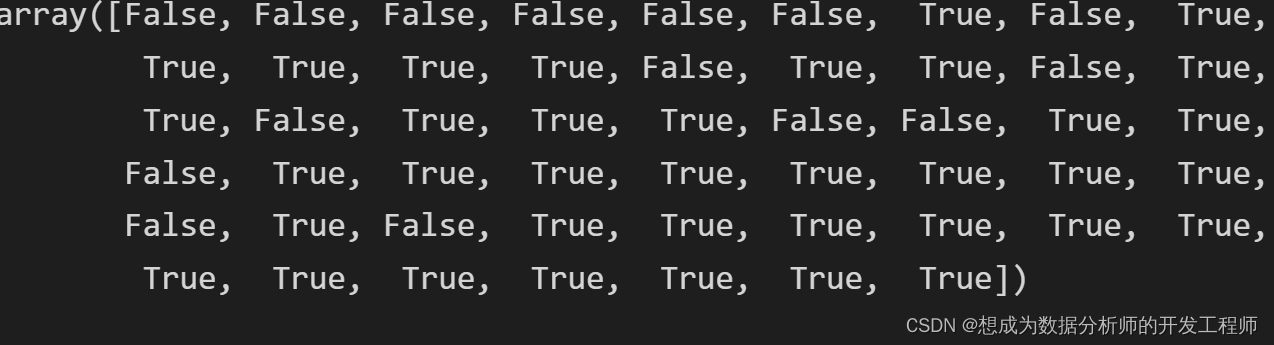
print(df[~df.duplicated(['开设','课程'])])
# 1.5 使用索引标识重复行
df2 = df.set_index(['开设','课程'])
df2.index.duplicated()