
🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
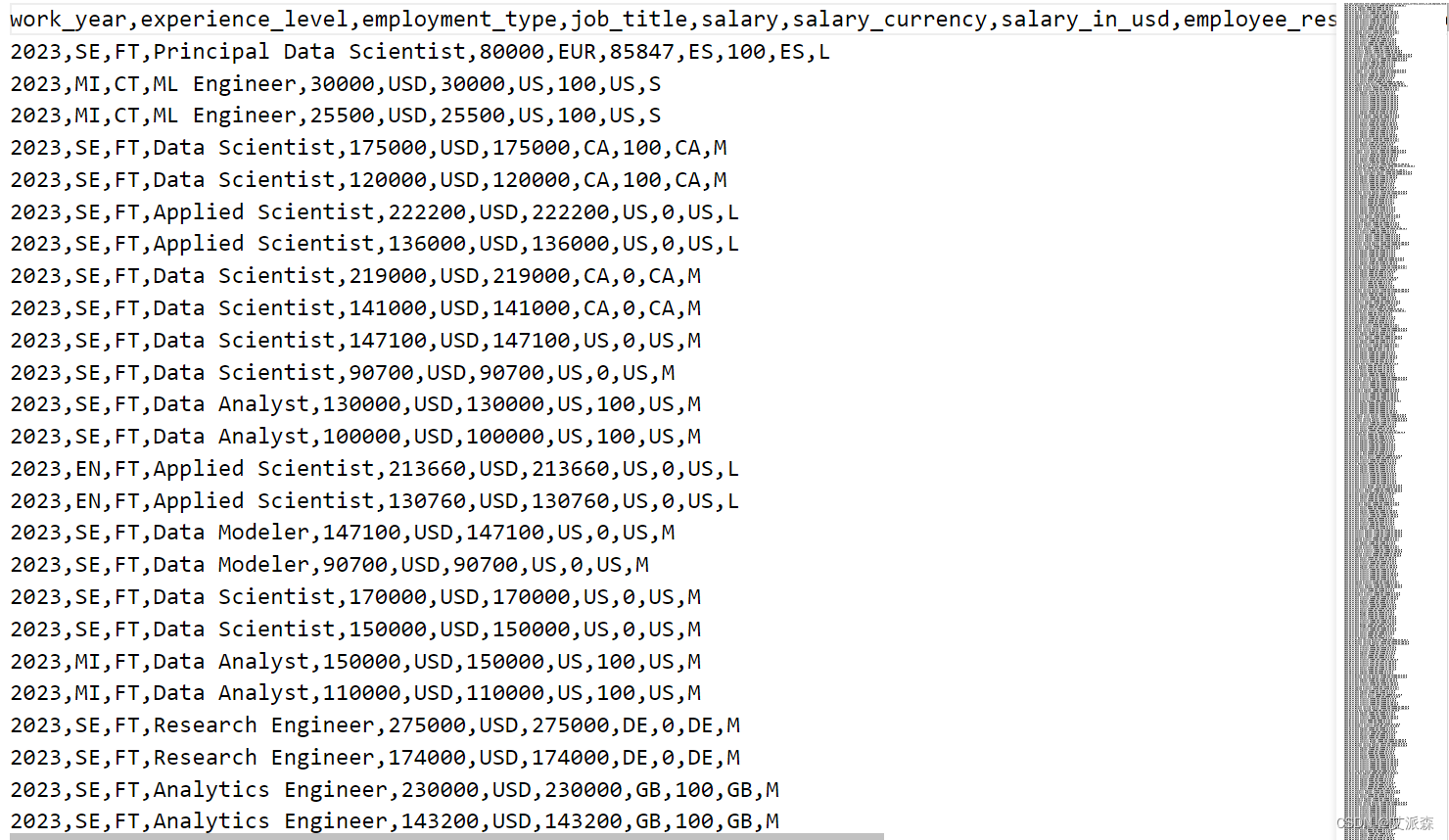
数据集介绍
本数据集来源于kaggle,原始数据集共有3755条, 11列特征,各特征具体含义如下:
work_year:发工资的年份。
experience_level:该职位在一年内的经验水平
employment_type:角色的雇佣类型
job_title:这一年中工作的角色
工资:支付的工资总额
salary_currency:作为ISO 4217货币代码支付的工资的货币
salaryinusd:以美元计算的工资
employee_residence:作为ISO 3166国家代码,雇员在工作年度的主要居住国家
remote_ratio:远程完成的总工作量
company_location:雇主的主要办事处或承包分公司所在的国家
company_size:该年度为该公司工作的人数中位数
可视化分析
首先导入本次可视化用到的第三方库,并使用pandas导入数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
import seaborn as sns
import country_converter as coco
import warnings
warnings.filterwarnings('ignore')
sns.set_theme()
sns.set(rc = {"figure.figsize":(8,6)})
df = pd.read_csv('ds_salaries.csv')
df.head()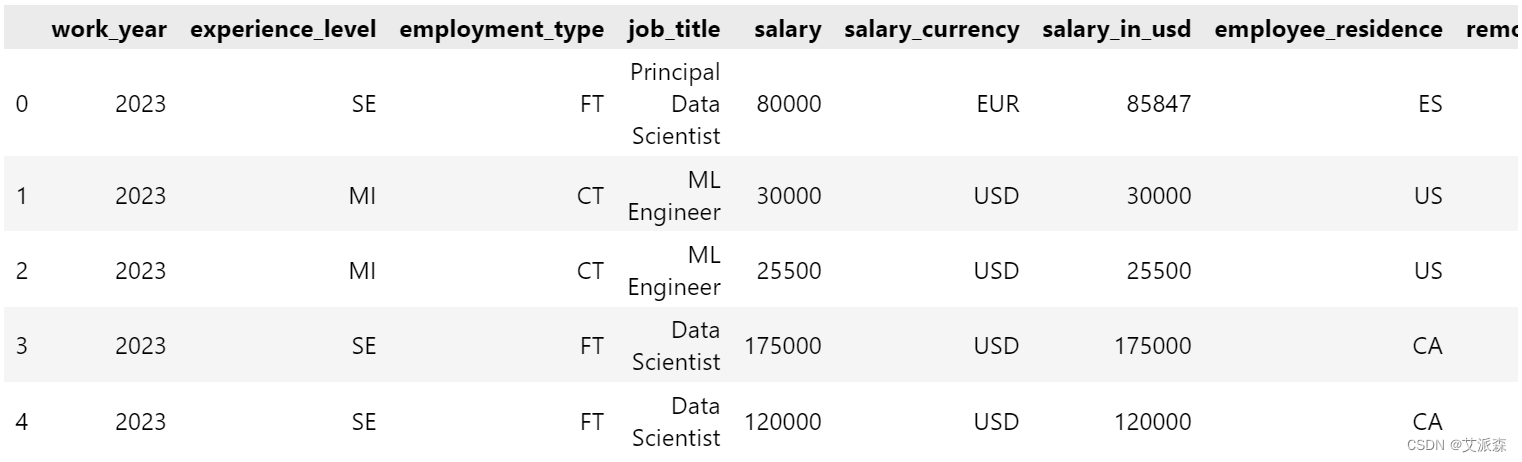
1.分析2023年排名前十的岗位
# Top 10 Job Titles in 2023
jobs = df[df['work_year']==2023]['job_title'].value_counts().nlargest(10).reset_index()
fig, ax = plt.subplots()
ax = sns.barplot(ax = ax, data = jobs , y = jobs['index'], x = jobs.job_title)
ax.set(ylabel='Job Titles',xlabel='Counts', title='Top 10 Job Titles in 2023')
ax.bar_label(ax.containers[0], padding = 2)
plt.show()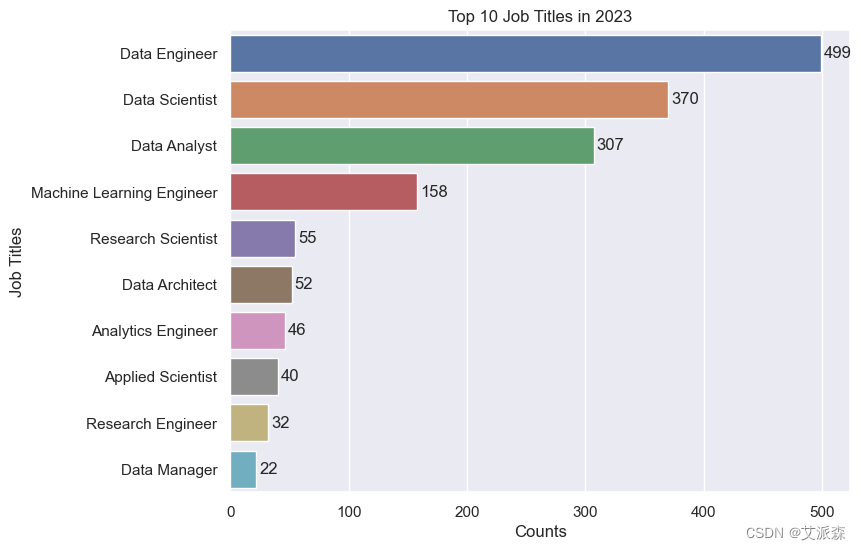
正如您所看到的,数据工程师最多,其次是数据科学家和数据分析师。
2.分析工作经验水平情况
# Experience Levels
df['experience_level'] = df['experience_level'].replace('EN','Entry-level/Junior')
df['experience_level'] = df['experience_level'].replace('MI','Mid-level/Intermediate')
df['experience_level'] = df['experience_level'].replace('SE','Senior-level/Expert')
df['experience_level'] = df['experience_level'].replace('EX','Executive-level/Director')
fig, ax = plt.subplots()
sns.countplot(ax = ax, data = df, x = df.experience_level)
ax.set(xlabel='', ylabel='Counts', title='Experience Levels')
ax.bar_label(ax.containers[0])
plt.show()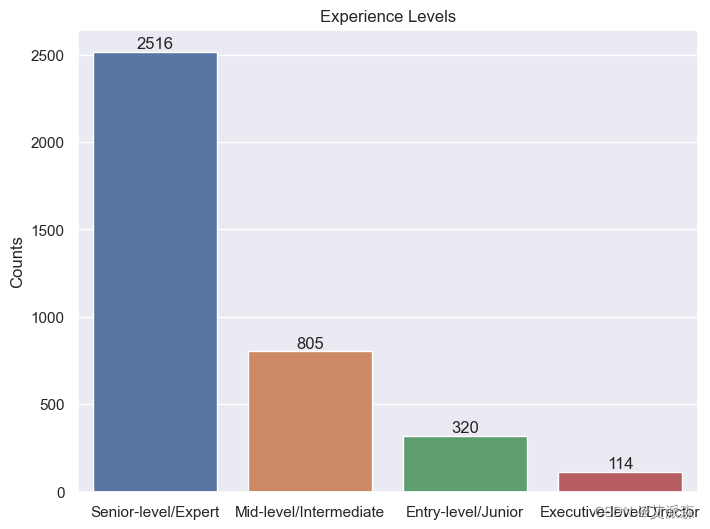
正如您所看到的,高级职位的计数最高,其次是中级和初级职位。与其他级别的职位相比,总监级别的职位更少。
3.分析雇佣类型情况
# Employment Types
df['employment_type'] = df['employment_type'].replace('FT','Full-Time')
df['employment_type'] = df['employment_type'].replace('PT','Part-Time')
df['employment_type'] = df['employment_type'].replace('CT','Contract')
df['employment_type'] = df['employment_type'].replace('FL','Freelance')
fig, ax = plt.subplots()
sns.countplot(ax = ax, data = df, x = df.employment_type, hue = 'experience_level')
ax.set(xlabel='', ylabel='Counts', title='Number of Employment Types')
ax.bar_label(ax.containers[0])
ax.bar_label(ax.containers[1])
ax.bar_label(ax.containers[2])
ax.bar_label(ax.containers[3])
plt.show()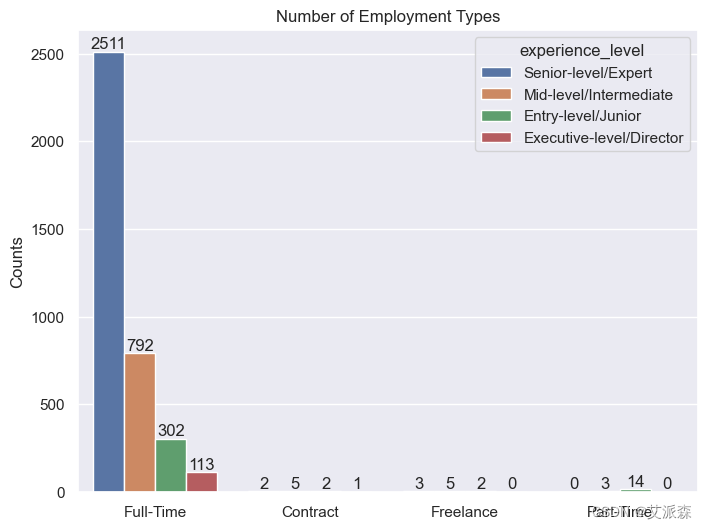
正如你所看到的,这里有相当多的人是全职工作。在全职员工中,大多数是高级员工。我们观察到自由职业现在不那么流行了。
4.分析薪资最高的岗位
# Salaries by Job Titles
job_title_salary = df['salary_in_usd'].groupby(df['job_title']).mean().round(0).nlargest(15).sort_values(ascending = False).reset_index()
fig, ax = plt.subplots()
ax = sns.barplot(ax = ax, data = job_title_salary , y = job_title_salary.job_title, x = job_title_salary.salary_in_usd)
ax.set(ylabel='Job titles',xlabel='Salary in usd', title='Top 15 Average Salaries by Job Titles')
ax.bar_label(ax.containers[0], padding = 2)
plt.show()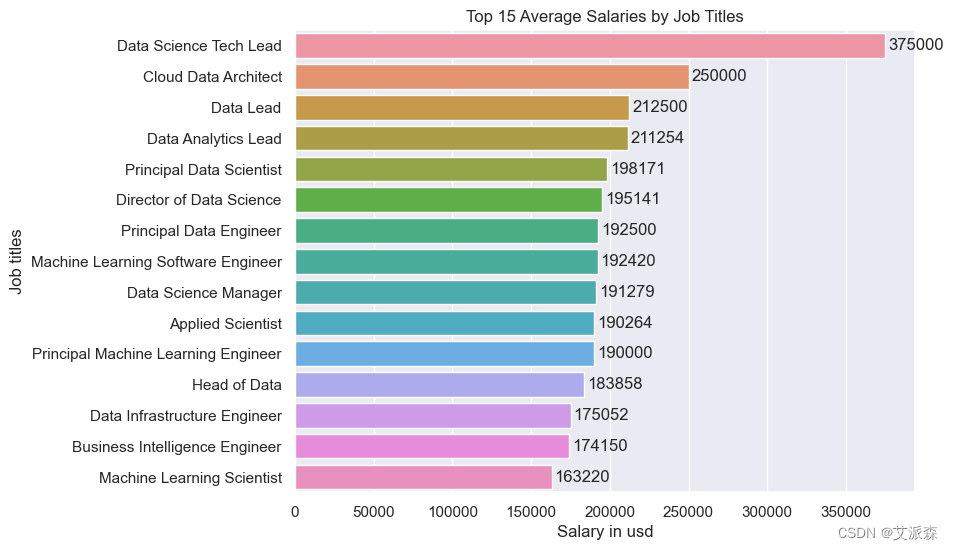
正如我们所料,一般在行政级别工作的人的平均工资要高一些。由于云计算的趋势,云数据架构师是收入第二高的职业。
5.分析薪资最高的雇佣类型
# Salaries by Employment Types
avg_salaries = df.groupby('employment_type')['salary_in_usd'].mean().round(0).sort_values(ascending = False).reset_index()
fig, ax = plt.subplots()
sns.barplot(ax =ax,data = df , x = 'employment_type', y = 'salary_in_usd',errorbar = None, hue = 'work_year')
ax.set(xlabel='', ylabel='Dollars', title='Average Salaries in Dollars Per Year')
ax.bar_label(ax.containers[3], padding = 2)
plt.show()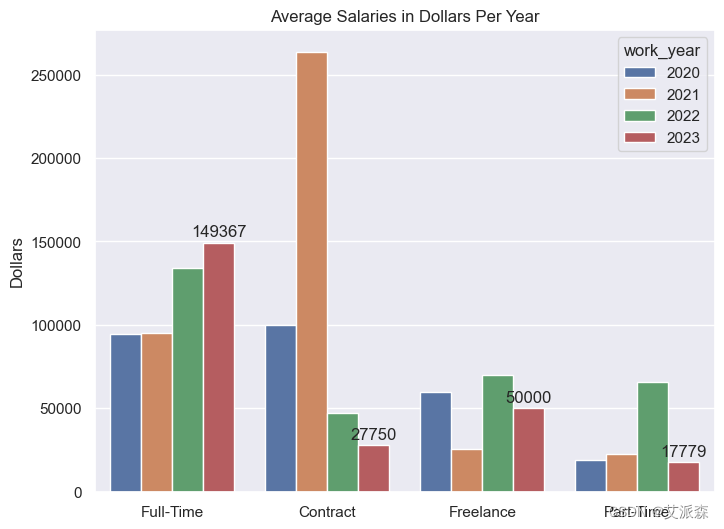
正如你所看到的,全职员工的平均工资多年来一直在增长。这表明公司关心数据科学。第二高的薪水属于自由职业者,这清楚地表明了自由职业者的增长趋势。
6.分析平均薪资最高的年份
# Salaries by Work Years
year_based_salary=df['salary_in_usd'].groupby(df['work_year']).mean()
plt.title("Average Salaries based on Work Year")
plt.xlabel('Work Year')
plt.ylabel('Salary')
sns.lineplot(x=['2020', '2021', '2022','2023'],y=year_based_salary)
plt.show()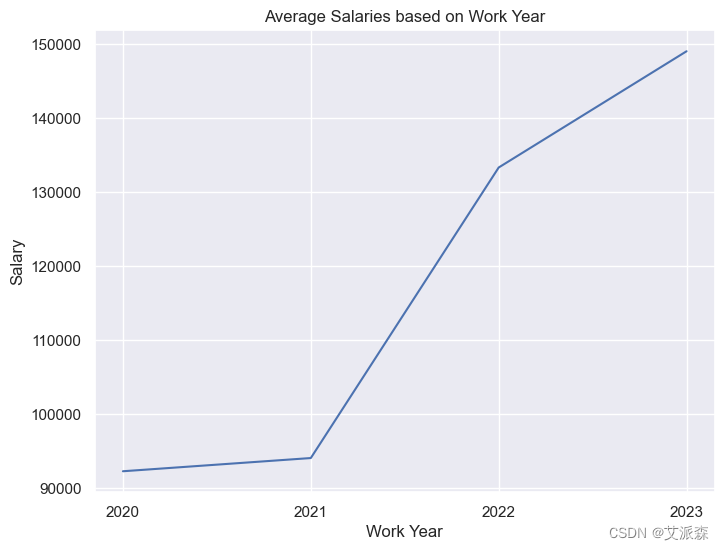
正如你所看到的,数据驱动型工作的平均工资每年都在增长,在2021年到2022年之间的增幅尤其显著。这一趋势凸显了对该领域熟练专业人员的需求日益增长。
7.绘制公司分布热力地图
# Remote Jobs Locations
rr = df.groupby('company_location')['remote_ratio'].mean().reset_index()
rr['company_location'] = coco.convert(names = rr['company_location'], to = "ISO3")
fig = px.choropleth(rr,
locations = rr.company_location,
color = rr.remote_ratio,
labels={'company_location':'Country','remote_ratio':'Remote Jobs Ratio'})
fig.update_layout(title = "Remote Jobs Locations")
fig.show()
图片看不到的话,大家就自行运行吧。
本期推荐
《 Python自动化办公应用大全(ChatGPT版)》

内容简介:
本书全面系统地介绍了Python语言在常见办公场景中的自动化解决方案。全书分为5篇21章,内容包括Python语言基础知识,Python读写数据常见方法,用Python自动操作Excel,用Python自动操作Word 与 PPT,用Python自动操作文件和文件夹、邮件、PDF 文件、图片、视频,用Python进行数据可视化分析及进行网页交互,借助ChatGPT轻松进阶Python办公自动化。
本书适合各层次的信息工作者,既可作为初学Python的入门指南,又可作为中、高级自动化办公用户的参考手册。书中大量的实例还适合读者直接在工作中借鉴。
粉丝福利
《Python自动化办公应用大全(ChatGPT版)》免费送书2本!
参与福利
- 抽奖方式:评论区随机抽取2位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-05-27 20:00:00
名单公布时间:2023-05-27 21:00:00
