
✨前言✨
🎓作者:【 教主 】
📜文章推荐:
☕博主水平有限,如有错误,恳请斧正。
📌机会总是留给有准备的人,越努力,越幸运!
💦导航助手💦
目录
整数
整数在内存中是以二进制补码的形式来存储。这里先介绍 原码 反码 补码
//注意:正数的原码 反码 补码 相同
在这种储存模式下,二进制数据分为两个部分:
- 符号位
将整数转换为二进制后,数据最高位即为符号位:0表示正,1表示负。
举个例子:int a = 1,a的二进制表示为:00000000 00000000 00000000 00000001
int b =-1,b的二进制表示为:10000000 00000000 00000000 00000001
- 数据位
除了最高位的符号位,剩下的就是数据位,用来计算数据的绝对值大小。
原码
直接将整数转换为二进制形式,即为数据的原码。
举个例子,
举个例子:int a = 1,a的原码表示为:00000000 00000000 00000000 00000001
int b =-1,b的原码表示为:10000000 00000000 00000000 00000001
反码
正数的原码反码补码相同,不用考虑。
如果是负数,从原码转换为反码的规则是:符号位不变,数据位取反。
取反是什么意思呢?在二进制表示法中,位的情况只有两种,不是0就是1,所以取反就是0变1,1变0。
举个例子, int b =-1,b的原码表示为:10000000 00000000 00000000 00000001
那么b的反码即为:111111111 111111111 111111111 111111110
补码
正数的原码反码补码相同,不用考虑。
如果是负数,从反码转换为补码的规则是:反码+1
举个例子, int b =-1,b的原码表示为:10000000 00000000 00000000 00000001
那么b的反码即为:111111111 111111111 111111111 111111110
1的二进制表示:00000000 00000000 00000000 00000001
相加后就是b的补码:111111111 111111111 111111111 111111111
所以,-1就是以这种形式存储。
浮点数
浮点数在内存中以IEEE标准来进行存储。常用的分为单精度(余127码表示法)和双精度(余1032码表示法)两种精度,这里重点介绍单精度,双精度类似与单精度。
单精度(余127码表示法)
浮点数存储分为三个部分
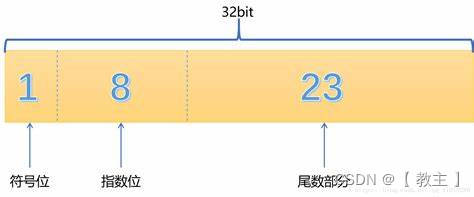
- 符号位(S)
和整数一样,符号位0表示正,1表示负。
- 指数(E)
单精度模式下,指数位有8位。那么指数为是如何来计算的呢?我们来看
举个例子,浮点数5.75。
首先我们将5.75转换为二进制表示:101.11
这时我们需要对二进制进行标准化,即先找到二进制形式下的左边第一个1,将小数点移到这个1右边。
标准化之后为:1.0111x2^2
2的指数为2,所以E=2+127=129
这里+127就是为什么单精度存储方法又叫余127码法。
再将E转换为二进制形式:10000001 这就是我们所需要的E
- 尾数部分(M)
我们将5.75标准化后得到:1.0111x2^2
小数点之后的数据即M,所以M=0111,但是M一共需要23位,所以要在右边补0,所以最终表示出来就是这样,如图:

存储在计算机中就是01000000101110000000000000000000
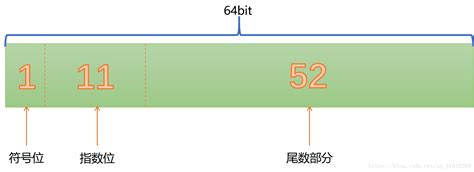
双精度(余1023码)
存储方法类似与单精度,参考单精度。
大端、小端模式
把数据的低位字节处的数据存放在高地址处,把数据高位字节处的数据存放在低地址处叫大端存储,小端存储反之。
举个例子,如果采用大端存储,int a=1,a的补码:00000000 00000000 00000000 00000001

如果采用小端存储

//注意:计算机在读取数据时,是从低地址开始访问,访问到高地址。
那么我们如何来判断编译器是采用哪种存储方式呢?
例如,int a =1,创建了一个占4个字节的整形变量a,如果我们可以访问到a的最低地址处的一个字节,看看这个数是多少,如果是1,说明低地址处放的是低位字节,如果是0,说明低地址处放的是高位字节,如何访问到一个字节呢?这时候就体现出指针分类型的意义了,不同的指针每次解引用的大小是不同的,那我们就用char* 类型的指针来访问a的一个字节,看看这个数到底是多少。
代码如下:
#include<stdio.h>
int main()
{
int a = 1;
char* pa = (char*)&a;
if (1 == *pa)
{
printf("小端字节序存储\n");
}
else
{
printf("大端字节序存储\n");
}
return 0;
}运行结果如下:

博主当前使用的是Visual Studio 2022 编译器,采用的是小端存储,其实大部分的编译器采用的是小端模式,大端模式采用的并不多。
欢迎关注,码字不易,希望多多点赞、收藏哦!抱拳了。
