您可以使用以下 SQL 查询语句来提取 detail 字段中包含 oss.kxlist.com 的 URL 里的 commodity/ 后面的数字串:
<p><img style="max-width:100%;" src="https://oss.kxlist.com//8a989a0c55e4a7900155e7fd7971000b/commodity/20170925/20170925190215_f46831.jpg"/><br/></p><p><br/></p>
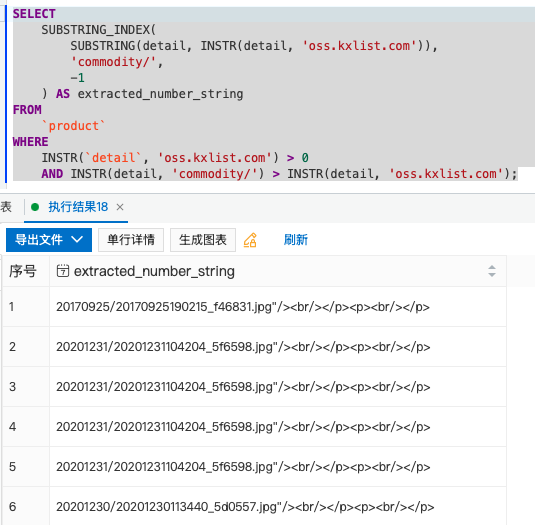
SELECT
SUBSTRING_INDEX(
SUBSTRING(detail, INSTR(detail, 'oss.kxlist.com')),
'commodity/',
-1
) AS extracted_number_string
FROM
`product`
WHERE
INSTR(`detail`, 'oss.kxlist.com') > 0
AND INSTR(detail, 'commodity/') > INSTR(detail, 'oss.kxlist.com');
语句解释:
-
SELECT ... FROMproductWHERE ...: 这是基本的SELECT查询框架,从product表中选择数据,并使用WHERE子句进行条件筛选。 -
WHERE INSTR(detail, 'oss.kxlist.com') > 0 AND INSTR(detail, 'commodity/') > INSTR(detail, 'oss.kxlist.com'):WHERE子句包含两个条件,使用AND连接,确保同时满足:INSTR(detail, 'oss.kxlist.com') > 0: 第一个条件,确保detail字段中包含oss.kxlist.com。 这和我们之前的查询条件一样,用于筛选出包含旧域名的记录。INSTR(detail, 'commodity/') > INSTR(detail, 'oss.kxlist.com'): 第二个条件,确保commodity/出现在oss.kxlist.com之后。 这更精确地定位到您想要提取数字串的 URL 部分,避免误提取其他地方可能出现的commodity/。
-
SUBSTRING_INDEX( ... , 'commodity/', -1):SUBSTRING_INDEX()函数用于截取字符串,并根据指定的分隔符和计数返回子字符串。SUBSTRING(detail, INSTR(detail, 'oss.kxlist.com')): 内层SUBSTRING()函数:INSTR(detail, 'oss.kxlist.com'): 找到detail字段中oss.kxlist.com第一次出现的位置。SUBSTRING(detail, INSTR(detail, 'oss.kxlist.com')): 从detail字段中,截取从oss.kxlist.com第一次出现的位置开始到字符串末尾 的子字符串。 这样做是为了先定位到包含旧域名的 URL 部分,再在这个子字符串中查找commodity/。
SUBSTRING_INDEX(..., 'commodity/', -1): 外层SUBSTRING_INDEX()函数:- 第一个参数是内层
SUBSTRING()函数截取的结果 (即包含oss.kxlist.com开始的子字符串)。 - 第二个参数
'commodity/'是分隔符,我们想要根据commodity/来分割字符串。 - 第三个参数
-1是计数。-1表示返回分隔符最后一次出现之后的所有子字符串。 由于我们已经用内层SUBSTRING()定位到了 URL 部分,并且 URL 结构通常是...oss.kxlist.com//.../commodity/数字串..., 使用-1可以直接提取commodity/后面的部分,也就是您需要的数字串。
- 第一个参数是内层
-
AS extracted_number_string:AS关键字用于给查询结果的列起一个别名,这里将提取出来的数字串列命名为extracted_number_string,使结果更易于理解。
执行查询:
您可以使用 MySQL 客户端工具执行这个查询语句。 执行后,您将会得到一个结果集,每一行都包含一个名为 extracted_number_string 的列,列值就是 detail 字段中包含 oss.kxlist.com 的 URL 里, commodity/ 后面的数字字符串。
示例结果 (假设 detail 字段包含 <img src="//oss.kxlist.com//8a989a0c55e4a7900155e7fd7971000b/commodity/20170925/20170925190215_f46831.jpg"/>):
| extracted_number_string |
|---|
| 20170925/20170925190215_f46831.jpg"/> |
| … (其他符合条件的记录) |
请注意:
- 这个查询语句假设在包含
oss.kxlist.com的 URL 中,commodity/后面紧跟着您需要的数字串。 如果 URL 结构更复杂,或者commodity/后面的内容不总是数字串,您可能需要根据实际情况调整SUBSTRING_INDEX()函数的参数,或者使用更复杂的正则表达式或字符串处理方法来精确提取您想要的内容。 - 提取出来的字符串可能仍然包含一些不需要的部分 (例如示例结果中的
"/>)。 如果您只需要纯数字部分,可能需要进一步使用字符串函数或正则表达式来清洗和提取。 但这个查询已经提取了commodity/后面的主要部分,您可以在此基础上进行进一步处理。