✨个人主页欢迎您的访问 ✨期待您的三连 ✨
✨个人主页欢迎您的访问 ✨期待您的三连 ✨
✨个人主页欢迎您的访问 ✨期待您的三连✨



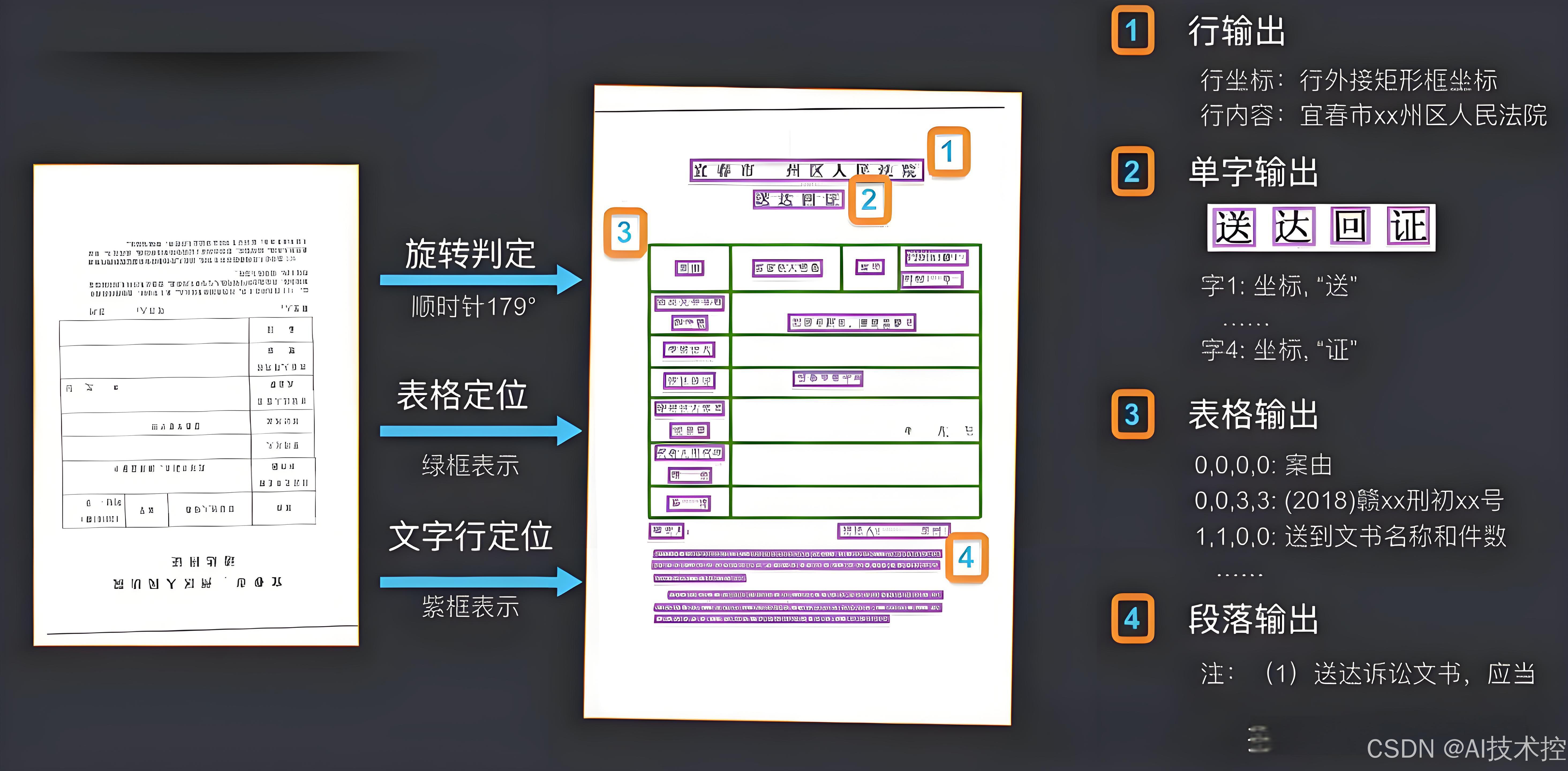
一、领域简介✨✨
文档扫描与 OCR(Optical Character Recognition) 是计算机视觉的核心应用之一,旨在将物理文档(如纸质文件、名片、票据)转化为可编辑的数字化文本。其核心流程包括:
- 文档检测与矫正:定位图像中的文档区域并校正透视变形。
- 文本检测:识别图像中的文本区域(行、单词、字符)。
- 文本识别:将文本区域转换为机器编码字符(如 UTF-8)。
- 后处理:基于语义规则或语言模型纠错。
应用场景:
- 企业财务自动化(发票识别)
- 证件信息录入(身份证、护照)
- 古籍数字化
- 移动端文档扫描(如 “扫描全能王”)

二、当前主流算法✨✨
1. 文档检测与矫正
- 传统方法:基于边缘检测(Canny) + 霍夫变换(Hough)定位文档四角。
- 深度学习方法:
- DewarpNet(ICCV 2021):通过 UNet 预测文档的 3D 形变网格。
- DocTr(AAAI 2022):基于 Transformer 的端到端文档矫正网络。
2. 文本检测
- CTPN(Connectionist Text Proposal Network):基于 Faster R-CNN 的文本行检测。
- DBNet(AAAI 2020):动态阈值二值化检测,支持弯曲文本。
- Mask TextSpotter(ECCV 2018):实例分割模型检测任意形状文本。
3. 文本识别
- CRNN(2015):CNN + RNN + CTC 的经典架构。
- Transformer OCR(2021):基于自注意力机制,支持多语言长文本。
- SVTR(CVPR 2022):单视觉模型,无需 RNN 即可捕捉上下文。

三、性能最佳算法:PaddleOCR v3✨✨
算法原理
PaddleOCR 是百度开源的 OCR 工具库,其 v3 版本在精度和速度上均达到业界领先水平:
-
文本检测(DB++):
- 动态阈值学习:通过可微分二值化(Differentiable Binarization)提升小文本检测精度。
- 轻量级骨干网络:采用 MobileNetV3 优化推理速度(<50ms / 图)。
-
文本识别(SVTR-Large):
- 视觉 - 语义联合建模:通过混合 CNN-Transformer 结构捕捉全局上下文。
- 多语言支持:支持 80 + 种语言(包括中文、阿拉伯语等复杂文字)。
四、数据集与下载链接✨✨
1. 文档矫正数据集
- Doc3D(合成文档数据集)
- 下载链接:Doc3D Dataset
- 内容:10 万 + 带 3D 形变标注的文档图像。
2. 文本检测与识别数据集
- ICDAR 2015(自然场景文本)
- 下载链接:ICDAR 2015
- SROIE(扫描票据数据集)
- 下载链接:SROIE on Kaggle
- FUNSD(表单理解数据集)
- 下载链接:FUNSD on GitHub
3. 合成数据工具
- TextRecognitionDataGenerator
- 代码库:GitHub - TRDG
五、代码实现(基于 PaddleOCR)✨✨
1. 环境安装
pip install paddlepaddle paddleocr2. 文档扫描与 OCR
from paddleocr import PaddleOCR
import cv2
# 初始化模型
ocr = PaddleOCR(use_angle_cls=True, lang='ch', use_gpu=False)
# 文档扫描与识别
def scan_and_ocr(image_path):
# 1. 文档矫正(PaddleOCR内置检测模型)
img = cv2.imread(image_path)
result = ocr.ocr(img, cls=True)
# 2. 输出结果
for line in result:
text = line[1][0]
confidence = line[1][1]
print(f"文本: {text}, 置信度: {confidence:.2f}")
# 示例
scan_and_ocr('invoice.jpg')3. 输出示例
文本: 发票代码: 144031800111, 置信度: 0.98
文本: 金额: ¥5,200.00, 置信度: 0.95 六、优秀论文推荐✨✨
-
《PaddleOCR: A Practical Ultra Lightweight OCR System》(2021)
- 链接:arXiv:2009.09941
- 亮点:详述 PaddleOCR 的轻量化设计与多语言优化。
-
《DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction》(AAAI 2022)
- 链接:arXiv:2110.14942
- 亮点:基于 Transformer 的端到端文档矫正模型。
-
《SVTR: Scene Text Recognition with a Single Visual Model》(CVPR 2022)
- 链接:arXiv:2203.12945
- 亮点:去除了 RNN,提升长文本识别效率。
七、具体应用✨✨
1. 企业财务自动化
- 案例:用 OCR 识别发票代码、金额、税号,自动录入 ERP 系统。
- 技术栈:PaddleOCR + 规则引擎(校验发票真伪)。
2. 移动端证件识别
- 案例:银行 APP 扫描身份证,自动填充姓名、身份证号。
- 优化点:模型量化(TensorFlow Lite) + 活体检测。
3. 古籍数字化
- 案例:故宫博物院古籍扫描,识别繁体字并生成电子档案。
- 挑战:复杂版式解析 + 古文字字符集扩展。

八、未来研究方向✨✨
-
低资源语言支持
- 开发适用于小语种(如藏文、彝文)的 OCR 模型。
-
3D 文档处理
- 结合 NeRF 技术复原褶皱、卷曲文档的文本内容。
-
多模态理解
- 联合解析文本、表格、图表(如医疗报告结构化)。
-
隐私保护
- 联邦学习框架下的 OCR 模型训练(如医院数据不出院)。
-
实时视频 OCR
- 动态视频流中的文本跟踪与识别(如路牌实时翻译)。

结语✨✨
文档扫描与 OCR 技术正从 “能用” 向 “好用” 快速演进,未来随着多模态大模型(如 GPT-4V)的融合,其理解能力将进一步提升。开发者可借助 PaddleOCR 等开源工具快速落地应用,同时关注 3D 重建、低资源学习等前沿方向,开拓更广阔的工业场景。
