摘要:我们的研究表明,将强化学习应用于大型语言模型(LLMs)能显著提升复杂编码和推理任务的性能。此外,我们将两个通用推理模型——OpenAI的o1模型和o3模型的一个早期检查点——与一个特定领域的系统o1-ioi进行了比较。o1-ioi采用了为参加2024年国际信息学奥林匹克竞赛(IOI)而手工设计的推理策略。我们使用o1-ioi实时参加了2024年IOI竞赛,并凭借手工制定的测试时策略取得了第49百分位的成绩。在放宽比赛约束的条件下,o1-ioi获得了金牌。然而,在评估后续模型(如o3)时,我们发现o3无需手工制定的领域特定策略或放宽约束即可获得金牌。我们的研究结果表明,尽管像o1-ioi这样的专用流程带来了显著的改进,但扩展后的通用o3模型在不依赖手工推理启发式方法的情况下超越了这些结果。值得注意的是,o3在2024年IOI中获得了金牌,并且在Codeforces平台上的评分与顶尖人类选手相当。总体而言,这些结果表明,扩展通用强化学习,而非依赖领域特定技术,为在推理领域(如竞技编程)实现最先进的人工智能提供了一条稳健的途径。Huggingface链接:Paper page,论文链接:2502.06807
1. 引言
竞技编程的挑战:
- 竞技编程被广泛认为是评估推理和编码能力的一项具有挑战性的基准测试。解决复杂的算法问题需要高级的计算思维和问题解决技能。
- 这些问题具有客观的可评估性,使其成为评估AI系统推理能力的理想测试平台。
大型语言模型在编程中的应用:
- 近期关于使用大型语言模型(LLMs)进行程序合成的研究表明,即使是参数范围从2.44亿到1370亿的相对通用的模型,也能根据自然语言指令生成简短的Python脚本。
- 模型的性能随着其规模的增加而呈对数线性增长,且通过微调可以显著提高准确性。
强化学习在LLMs中的应用:
- Codex是一个早期的专注于代码的LLM,在Python程序生成方面表现出色,并推动了GitHub Copilot的发展。
- AlphaCode系统通过大规模代码生成和推理时的启发式方法解决了竞技编程任务,其后续版本AlphaCode2的改进几乎使解决的问题数量翻倍,并在Codeforces平台上达到了85百分位。
2. OpenAI o1模型
o1模型的训练与特点:
- OpenAI的o1是第一个大型推理模型,使用强化学习来解决复杂的推理任务。
- o1通过生成扩展的内部思维链来回答问题,类似于人类逐步解决挑战性问题的过程。
- 强化学习精炼了这种思维链过程,帮助模型识别并纠正错误,将复杂任务分解为可管理的部分,并在一种方法失败时探索替代解决方案路径。
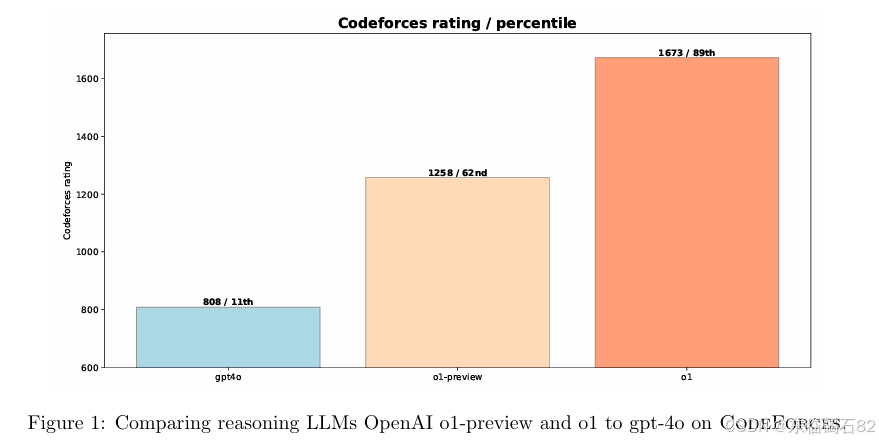
Codeforces基准测试:
- Codeforces是一个国际性的编程竞赛网站,我们模拟了Codeforces竞赛来评估模型的竞技编程能力。
- 相比非推理LLM(gpt-4o)和早期推理模型(o1-preview),o1在Codeforces上的表现显著提升,达到了89百分位。
3. OpenAI o1-ioi模型
针对IOI的微调与策略:
- 为了参加2024年IOI,我们开发了o1-ioi系统,该系统在o1的基础上进行了针对编码任务的额外强化学习训练。
- o1-ioi还融入了为竞技编程设计的专用测试时推理策略,这些策略类似于AlphaCode系统中使用的策略。
编码强化学习微调:
- 我们从o1的检查点开始恢复强化学习训练,特别强调了具有挑战性的编程问题,以帮助模型改进C++代码生成和运行时检查。
- 通过指导模型以IOI提交格式输出结果,o1-ioi能够在推理过程中编写和执行C++程序。
测试时策略:
- o1-ioi将每个IOI问题分解为子任务,为每个子任务从模型中采样10,000个解决方案,并采用基于聚类和重排名的方法来决定提交哪些解决方案。
- 该策略基于模型生成的测试输入对解决方案进行聚类,并根据学习到的评分函数、模型生成测试输入上的错误以及提供的公共测试用例的失败情况对解决方案进行评分。
Codeforces与IOI表现:
- 在Codeforces基准测试中,o1-ioi的表现优于93%的竞争对手,通过完整的测试时策略进一步将性能提升至98百分位。
- 在2024年IOI实时竞赛中,o1-ioi在10小时内解决了六个算法问题,使用测试时选择策略获得了213分,位于第49百分位。在放宽提交限制至10,000个解决方案后,o1-ioi的得分提升至362.14分,超过了金牌门槛。
4. OpenAI o3模型
强化学习的进一步应用:
- 在o1和o1-ioi的基础上,我们探索了仅依赖强化学习训练而不依赖人工设计的测试时策略的性能极限。
- o3模型通过进一步的强化学习训练,能够在没有人工干预的情况下自主开发和执行测试时推理策略。
Codeforces与IOI表现:
- 在Codeforces基准测试中,o3的表现显著优于o1和o1-ioi,达到了99.8百分位。
- 在回顾性评估中,o3在2024年IOI问题上的表现也优于o1-ioi,即使在50个提交的限制下也获得了395.64分,超过了金牌门槛。
o3的推理策略:
- o3在测试时展示了复杂的推理策略,例如为验证输出而编写简单的暴力解决方案,然后与更优化的算法实现进行交叉检查。
- 这种自我施加的验证机制使o3能够捕获潜在错误并提高解决方案的可靠性。
5. 软件工程评估
HackerRank Astra数据集:
- HackerRank Astra数据集包含65个面向项目的编码挑战,旨在模拟真实的软件开发任务。
- 在该数据集上的评估表明,o1和o3模型的推理能力不仅提高了算法问题解决能力,还扩展到了更实际的行业相关编码任务。
SWE-Bench Verified基准测试:
- SWE-Bench Verified是OpenAI的一个经过人类验证的SWE-Bench子集,用于更可靠地评估AI模型解决现实世界软件问题的能力。
- o1和o3模型在该基准测试上的表现优于gpt-4o,特别是o3模型通过显著的增强训练资源实现了22.8%的性能提升。
6. 结论
推理在编码任务中的重要性:
- 我们的研究表明,思维链推理是提高编码任务性能的一种强大策略,从Codeforces和IOI等竞技编程基准测试到SWE-Bench和Astra等复杂的软件工程挑战均有所体现。
强化学习的扩展:
- 增加强化学习训练计算量,并结合增强的测试时计算量,能够持续提高模型性能,使其几乎达到世界上最优秀的人类水平。
o系列大型推理模型的未来:
- 我们相信,o系列大型推理模型将为科学、编码、数学等许多领域的人工智能解锁许多新的用例。
7. 方法论细节
数据准备与模型训练:
- 数据准备涉及从Codeforces和IOI等来源收集问题,并使用OpenAI的嵌入API进行污染检查,以确保测试问题在训练期间未被模型看到过。
- 模型训练包括使用强化学习来精炼模型的推理过程,并通过外部工具(如代码解释器)进行验证。
评估方法:
- 我们模拟了Codeforces竞赛来评估模型的性能,包括使用完整的测试套件、施加适当的时间和内存限制,并根据AlphaCode的方法允许模型进行多次提交。
- 对于IOI,我们严格遵循官方规则,限制每个问题最多提交50个解决方案,并在提交前使用学习到的评分函数和模型生成的测试输入对解决方案进行排名。
8. 具体案例与代码示例
IOI 2024解决方案示例:
- 论文中提供了o1-ioi和o3在IOI 2024上解决的具体问题的代码示例,如“Nile”、“Message”和“Tree”等。
- 这些示例展示了模型如何解决复杂的算法问题,包括通过联合查找结构、二分搜索和动态规划等技术来优化解决方案。
9. 未来展望
模型扩展与应用:
- 随着计算资源的不断增加和强化学习技术的持续发展,我们预期大型推理模型的能力将进一步提升。
- 这些模型有望在更多领域得到应用,包括自动化软件开发、科学研究和复杂系统建模等。
挑战与限制:
- 尽管取得了显著进展,但大型推理模型仍面临一些挑战,如处理长期依赖、解释模型决策和确保模型的可靠性与安全性。
- 未来的研究将致力于解决这些问题,并推动人工智能技术的进一步发展。