摘要:我们隆重推出Qwen2.5-VL,这是Qwen视觉-语言系列的最新旗舰模型,它在基础能力和创新功能方面都取得了显著进步。Qwen2.5-VL通过增强的视觉识别、精确的目标定位、强大的文档解析以及长视频理解能力,实现了在理解和与世界互动方面的重大飞跃。Qwen2.5-VL的一个突出特点是其能够使用边界框或点准确地定位目标。它能够从发票、表格和表单中稳健地提取结构化数据,并对图表、示意图和布局进行详细分析。为了处理复杂输入,Qwen2.5-VL引入了动态分辨率处理和绝对时间编码技术,使其能够处理不同尺寸的图像和长达数小时的视频,并实现秒级事件定位。这使得模型能够在不依赖传统归一化技术的情况下,原生地感知空间尺度和时间动态。我们通过从头训练一个原生动态分辨率的视觉变换器(ViT),并结合窗口注意力机制,在保持原生分辨率的同时降低了计算开销。因此,Qwen2.5-VL不仅在静态图像和文档理解方面表现出色,还作为一个交互式视觉代理,能够在操作计算机和移动设备等现实世界场景中进行推理、工具使用和任务执行。Qwen2.5-VL提供三种不同规模的模型,以满足从边缘AI到高性能计算的多样化应用场景。旗舰版Qwen2.5-VL-72B模型与GPT-4o和Claude 3.5 Sonnet等最先进的模型相媲美,尤其在文档和图表理解方面表现卓越。此外,Qwen2.5-VL还保持了稳健的语言性能,保留了Qwen2.5大语言模型(LLM)的核心语言能力。Huggingface链接:Paper page,论文链接:2502.13923
一、引言
- Qwen2.5-VL模型发布:Qwen团队在阿里巴巴集团发布了其最新的旗舰模型Qwen2.5-VL,这是Qwen视觉-语言系列更新的一个,重大标志着在基础能力和创新功能方面的显著提升。
- 多模态理解的重要性:随着大型视觉-语言模型(LVLMs)的发展,多模态理解成为人工智能领域的一个关键突破。这些模型能够无缝集成视觉感知与自然语言处理,从而重塑机器跨领域复杂信息的解释和分析方式。
- Qwen2.5-VL的目标:Qwen2.5-VL旨在通过增强的视觉识别、精确的目标定位、强大的文档解析以及长视频理解能力,实现与世界更深入的交互和理解。
二、模型架构与技术创新
- 模型架构概述:Qwen2.5-VL模型架构由三个主要部分组成:大型语言模型(LLM)、视觉编码器(Vision Encoder)以及基于多层感知机(MLP)的视觉-语言合并器(Vision-Language Merger)。
- 视觉编码器优化:
- 窗口注意力机制:为了优化推理效率,视觉编码器在大多数层中引入了窗口注意力机制,确保计算成本随图像块数量线性增长而非二次增长。
- 2D RoPE与3D补丁划分:采用2D RoPE来有效捕捉二维空间中的空间关系,并为视频输入扩展到3D补丁划分,显著减少输入语言模型的令牌数量。
- RMSNorm与SwiGLU:采用RMSNorm进行归一化,并使用SwiGLU作为激活函数,这些选择增强了计算效率和视觉与语言组件之间的兼容性。
- 动态分辨率处理与绝对时间编码:
- 动态分辨率处理:Qwen2.5-VL能够处理不同尺寸的图像,并在保持原生分辨率的同时进行推理,避免了不必要的缩放或失真。
- 绝对时间编码:通过引入与绝对时间对齐的MRoPE,模型能够更好地理解视频内容的时间动态,如事件的速度和精确时刻定位。
- 多模态Rotary位置嵌入:扩展了MRoPE的能力,以更好地处理视频中的时间信息,通过时间ID的间隔来理解不同帧率视频之间的一致时间对齐。
三、数据预训练与训练策略
- 预训练数据集的扩展:
- 数据集规模:与Qwen2-VL相比,Qwen2.5-VL的预训练数据集显著扩展,从1.2万亿令牌增加到约4万亿令牌。
- 数据多样性:数据集涵盖了广泛的多模态数据,包括图像字幕、交错的图像-文本数据、光学字符识别(OCR)数据、视觉知识、多模态学术问题、定位数据、文档解析数据、视频描述、视频定位以及基于代理的交互数据。
- 数据清洗与评分系统:
- 数据清洗流程:通过标准数据清洗和内部评估模型的四阶段评分系统,确保仅使用高质量、相关的交错数据。
- 评分标准:包括文本质量、图像-文本相关性、信息互补性和信息密度平衡,以提高模型进行复杂推理和生成连贯多模态内容的能力。
- 训练阶段:
- 视觉预训练:首先仅训练视觉变换器(ViT),以提高其与语言模型的对齐能力。
- 多模态预训练:然后解冻所有模型参数,在多种多模态图像数据上训练模型,增强其处理复杂视觉信息的能力。
- 长上下文预训练:最后,通过增加序列长度,进一步提高模型对更长序列的推理能力,以处理需要长范围依赖和复杂推理的任务。
四、后训练优化
- 监督微调(SFT):
- 目标:通过有针对性的指令优化,弥合预训练表示与下游任务需求之间的差距。
- 数据集:采用约200万条条目的精心策划的数据集,包括纯文本数据和多模态数据(如图像-文本和视频-文本组合)。
- 数据过滤管道:
- 阶段1:领域特定分类:使用Qwen2-VL-Instag对问答对进行层次分类,以便进行领域感知和子领域感知的数据过滤。
- 阶段2:领域定制过滤:结合规则基和模型基方法,针对不同领域(如文档处理、OCR和视觉定位)的特定特性优化数据质量。
- 拒绝采样与增强推理:
- 方法:通过拒绝采样策略,仅保留模型输出与预期答案匹配的样本,以提高数据质量和模型的推理能力。
- 应用:特别适用于需要复杂推理的任务,如数学问题解决、代码生成和领域特定的视觉问答(VQA)。
- 直接偏好优化(DPO):
- 目标:通过偏好数据对齐模型与人类偏好,专门关注图像-文本和纯文本数据,以优化跨模态推理和特定任务性能。
五、模型性能评估
- 与最先进模型的比较:
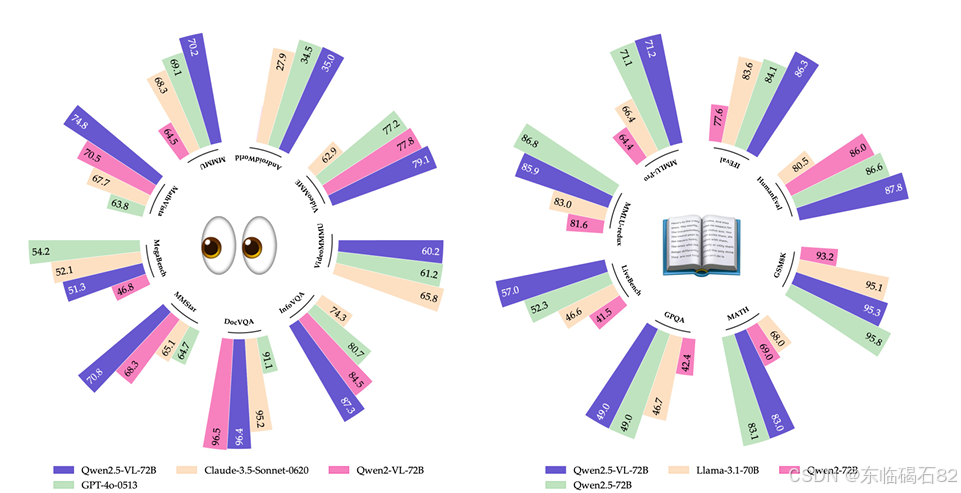
- 大学水平问题:在MMMU数据集上,Qwen2.5-VL-72B模型的得分为70.2,超过了之前的开源最先进模型,并与GPT-4o的性能相当。
- 数学任务:在MathVista和MATH-Vision数据集上,Qwen2.5-VL-72B分别取得了74.8和38.1的分数,展示了强大的数学推理能力。
- 一般视觉问答:在多个基准数据集(如MMBench系列、MMStar、MME等)上,Qwen2.5-VL-72B均表现出色,尤其在多语言和多图像理解任务中。
- 纯文本任务性能:
- 评估基准:在MMLU-Pro、LiveBench-0831、GPQA、MATH、GSM8K等基准上,Qwen2.5-VL模型展示了与类似大小的LLM相当的甚至更优的性能。
- 定量结果:
- 视觉问答:在MMBench-EN-V1.1、MMStar等数据集上,Qwen2.5-VL-72B取得了领先的准确率。
- 文档理解和OCR:在OCRBench、InfoVQA、SEED-Bench-2-Plus等基准上,Qwen2.5-VL模型在文档理解和OCR相关任务中表现出色。
- 空间理解:在指代表达理解基准(如Refcoco)和目标检测基准(如ODinW)上,Qwen2.5-VL展示了精确的目标定位和计数能力。
- 视频理解和定位:在LVBench、MLVU和Charades-STA等视频基准上,Qwen2.5-VL-72B在视频理解和事件定位任务中取得了显著优于其他模型的结果。
- 代理功能:在GUI代理基准(如ScreenSpot、Android Control等)上,Qwen2.5-VL-72B展示了出色的UI元素定位和任务执行能力。
六、结论
- Qwen2.5-VL的成就:Qwen2.5-VL作为Qwen视觉-语言系列的最新旗舰模型,在视觉识别、目标定位、文档解析和视频理解方面取得了重大进展。
- 技术创新:通过动态分辨率处理、绝对时间编码和窗口注意力机制等技术创新,Qwen2.5-VL能够在保持高效计算的同时,处理复杂的多模态输入。
- 广泛应用:Qwen2.5-VL提供三种不同规模的模型,适用于从边缘AI到高性能计算的多样化应用场景,展示了在文档和图表理解、纯文本任务以及现实世界场景中的交互代理功能方面的卓越性能。
- 未来展望:Qwen2.5-VL的发布为视觉-语言模型树立了新的基准,其技术创新为更智能和交互式的系统铺平了道路,桥梁感知与现实世界应用。
七、作者贡献
- 核心贡献者:报告列出了对Qwen2.5-VL开发做出核心贡献的团队成员,包括Shuai Bai、Keqin Chen、Xuejing Liu等。
- 其他贡献者:此外,还有多位贡献者参与了项目的不同方面,包括数据收集、模型训练和优化等。
八、参考文献
- 广泛引用:报告引用了大量相关文献,涵盖了视觉-语言模型、多模态学习、数据增强、模型优化等多个领域的研究成果,展示了Qwen2.5-VL开发背后的深厚学术基础。
Qwen2.5-VL技术报告详细介绍了该模型的架构、技术创新、数据预训练策略、后训练优化方法以及性能评估结果。通过引入动态分辨率处理、绝对时间编码和窗口注意力机制等技术,Qwen2.5-VL在保持高效计算的同时,显著提升了多模态理解和交互能力。报告还通过广泛的实验评估,验证了Qwen2.5-VL在多个基准数据集上的卓越性能,展示了其在视觉识别、目标定位、文档解析和视频理解等方面的领先地位。此外,报告还强调了Qwen2.5-VL的广泛应用前景和未来发展方向,为视觉-语言模型的研究和应用提供了新的思路和方向。