一、 人工神经网络
人工神经网络(artificial neural network, ANN)是模拟人脑神经系统实现人工智能的一种途径。
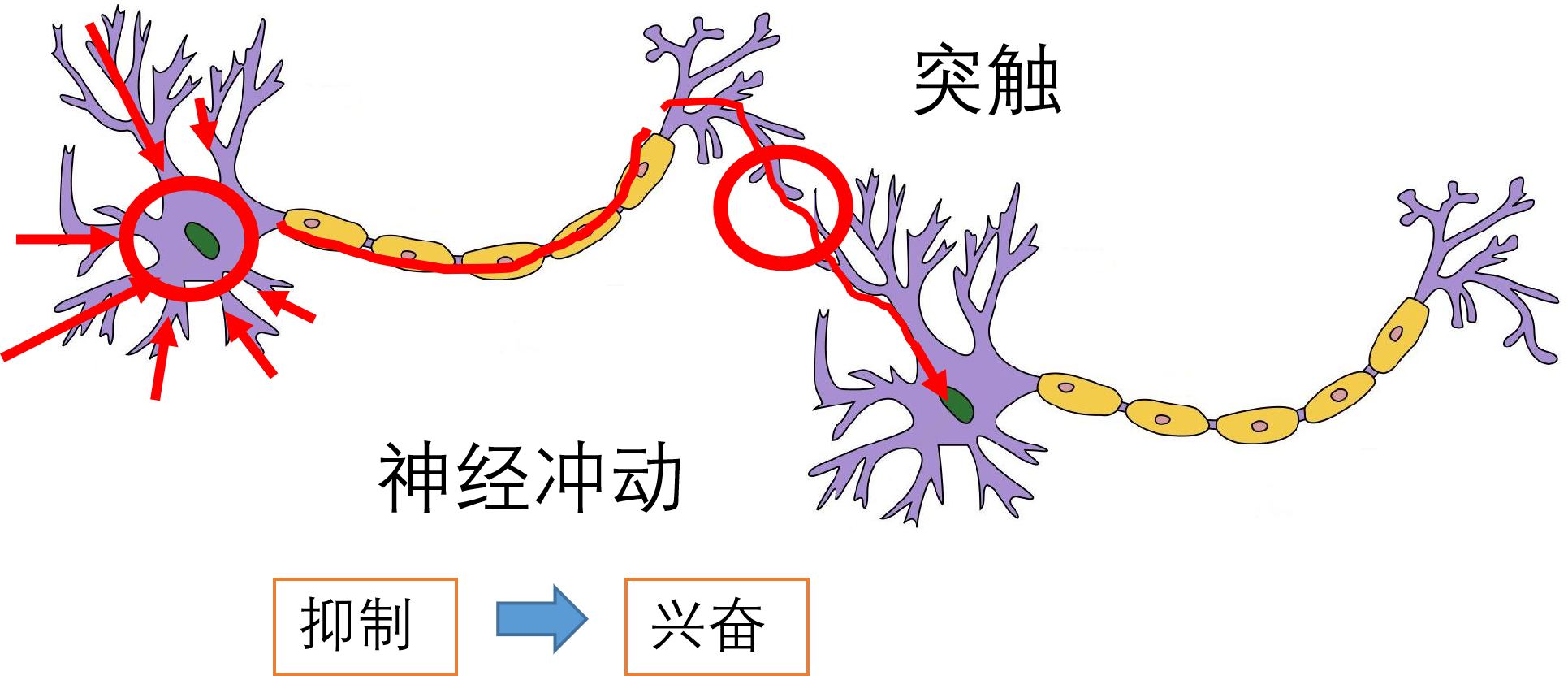
1 生物神经元
研究表明人类大脑大约有1.410^11个神经细胞(神经元)。 每个神经元有数以千计通道同其它神经元相互连接接,形成复杂生物神经网络。
|
1890年,詹姆斯首次阐明人脑结构及功能,及记忆、学习、联想的规律。这种生物神经网络以神经元为基本信息处理单元,对信息进行分布式存储与加工,这种信息加工与存储相结合的群体协同工作方式使得人脑呈现出目前计算机无法模拟的神奇智能。
2 MP模型
为模拟人脑形象思维,不得不跳出冯.诺依曼计算机的框架另辟蹊径,而从模拟人脑生物神经网络的信息存储、加工处理机制入手,设计具有人类思维特点的智能机器,因此也迎来了模拟生物神经元的人工神经元-MP模型的诞生。
第一个1943年,心理学家warren McCulloch麦卡洛克和数理逻辑学家Walter Pitts提出了提出了人工神经元的第一个模型,称为M-P模型。
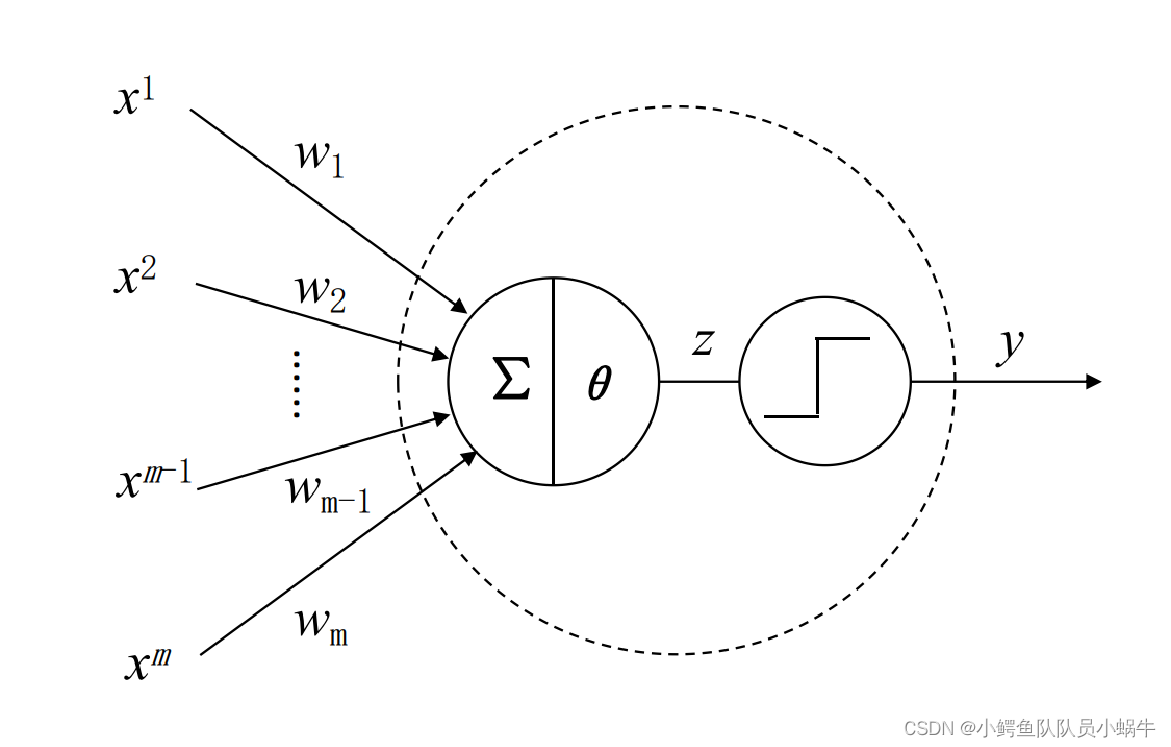
|
MP神经元的数学形式表述如下 :
z
=
∑
j
=
1
j
=
m
w
j
x
j
−
θ
z=\sum_{j=1}^{j=m}w_jx^j-\theta
z=j=1∑j=mwjxj−θ
y
=
s
t
e
p
(
z
)
{
0
,
z
<
0
1
,
z
≥
0
y=step(z) ~~\lbrace_{0 , z<0}^{1, z\ge0}
y=step(z) {0,z<01,z≥0
y
=
s
t
e
p
(
∑
j
=
1
j
=
m
w
j
x
j
−
θ
)
y=step(\sum_{j=1}^{j=m}w_jx^j-\theta)
y=step(j=1∑j=mwjxj−θ)
令
w
0
=
−
θ
,
x
0
=
1
令w_0=-\theta,~~~x^0=1
令w0=−θ, x0=1
y
=
s
t
e
p
(
w
0
x
0
+
w
1
x
1
+
.
.
.
.
.
.
+
w
m
x
m
)
~~~~~~~~y=step(w_0x^0+w_1x^1+......+w_mx^m)
y=step(w0x0+w1x1+......+wmxm)
=
s
t
e
p
(
W
∗
X
T
)
=step(W*X^T)
=step(W∗XT)
其中,
W
=
[
w
0
,
w
1
,
.
.
.
.
.
.
,
w
m
]
其中,W=[w_0,w_1,......,w_m]
其中,W=[w0,w1,......,wm]
X
=
[
x
0
,
x
1
,
.
.
.
.
.
.
,
x
m
]
X=[x^0,x^1,......,x^m]
X=[x0,x1,......,xm]
和生物神经元结构进行对比,不难发现:MP模型的输入信号
X
X
X模拟生物神经元的树突,权值表示神经元来源不同而对神经元产生的影响程度。计算单元模拟生物神经元中细胞核,对接受到属于信号加权求和之后,与产生输出兴奋的阈值相比较,得到中间结果
Z
Z
Z,最后通过阶跃函数模拟神经兴奋状态。
Z
Z
Z小于0,表示抑制状态,输出0;如果Z大于等于零,神经元被激活,处于兴奋状态,输出1。这个阶跃函数被称为激活函数或激励函数。输出
Y
Y
Y模拟生物神经元中轴突。从而实现了将神经元的输出信号传递给其他神经元。
3 神经网络的两个核心问题
MP本质是对多个输入信号加权整合之后通过阈值激活输出,其权值向量W无法自动学习和更新,不具备学习的能力。然而机器学习任务是计算机通过数据集学习出人工神经网络模型,因此人工神经网络必须解决一下两个核心问题:(1)如何连接神经元从而构成的人工神经网络模型的结构?
(2) 如何通过规则或者算法实现人工神经网络结构权值等参数如何学习?
生理心理学家唐纳德赫布(Donald Hebb)心理学家罗森伯特(Rosenblatt)分别与1949年和1957年提出了著名的赫布律和感知机模型。赫布律在神经网络学习算法上的重要基石;感知机是用算法来第一个精确定义算法的神经网络模型,它实现了二分类的线性分类器。在二维三维和高维空间中,分别对应直线、平面和超平面。感知机算法框架构建了机器学习框架,这一框架包括了所有分类、回归、及强化学习等领域问题。罗森伯特(Rosenblatt)成为构建机器学习构架第一人。
下面就赫布律和感知机进行描述。
二、 赫布律
唐纳德.赫布(Donald Hebb)1949年在《The organization of Behavior》书中说道:当A细胞突出和B细胞足够近,并重复或不断对其放电时,A,B中的一个细胞或者两个细胞都会经历生长过程或者代谢改变,这样A细胞(作为B细胞放电的细胞之一)的效率就会得到提高“。
赫布认为:大脑的学习过程就是通过神经元之间突触的形成连接和强度的变化来实现的。两个神经细胞交流越多,他们之间连接就越强。
 Hebb学习规则给人们指出:人脑在学习知识经验的过程本质在是在不断塑造改变突触连接的过程。
三 感知机
1 模型架构
1957年,心理学家罗森伯特(Rosenblatt)从纯数学角度重新考察MP模型:如果将MP模型看出黑盒子。神经元的输入向量
x
i
,
对应输出向量
t
i
x_i,对应输出向量t_i
xi,对应输出向量ti, 网络实际输出向量记作
y
i
y_i
yi.若能够设计一个算法,自动调整网络参数,那么,机器学习就是可行的。为此,罗森伯特(Rosenblatt)提出感知器(Perceptron)的人工网络架构及其训练算法。如下图所示:
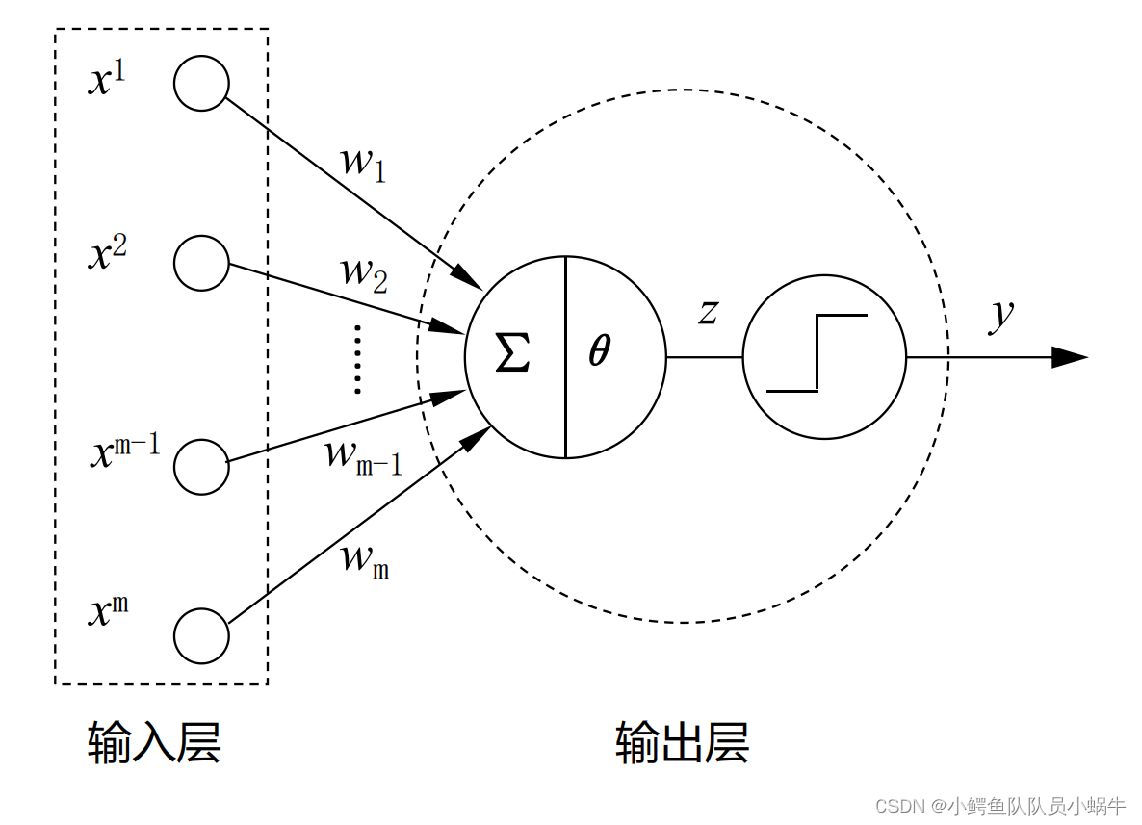
|
感知机输入层接受外界信号,输出层为MP神经元。每一个圆圈表示一个神经元,也称为节点。输出层神经元是发生计算的功能神经元,而输入层不参与计算。从这个角度,感知机可看出是一个单层神经网络。
2 学习算法
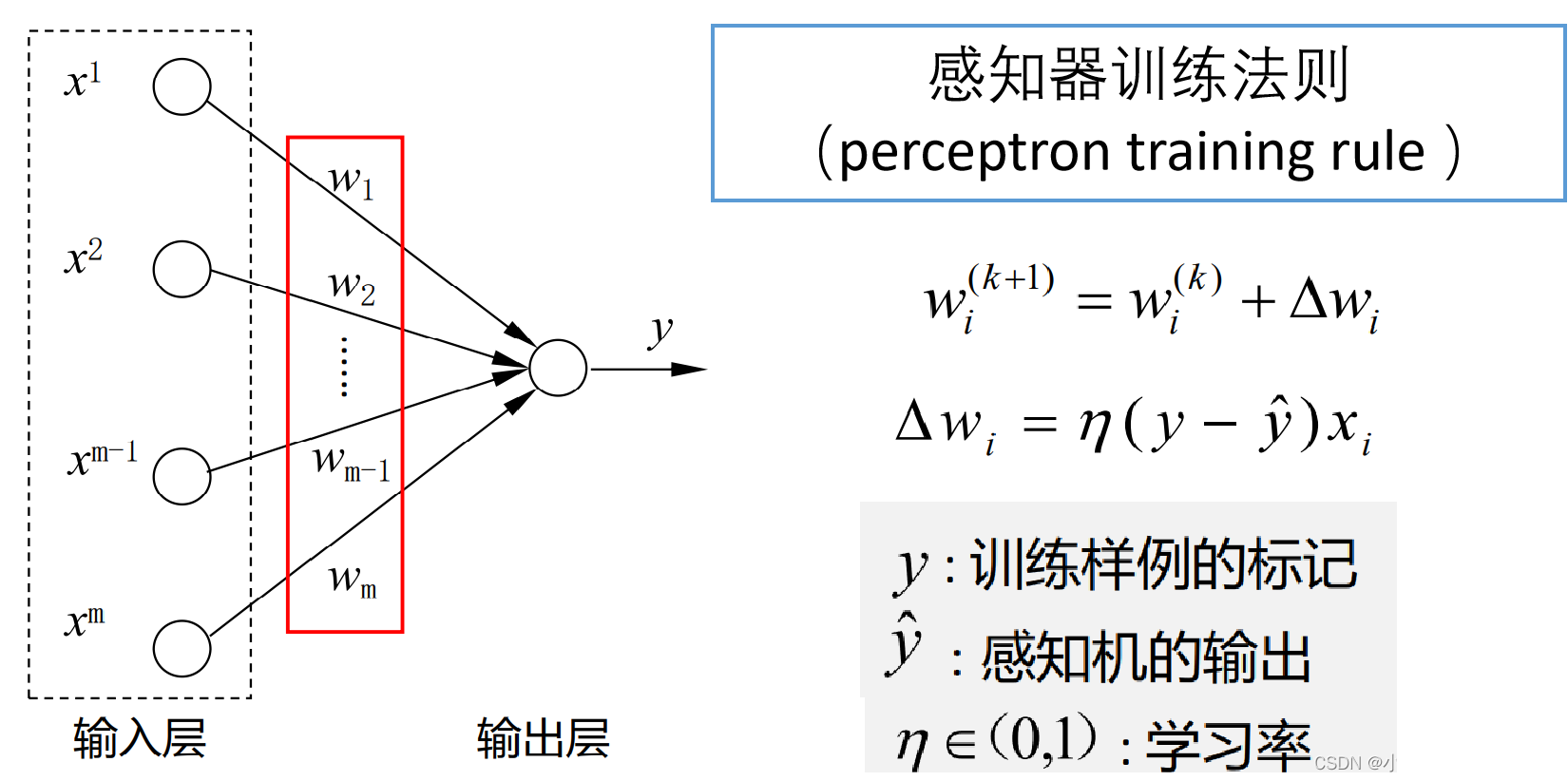
|
运用梯度下降法实现感知机
W
,
b
W,b
W,b参数学习算法如下:
*输入:m个样本数据集(x(i),y(i)),学习率
η
∈
(
0
,
1
)
\eta\in(0,1)
η∈(0,1);
输出:
W
,
b
W,b
W,b
step1: 对
W
,
b
W,b
W,b随机赋予初始值,这是对应的分隔直线;
step2:依次计算每个样本估算值,并视情进行
W
,
b
W,b
W,b更新,计算步 骤如下:
do while
(
i
<
m
+
1
)
(i<m+1)
(i<m+1)
i
f
y
(
i
)
=
f
(
w
∗
x
(
i
)
T
+
b
)
:
~~~~if~~~~ y^{(i)}=f(w*x^{{(i)}^T}+b):
if y(i)=f(w∗x(i)T+b):
标记有样本估算错误
~~~~~~~~~~~标记有样本估算错误
标记有样本估算错误
w
:
=
w
+
η
(
y
(
i
)
−
f
(
w
∗
x
(
i
)
T
+
b
)
)
x
(
i
)
;
~~~~~~~~~~~~w:=w+\eta (y^{(i)}-f(w*x^{{(i)}^T}+b))x^{(i)};
w:=w+η(y(i)−f(w∗x(i)T+b))x(i);
b
:
=
b
+
η
(
y
(
i
)
−
f
(
w
∗
x
(
i
)
T
+
b
)
)
~~~~~~~~~~~~b:=b+\eta (y^{(i)}-f(w*x^{{(i)}^T}+b))
b:=b+η(y(i)−f(w∗x(i)T+b))
3 举例分析
(1)手工推演法求解OR函数值
令:
η
=
0.5
\eta=0.5
η=0.5, 初始赋值:
W
=
[
0
,
0
,
0
]
,
f
为阶跃函数。
W=[0,0,0] , f为阶跃函数。
W=[0,0,0],f为阶跃函数。
为了书写方便,令
w
3
=
b
w_3=b
w3=b
根据或运算法则,容易制作表格如下:
| x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | w 1 w_1 w1 | w 2 w_2 w2 | w 3 = b w_3=b w3=b | z = X . W z=X.W z=X.W | f ( z ) f(z) f(z) | y ( i ) y^{(i)} y(i) |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -1 | 0 | 0 | 0 | 0 | ||
| 0 | 1 | -1 | 1 | |||||
| 1 | 0 | -1 | 1 | |||||
| 1 | 1 | -1 | 1 |
第一轮的第一行计算得:
z
=
X
.
W
=
[
0
,
0
,
−
1
]
.
[
0
,
0
,
0
]
T
=
0
z=X.W=[0, 0 ,-1].[0, 0, 0]^T=0
z=X.W=[0,0,−1].[0,0,0]T=0
f
(
z
)
=
1
f(z)=1
f(z)=1, 故需要进行参数调整。
根据
w
:
=
w
+
η
(
y
(
i
)
−
f
(
w
∗
x
(
i
)
T
+
b
)
)
x
(
i
)
w:=w+\eta (y^{(i)}-f(w*x^{{(i)}^T}+b))x^{(i)}
w:=w+η(y(i)−f(w∗x(i)T+b))x(i)
计算出:
w
1
=
0
+
0.5
∗
(
0
−
1
)
∗
0
=
0
w_1=0+0.5*(0-1)*0=0
w1=0+0.5∗(0−1)∗0=0
w
2
=
0
+
0.5
∗
(
0
−
1
)
∗
0
=
0
w_2=0+0.5*(0-1)*0=0
w2=0+0.5∗(0−1)∗0=0
w
3
=
b
=
0
+
0.5
∗
(
0
−
1
)
∗
(
−
1
)
=
0.5
w_3=b=0+0.5*(0-1)*(-1)=0.5
w3=b=0+0.5∗(0−1)∗(−1)=0.5
更新上述表格参数值:
| x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | w 1 w_1 w1 | w 2 w_2 w2 | w 3 = b w_3=b w3=b | z = X . W z=X.W z=X.W | f ( z ) f(z) f(z) | y ( i ) y^{(i)} y(i) |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 1 | -1 | 0 | 0 | 0.5 | 1 | ||
| 1 | 0 | -1 | 1 | |||||
| 1 | 1 | -1 | 1 |
运用同样法则,继续进行下一个样本的评估和参数训练,可得表格如下:
| x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | w 1 w_1 w1 | w 2 w_2 w2 | w 3 = b w_3=b w3=b | z = X . W z=X.W z=X.W | f ( z ) f(z) f(z) | y ( i ) y^{(i)} y(i) |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 1 | -1 | 0 | 0 | 0.5 | -0.5 | 0 | 1 |
| 1 | 0 | -1 | 0 | 0.5 | 0 | 0 | 1 | 1 |
| 1 | 1 | -1 | 0 | 0.5 | 0 | 0.5 | 1 | 1 |
可以看出,虽然第三和第四个样本估算后的值和标签一致,但是第一个和第二个样本估算后的值和标签不一致。因此,需要在此基础上,从第一个样本开始进行新一轮的评估和参数训练。得到参数结果如表:
| x 1 x_1 x1 | x 2 x_2 x2 | x 3 x_3 x3 | w 1 w_1 w1 | w 2 w_2 w2 | w 3 = b w_3=b w3=b | z = X . W z=X.W z=X.W | f ( z ) f(z) f(z) | y ( i ) y^{(i)} y(i) |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -1 | 0 | 0.5 | 0 | 0 | 1 | 0 |
| 0 | 1 | -1 | 0 | 0.5 | 0.5 | 0 | 1 | 1 |
| 1 | 0 | -1 | 0 | 0.5 | 0.5 | 0 | 1 | 1 |
| 1 | 1 | -1 | 0 | 0.5 | 0 | 0.5 | 1 | 1 |
可以看出,这次虽然第二、三和四样本训练结果符合要求,但第一个样本由偏差,所以,依旧需要重新再开展一轮训练。直到最后输出的所有样本预测结果和实际标签均一致。最终得到结果为:
| x 1 x^1 x1 | x 2 x^2 x2 | x 3 x^3 x3 | w 1 w_1 w1 | w 2 w_2 w2 | w 3 = b w_3=b w3=b | z = X . W z=X.W z=X.W | f ( z ) f(z) f(z) | y ( i ) y^{(i)} y(i) |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -1 | 0.5 | 0.5 | 0.5 | 0 | 1 | 1 |
| 0 | 1 | -1 | 0.5 | 0.5 | 0.5 | 0 | 1 | 1 |
| 1 | 0 | -1 | 0.5 | 0.5 | 0.5 | 0 | 1 | 1 |
| 1 | 1 | -1 | 0.5 | 0.5 | 0 | 0.5 | 1 | 1 |
因此,得到的or的训练模型为:
y
=
s
t
e
p
(
0.5
x
1
+
0.5
x
2
−
0.5
)
y=step(0.5x^1+0.5x^2-0.5)
y=step(0.5x1+0.5x2−0.5)
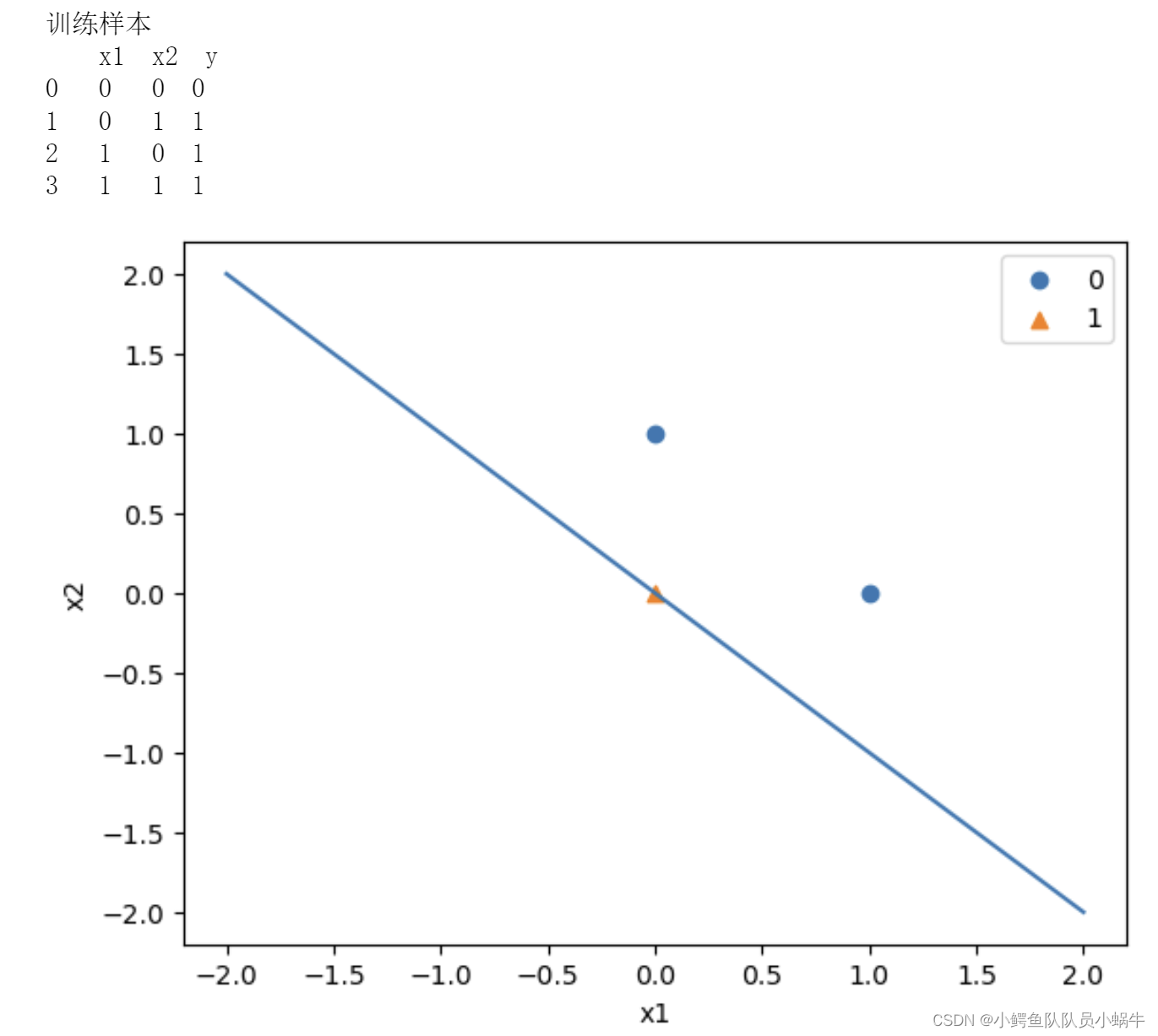
(2)基于python程序实现
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
df=pd.read_csv("D:/ML/3data/or.csv")
print(df)
df.columns= ['x1', 'x2', 'y']
df.y.value_counts()
data = np.array(df.iloc[[0, 1, 2]])
print(data)
X, y = data[:,:-1], data[:,-1]
#将标签记作-1和1
y = np.array([1 if i == 1 else -1 for i in y])
# 此处为一元一次线性方程
class Model:
def __init__(self):
self.w = np.ones(len(data[0])-1, dtype=np.float32)
self.b = 0
self.l_rate = 0.1
# self.data = data
#定义感知机的模型
def sign(self, x, w, b):
y = np.dot(x, w) + b
return y
# 随机梯度下降法
def fit(self, X_train, y_train):
is_wrong = False
while not is_wrong:
is_wrong = True
for i in range(len(X_train)):
if y_train[i] * self.sign(X_train[i],self.w,self.b) < 0:
self.w = self.w + self.l_rate*np.dot(X_train[i],y_train[i])
self.b = self.b + self.l_rate*y_train[i]
is_wrong = False
break
perceptron = Model()
perceptron.fit(X, y)
fig = plt.figure()
x_points = np.linspace(-2, 2,10)
#画出分类线及样本点的散状图
y_= -(perceptron.b+perceptron.w[0]*x_points)/perceptron.w[1]
plt.plot(x_points,y_)
right = plt.scatter(X[:,0][y==1],X[:,1][y==1])
false = plt.scatter(X[:,0][y==-1],X[:,1][y==-1],marker='^')
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend([right,false],['0','1'])
plt.show()
return 'Perceptron Model!'
def score(self):
pass
|
4 补充说明
(1)于线性可分的二类别识别问题,感知机训练算法是收敛的,且多解。
(2)当训练样本集线性不可分时,单个感知机训练法则无法收敛。迭代结果会一直正当震荡。
(3)阶跃函数有不连续,不光滑等性质。实际中,经常使用sigmoid函数作为激活函数,而这就是我们前面说到的逻辑回归。因此,逻辑回归可以看做简单的单层神经网络。
(4)生物神经元改变突触的连接过程就是类似人工神经网络中确定合适的、能符合预期输出与输入的权重参数的过程,在这个过程中人工神经网络能够自动的从数据中学习到合适的权重参数。通过算法自动调整神经元的权值,从而模拟人类神经网络的学习能力,这已成为今天神经网络算法的理论依据。
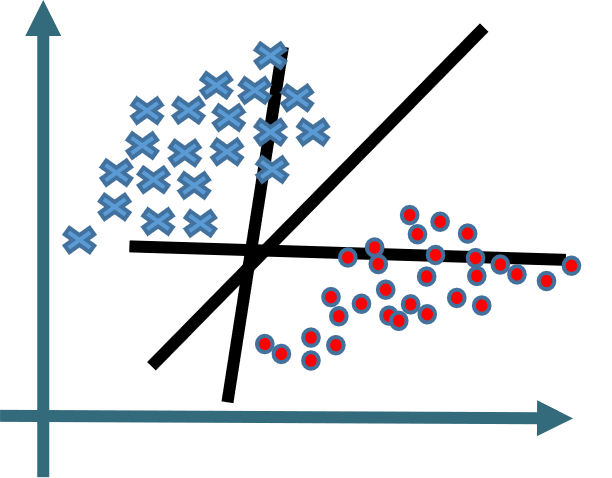
5 单个感知机的瓶颈的解决
如图所示:感知机是可以解决线性可分的问题。
|
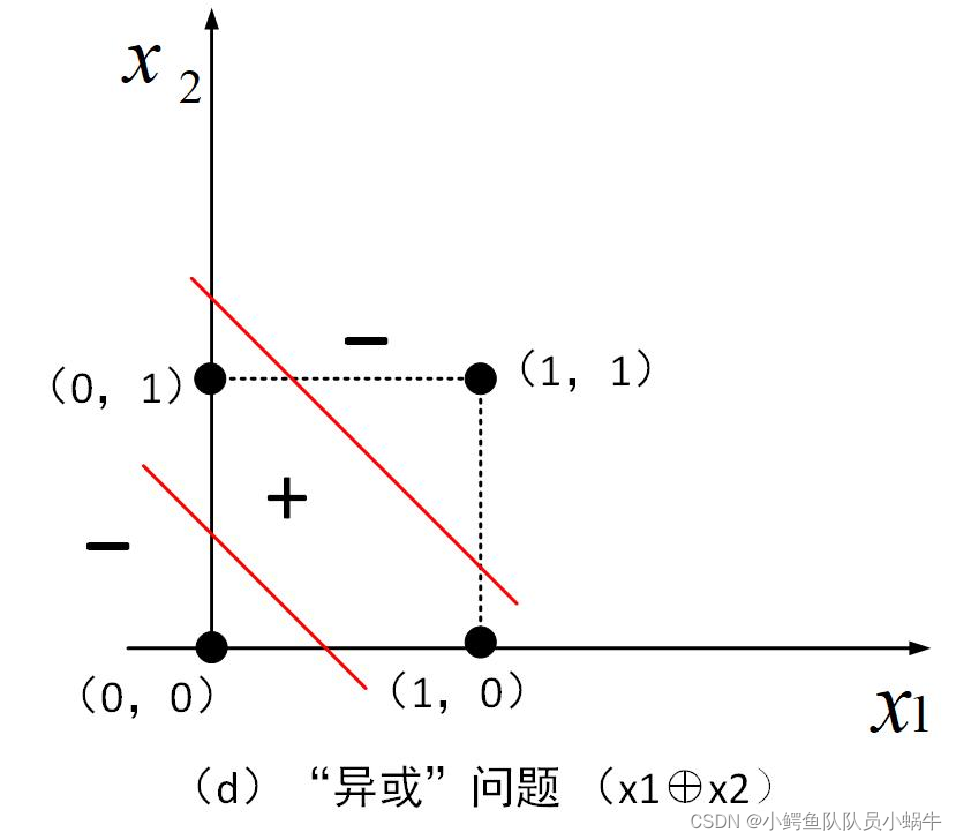
单个感知机只有一个输出节点。只能实现二分类问题。而对异或问题,则需要两条线才能分开。
|
针对上述问题,1969年,明斯基指出神经网络的两个关键难题:(1)感知器无法处理“异或”问题(2)若解决复杂非线性问题,需要复杂神经网络。但大型神经网络需要算力极大,不现实。(在当时技术发展状况下,这个看法有相对的实际性)。
我们知道,任何非线性问题可以线性化处理。如异或问题,可以用两个感知机连接,并通过“与”的算子实现边界的划分。
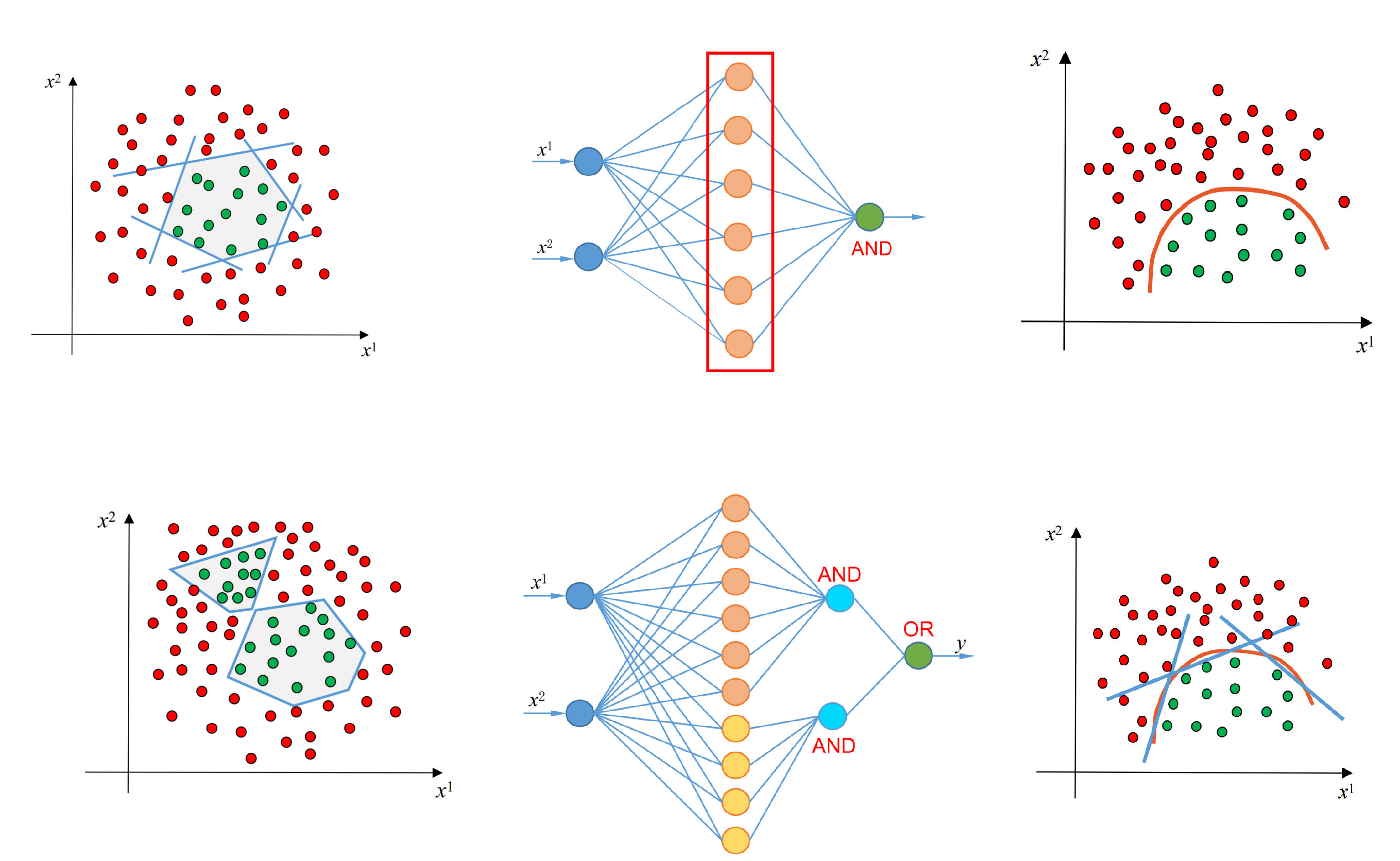
同理,对复杂的非线性边界,可以用多个感知机,并运用“与”和“或”进行连接,从而实现边界分割。如下图示所示,具体这里不再展开,后续可能会继续研讨。
|
问题来了:当多个感知机连接成复杂网络时,其权值参数会井喷式增加,那么,该通过什么方法有效地进行参数训练呢?这就带来了BP算法的提出。BP算法,后面文章将进行描述。