一、生成模型(学习)(Generative Model) vs 判别模型(学习)(Discriminative Model)
结论:贝叶斯分类器是生成模型
1、官方说明
生成模型对联合概率 p(x, y)建模, 判别模型对条件概率 p(y | x)进行建模。
2、通俗理解
生成模型重点在于“生成”过程。比如你想做一道菜,生成模型就像是在研究各种食材(x)和菜的口味(y)同时出现的“配方”,它试图去了解整个“烹饪过程”中,食材和口味是如何一起搭配出现的,是从整体上把握“食材+口味”这个组合出现的概率。
判别模型重点在于评判。还是用做菜举例,判别模型就像是在已经知道食材(x)的情况下,去评判这道菜会是什么口味(y)。它不关心整个“烹饪过程”,只关心在给定食材这个前提下,不同口味出现的可能性,是从结果导向的角度,去判断在x出现的情况下,y出现的概率。
3、举例
以水果分类问题为例
判别学习算法:如果我们要找到一条直线把两类水果分开, 这条直线可以称作边界, 边界的两边是不同类别的水果;
生成学习算法:如果我们分别为樱桃和猕猴桃生成一个模型来描述他们的特征, 当要判断一个新的样本是什么水果时, 可以将该样本带入两种水果的模型, 比较看新的样本是更像樱桃还是更像猕猴桃。
二、生成学习算法
以水果分类问题为例
1、数学符号说明
y = 0:样本是樱桃
y = 1:样本是猕猴桃
p(y):类的先验概率, 表示每一类出现的概率。
p(x | y):样本出现的条件概率
- p(x | y=0)对樱桃的特征分布建模,
- p(x | y=1)对猕猴桃的特征分布建模。
p(y | x):类的后验概率
注:
- 先验概率:就是在没看到具体证据之前,基于已有经验或知识对事件发生概率的初步判断。
- 后验概率:就是在看到具体证据之后,结合先验概率和新证据,对事件发生概率的更新判断。
2、贝叶斯公式
计算出样本属于每一类的概率:
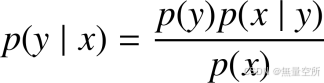
分类问题只需要预测类别, 只需要比较样本属于每一类的概率, 选择概率值最大的那一类即可, 因此, 分类器的判别函数表示为:
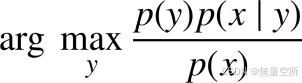
因为p(y)p(x | y)=p(x , y),而p(x)是一个常数,故贝叶斯公式计算公式计算需要p(x , y)值,它对联合概率进行建模, 与生成模型的定义一致, 因此是生成学习算法
三、朴素贝叶斯分类器
假设特征向量的分量之间相互独立
样本的特征向量 x,根据条件概率公式可知该样本属于某一类ci的概率为:
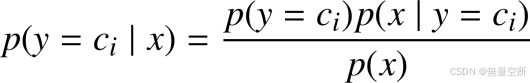
由于假设特征向量各个分量相互独立, 因此有:
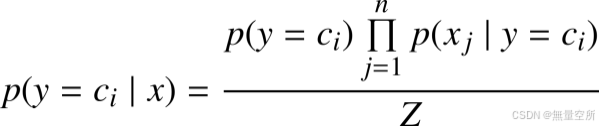
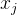
1、离散型特征
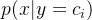
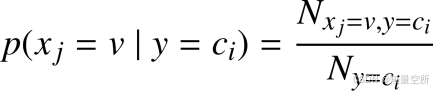
特殊情况
在计算条件概率时, 如果
为 0, 即特征分量的某个取值在某一类训练样本中一次都没出现, 则会导致特征分量取到这个值时的预测函数为 0。 可以使用拉普拉斯平滑(Laplace smoothing) 来处理这种情况。
具体做法就是给分子和分母同时加上一个正整数, 给分子加上 1, 分母加上特征分量取值的 k 种情况,这样就可以保证所有类的条件概率之和还是 1, 并且避免了预测结果为 0 的情况。
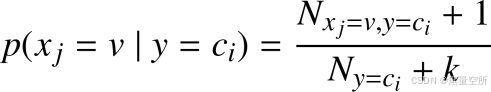
类 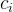
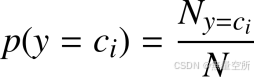
最终分类判别函数可以写成:
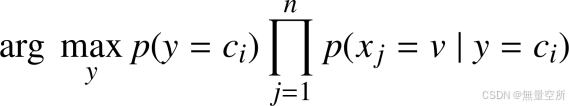
2、连续型特征
假设特征向量的分量服从一维正态分布
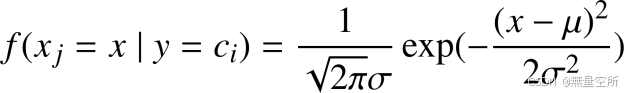
样本属于某一类
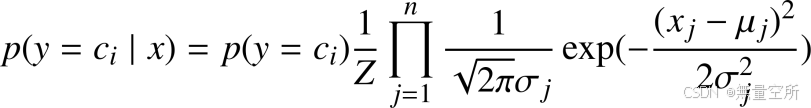
最终分类判别函数可以写成:
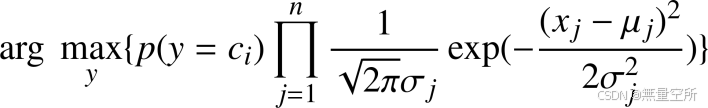
上述两种特征唯一区别在于计算
四、代码实现连续型特证朴素贝叶斯分类器
1、算法流程
(1) 收集训练样本;
(2) 计算各类别的先验概率 ;
(3) 计算每个类别下各特征属性 xj的条件概率 ;
(4) 计算后验概率 ;
(5) 将待分类样本归类到后验概率最大的类别中。
2、数据集选择
iris 数据集。包含 150 个数据样本, 分为 3 类, 每类 50 个数据, 每个数据包含 4个属性, 即特征向量的维数为 4。
3、需要安装的 Python 库
numPy:数值计算库
pandas:数据操作和分析库
sklearn:机器学习的 Python 库
pip install numpy
pip install pandas
pip install scikit-learn4、手动实现(分步骤代码)
1)收集训练样本
def loadData(filepath):
"""
:param filepath: csv
:return: list
"""
data_df = pd.read_csv(filepath)
data_list = np.array(data_df)
data_list = data_list.tolist() # 将pandas DataFrame转换成Numpy的数组再转换成列表
print("Loaded {0} samples successfully.".format(len(data_list)))
return data_list
# 按ratio比例划分训练集与测试集
def splitData(data_list, ratio):
"""
:param data_list:all data with list type
:param ratio: train date's ratio
:return: list type of trainset and testset
"""
train_size = int(len(data_list) * ratio)
random.shuffle(data_list) #随机打乱列表元素
trainset = data_list[:train_size]
testset = data_list[train_size:]
return trainset, testset
# 按类别划分数据
def seprateByClass(dataset):
"""
:param dataset: train data with list type
:return: seprate_dict:separated data by class;
info_dict:Number of samples per class(category)
"""
seprate_dict = {}
info_dict = {}
for vector in dataset:
if vector[-1] not in seprate_dict:
seprate_dict[vector[-1]] = []
info_dict[vector[-1]] = 0
seprate_dict[vector[-1]].append(vector)
info_dict[vector[-1]] += 1
return seprate_dict, info_dict主函数中调用
data_list = loadData('IrisData.csv')
trainset, testset = splitData(data_list, 0.7)
dataset_separated, dataset_info = seprateByClass(trainset)2) 计算各类别的先验概率
def calulateClassPriorProb(dataset, dataset_info):
"""
calculate every class's prior probability
:param dataset: train data with list type
:param dataset_info: Number of samples per class(category)
:return: dict type with every class's prior probability
"""
dataset_prior_prob = {}
sample_sum = len(dataset)
for class_value, sample_nums in dataset_info.items():
dataset_prior_prob[class_value] = sample_nums / float(sample_sum)
return dataset_prior_prob主函数中调用
prior_prob = calulateClassPriorProb(trainset, dataset_info)3) 计算每个类别下各特征属性 的条件概率
先计算均值和方差
def mean(number_list):
number_list = [float(x) for x in number_list] # str to number
return sum(number_list) / float(len(number_list))
def var(number_list):
number_list = [float(x) for x in number_list]
avg = mean(number_list)
var = sum([math.pow((x - avg), 2) for x in number_list]) / float(len(number_list))
return var
# 计算每个属性的均值和方差
def summarizeAttribute(dataset):
"""
calculate mean and var of per attribution in one class
:param dataset: train data with list type
:return: len(attribution)'s tuple ,that's (mean,var) with per attribution
"""
dataset = np.delete(dataset, -1, axis=1) # delete label
# zip函数将数据样本按照属性分组为一个个列表,然后可以对每个属性计算均值和标准差。
summaries = [(mean(attr), var(attr)) for attr in zip(*dataset)]
return summaries
# 按类别提取数据特征
def summarizeByClass(dataset_separated):
"""
calculate all class with per attribution
:param dataset_separated: data list of per class
:return: num:len(class)*len(attribution)
{class1:[(mean1,var1),(),...],class2:[(),(),...]...}
"""
summarize_by_class = {}
for classValue, vector in dataset_separated.items():
summarize_by_class[classValue] = summarizeAttribute(vector)
return summarize_by_class #返回的是某类别各属性均值方差的列表主函数中调用 :
summarize_by_class = summarizeByClass(dataset_separated)计算条件概率
def calculateClassProb(input_data, train_Summary_by_class):
"""
calculate class conditional probability through multiply
every attribution's class conditional probability per class
:param input_data: one sample vectors
:param train_Summary_by_class: every class with every attribution's (mean,var)
:return: dict type , class conditional probability per class of this input data belongs to which class
"""
prob = {}
p = 1
for class_value, summary in train_Summary_by_class.items():
prob[class_value] = 1
for i in range(len(summary)):
mean, var = summary[i]
x = input_data[i]
exponent = math.exp(math.pow((x - mean), 2) / (-2 * var))
p = (1 / math.sqrt(2 * math.pi * var)) * exponent
prob[class_value] *= p
return prob4) 计算后验概率并将待分类样本归类到后验概率最大的类别中
主函数中使用
# 下面对测试集进行预测
correct = 0 # 预测的准确率
for vector in testset:
input_data = vector[:-1]
label = vector[-1]
prob = calculateClassProb(input_data, summarize_by_class)
result = {}
for class_value, class_prob in prob.items():
p = class_prob * prior_prob[class_value]
result[class_value] = p
type = max(result, key=result.get)
print(vector)
print(type)
if type == label:
correct += 1
print("predict correct number:{}, total number:{}, correct ratio:{}".format(correct, len(testset), correct / len(testset)))
5、手动实现(整体代码)
# 导入需要用到的库
import pandas as pd
import numpy as np
import random
import math
# 载入数据集
def loadData(filepath):
"""
:param filepath: csv
:return: list
"""
data_df = pd.read_csv(filepath)
data_list = np.array(data_df) # 将pandas DataFrame转换成Numpy的数组再转换成列表
data_list = data_list.tolist()
print("Loaded {0} samples successfully.".format(len(data_list)))
return data_list
# 划分训练集与测试集
def splitData(data_list, ratio):
"""
:param data_list:all data with list type
:param ratio: train date's ratio
:return: list type of trainset and testset
"""
train_size = int(len(data_list) * ratio)
random.shuffle(data_list) #随机打乱列表元素
trainset = data_list[:train_size]
testset = data_list[train_size:]
return trainset, testset
# 按类别划分数据
def seprateByClass(dataset):
"""
:param dataset: train data with list type
:return: seprate_dict:separated data by class;
info_dict:Number of samples per class(category)
"""
seprate_dict = {}
info_dict = {}
for vector in dataset:
if vector[-1] not in seprate_dict:
seprate_dict[vector[-1]] = []
info_dict[vector[-1]] = 0
seprate_dict[vector[-1]].append(vector)
info_dict[vector[-1]] += 1
return seprate_dict, info_dict
# 计算先验概率
def calulateClassPriorProb(dataset, dataset_info):
"""
calculate every class's prior probability
:param dataset: train data with list type
:param dataset_info: Number of samples per class(category)
:return: dict type with every class's prior probability
"""
dataset_prior_prob = {}
sample_sum = len(dataset)
for class_value, sample_nums in dataset_info.items():
dataset_prior_prob[class_value] = sample_nums / float(sample_sum)
return dataset_prior_prob
# 计算均值的函数
def mean(number_list):
number_list = [float(x) for x in number_list] # str to number
return sum(number_list) / float(len(number_list))
# 计算方差的函数
def var(number_list):
number_list = [float(x) for x in number_list]
avg = mean(number_list)
var = sum([math.pow((x - avg), 2) for x in number_list]) / float(len(number_list))
return var
# 计算每个属性的均值和方差
def summarizeAttribute(dataset):
"""
calculate mean and var of per attribution in one class
:param dataset: train data with list type
:return: len(attribution)'s tuple ,that's (mean,var) with per attribution
"""
dataset = np.delete(dataset, -1, axis=1) # delete label
# zip函数将数据样本按照属性分组为一个个列表,然后可以对每个属性计算均值和标准差。
summaries = [(mean(attr), var(attr)) for attr in zip(*dataset)]
return summaries
# 按类别提取数据特征
def summarizeByClass(dataset_separated):
"""
calculate all class with per attribution
:param dataset_separated: data list of per class
:return: num:len(class)*len(attribution)
{class1:[(mean1,var1),(),...],class2:[(),(),...]...}
"""
summarize_by_class = {}
for classValue, vector in dataset_separated.items():
summarize_by_class[classValue] = summarizeAttribute(vector)
return summarize_by_class #返回的是某类别各属性均值方差的列表
# 计算条件概率
def calculateClassProb(input_data, train_Summary_by_class):
"""
calculate class conditional probability through multiply
every attribution's class conditional probability per class
:param input_data: one sample vectors
:param train_Summary_by_class: every class with every attribution's (mean,var)
:return: dict type , class conditional probability per class of this input data belongs to which class
"""
prob = {}
p = 1
for class_value, summary in train_Summary_by_class.items():
prob[class_value] = 1
for i in range(len(summary)):
mean, var = summary[i]
x = input_data[i]
exponent = math.exp(math.pow((x - mean), 2) / (-2 * var))
p = (1 / math.sqrt(2 * math.pi * var)) * exponent
prob[class_value] *= p
return prob
if __name__ == '__main__':
data_list = loadData('IrisData.csv')
trainset, testset = splitData(data_list, 0.7)
dataset_separated, dataset_info = seprateByClass(trainset)
summarize_by_class = summarizeByClass(dataset_separated)
prior_prob = calulateClassPriorProb(trainset, dataset_info)
# 下面对测试集进行预测
correct = 0 # 预测的准确率
for vector in testset:
input_data = vector[:-1]
label = vector[-1]
prob = calculateClassProb(input_data, summarize_by_class)
result = {}
for class_value, class_prob in prob.items():
p = class_prob * prior_prob[class_value]
result[class_value] = p
type = max(result, key=result.get)
print(vector)
print(type)
if type == label:
correct += 1
print("predict correct number:{}, total number:{}, correct ratio:{}".format(correct, len(testset), correct / len(testset)))
6、使用 sklearn 库实现
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载iris数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7)
# 初始化朴素贝叶斯分类器(这里使用高斯朴素贝叶斯)
gnb = GaussianNB()
# 使用训练集训练朴素贝叶斯分类器
gnb.fit(X_train, y_train)
# 使用测试集进行预测
y_pred = gnb.predict(X_test)
# 计算预测的准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: {}".format(accuracy))