目录
一、在Jupyter Notebook中新建Python运行环境,以单元格为单位运行代码,解释每行代码的含义,分析运行结果。
二、梯度下降算法和Sklearn库都可以用来实现线性逻辑回归模型,二者有各自的优缺点。
一、在Jupyter Notebook中新建Python运行环境,以单元格为单位运行代码,解释每行代码的含义,分析运行结果。
1. 测试运行代码版.ipynb
1.1 导入数据集

1.2 初始化列表

1.3 可视化

1.4 对数据进行处理
给X添加一列全为1的数据:通过 np.ones((len(x_data),1)) 创建了一个形状为(样本数量, 1) 的全为1的矩阵,作为一列新的特征数据。然后使用 np.concatenate() 函数将原始特征数据 x_data 和新的特征数据连接起来,axis=1 表示按列进行连接,最终得到新的特征数据 X_data。

1.5 定义sigmoid 函数
该函数将输入的值 x 映射到 [0,1] 范围内

1.6 使用逻辑回归的损失函数
根据预测的概率值和实际标签值计算损失。

1.7 定义梯度下降函数 gradAscent
用于更新θ参数以最小化损失函数。在每次迭代中,根据学习率和损失函数的梯度更新θ参数

1.8 迭代更新θ参数,同时计算并记录每次迭代的损失值
最终返回更新后的θ参数和损失列表。

1.9 训练模型并输出θ参数向量 ws

1.10 绘制分类结果如下


1.11 绘制损失函数的曲线图
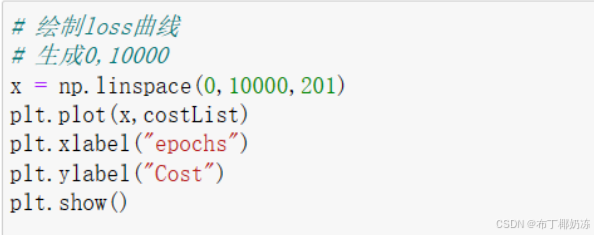

2 测试运行代码版.ipynb
2.1 导入数据集

之后到画图的步骤和1一样。
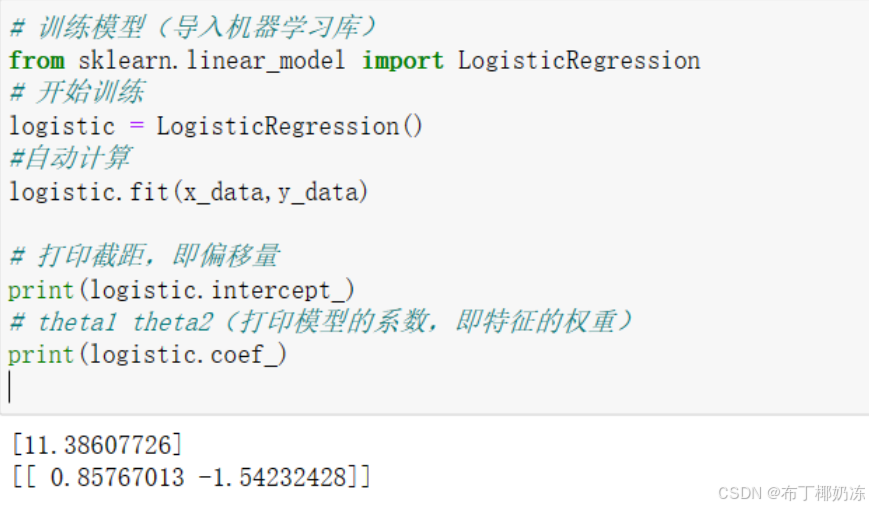
2.2 训练线性逻辑回归模型
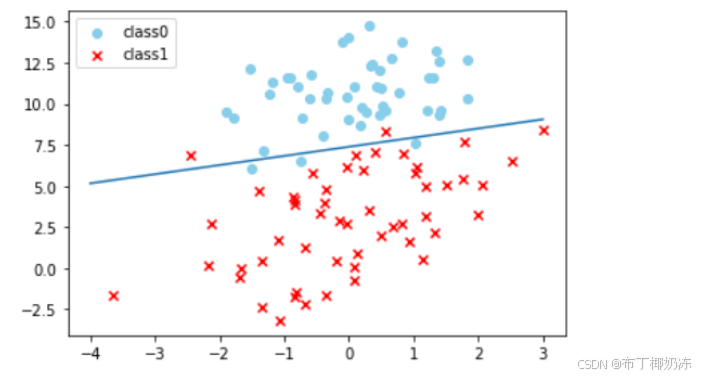
2.3 画出散点图和线性逻辑回归的决策边界

得到准确率如下:

二、梯度下降算法和Sklearn库都可以用来实现线性逻辑回归模型,二者有各自的优缺点。
1. 梯度下降算法的优缺点
优点
(1)梯度下降算法是一种通用的优化算法,可以应用到多种模型的优化中;
(2)能方便地处理非线性模型的优化问题;
(3)梯度下降算法是数据驱动的方法,更适用于数据量较大或特征较多的情况。
缺点
(1)需要多次迭代才能收敛,并且要求步长设置合理,否则可能会得到局部最优解;
(2)梯度下降算法通常需要手动选择学习率和迭代次数参数。
2. Sklearn库的优缺点
优点
(1)Sklearn库已经封装了训练流程,只需要输入数据即可完成训练;
(2)提供了大量的模型评估指标和工具函数,方便模型的评估和调参;
(3)还提供了并行处理、特征选择等功能,可以进一步提升模型效果。
缺点
(1)Sklearn库是一种黑箱方法,不能深入理解模型的内部原理;
(2)适用于标准的机器学习问题,但对于特殊需求或非标准数据集可能需要自己实现算法。