基于YOLOv5深度学习的车距检测系统(单目测距+源码+远程部署)
目录
核心源码
main.py
import argparse
import torch.backends.cudnn as cudnn
from models.experimental import attempt_load
from utils.dataloaders import LoadStreams, LoadImages
from utils.general import *
from utils.plots import *
from utils.torch_utils import *
import plotly.graph_objects as go
start_time = time.time()
print('Pandas Version:', pd.__version__)
print('Nunpy Version:', np.__version__)
@torch.no_grad()
class DistanceEstimation:
def __init__(self):
self.W = 640
self.H = 480
self.excel_path = r'./camera_parameters.xlsx'
def camera_parameters(self, excel_path):
df_intrinsic = pd.read_excel(excel_path, sheet_name='内参矩阵', header=None)
df_p = pd.read_excel(excel_path, sheet_name='外参矩阵', header=None)
print('外参矩阵形状:', df_p.values.shape)
print('内参矩阵形状:', df_intrinsic.values.shape)
return df_p.values, df_intrinsic.values
def object_point_world_position(self, u, v, w, h, p, k):
u1 = u
v1 = v + h / 2
print('关键点坐标:', u1, v1)
alpha = -(90 + 0) / (2 * math.pi)
peta = 0
gama = -90 / (2 * math.pi)
fx = k[0, 0]
fy = k[1, 1]
H = 1
angle_a = 0
angle_b = math.atan((v1 - self.H / 2) / fy)
angle_c = angle_b + angle_a
print('angle_b', angle_b)
depth = (H / np.sin(angle_c)) * math.cos(angle_b)
print('depth', depth)
k_inv = np.linalg.inv(k)
p_inv = np.linalg.inv(p)
# print(p_inv)
point_c = np.array([u1, v1, 1])
point_c = np.transpose(point_c)
print('point_c', point_c)
print('k_inv', k_inv)
c_position = np.matmul(k_inv, depth * point_c)
print('c_position', c_position)
c_position = np.append(c_position, 1)
c_position = np.transpose(c_position)
c_position = np.matmul(p_inv, c_position)
d1 = np.array((c_position[0], c_position[1]), dtype=float)
return d1
def distance(self, kuang, xw=5, yw=0.1):
print('=' * 50)
print('开始测距')
fig = go.Figure()
p, k = self.camera_parameters(self.excel_path)
if len(kuang):
obj_position = []
u, v, w, h = kuang[1] * self.W, kuang[2] * self.H, kuang[3] * self.W, kuang[4] * self.H
print('目标框', u, v, w, h)
d1 = self.object_point_world_position(u, v, w, h, p, k)
distance = 0
print('距离', d1)
if d1[0] <= 0:
d1[:] = 0
else:
distance = math.sqrt(math.pow(d1[0], 2) + math.pow(d1[1], 2))
return distance, d1
def Detect(self, weights='yolov5s.pt',
source='data/images', # file/dir/URL/glob, 0 for webcam
imgsz=640, # inference size (pixels)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
update=False, # update all models
project='inference/output', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
):
save_img = not nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
#save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
#(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
save_dir = Path(project)
# Initialize
set_logging()
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA 仅在使用CUDA时采用半精度
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = max(int(model.stride.max()), 32) # model stride
names = model.module.names if hasattr(model, "module") else model.names # get class names
if half:
model.half() # to FP16
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=augment)[0]
# Apply NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
t2 = time_synchronized()
# Process detections 检测过程
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count #path[i]为source 即为0
else:
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path p为inference/images/demo_distance.mp4
save_path = str(save_dir / p.name) # img.jpg inference/output/demo_distance.mp4
txt_path = str(save_dir / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt inference/output/demo_distance_frame
#print('txt', txt_path)
s += '%gx%g ' % img.shape[2:] # print string 图片形状 eg.640X480
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
if not names[int(c)] in ['person', 'car', 'truck', 'bicycle', 'motorcycle', 'bus', 'traffic light', 'stop sign']:
continue
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if not names[int(cls)] in ['person','chair', 'car', 'truck', 'bicycle', 'motorcycle', 'bus', 'traffic light', 'stop sign']:
continue
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
kuang = [int(cls), xywh[0], xywh[1], xywh[2], xywh[3]]
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * 5 + '\n') % (int(cls), *xywh))
distance, d = self.distance(kuang)
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
if label != None and distance!=0:
label = label + ' ' + str('%.1f' % d[0]) + 'm'+ str('%.1f' % d[1]) + 'm'
plot_one_box(xyxy, im0, label=label, color=colors(c, True), line_thickness=line_thickness)
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {save_dir}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='weights/yolov5s.pt', help='model.pt path(s)')
# parser.add_argument('--source', type=str, default='inference/images/demo_distance.mp4', help='inference/dir/URL/glob, 0 for webcam')
parser.add_argument('--source', type=str, default='inference/inputs', help='inference/dir/URL/glob, 0 for webcam')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=1440, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.5, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save_txt',default=False, action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='inference/output', help='save results to project/name') #保存地址
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('tensorboard', 'thop'))
print('开始进行目标检测和单目测距!')
DE = DistanceEstimation()
DE.Detect(**vars(opt))
if time.time()>(start_time + 10):
cv2.waitKey (0)
cv2.destroyAllWindows()
detect.py
import os import shutil import xml.etree.ElementTree as ET import json import tensorflow as tf import matplotlib.pyplot as plt coco = dict() coco['images'] = [] coco['type'] = 'instances' coco['annotations'] = [] coco['categories'] = [] category_set = dict() image_set = set() category_item_id = 0 image_id = 20200000000 annotation_id = 0 def addCatItem(name): global category_item_id category_item = dict() category_item['supercategory'] = 'none' category_item_id += 1 category_item['id'] = category_item_id category_item['name'] = name coco['categories'].append(category_item) category_set[name] = category_item_id return category_item_id def addImgItem(file_name, size): global image_id if file_name is None: raise Exception('Could not find filename tag in xml file.') if size['width'] is None: raise Exception('Could not find width tag in xml file.') if size['height'] is None: raise Exception('Could not find height tag in xml file.') image_id += 1 image_item = dict() image_item['id'] = image_id image_item['file_name'] = file_name image_item['width'] = size['width'] image_item['height'] = size['height'] coco['images'].append(image_item) image_set.add(file_name) return image_id def addAnnoItem(object_name, image_id, category_id, bbox): global annotation_id annotation_item = dict() annotation_item['segmentation'] = [] seg = [] # bbox[] is x,y,w,h # left_top seg.append(bbox[0]) seg.append(bbox[1]) # left_bottom seg.append(bbox[0]) seg.append(bbox[1] + bbox[3]) # right_bottom seg.append(bbox[0] + bbox[2]) seg.append(bbox[1] + bbox[3]) # right_top seg.append(bbox[0] + bbox[2]) seg.append(bbox[1]) annotation_item['segmentation'].append(seg) annotation_item['area'] = bbox[2] * bbox[3] annotation_item['iscrowd'] = 0 annotation_item['ignore'] = 0 annotation_item['image_id'] = image_id annotation_item['bbox'] = bbox annotation_item['category_id'] = category_id annotation_id += 1 annotation_item['id'] = annotation_id coco['annotations'].append(annotation_item) def parseXmlFiles(xml_path): for f in os.listdir(xml_path): if not f.endswith('.xml'): continue bndbox = dict() size = dict() current_image_id = None current_category_id = None file_name = None size['width'] = None size['height'] = None size['depth'] = None xml_file = os.path.join(xml_path, f) tree = ET.parse(xml_file) root = tree.getroot() if root.tag != 'annotation': raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag)) # elem is <folder>, <filename>, <size>, <object> for elem in root: current_parent = elem.tag current_sub = None object_name = None if elem.tag == 'folder': continue if elem.tag == 'filename': file_name = elem.text if file_name in category_set: raise Exception('file_name duplicated') # add img item only after parse <size> tag elif current_image_id is None and file_name is not None and size['width'] is not None: if file_name not in image_set: current_image_id = addImgItem(file_name, size) #print('add image with {} and {}'.format(file_name, size)) else: raise Exception('duplicated image: {}'.format(file_name)) # subelem is <width>, <height>, <depth>, <name>, <bndbox> for subelem in elem: bndbox['xmin'] = None bndbox['xmax'] = None bndbox['ymin'] = None bndbox['ymax'] = None current_sub = subelem.tag if current_parent == 'object' and subelem.tag == 'name': object_name = subelem.text if object_name not in category_set: current_category_id = addCatItem(object_name) else: current_category_id = category_set[object_name] elif current_parent == 'size': if size[subelem.tag] is not None: raise Exception('xml structure broken at size tag.') size[subelem.tag] = int(subelem.text) # option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox> for option in subelem: if current_sub == 'bndbox': if bndbox[option.tag] is not None: raise Exception('xml structure corrupted at bndbox tag.') bndbox[option.tag] = int(option.text) # only after parse the <object> tag if bndbox['xmin'] is not None: if object_name is None: raise Exception('xml structure broken at bndbox tag') if current_image_id is None: raise Exception('xml structure broken at bndbox tag') if current_category_id is None: raise Exception('xml structure broken at bndbox tag') bbox = [] # x bbox.append(bndbox['xmin']) # y bbox.append(bndbox['ymin']) # w bbox.append(bndbox['xmax'] - bndbox['xmin']) # h bbox.append(bndbox['ymax'] - bndbox['ymin']) # print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id, bbox)) addAnnoItem(object_name, current_image_id, current_category_id, bbox) print('完成xml到jsion格式转换!') print('目标的种类及编号为:', coco['categories']) def del_images(image_path, ann_path): ''' 该函数用于删除未标注的图片 :param xml_path: xml标注文件夹绝对路径 :param image_path: 图片文件夹绝对路径 :return: 删除的图片列表 ''' xmls = os.listdir(ann_path) images = os.listdir(image_path) del_images_list = [] xml_index = [] for xml in xmls: xml_index.append(xml.split('.')[0]) for image in images: image_index = image.split('.')[0] if image_index not in xml_index and os.path.isfile(os.path.join(image_path, image)): os.remove(os.path.join(image_path, image)) print('删除:',image) del_images_list.append(image) print('完成删除未标注图片{0}张'.format(len(del_images_list ))) print('删除的图片名列表:', del_images) xmls = os.listdir(ann_path) images = os.listdir(image_path) print('图片张数:',len(images)) print('标注文件数:', len(xmls)) if len(images) != len(xmls): print('错误:图片与标注文件不对应!') else: print('图片与标注文件数相等') return del_images_list def rename(image_path, ann_path): ''' rename函数根据图像名找到对应的标注文件,然后将两个文件改成相同的数字名 :param image_path: :param ann_path: :return: ''' image_names = os.listdir(image_path) ann_names = os.listdir(ann_path) print('图片数量:{0},标注文件数量{1}'.format(len(image_names), len(ann_names))) if len(image_names) != len(ann_names): print('图片与标注文件数量相等') i = 0 for image_name in image_names: image_oldname = os.path.join(image_path, image_name) index = image_name.split('.')[0] ann_name = index + ".xml" ann_oldname = os.path.join(ann_path, ann_name) las = image_name.split('.')[1] im_newname = str(i) + '.' + las an_newname = str(i) + '.xml' image_newname = os.path.join(image_path, im_newname) ann_newname = os.path.join(ann_path, an_newname) i += 1 os.rename(image_oldname, image_newname) os.rename(ann_oldname, ann_newname) print('完成图像与对应标注文件的重命名') def split_data(image_path, ann_path, save_split_path, rate = 0.8): ''' 按比例rate将数据集划分为训练集和验证集,并检查图片与标注文件的对应性 :param image_path: 已标注图片路径 :param ann_path: 标注文件路径 :param save_split_path: 划分数据集保存的路径 :param rate: 划分给训练集的比例 :return: 返回训练集和测试集的图片与标注文件路径 ''' if not os.path.exists(save_split_path): os.mkdir(save_split_path) else: shutil.rmtree(save_split_path) os.mkdir(save_split_path) ann_train_path = os.path.join(save_split_path,'ann_train/') ann_val_path = os.path.join(save_split_path,'ann_val/') image_train_path = os.path.join(save_split_path,'images_train/') image_val_path = os.path.join(save_split_path,'images_val/') # 创建文件夹 os.mkdir(ann_train_path) os.mkdir(ann_val_path) os.mkdir(image_train_path) os.mkdir(image_val_path) print('清空文件夹') images_names = os.listdir(image_path) # 取图片的原始路径 images_number = len(images_names) ann_names = os.listdir(ann_path) ann_number = len(ann_names) if images_number != ann_number: print('错误:图片数与标注文件数不相等') # 自定义抽取训练图片的比例,比方说100张抽10张,那就是0.1 sample_number = int(images_number * rate) # 按照rate比例从文件夹中取一定数量图片 for name in images_names[0:sample_number]: shutil.copy(image_path + name, image_train_path + name) for name in ann_names[0:sample_number]: shutil.copy(ann_path + name, ann_train_path + name) for name in images_names[sample_number:images_number+1]: shutil.copy(image_path + name, image_val_path + name) for name in ann_names[sample_number:images_number+1]: shutil.copy(ann_path + name, ann_val_path + name) print('完成训练集({0})与测试集({1})划分'.format(round(rate,1),round((1-rate), 1))) print('图片总数为{0},标注文件总数为{1}'.format(images_number, ann_number)) print('{0} 张图片用于训练,{1} 张图片用于验证'.format(sample_number, images_number - sample_number)) # 检验图片与标注的匹配关系 image_train_names = os.listdir(image_train_path) ann_train_names = os.listdir(ann_train_path) count = 0 for i in range(len(image_train_names)): if image_train_names[i].split('.')[0] != ann_train_names[i].split('.')[0]: print('{0} 图片与{1}标注文件不匹配'.format(image_train_names[i][0]+image_train_names[i][1], ann_train_names[i][ann_train_names[i][1]])) count +=1 if count == 0: print('训练集所有图片与标注文件一一对应') else: print('训练集图片与标注文件不匹配数目:',count) image_val_names = os.listdir(image_val_path) ann_val_names = os.listdir(ann_val_path) c = 0 for i in range(len(image_val_names)): if image_val_names[i].split('.')[0] != ann_val_names[i].split('.')[0]: print('{0} 图片与{1}标注文件不匹配'.format(image_val_names[i][0]+image_val_names[i][1], ann_val_names[i][ann_val_names[i][1]])) c +=1 if count == 0: print('验证集所有图片与标注文件一一对应') else: print('验证集图片与标注文件不匹配数目:', c) return image_train_path, image_val_path, ann_train_path, ann_val_path def voc2coco_json(image_path, ann_path, save_split_path,save_coco_path): del_iammges = del_images(image_path, ann_path) if not os.path.exists(save_coco_path): os.mkdir(save_coco_path) else: shutil.rmtree(save_coco_path) os.mkdir(save_coco_path) annotations_path = os.path.join(save_coco_path,'annotations/') train2017_path = os.path.join(save_coco_path,'train2017/') val2017_path = os.path.join(save_coco_path,'val2017/') os.mkdir(annotations_path) os.mkdir(train2017_path) os.mkdir(val2017_path) image_train_path, image_val_path, ann_train_path, ann_val_path=split_data(image_path, ann_path, save_split_path, rate = 0.8) json_file = [os.path.join(annotations_path, 'instances_train2017.json'), os.path.join(annotations_path, 'instances_val2017.json')] ann_path = [ann_train_path, ann_val_path] for i in range(len(ann_path)): parseXmlFiles(ann_path[i]) json.dump(coco, open(json_file[i], 'w')) images_train = os.listdir(image_train_path) images_val = os.listdir(image_val_path) for name in images_train: shutil.copy(image_train_path+name, train2017_path+name) for name in images_val: shutil.copy(image_val_path+name, val2017_path+name) print('完成数据清洗、拆分、xlm到json转换') def data_augment(image_path, save_image_path = None): #images = os.listdir(image_path) image_string = tf.io.read_file(image_path) image = tf.image.decode_jpeg(image_string, channels = 3) # 翻转图像(垂直和水平) flipped_h = tf.image.flip_left_right(image) flipped_v = tf.image.flip_up_down(image) bright_0 = tf.image.adjust_brightness(image, 0.2) bright_5 = tf.image.adjust_brightness(image, 0.5) bright_8 = tf.image.adjust_brightness(image, 0.6) bright_10 = tf.image.adjust_brightness(image, 0.8) grayscaled = tf.image.rgb_to_grayscale(image) saturated_3 = tf.image.adjust_saturation(image, 3) saturated_8 = tf.image.adjust_saturation(image, 8) #visualize(image, bright_0) #visualize(image, flipped_h) #visualize(image, flipped_v) # visualize(image, tf.squeeze(grayscaled)) visualize(image, saturated_3) def visualize(original, augmented): plt.figure(figsize = (20, 10)) plt.subplot(1, 2, 1) plt.title("Original Picture", fontsize=50, fontweight='bold') # plt.axis("off") # 关闭坐标轴显示 #plt.imshow(original) plt.subplot(1, 2, 2) plt.title("saturation 3", fontsize=50, fontweight='bold') # plt.axis("off") # 关闭坐标轴显示 #plt.imshow(augmented) plt.xticks(fontsize = 30) plt.yticks(fontsize = 30) plt.tight_layout() plt.savefig('./saturation3.png') #plt.show() if __name__ == '__main__': image_path = "D:/PythonFile/aicar/aicar标志物数据集/JPEGImages/" ann_path = "D:/PythonFile/aicar/aicar标志物数据集/Annotations/" save_coco_path ="D:/PythonFile/aicar/coco2017/" save_split_path = "D:/PythonFile/aicar/splitdata/" #voc2coco_json(image_path, ann_path, save_split_path, save_coco_path) data_augment("D:\PythonFile\shangqi\ObjectDistance\dog.png")
安装环境
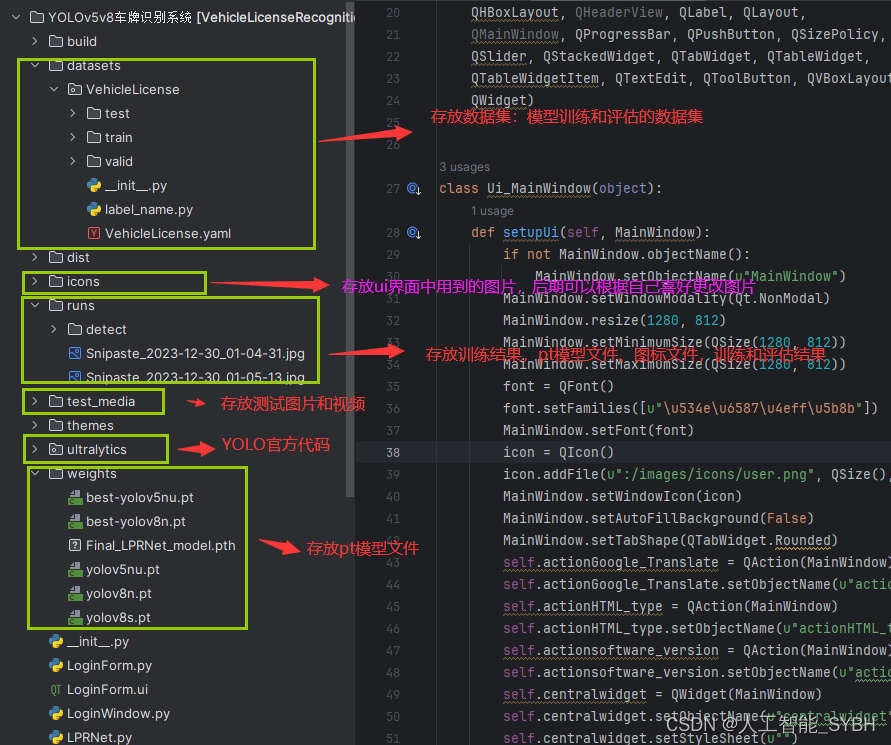
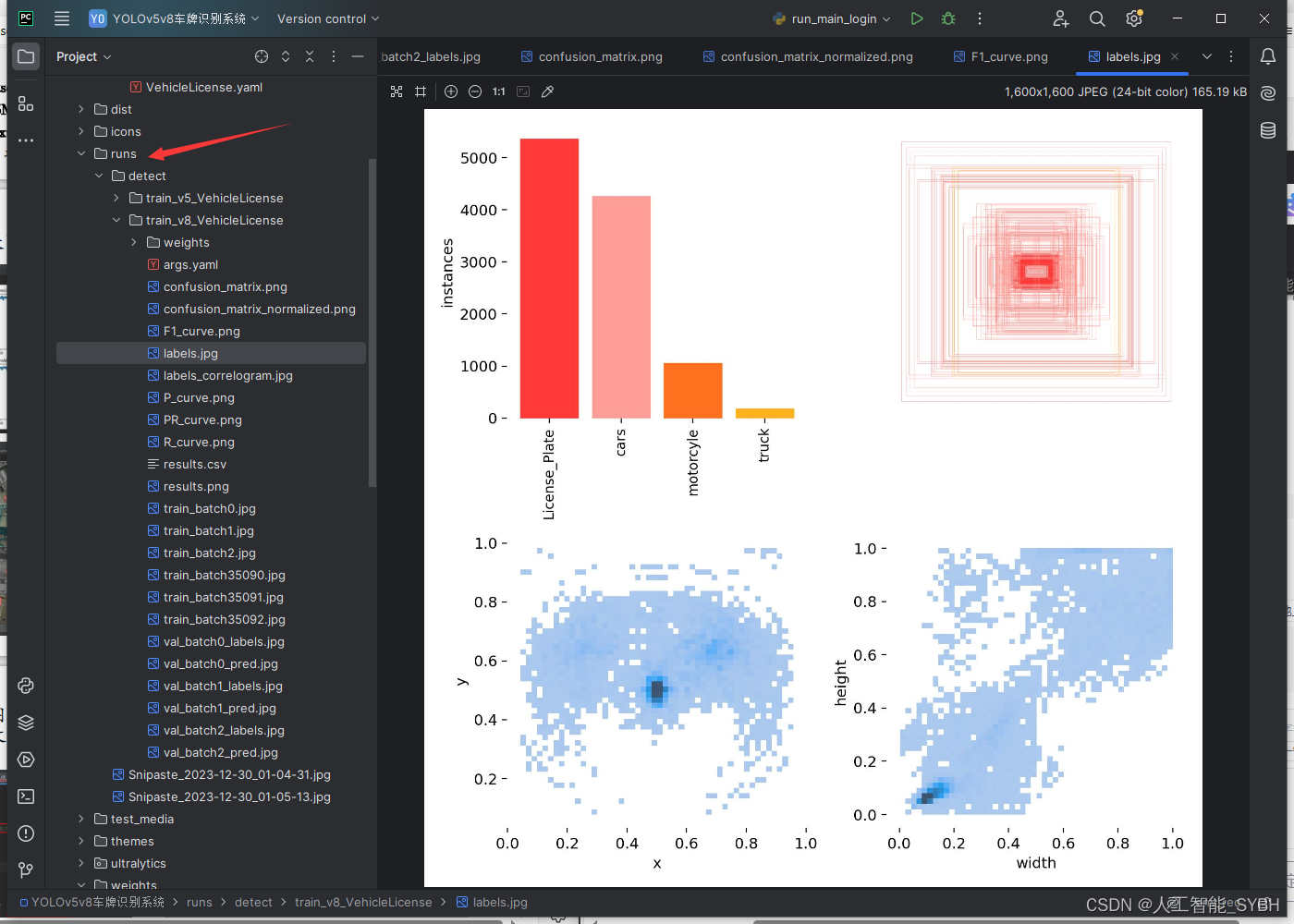
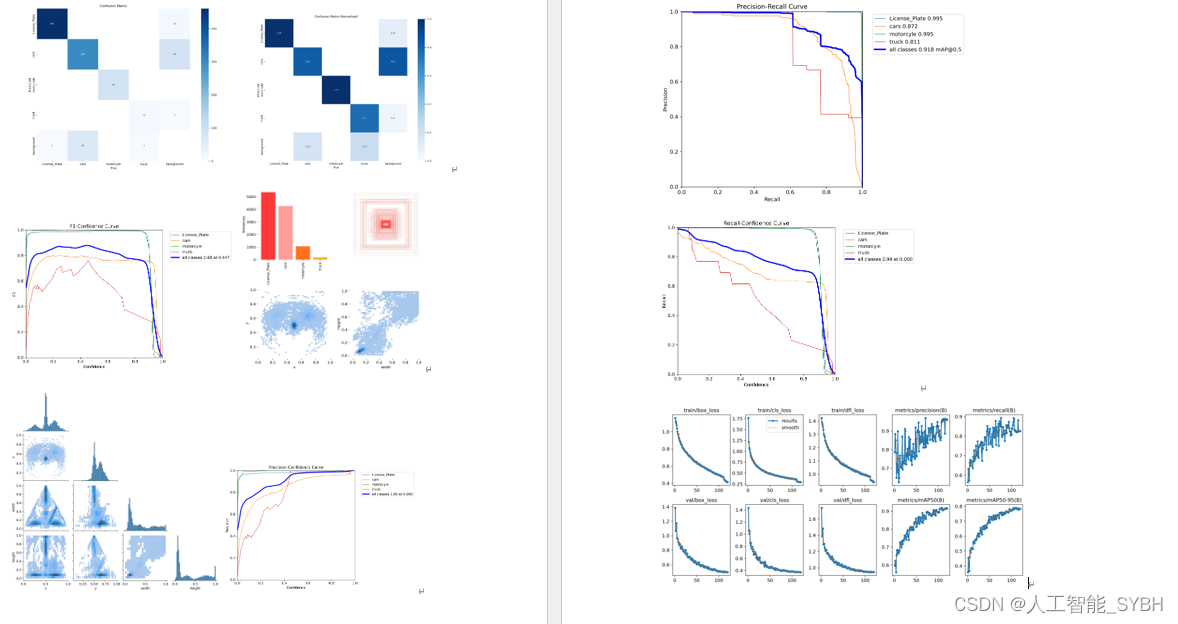
runs文件夹中,存放训练和评估的结果图
环境安装:
请按照给定的python版本配置环境,否则可能会因依赖不兼容而出错,
在文件目录下cmd进入终端
(1)使用anaconda新建python3.10环境:
conda create -n env_rec python=3.10

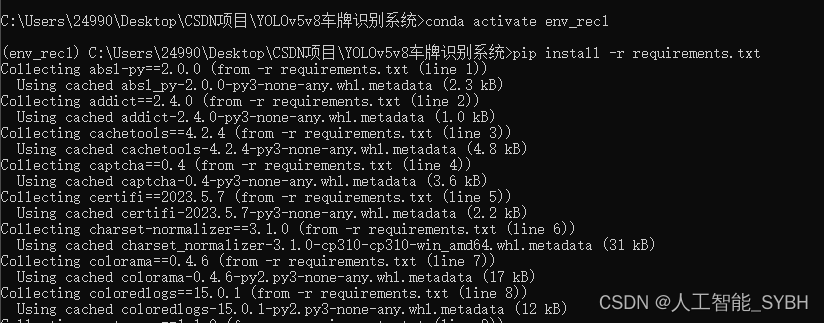
(2)激活创建的环境:
conda activate env_rec

(3)使用pip安装所需的依赖,可通过requirements.txt:
pip install -r requirements.txt
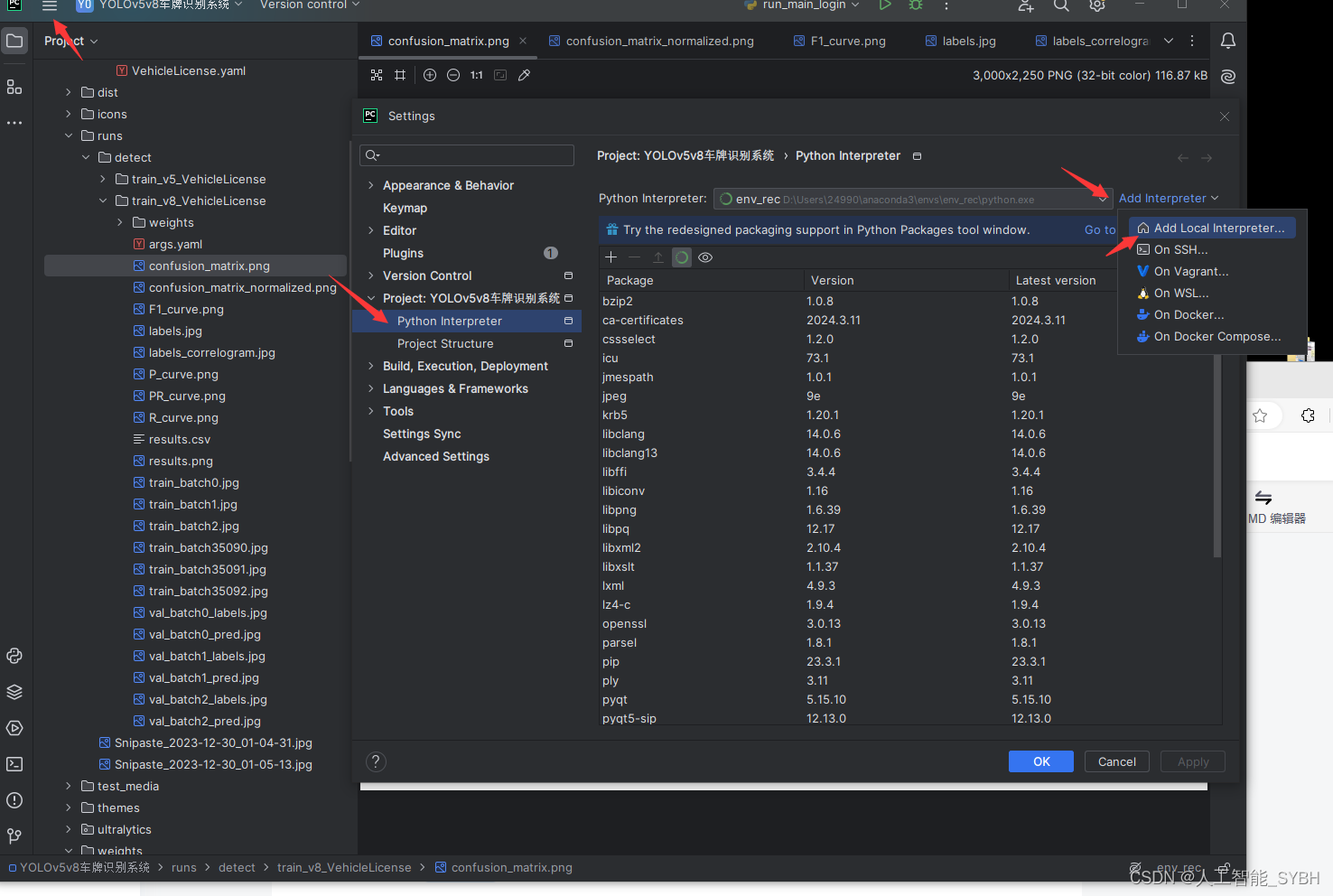
在settings中找到project python interpreter 点击Add Interpreter
点击conda,在Use existing environment中选择刚才创建的虚拟环境 ,最后点击确定。如果conda Executable中路径没有,那就把anaconda3的路径添加上
