文章目录
摘要
自监督学习通过自我监督的方式学习通用特征表达,主要分为生成式学习和对比学习。生成式学习关注像素空间的重建误差,而对比学习关注特征空间中不同输入的区分。BERT作为一种基于Transformer架构的预训练语言模型,通过双向上下文理解和大量参数,显著提升了NLP任务的性能。BERT通过无监督预训练和有监督微调的方式,实现了在多个任务上的优异表现,但其训练成本高,对长序列处理能力有限,可能学习数据偏见。
Abstract
Self-supervised learning can be divided into generative learning and contrastive learning through self-supervised learning of general feature expression. Generative learning focuses on the reconstruction error of pixel space, while contrastive learning focuses on the differentiation of different inputs in feature space. BERT, as a pre-trained language model based on the Transformer architecture, significantly improves the performance of NLP tasks through bi-directional context understanding and a large number of parameters. BERT achieves excellent performance on multiple tasks through unsupervised pre-training and supervised fine-tuning, but its training cost is high, its ability to process long sequences is limited, and it may learn data bias
1.Self-supervised Learning
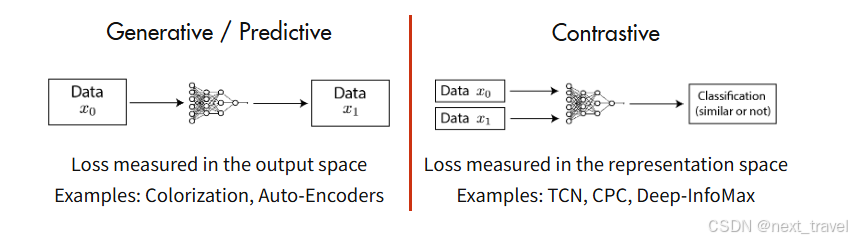
自监督学习是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务。其主要方式是通过自己监督自己,比如把有一段话里面的几个单词去掉,用他的上下文去预测确实的单词,或者将图片的一部分去掉,依赖其周围的信息去预测缺失的patch。自监督学习有两个方向:生成式学习和对比学习。
1.1 生成式学习
这类方法主要关注pixel space(像素点)的重建误差,大多以pixel label的loss为主。对编码器的基本要求就是尽可能保留原始数据的重要信息,如果能通过decoder解码回原始图片,则说明latent code 重建的足够好了。
但是存在一些问题:
1.基于pixel进行重建计算开销非常大。
2.要求模型逐像素重建过于苛刻,而用GAN的方式构建一个判别器又会让任务复杂和难以优化。
基于上述问题就提出了对比学习的方法。
1.2 对比学习
这类方法并不要求模型能够重建原始输入,而是希望能够在特征空间上对不同的输入进行分辨。
此类方法有如下特点:
1.在feature space上构建距离度量
2.通过特征不变性,可以得到多种预测结果
3.使用孪生网络(一种比较两个输入的神经网络架构,由两个或多个共享权重的子网络组成,这些子网络分别处理输入数据,并映射到相同的特征空间。网络通过某种距离函数计算两个输入的相似性)
4.不需要pixel-level重建。
正是因为这类方法不需要pixel-level上进行重建,所以优化变得更加容易。但是缺点是因为数据中没有标签,主要的问题就是怎么去构造正样本和负样本(之后再进一步学习)如可以通过多模态的信息去构造link,进一步了解可参照link。
下面是两个方法的对比:
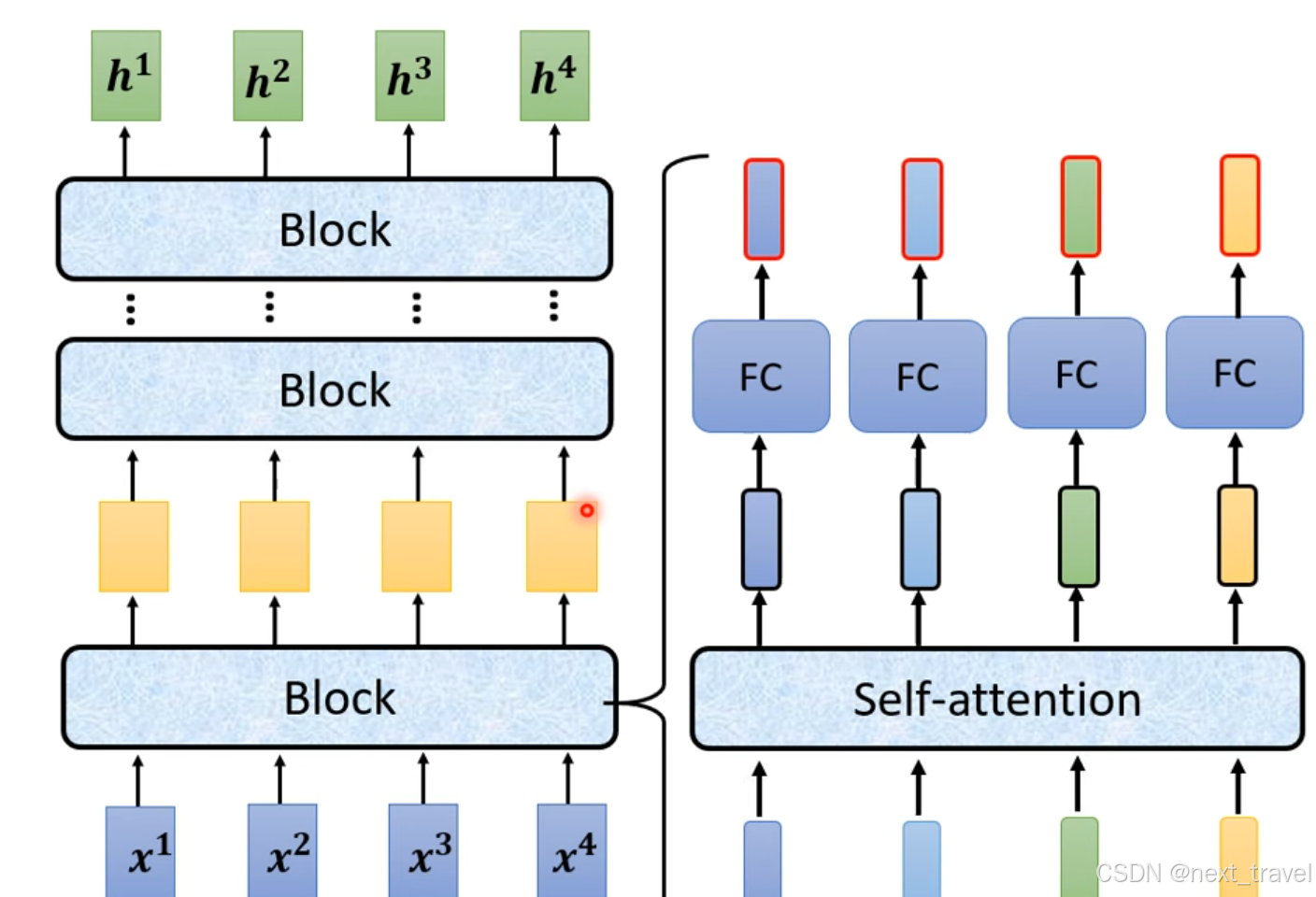
2.seq2seq
2.1 Encoder
对于一个block块的输入到输出的过程:
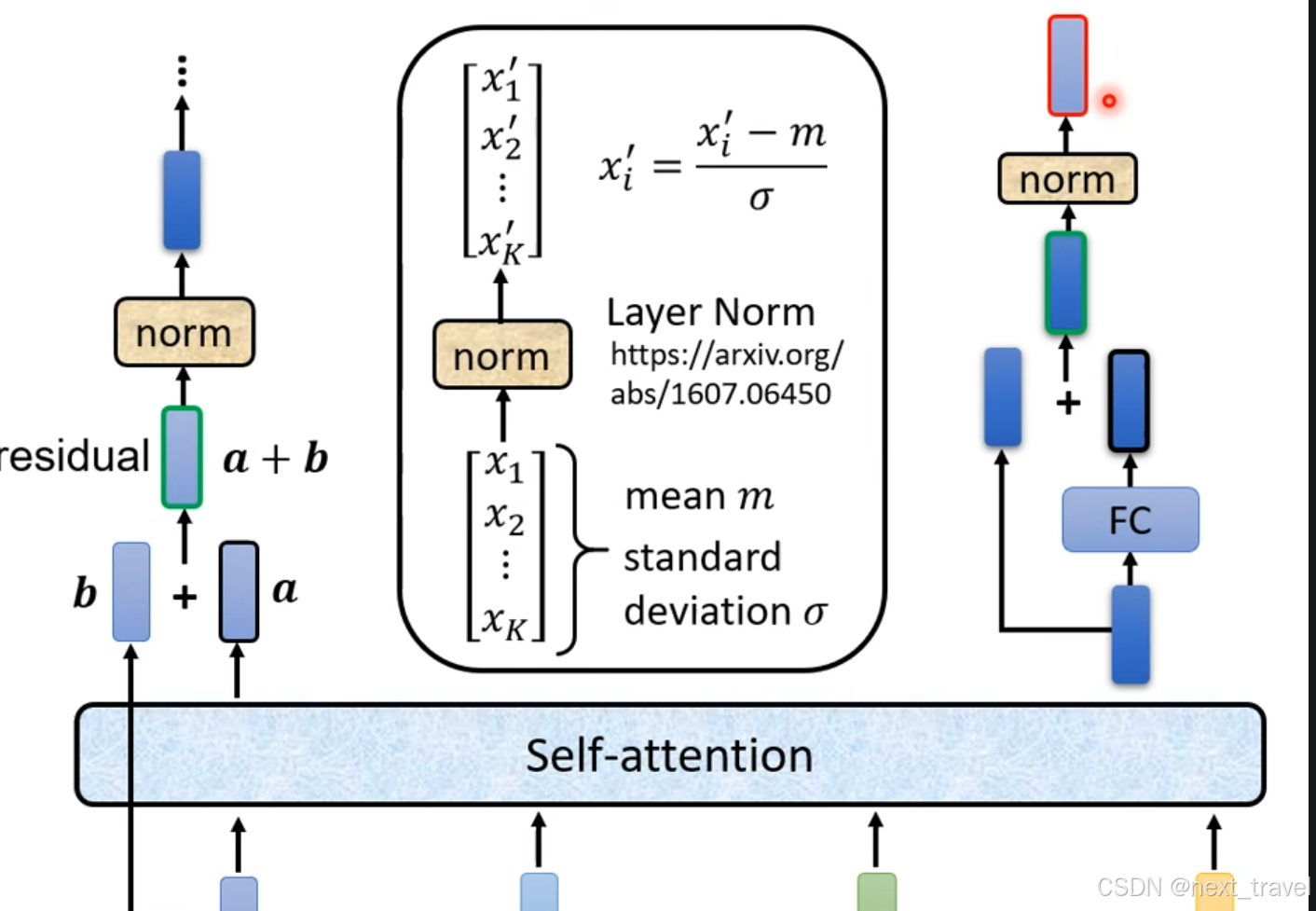
在transformer架构中encoder部分
上述对于encoder部分改进可参考两篇文章
On Layer Normalization in the Transformer Architecture link
PowerNorm:Rethinking Batch Normalization in Transfromers] link
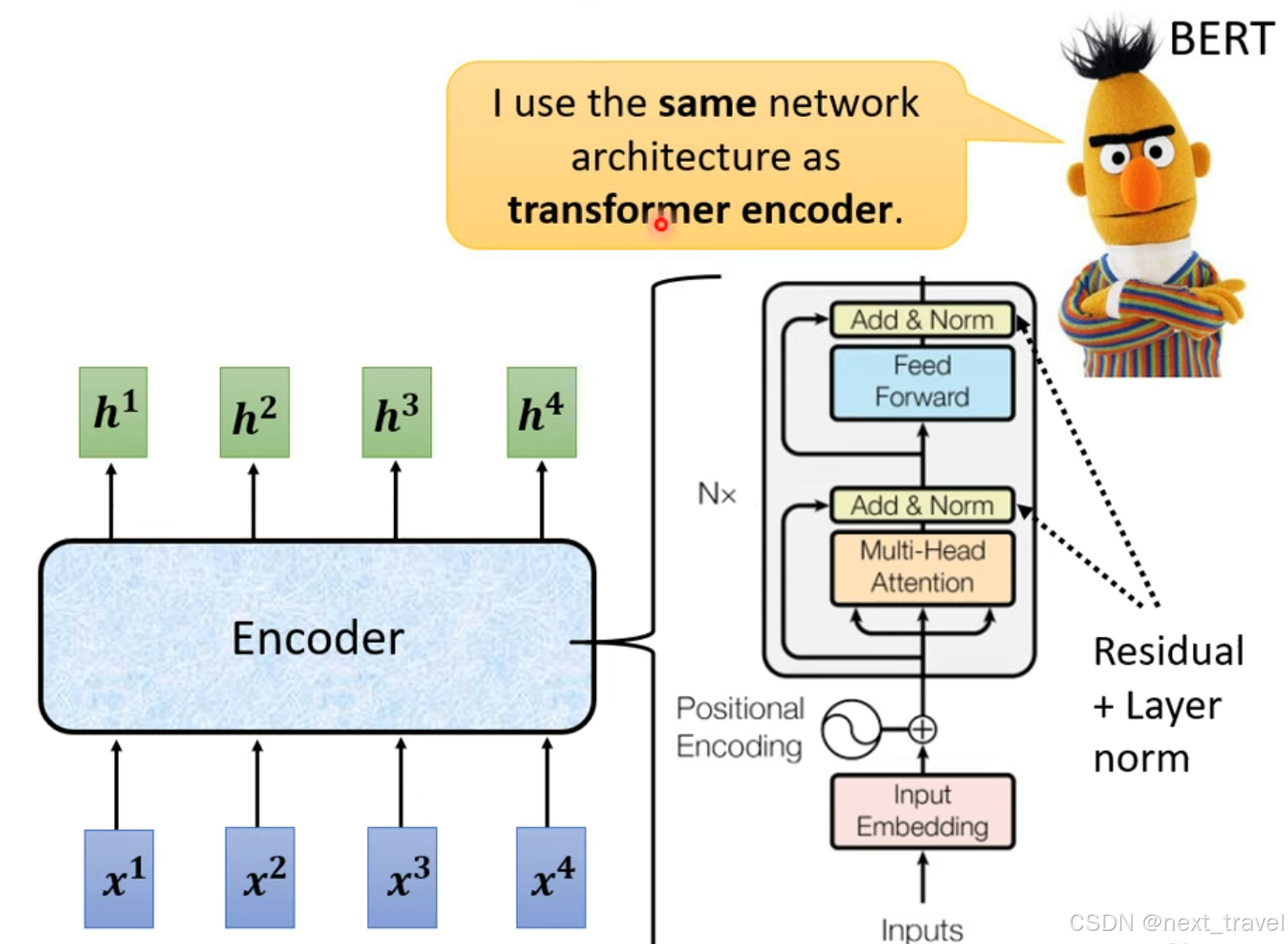
3.BERT
BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer架构的预训练语言模型。其核心结构由多层Transformer Encoder 组成。
通常分为BERT-base和BERT-large两个版本:
1.BERT-base:12个编码器层,隐藏层大小768,注意力头数12,总参数约为1.1亿。
2.BERT-large:24个编译器层,隐藏层大小为1024,注意力头数16,总参数量约为3.4亿。
训练过程:BERT采用无监督预训练+有监督微调的方式:
1.预训练阶段:
Masked Language Model(MLM):随机掩盖输入序列中15%的词汇,模型需要预测这些背掩盖的词。
2.微调阶段:
使用预训练的权重,在具体任务(如文本分类、命名实体识别、问答系统)上进行有监督微调。
模型优势:
双向上下文:BERT同时考虑句子中每个词的前后信息,有别于传统的单向语言模型
通用性强:预训练模型可以适应多种NLPr任务,只需在下游任务上微调
语言理解能力:在GLUE\SQuAD等基准测试中,BERT刷新了多个任务的最佳表现。
局限性:
1.训练成本大
2.对长序列处理能力有限(原始BERT支持最长512个token)
3.可能会学习到数据中的偏见。
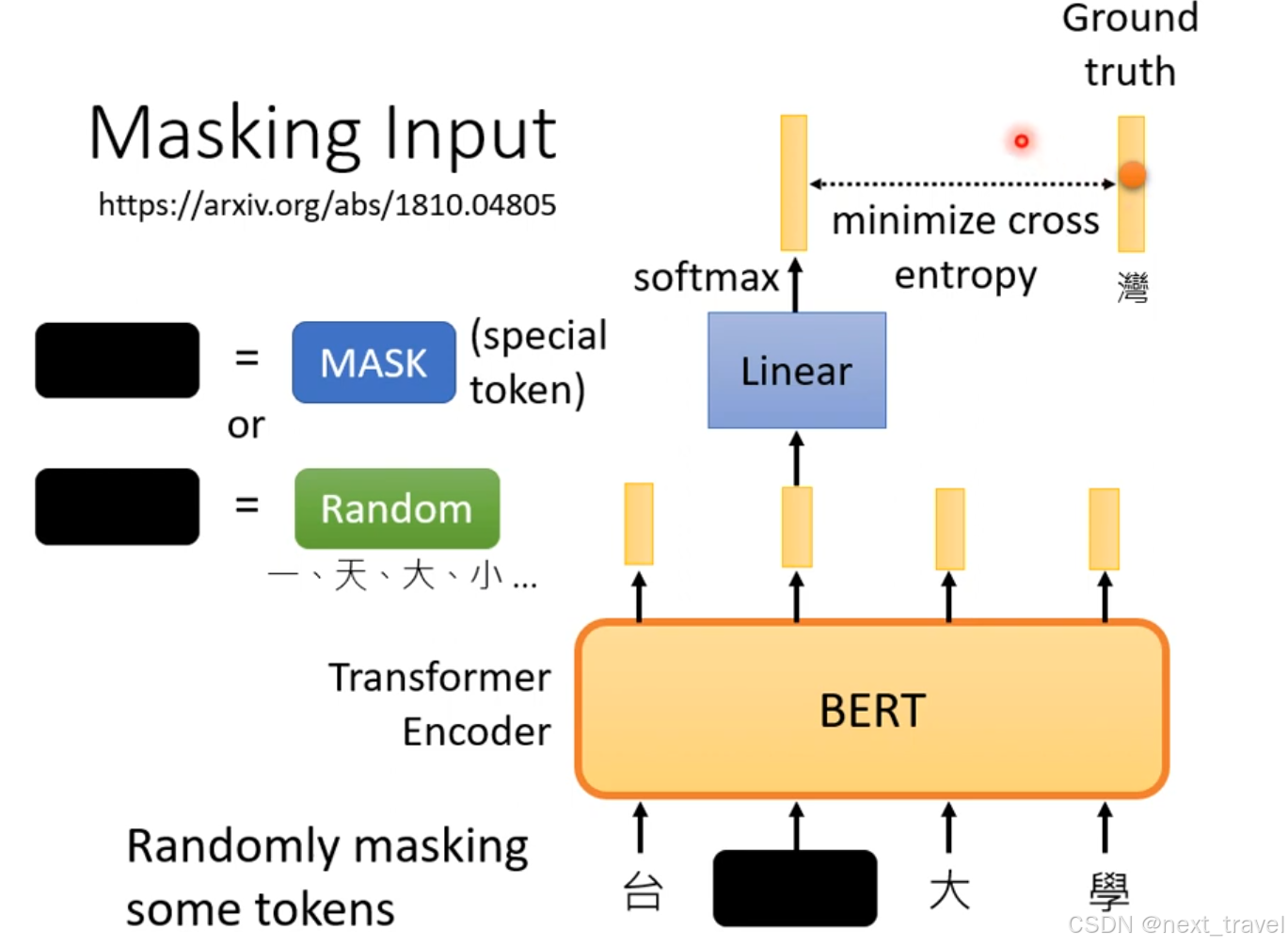
3.1 Masking Input
BERT在训练时,通过MASK或者Random这两种方法随机采用一种方法来mask一些tokens,对mask的部分进行一个Linear变换(乘以一个矩阵)然后做softmax。bert学习的目标就是mask部分的输出和真实值的交叉熵尽可能的小。
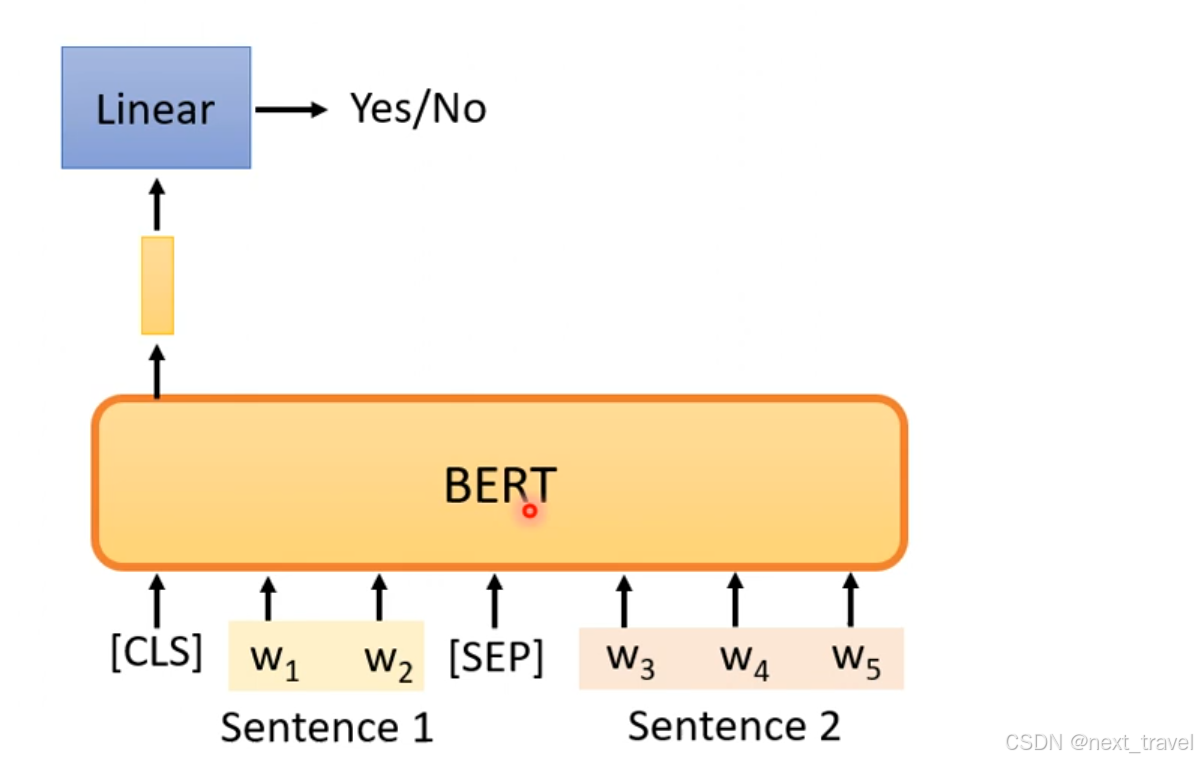
3.2 Next Sentence Prediction
使用bert训练两个句子是否是相接的,但是在Robustly optimized BERT approach(RoBERTa) link ,表明这个方法是没有用的
后来在提出SOP(Sentence order prediction)被用于ALBERT中 link,用于判断同一个sequence中两个分句的前后关系。
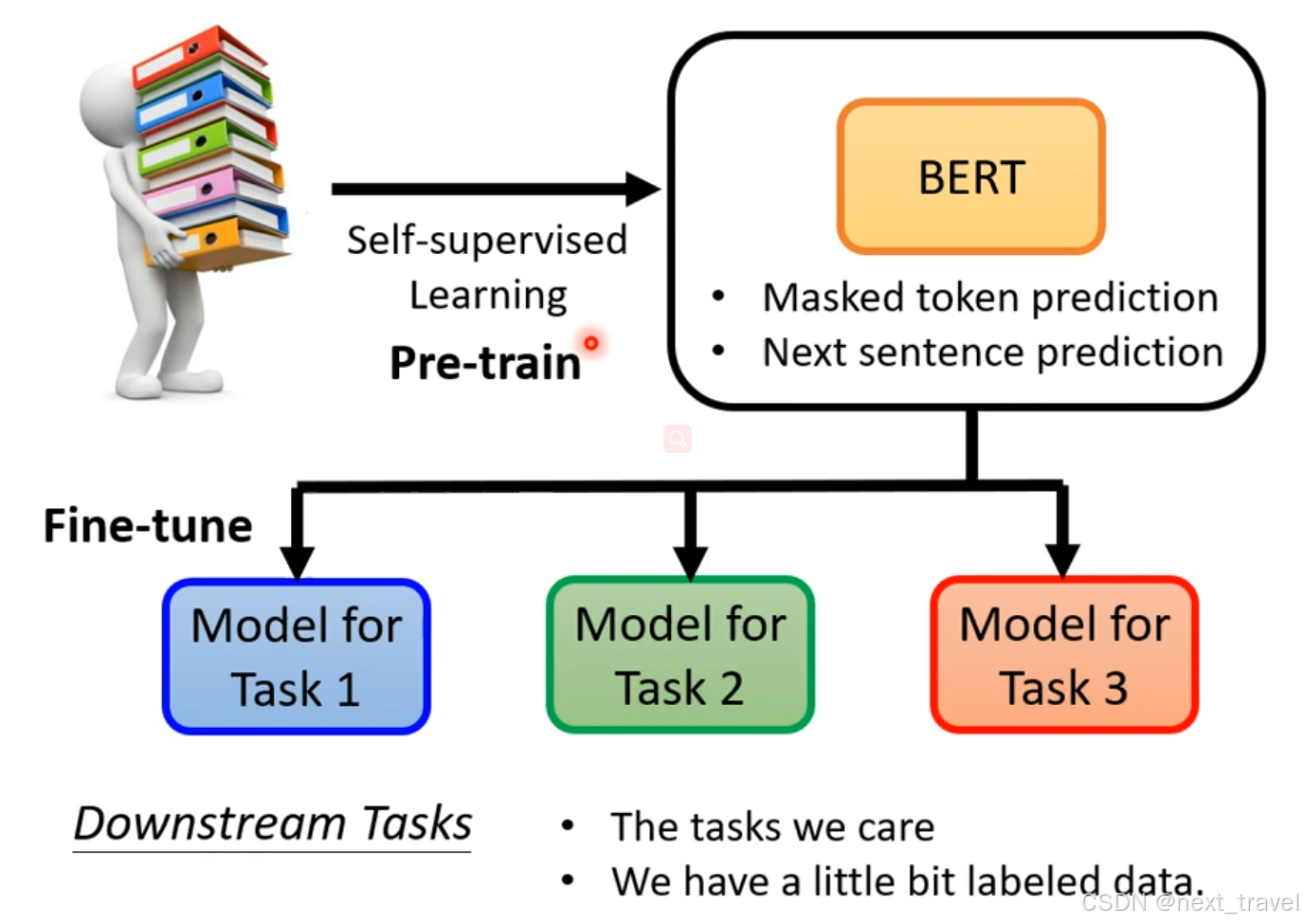
在上述的过程说明,BERT最大的用处就是做填空题。但是后来表明BERT可以用于处理下游任务(模型微调Fine-tune)
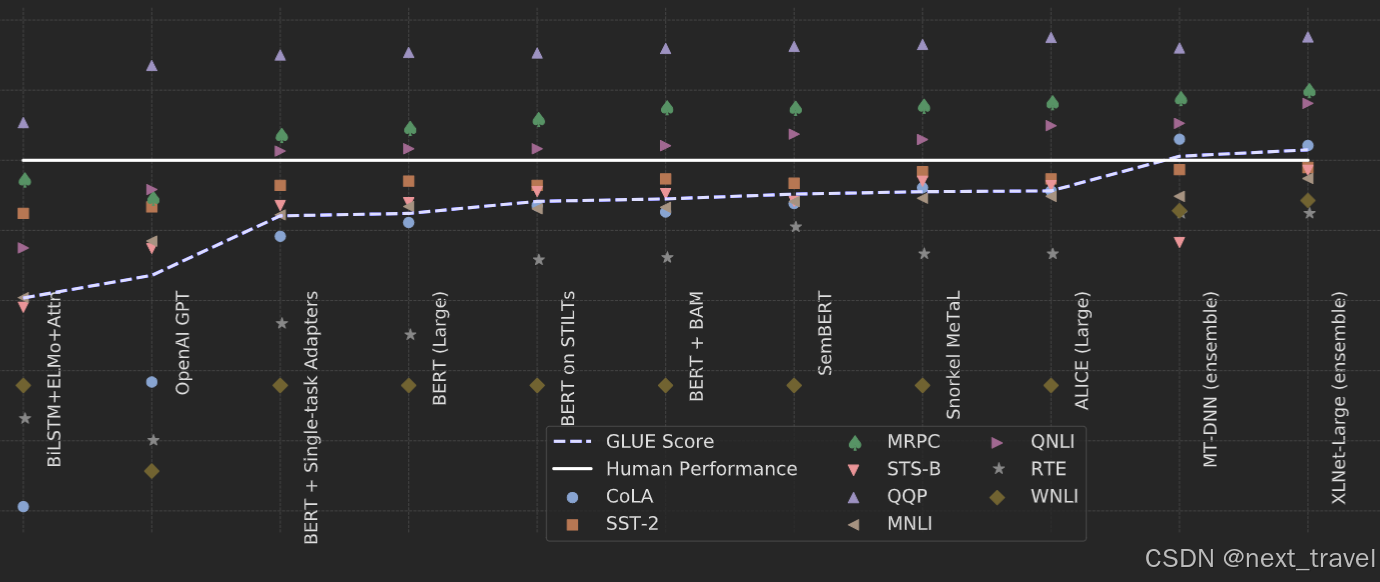
使用GLUE(General Language Understanding Evaluation)link 来评估BERT在九个任务集中的效果
下面是BERT在自然语言处理中的分数表现,可以看出随着BERT的提出,各种BERT变体的出现,和人类表现相比模型的表现越来越好了link。

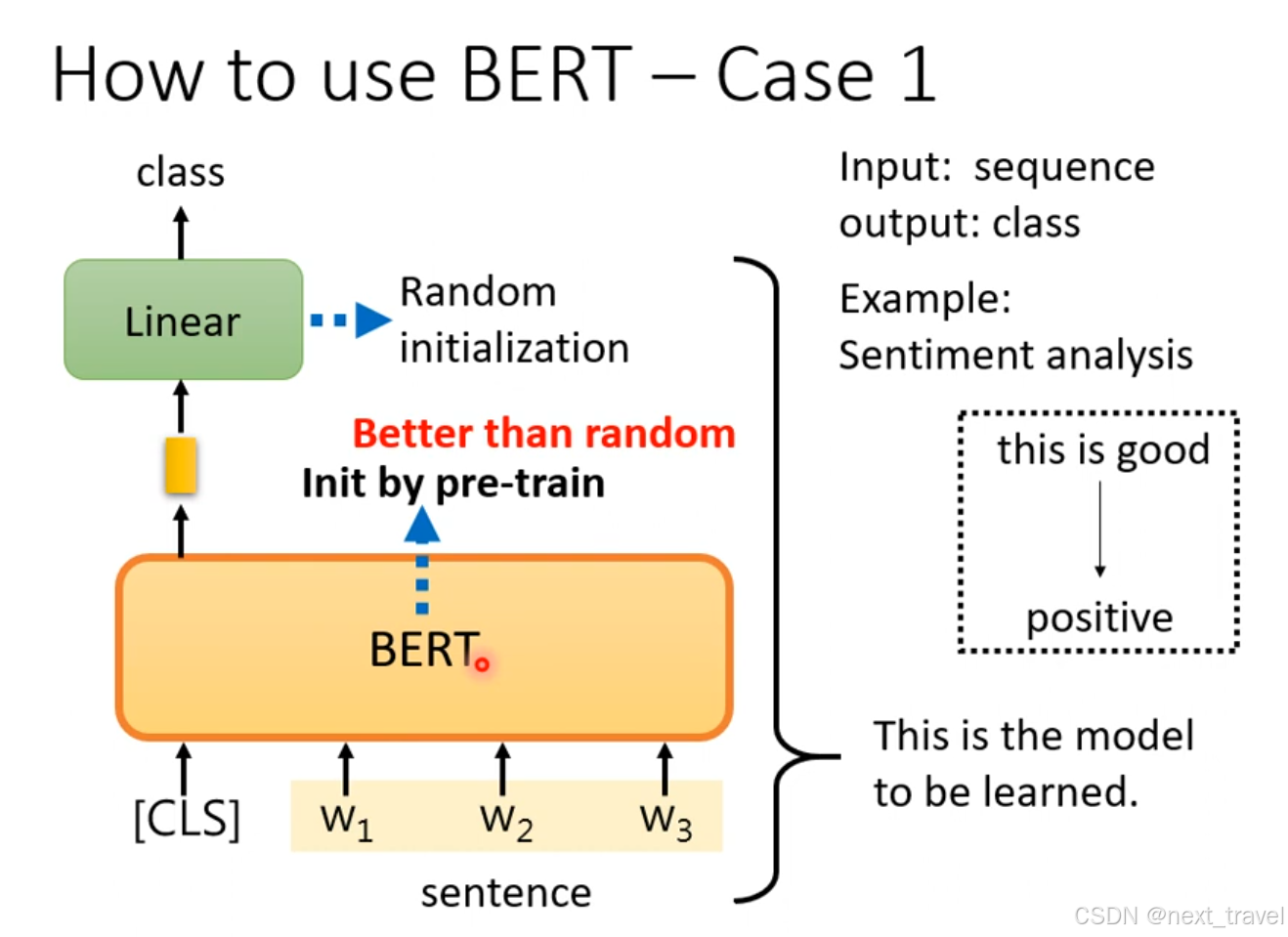
那么应该如何使用BERT?
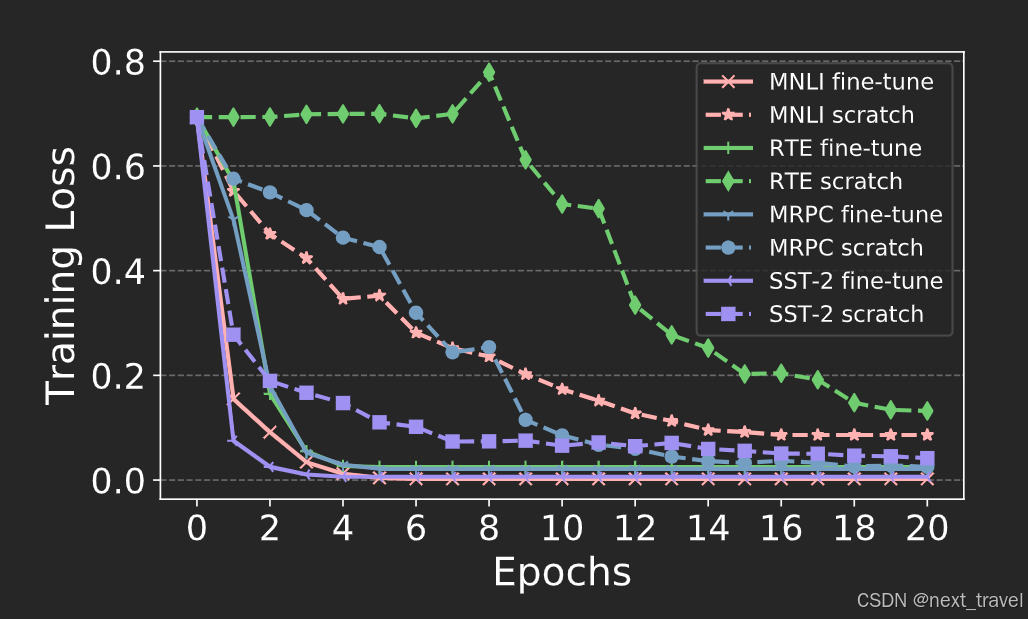
BERT的参数初试化和训练模型相关(比随机初始化要好),
下面是使用预训练好的参数初始化(fine-tune)和随机初始化(scratch)的对比link:
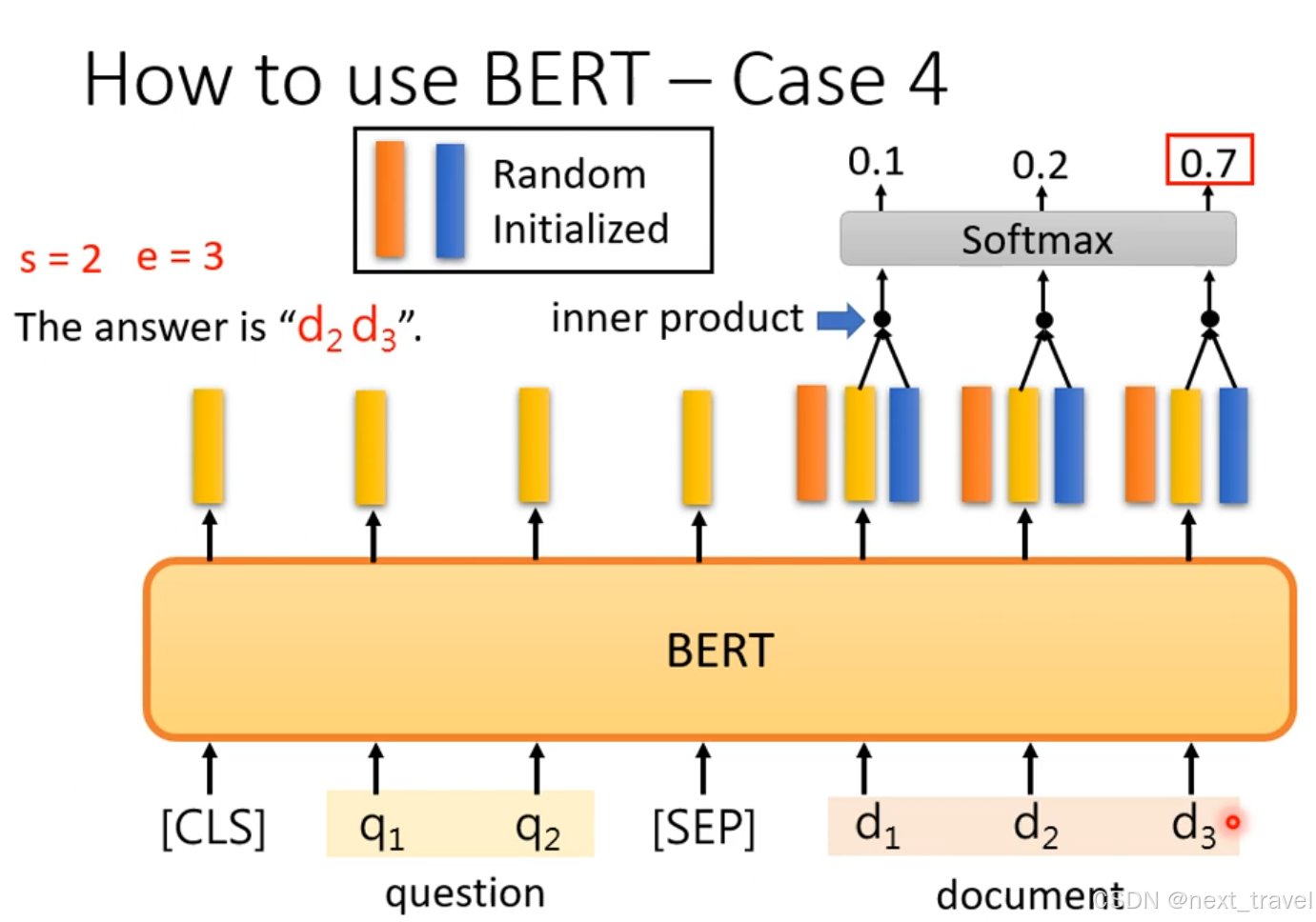
在问题系统中,开始是给定一段文本,怎么找到一句话在文本中的起始位置和结束位置,最后返回在文本的位置信息(s,e)
思考: BERT最初是为了解决填空任务上的,为什么可以处理其他任务,如QA任务等?
尽管BERT的预训练任务是填空,但它的双向上下文理解能力使其在各种自然语言处理(NLP)任务中表现优异。关键在于BERT学到的通用语言表示可以被迁移到不同的任务中。
4.论文阅读
本周阅读论文BERT:Per-training of Deep Bidirectional Transformers for Language Understanding
有两种策略将预先训练的语言表示应用于下游任务:基于特征和微调。
1.基于特征的方法:
如ELMo,使用特定的任务架构,其中包括预训练的表示作为附加特征。
2.微调的方法:
如OpenAI GPT,引入了最小的特定的任务的参数,并通过简单的微调所有与训练参数来对下游任务进行训练。(作者使用从左到右的架构,其中每个Token只能关注Transformer的自注意力层中的先前Token,这种限制杜宇句子级任务来说并不是最优的,并且使用基于微调的方法应用于标记级任务(如QA)有可能结果不好)
上述两种方法在预训练区间共享相同的目标函数。
背景:
当前的技术限制了预训练表示的能力,特别是对于微调方法。 主要限制是标准语言模型是单向的,这限制了预训练期间可以使用的架构的选择。 例如,在 OpenAI GPT 中,作者使用从左到右的架构,其中每个令牌只能关注 Transformer 的自注意力层中的先前令牌(Vaswani 等人,2017)。 这种限制对于句子级任务来说并不是最优的,并且当将基于微调的方法应用于标记级任务(例如问答)时可能非常有害,因为在这些任务中,从两个方向合并上下文至关重要。BERT 是第一个基于微调的表示模型,它在大量句子级和标记级任务上实现了最先进的性能,优于许多特定于任务的架构。
方法:
在预训练期间,模型在不同的预训练任务中使用未标记的数据进行训练。 对于微调,BERT 模型首先使用预先训练的参数进行初始化,然后使用来自下游任务的标记数据对所有参数进行微调。 每个下游任务都有单独的微调模型,即使它们是使用相同的预训练参数进行初始化的。图一是基于BERT模型的问答示例
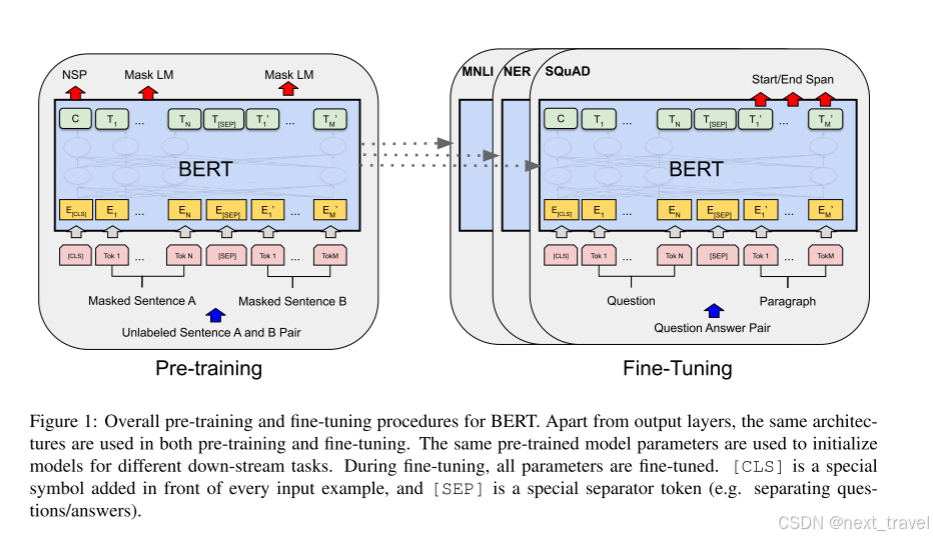
在BERT中,对于给定的标记,其输入表示是通过对相应的标记、段和位置嵌入求和来构造的。

BERT相对于其他单向模型的改进:
- 双向预训练(Bidirectional Pre-training):BERT使用Masked LM预训练目标,允许模型在所有层中联合考虑左右上下文,而不像传统的语言模型那样只能单向预测。
- 统一架构(Unified Architecture):BERT在不同任务之间使用统一的架构,预训练模型和下游任务模型之间的差异最小。
- 预训练任务(Pre-training Tasks):BERT引入了Next Sentence Prediction任务,帮助模型理解句子间的关系,这对于问答和自然语言推理等任务至关重要。
- 模型大小(Model Size):BERT提供了不同大小的模型,BERTBASE和BERTLARGE,后者在性能上有显著提升。
- 微调(Fine-tuning):BERT在微调时只需添加少量任务特定的参数,这使得模型能够快速适应不同的下游任务。
5.总结
自监督学习通过自我监督的方式,旨在学习一种通用的特征表达,用于下游任务。生成式学习关注像素空间的重建误差,而对比学习则关注特征空间中不同输入的区分。BERT模型通过双向上下文理解和大量参数,显著提升了自然语言处理任务的性能。BERT采用无监督预训练和有监督微调的方式,实现了在多个任务上的优异表现。尽管BERT在训练成本、长序列处理能力以及可能学习数据偏见方面存在局限性,但其在NLP领域的贡献是巨大的,为后续的研究和应用提供了重要的基础。