⭐博客主页:️CS semi主页
⭐欢迎关注:点赞收藏+留言
⭐系列专栏:数据结构初阶
⭐代码仓库:Data Structure
家人们更新不易,你们的点赞和关注对我而言十分重要,友友们麻烦多多点赞+关注,你们的支持是我创作最大的动力,欢迎友友们私信提问,家人们不要忘记点赞收藏+关注哦!!!
排序 -- 归并排序、计数排序和排序总结
前言
归并排序的算法难度较大而且细节较多,我们在进行归并排序的时候,需要注意的细节过于多,尤其是非递归版本需要注意越界的问题,这个是需要重点考虑的,后面的计数排序是比较基础,也比较好理解的,但同样也是有细节需要注意的,就比如这个range的问题以及我们数组需要选择多少的问题,最后,我给出进行排序数组的时间比较,这里用的是随机数,我们可以控制几万个、几十万个甚至几百万个随机数,用来帮助我们理解。
一、归并排序
1、递归版本
(1)思路及演示
归并排序是采用分治法的一个典型应用。是将已经有序的子数组进行合并,得到完全有序的序列,是先将每个子数列有序,再将子序列段间有序,若将两个有序表合并成一个有序表,称为二路归并。
我们看到上图,归并的基本思路就是先分解再合并,其核心要义在于如何去拆分每一个子序列并将每个子序列进行合并再将他们合并回去。
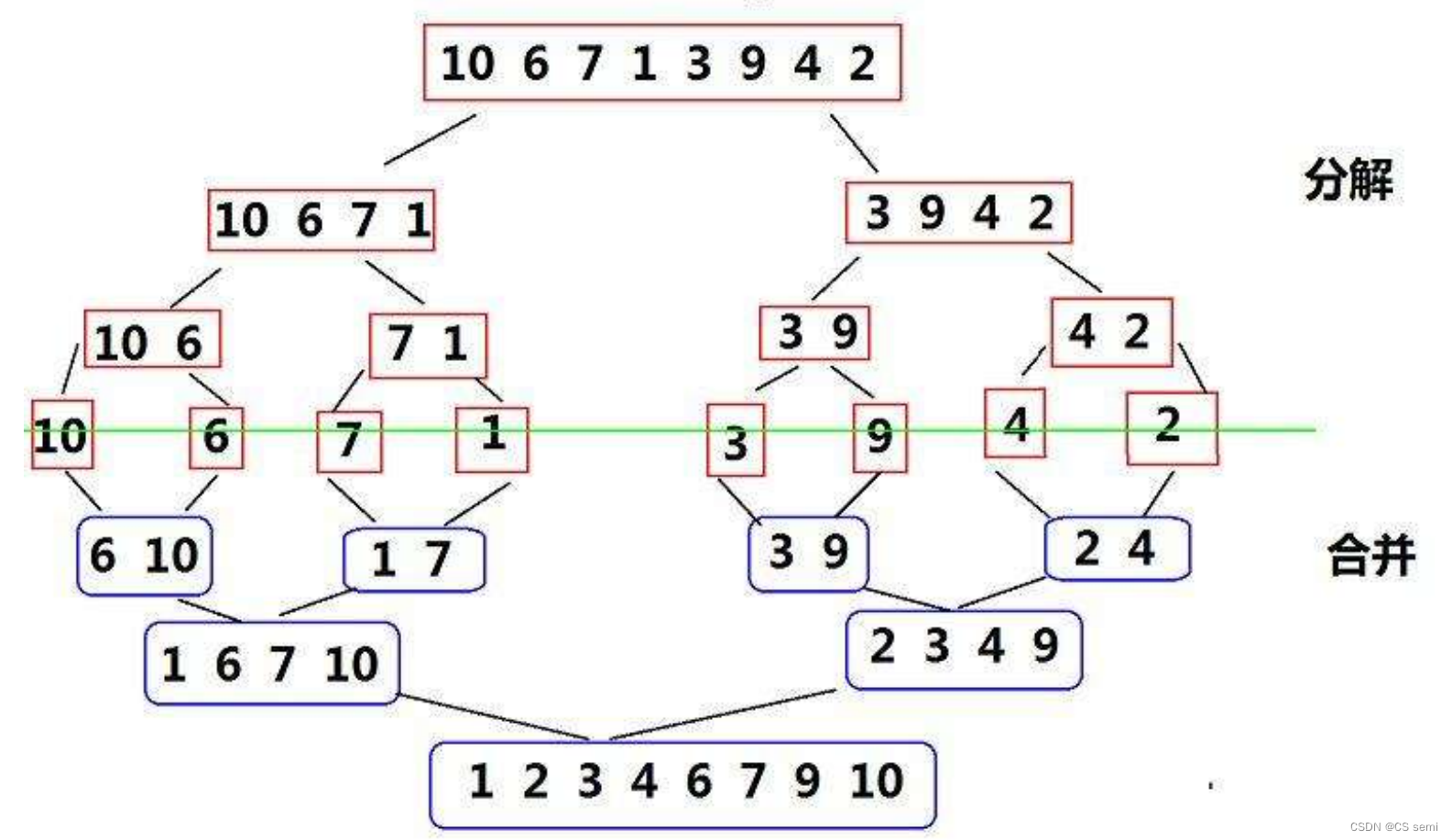
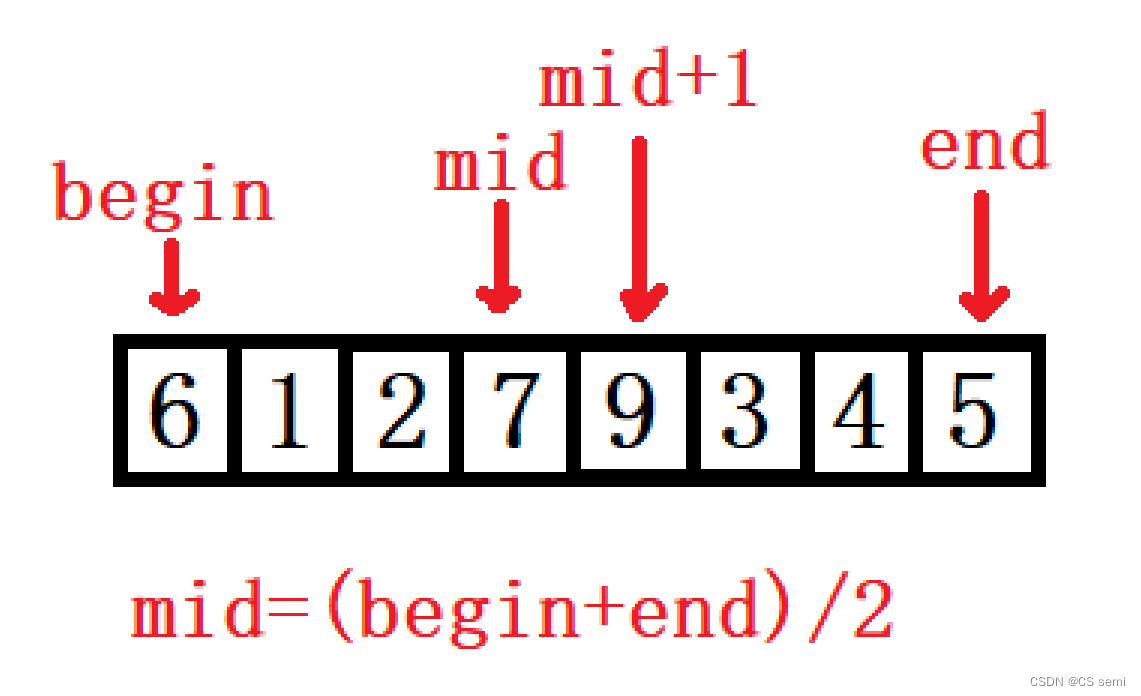
1、我们利用类似于二叉树的后序遍历,找出数组中间的下标,将分开的两个子序列再进行拆分,直到拆到只有一个子序列停止。
2、拆分方法:找mid,再递归,直到只剩一个子序列。
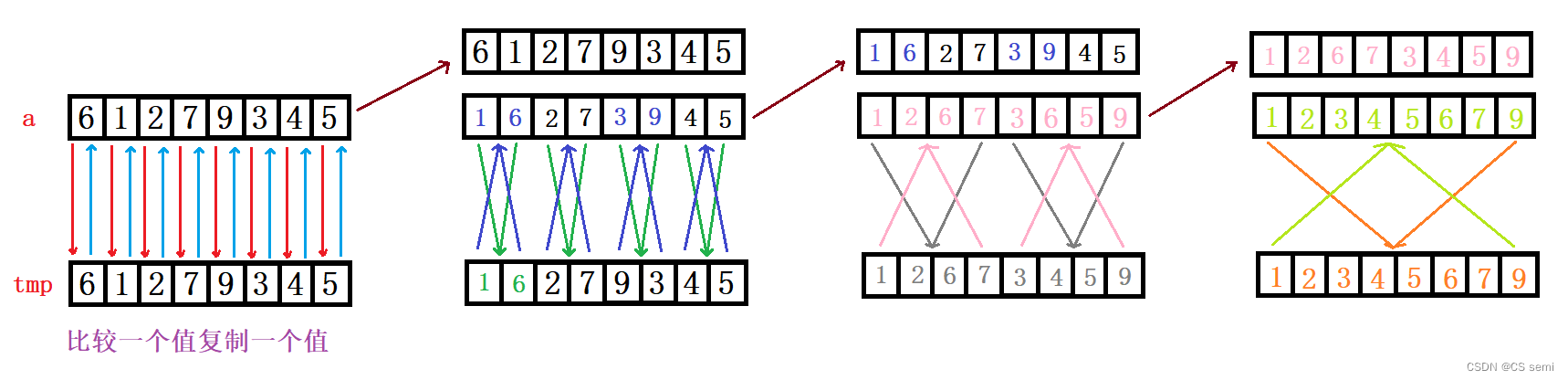
3、将所有的子序列拆分开以后,我们进行排序,就像下图紫框框里的步骤演示一样,我们将两个数组从两个头开始进行比较,小的数尾插到tmp临时数组中,最后将这些数全部拷回a数组中即可。
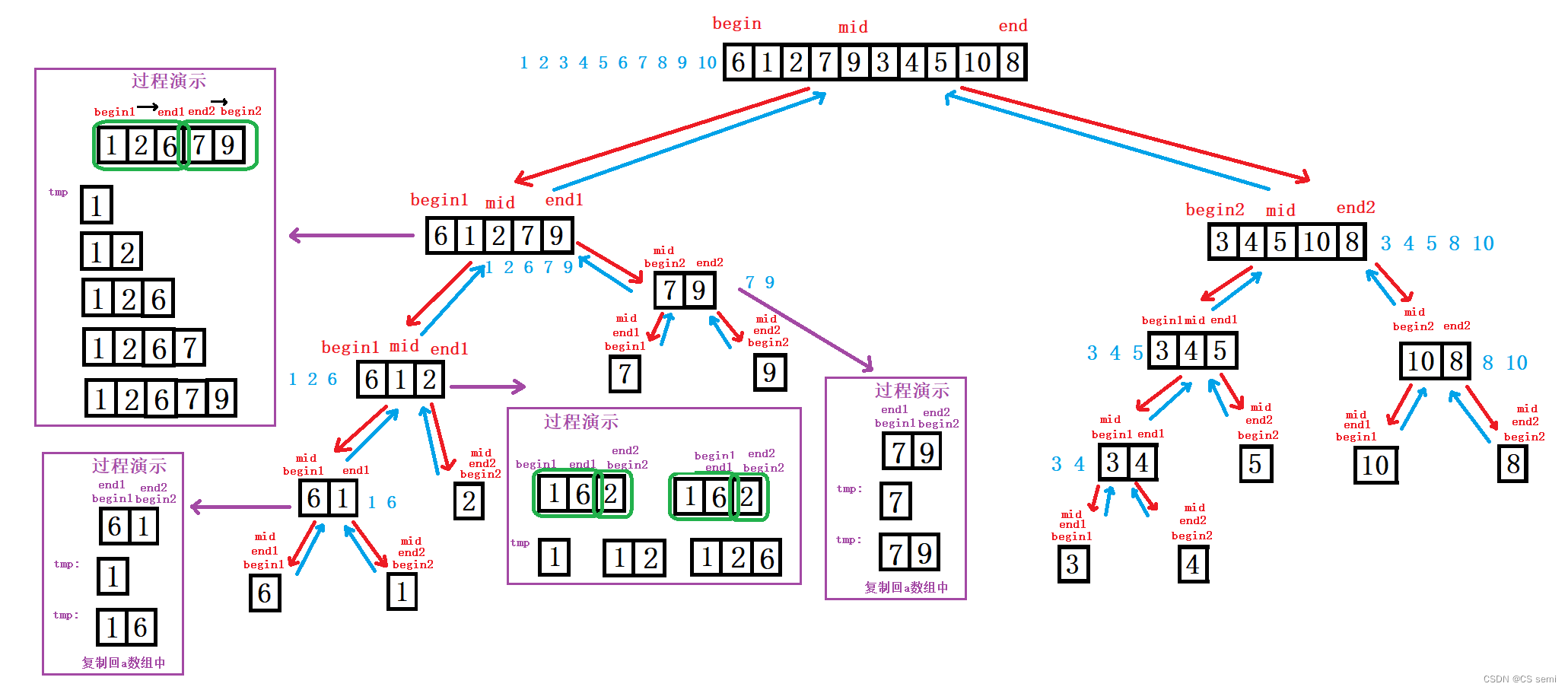
(2)代码
//归并排序 -- 初始递归版本
void _MergeSort(int* a, int begin, int end, int* tmp)
{
//控制返回条件
if (begin >= end)
return;
//先算出中间数据的下标
int mid = (begin + end) / 2;
//递归
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
//将区间进行赋值,不会改变原来的值
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
//归并回去
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
//尾插
tmp[i] = a[begin1];
i++;
begin1++;
}
else
{
tmp[i] = a[begin2];
i++;
begin2++;
}
}
//剩余的数继续尾插,利用循环解决
while (begin1 <= end1)
{
tmp[i] = a[begin1];
i++;
begin1++;
}
while (begin2 <= end2)
{
tmp[i] = a[begin2];
i++;
begin2++;
}
//复制回去
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc::fail\n");
return;
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}
2、非递归版本
(1)梭哈版本
也就是先排好序再进行拷贝回去。
(i)思路及演示
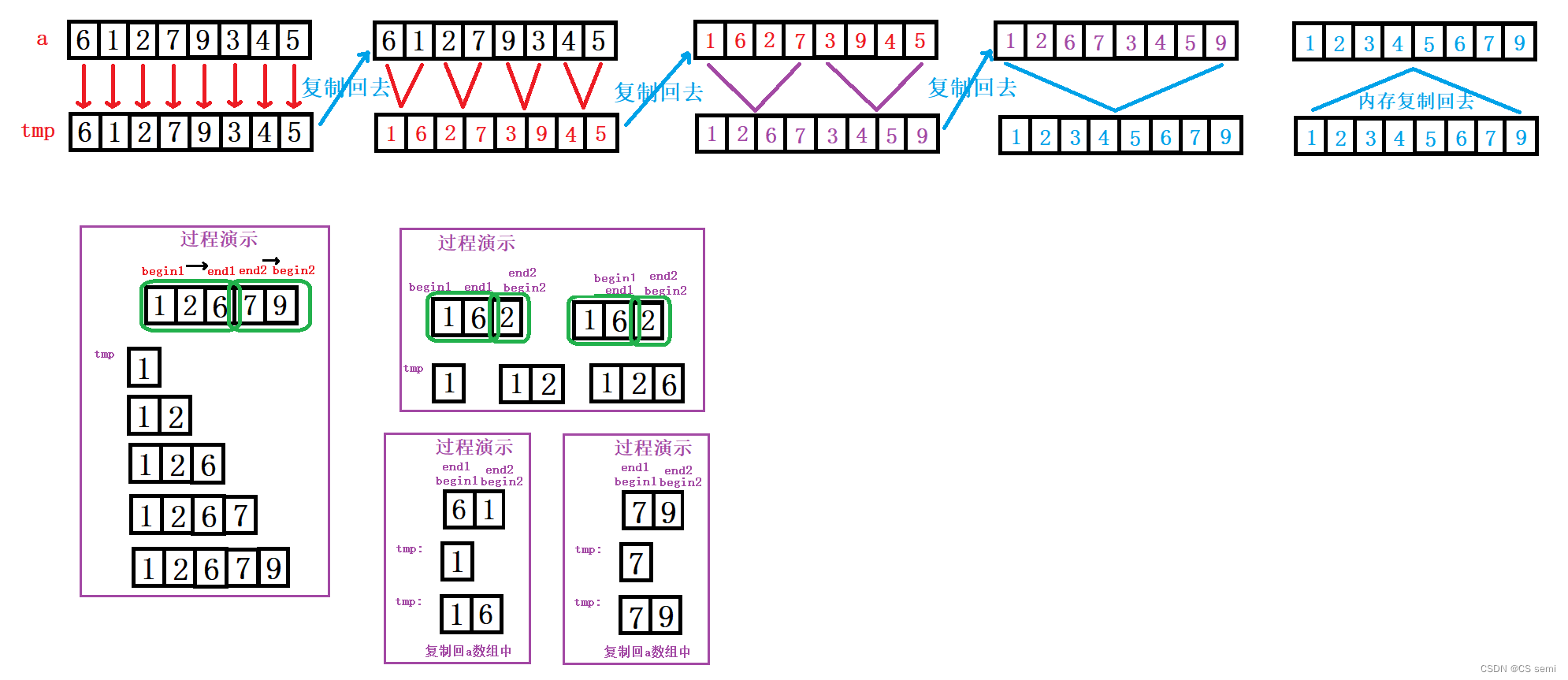
解题思路:
总体思路:暴力循环解决,这个与快速排序不一样的是快速排序是借助栈进行解决非递归版本的。
1、先找一轮游:我们看上面的图,我们以八个数据进行举例子,先进行一一归并,第一组数据是6和1,6对应着begin1和end1;1对应着begin2和end2,然后begin1和end1跳过一个数到2的位置;我们推出规律:i每次跳2个gap的距离,begin1是跟着i走的,end1是i+gap-1,begin2是end1的下一个位置也就是i+gap,end2可以效仿end1的思路的位置,也就是i+2*gap-1的位置。
2、第二轮:此时的gap增长到2了,我们依旧看我们的begin1、end1与begin2、end2的规律,begin1可以跟着i的步伐来,因为每次i往后走两个gap的距离,由上图知begin1先在6的位置,第二轮的位置在2的位置,所以begin1即跟着i的步伐走;end1是往后gap-1个位置,也就是end1是i+gap-i;begin2又是end1的后一个位置,即为i+gap;end2又可以找规律,是begin2往后gap-1个位置,则i+gap+gap-1即为i+2*gap-1。
3、最终步:取小的尾插到新数组,解释:begin1和end1之间的数和begin2和end2之间的数进行比较,先从begin开始进行比较,小的数进行尾插到新数组中,经过完一轮以后将这些个数据进行复制回原数组,一直持续到有序即可。
我们有了上述的思路就可以进行写代码了,我们写下述图片的代码看一下是否正确:
看起来很不错呀!这排序成功了!难道就是完全成功了吗,我们用10个数进行测试一下:
十个数崩了,我们利用打印每一轮的begin与end数来看一下到底是不是越界了:
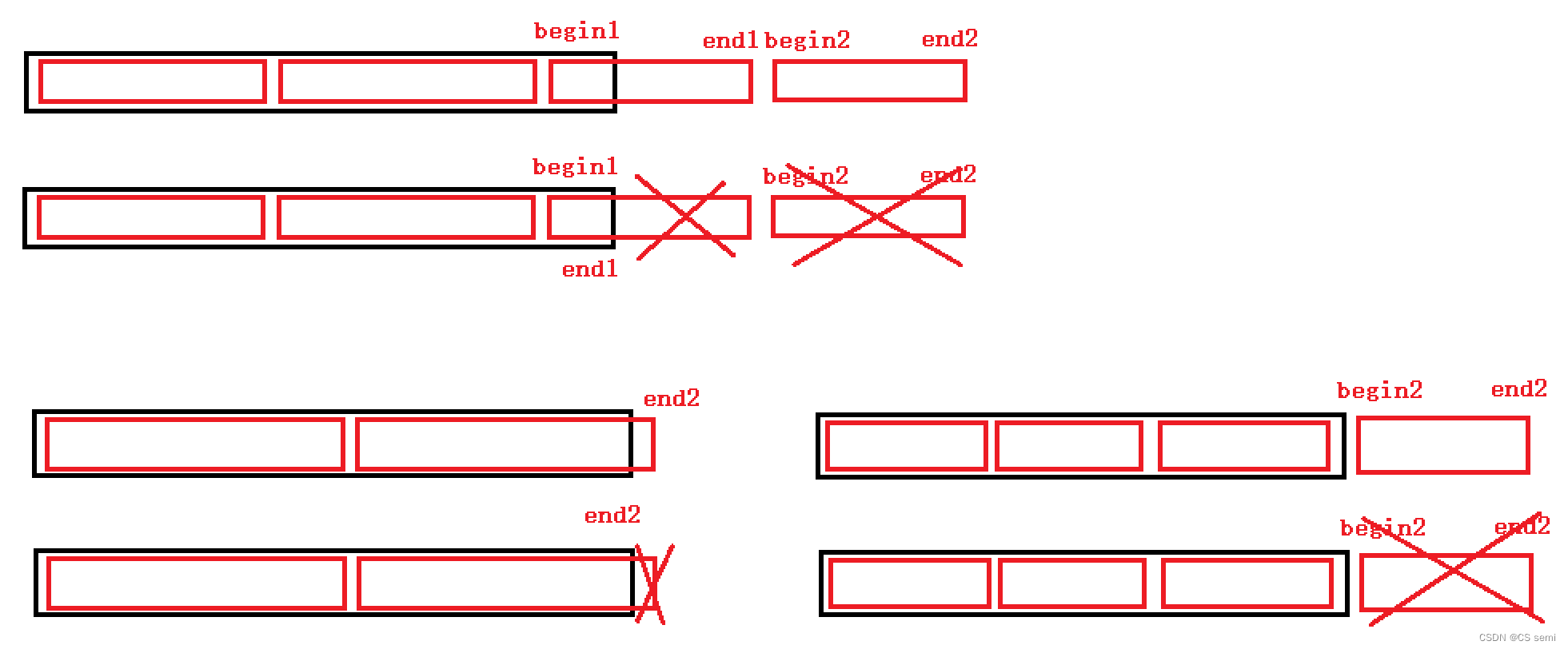
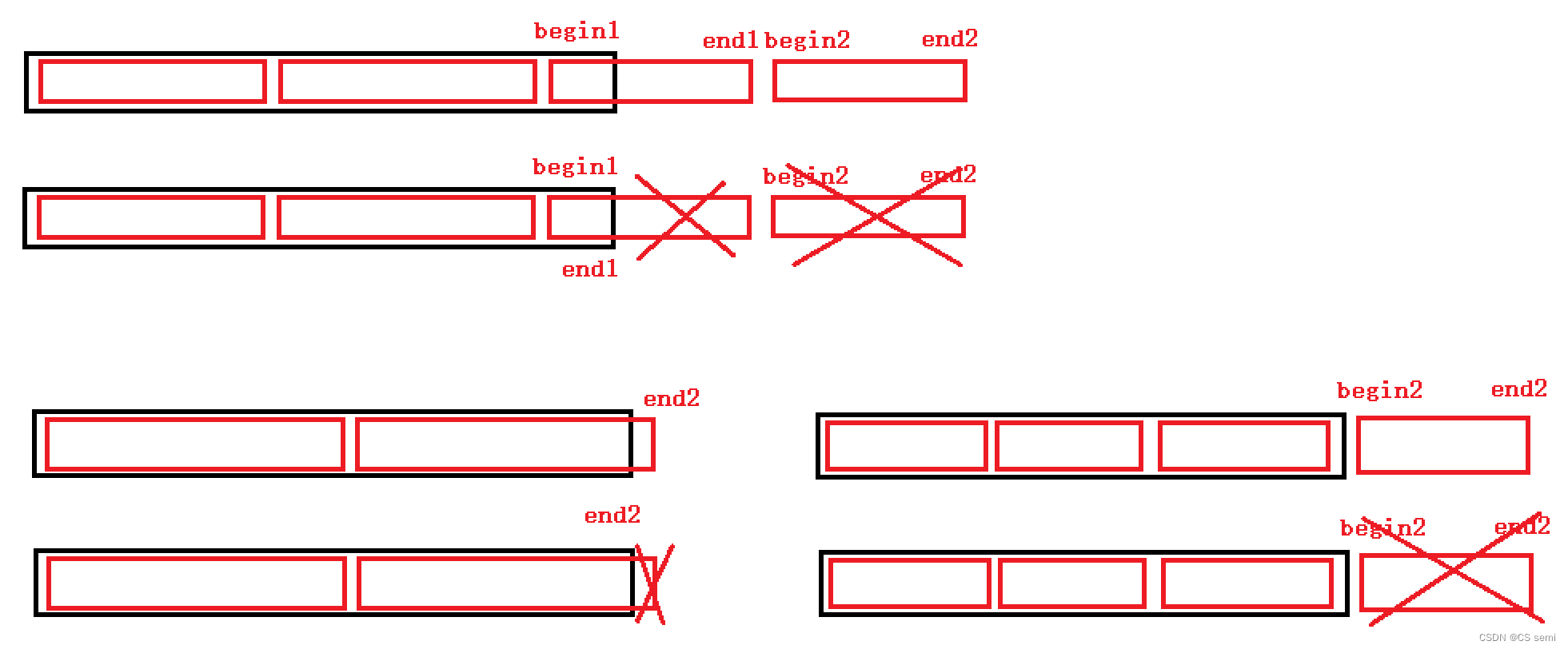
三种情况改法:

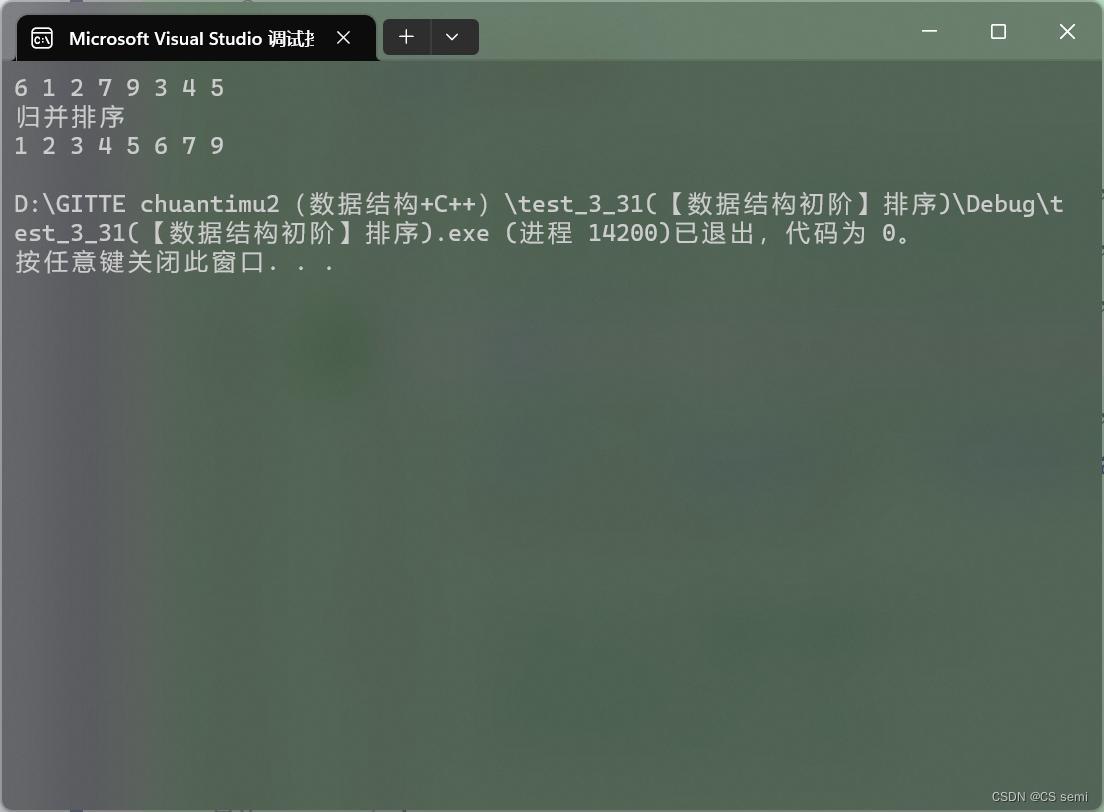
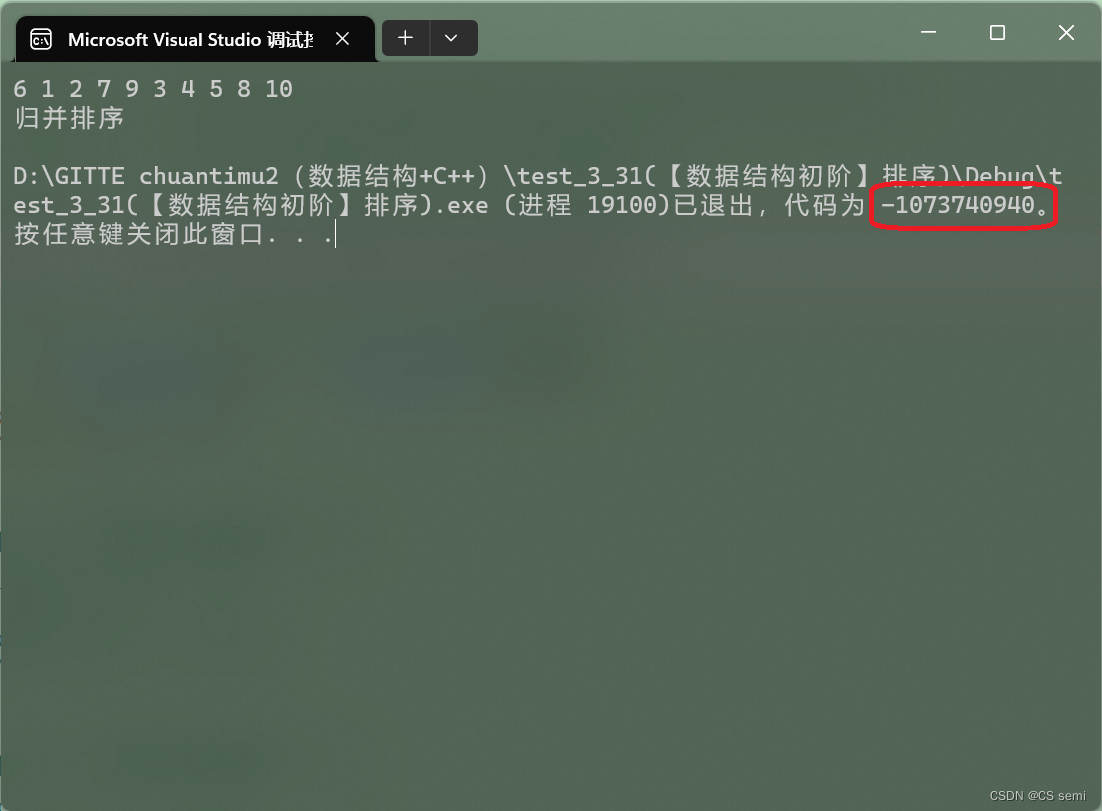

1、begin2越界:只需要造一个不存在的空间即可,因为造一个不存在的空间下面的循环根本进不去,这个不存在的空间是end2要小于begin2,与下面循环相对应。
2、end1越界:end1越界,后面begin2和end2必然越界,先造begin2和end2不存在的空间,再将end1赋值到数组的最后一个元素。
3、end2越界:只需要将end2放到数组最后一个元素即可。
增设条件:

(ii)代码
//整体复制
void _MergeSortNonREn(int* a, int begin, int end, int* tmp)
{
int gap = 1;
int n = end - begin + 1;
while (gap < n)
{
//一轮
for (int i = 0; i < n; i += 2 * gap)
{
//将区间进行赋值,不会改变原来的值
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
int j = i;
if (end1 >= n)
{
end1 = n - 1;
begin2 = n;
end2 = n - 1;
}
else if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
else if (end2 >= n)
{
end2 = n - 1;
}
//归并回去
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
//尾插
tmp[j] = a[begin1];
j++;
begin1++;
}
else
{
tmp[j] = a[begin2];
j++;
begin2++;
}
}
//剩余的数继续尾插,利用循环解决
while (begin1 <= end1)
{
tmp[j] = a[begin1];
j++;
begin1++;
}
while (begin2 <= end2)
{
tmp[j] = a[begin2];
j++;
begin2++;
}
}
memcpy(a, tmp, sizeof(int) * n);
gap *= 2;
}
}
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc::fail\n");
return;
}
_MergeSortNonRPa(a, 0, n - 1, tmp);
free(tmp);
}
(2)老实版本
(i)思路及演示
总体思路与上个版本的思路一样,只需要改变拷贝的值以及判断越界的条件即可。
修改:
1、修改memcpy内:memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));因为我们是归并一次修改a数组一次,用的是i,因为begin1在不断改变。
2、修改越界条件:end1或者begin2越界以后直接跳出循环,不进行归并复制即可,end2越界以后只需将end2放到数组最后一个数即可。
(ii)代码
//归并排序 -- 非递归版本
//一点一点复制
void _MergeSortNonRPa(int* a, int begin, int end, int* tmp)
{
int gap = 1;
int n = end - begin + 1;
while (gap < n)
{
//一轮
for (int i = 0; i < n; i += 2 * gap)
{
//将区间进行赋值,不会改变原来的值
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
int j = i;
if (end1 >= n || begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
//归并回去
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
//尾插
tmp[j] = a[begin1];
j++;
begin1++;
}
else
{
tmp[j] = a[begin2];
j++;
begin2++;
}
}
//剩余的数继续尾插,利用循环解决
while (begin1 <= end1)
{
tmp[j] = a[begin1];
j++;
begin1++;
}
while (begin2 <= end2)
{
tmp[j] = a[begin2];
j++;
begin2++;
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
}
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc::fail\n");
return;
}
_MergeSortNonRPa(a, 0, n - 1, tmp);
free(tmp);
}
3、特性总结
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
二、计数排序
1、思路及演示
思路:
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。 操作步骤:
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列
三板斧:
1、寻找最大值和最小值,算范围:这里就是比较简单的操作了,算出max和min,最终的范围为大的减小的再加一。
2、创立数组进行计数:创立一个新数组,数组的大小为range,且里面的数据全为0(可以利用两种方法,一种方法为使用calloc,另一种是malloc+memset),我们这里用的是相对位置,也就是说无论怎样数组都是从下标为0开始的,counta[a[i] - mincount]就是从下标为0开始的,将这个数在counta数组的指定位置进行加加。
3、排序:这里另外设置一个变量为0(这里很关键,因为这样才在循环中进入并加加),将counta数组进行减减,每减一次就将数据存入a数组中,这里最关键的是k+mincount,因为之前减过mincount了。

2、代码
//计数排序
void CountSort(int* a, int n)
{
//找最大值和最小值
int maxcount = a[0];
int mincount = a[0];
for (int j = 0; j < n; j++)
{
if (a[j] > maxcount)
{
maxcount = a[j];
}
if (a[j] < mincount)
{
mincount = a[j];
}
}
//算范围
int range = maxcount - mincount + 1;
int* counta = (int*)calloc(sizeof(int) * range, sizeof(int));
if (counta == NULL)
{
perror("malloc fail\n");
return;
}
//计数
int i = 0;
for (i = 0; i < n; i++)
{
//给相对位置加加
counta[a[i] - mincount]++;
}
//排序
int l = 0;
for (int k = 0; k < range; k++)
{
while (counta[k]--)
{
a[l] = k + mincount;
l++;
}
}
free(counta);
}
3、特性总结
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,范围))即O(N+range)
- 空间复杂度:O(范围)
- 稳定性:稳定
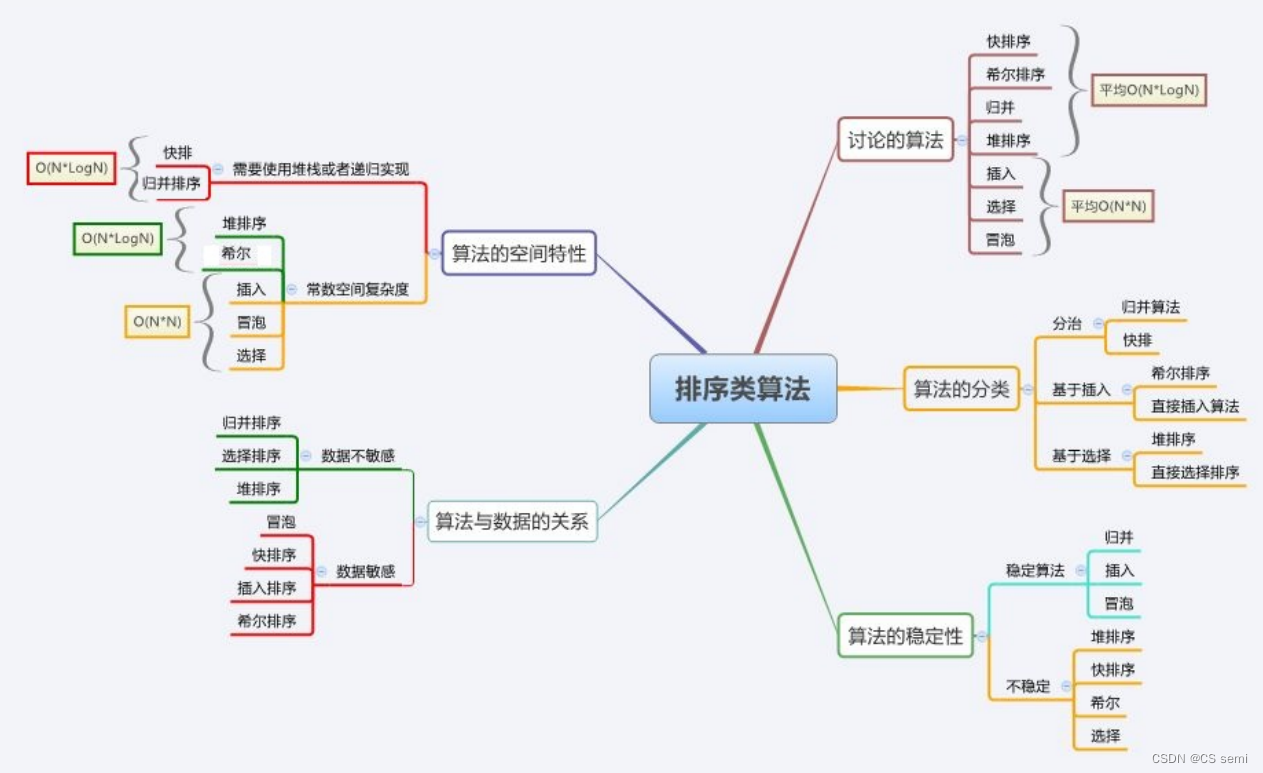
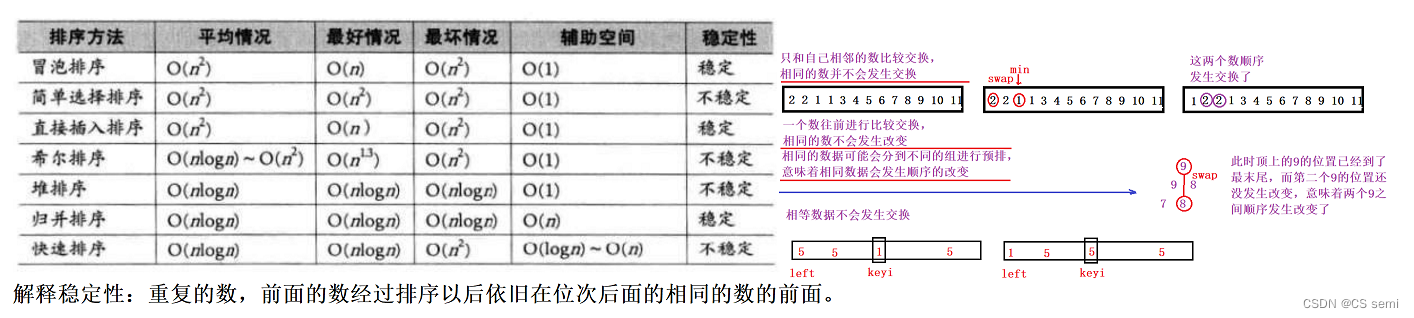
三、排序总结
总结
到此排序就告一段落了,想了解更多的排序我们需要更加深入了解诸如基数排序、桶排序等,掌握了以上的这些排序,也就是掌握了绝大多数的排序内容!
家人们不要忘记==点赞收藏+关注哦!!!