
接下来是我对学了Django和前后端分离需要的DRF的记录,这些记录我只会保留前后端分离需要的部分,其余的,比如模板,视图函数之类的,我并不会记录,因为DRF使用的是视图类而不是视图函数。
一.Django项目准备
我们想要学习Django+DRF,我们先要知道怎么创建一个项目。下面是我们所需要的一些准备:
- Django版本:4.1
- DRF版本:3.14.0
- 虚拟环境创建工具:anaconda2021.11
- 虚拟环境:python3.9
- django-filter版本:23.3
- PyCharm专业版2023.1
1.下载anaconda
直接去清华大学镜像源网站那里下载就行了,链接如下:
划到下面去,选择自己适合的版本,最好不要选择最新的,我之前就下了一个2023的版本,导致了自己的pytorch下载失败。我下载的是2021.11版本的,如下图。
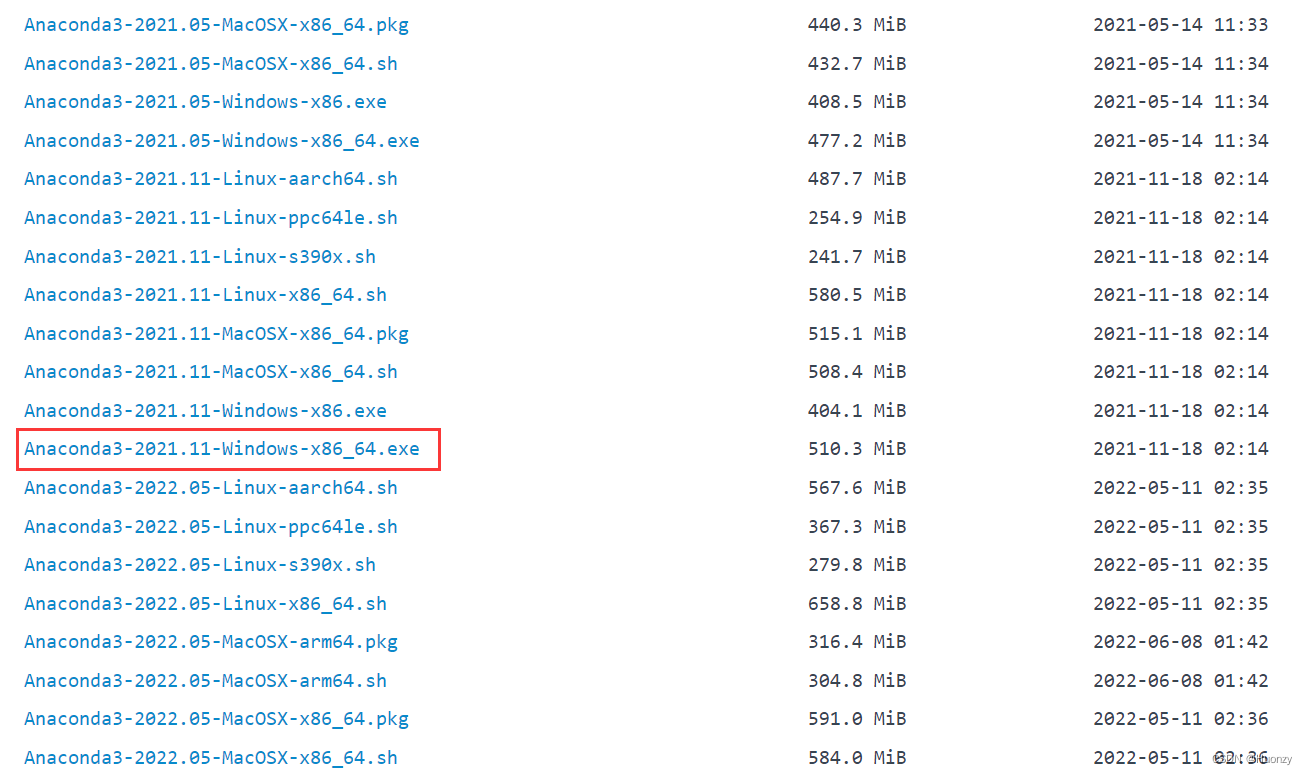
下载完这个exe后,点击它运行,安装位置需要自己选择,最好不要安装在C盘,还有,记得勾选添加进环境变量,然后剩下的都默认选项,安装完后不要让它自己启动anaconda,因为我们不需要。还有一点要注意,自己选择安装位置时,ananconda的安装目录一定不要乱取名字,就Anaconda2021就行了,不要起Conda2021.11这样子的,否则你会在开始菜单栏那里找不到Anaconda3目录,这样子对启动Anaconda Prompt很不方便。
2.创建虚拟环境
下载完anaconda后就可以去创建虚拟环境了,直接在开始栏那里找到Anaconda3目录(左下角的windows图标)。找到后点击Anaconda Prompt,进入到一个命令行窗口。
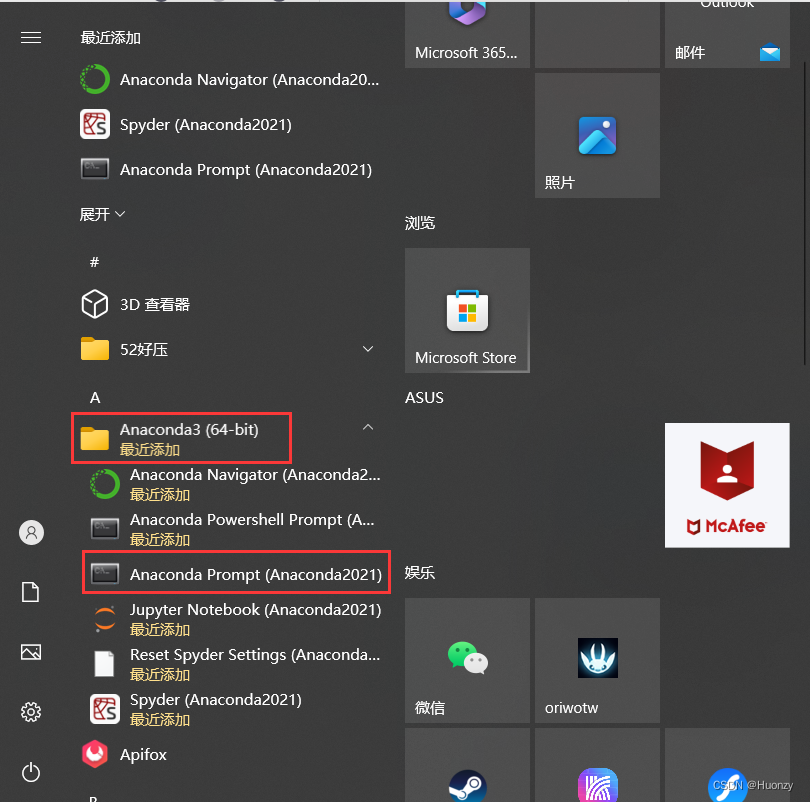
在窗口里面输入下面的命令,会创建一个虚拟环境,XXX代表该虚拟环境名称,可以随便起名,但不能出现中文字符,我这里起名为pytorch。
conda create -n XXX python=3.93.下载Django和DRF包
我们先在Anaconda Prompt中输入下面的命令以进入我们之前创建的虚拟环境中:
conda activate XXX我们有两种方式下载,一种是conda,一种是pip,在这里我们选择pip,因为conda方式下载可能会找不到。
pip install django==4.1pip install djangorestframework==3.14.0pip install django-filter==23.34.创建Django项目
创建Django有两种方式,我这里直接使用PyCharm专业版2023.1创建。如果大家没有的话,去网上找破解版,网上一堆破解版,随便挑一个按照其过程下载就行了。实在不行,直接去jetbrains官网申请学生认证,需要2到3天,申请成功后,所有jetbrains产品可以免费使用一年。
新建一个项目,进入项目种类选择界面。
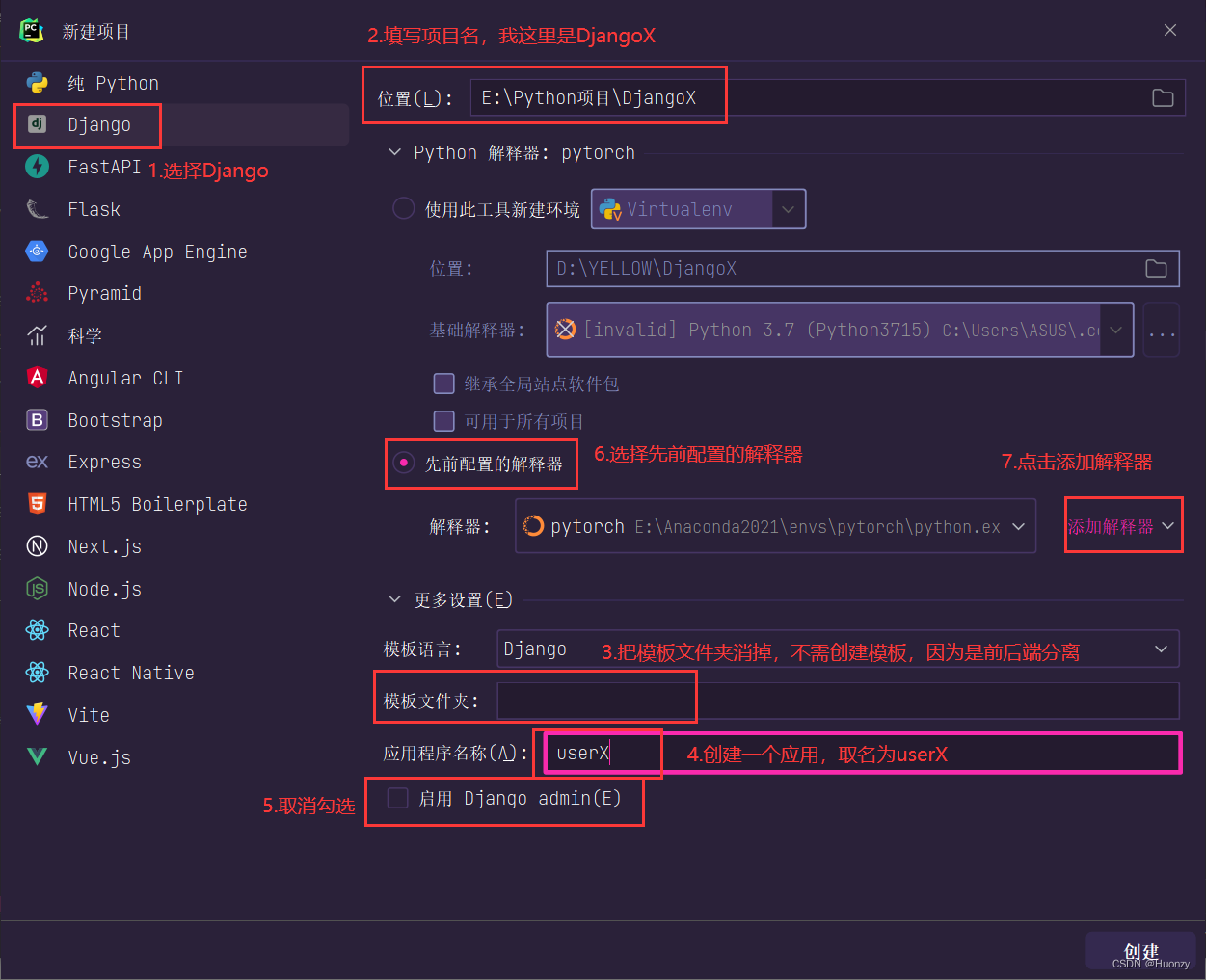
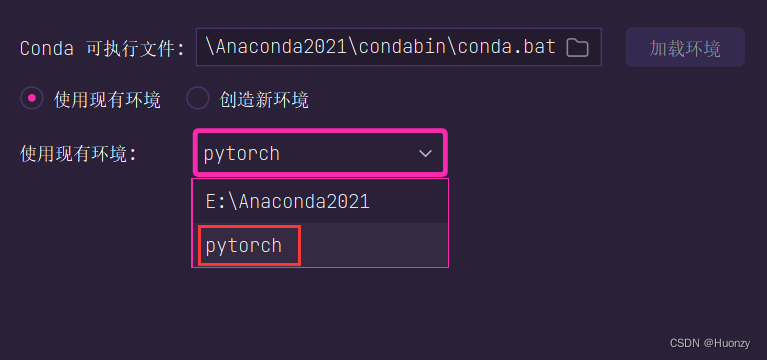
最后一步点击添加解释器后,会跳出另一个界面,让我们去找解释器,我们需要回到anaconda安装目录下,找到一个conda.bat的文件,如下图所示:
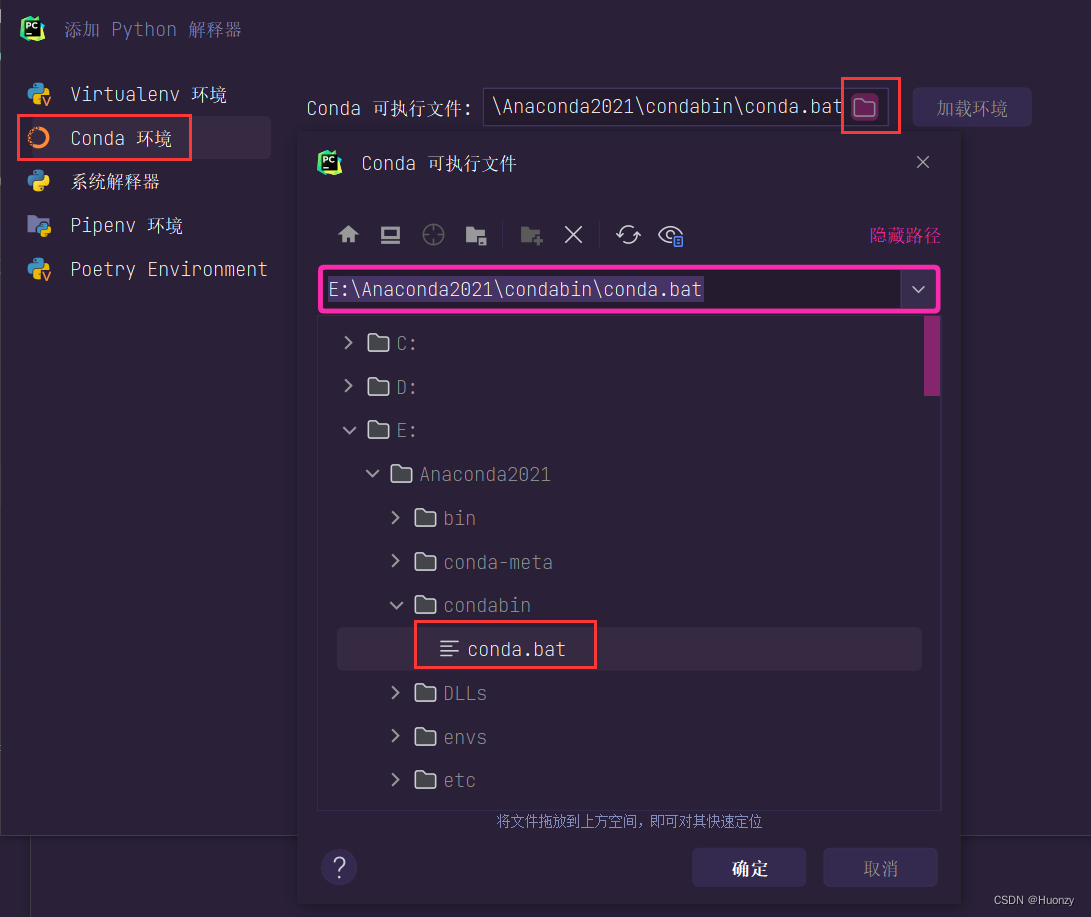
上图点击确定后,再选择我们刚才创建好的虚拟环境,如下图,我自己创建的虚拟环境是pytorch,选择完后,点击确定,返回之前的界面,再点击确定,然后就创建好Django项目了。
5.启用DRF
我们创建了Django项目后,并不会自动使用DRF,所以我们要手动添加进来。具体操作如下:
- 第一步,进入到默认目录的setting.py文件下,其实这个setting.py在整个项目就一个,你去找一找就能找到了
- 第二步,在该文件找到一个INSTALLED_APPS变量,然后在最后面填上rest_framework,如下:
INSTALLED_APPS = [ "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", 'userX.apps.UserxConfig', #上面是创建项目后自带的,下面是后面自己添加的 "rest_framework", ]
二.Django目录结构
在正式开始学习前,我们要熟悉刚刚创建出来的这个Django项目的目录结构,才能在后面的编程中如鱼得水。
1.默认目录结构

1.1 setting.py
from pathlib import Path
#项目根目录,在这里配置完后,后面如果出现了BASE_DIR / ,那就表示是项目的根目录的绝对路径。
# Build paths inside the project like this: BASE_DIR / 'subdir'.
BASE_DIR = Path(__file__).resolve().parent.parent
# SECURITY WARNING: keep the secret key used in production secret!
#不用动,确保唯一就行
SECRET_KEY = "django-insecure-ds+y^&!hh62js26^l*khp@df*9sylj4k)95=zis6r%l3y65t$^"
# SECURITY WARNING: don't run with debug turned on in production!
#是否调试模式
#True,一般用于开发过程中
#False,一般用于线上部署
DEBUG = True
#被允许的域名或ip,可以指定哪些域名或者ip可以访问Django后端项目。
# * : 表示通配符,匹配所有ip
ALLOWED_HOSTS = ['*']
# Application definition
#定义应用,创建该项目后会有一些已经有的默认应用
INSTALLED_APPS = [
"django.contrib.admin",
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
#userX是我创建项目时添加的应用,所有PyCharm自动帮我添加进去了。
'userX.apps.UserConfig',
#后面我又自己添加了一个应用,这回需要我自己手动添加该应用到这里了。
'appX',
"rest_framework",#使用DRF必须的配置
]
MIDDLEWARE = [
"django.middleware.security.SecurityMiddleware",
"django.contrib.sessions.middleware.SessionMiddleware",
"django.middleware.common.CommonMiddleware",
"django.middleware.csrf.CsrfViewMiddleware",
"django.contrib.auth.middleware.AuthenticationMiddleware",
"django.contrib.messages.middleware.MessageMiddleware",
"django.middleware.clickjacking.XFrameOptionsMiddleware",
]
# 根路由的路径
ROOT_URLCONF = "DjangoX.urls"
#模板
TEMPLATES = [
{
"BACKEND": "django.template.backends.django.DjangoTemplates",
"DIRS": []
,
"APP_DIRS": True,
"OPTIONS": {
"context_processors": [
"django.template.context_processors.debug",
"django.template.context_processors.request",
"django.contrib.auth.context_processors.auth",
"django.contrib.messages.context_processors.messages",
],
},
},
]
#wsgi的路径
WSGI_APPLICATION = "DjangoX.wsgi.application"
# Database
# https://docs.djangoproject.com/en/4.2/ref/settings/#databases
DATABASES = {
"default": {
#只支持关系型数据库,后面在学到整合Mysql时再回到这里修改,现在是默认的。
"ENGINE": "django.db.backends.sqlite3",
#第一次运行项目后才会出现db.sqlite3这个数据库,你们可以看一下我的项目目录,已经有了,因为我已经运行过了。
"NAME": BASE_DIR / "db.sqlite3",
}
}
#密码验证
AUTH_PASSWORD_VALIDATORS = [
{
"NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
},
{"NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",},
{"NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",},
{"NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",},
]
#国际化
LANGUAGE_CODE = "en-us"
TIME_ZONE = "UTC"
USE_I18N = True
USE_TZ = True
#静态文件
STATIC_URL = "static/"
DEFAULT_AUTO_FIELD = "django.db.models.BigAutoField"1.2 urls.py
from django.urls import path
from userX.views import UserView
urlpatterns = [#urls.py只需要有这一个就行了,里面就全都是path,比如说下面这一个path,代表访问user/这个url会执行userX应用的views.py里面的UserView这一个类视图,相当于一个springboot的一个控制类。
# path("admin/", admin.site.urls),
path("user/", UserView.as_view())
]2.应用目录结构
在应用目录结构中,我们只需要关注models.py和views.py即可,因为一个是容纳我们创建的模型的文件,一个是容纳我们类视图的文件。模型相当于springboot中的实体类+JPA,无需写sql语句即可访问数据库。类视图相当于springboot中的控制层类,起到与前端交互的作用。至于业务层,我们只需要创建其他的py文件来容纳我们构建的方法即可。

2.1 models.py
下面是一个简陋的模型,后面会具体讲怎么创建的:
from django.db import models
class User(models.Model):#继承models.Model
userName = models.CharField(max_length=30)#相当于数据库里的varchar(30)
password = models.CharField(max_length=18)2.2 views.py
一个简陋的类视图,后面会具体讲:
from django.http import HttpResponse
from rest_framework.views import APIView
class UserView(APIView):
def get(self, request):
print("get method is starting")
return HttpResponse("Get request is finish")
def post(self, request):
print("post method is starting")
return HttpResponse("Post request is finish")三.终端里经常要用到的命令
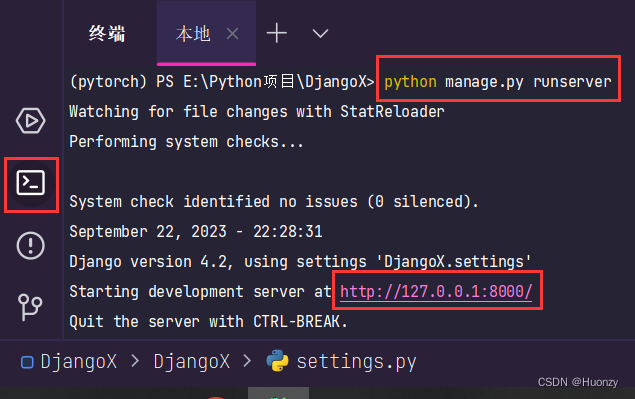
1.项目启动
想要启动项目,直接在终端里面输入python manage.py runserver就行了,默认的baseUrl是localhost:8000,我们想要修改端口的话,可以按照下面的图片进行。
启动项目后,我们如果修改了项目的代码,项目会自动重新启动的,不需要我们关闭了再重新启动。
2.数据迁移
迁移,就是将模型映射到数据库的过程,这个过程会自动帮我们建表,但是不会自动帮我们建数据库,所以我们还是要有一个提前准备好的数据库的。每次我们修改模型的属性的时候,我们都要重新进行数据迁移进行同步。
我们先输入一个命令,用来生成迁移文件,迁移文件会保存到对应应用的迁移文件夹里面,就是migrations文件夹。
python manage.py makemigrations紧接着,我们输入一个命令,执行迁移:
python manage.py migrate3.创建应用
创建应用可以直接再终端里输入下面的命令:
python manage.py startapp XXX (XXX换成自己的应用名字)创建应用后,我们需要手动将该应用添加进默认目录的setting.py里面的INSTALLED_APPS选项中,如下图:
INSTALLED_APPS = [
"django.contrib.auth",
"django.contrib.contenttypes",
"django.contrib.sessions",
"django.contrib.messages",
"django.contrib.staticfiles",
'userX.apps.UserxConfig',
#上面这些,都是项目创建的时候自带的应用
#如果我们创建了一个应用,这个应用名叫作books,那我们就要在这里添加进来
'books'
]四.模型
1.模型定义

上面是有关模型定义的一些说明,现在我们就先创建一个模型,如下:
from django.db import models
class User(models.Model):
userName = models.CharField(max_length=30)
password = models.CharField(max_length=18)
其实就是创建一个类,然后这个类继承了models.Model,这个类就是一个模型了,后面跟着的相当于是这个类的属性,只不过不需要在__init__里面声明,直接写,跟java和C++一样。
2.模型字段类型
我们知道,一个数据库表里面有许多字段,每个字段就会对应着模型的属性,而每个字段的类型可能不一样,接下来我们来介绍字段常用类型。



3.字段参数
接下来介绍一下一些常用的字段参数。



五.数据库基本操作
上面我们创建了模型后,只是建立了实体类和数据库表之间的映射,还没有进行过具体增删改查等操作,接下来我们会介绍数据库的增删改查。
1.增

2.删

3.改

4.查
4.1 基本查询

4.2 进阶操作


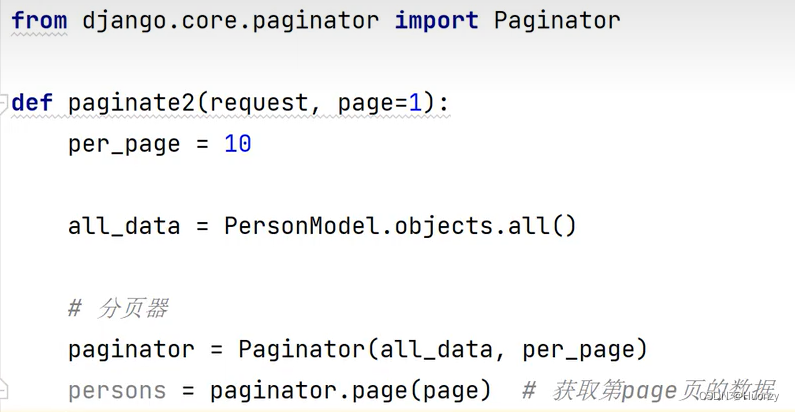
4.3分页
我们可以手动进行分页,将查询到的所有信息拿出一部分数据返回:

也可以借助分页器来进行分页操作,这个跟手动分页的本质是一样的,都是将所有数据从数据库中返回后再进行分页。
4.4聚合函数
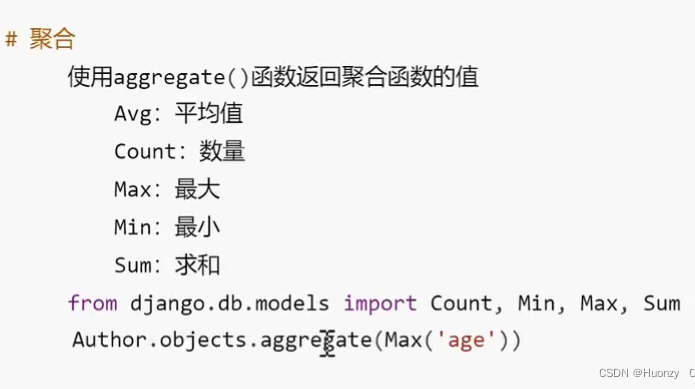
六.Mysql连接和操作
大家是不是有点疑惑,我上面都介绍了数据库操作,后面为什么还有Mysql操作。的确,我介绍了数据库操作,可是我并没有指定是哪个数据库的操作。其实上面的数据库操作是sqlite3的操作,因为sqlite3是我们创建Django项目后自带的数据库,我们的数据会存到这个sqlite3里面。其实sqlite3的操作跟mysql的操作一模一样,所以在上面,我们其实相当于也介绍了mysql的操作。上面的操作仅仅是单表操作,接下来我还会介绍mysql的多表操作,当然,在这之前,我会先介绍如何切换sqlite3成mysql。
1.Mysql连接
我们原来的项目的setting.py的数据库部分的配置是这样的:
DATABASES = {
"default": {
"ENGINE": "django.db.backends.sqlite3",
"NAME": BASE_DIR / "db.sqlite3",
}
}上面的配置代表了连接了sqlite3数据库,且这个数据库就在项目的根目录下,文件名为db.sqlite3。我们修改这个配置成Mysql的,变成了下面这样:
DATABASES = {
"default": {
"ENGINE": "django.db.backends.mysql",
"NAME": "djangox",#数据库名称
"USER": "root",#数据库的用户名
"PASSWORD":"123456",#密码
"HOST":"127.0.0.1",#数据库所在的主机IP
"PORT":"3306",#连接数据库的端口
}
}修改完配置后,记得要进行数据迁移,即输入上面介绍过的两条命令进入终端,这样就能在Mysql里面自动建表,表名为 应用名_模型名 。比如说我在应用userX里面创建了一个模型User,那么我的表名就是userx_user,因为表面全是小写,所以大写变小写了。
当然了,如果想要使用mysql线程池的话,请继续往下看。
我们先要下载一个库,命令如下:
pip install django-db-connection-pool然后再重新修改一下setting.py中的配置,如下:
DATABASES = {
"default": {
"ENGINE": "dj_db_conn_pool.backends.mysql",
"NAME": "djangox",#数据库名称
"USER": "root",#数据库的用户名
"PASSWORD":"123456",#密码
"HOST":"127.0.0.1",#数据库所在的主机IP
"PORT":"3306",#连接数据库的端口
"POOL_OPTIONS": {
"POOL_SIZE": 10,#连接池容量
"MAX_OVERFLOW": 10,#最大扩充容量
"RECYCLE": 24*60*60#超时时间,单位为秒
}
}
}2.多表操作
2.1 模型关联
一个班级有多个学生,所以班级类跟学生类是一对多的关系。一个老师有多个学生,一个学生也有多个老师,所以老师类跟学生类是多对多的关系。一个学生只有一个学生id,所以学生ID类跟学生类是一对一的关系。这三种关系可以在建立模型的时候通过下面的三个字段类型来确认关系。

例子:
 2.2 概念约定
2.2 概念约定

例子:


2.3 一对多关系
2.3.1 增
正向操作

反向操作

2.3.2 删改查
正向操作

反向操作

 2.4 多对多关系
2.4 多对多关系
2.4.1 介绍
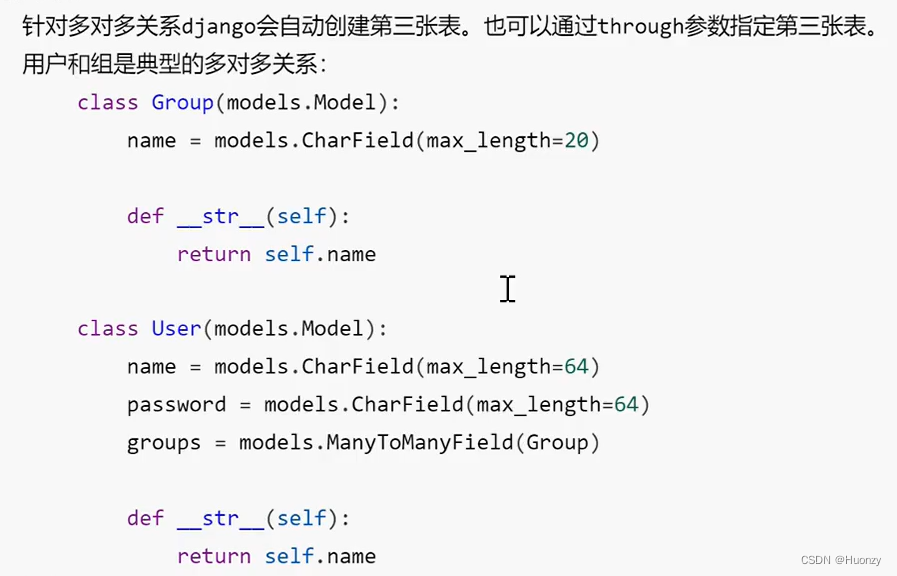
2.4.2 增删改查

 2.5 一对一关系
2.5 一对一关系
2.5.1 介绍

2.5.2 增删改查

七.路由
路由,可以帮助我们将前端的请求转到对应的类视图上,并处理该请求。那我们该如何使用路由,接着往下看。
1.在默认目录的urls.py下写路由
我们一般给类视图配置路由的时候,都是在urls.py上写的。请看下面的一个基本例子:
from django.urls import path
from userX.views import UserView
from userX.views import UserView2
urlpatterns = [
# path("admin/", admin.site.urls),
path("user/get/", UserView.as_view()),
path("user/add/", UserView.as_view()),
#有int str path这三个常用的,int代表非负整数,str代表非空字符串但不含/,path则代表非空字符串且可以含/
path("user/get/<str:username>/", UserView2.as_view()),
path("user/put/<str:username>/", UserView.as_view()),
path("user/delete/<str:username>/", UserView.as_view())
]在上面的代码中,我们先导入需要用到的类视图,即UserView和UserView2,接着在urlpatterns里面添加path,这里用到了两个面对模型User的类视图,因为这些类视图继承了APIView,而类视图是通过判断请求的方式来选择对应处理方式的。
- get请求对应获取数据
- post请求对应新增数据
- put请求对应修改数据
- delete请求对应删除数据
而get请求又分为获取部分数据和获取全部数据。
继承了APIView的类视图,不能同时写两个get方法,因为APIView封装了一个映射规则,通过判断请求类型找到名字一样的方法,所以说一个类视图无法写两个get方法,否则将无法作出抉择。对于同一个模型User的两种get请求,一个类视图无法满足User的需求,所以要用两个类视图,分别处理两个get请求。
上面解释了一下代码,现在继续回到正题:
- path方法第一个参数就是url,大家应该不陌生。如果想在url上存储值,我们可以像后面三条path一样,str代表存了一个非空字符串,不能包含/;int代表存了一个非负整数;path代表存了一个非空字符串,能包含/。
- path方法第二个参数需要一个方法名,代表将该请求送到这个方法上。因为我们使用的是类视图,所以说我们需要调用类视图的一个方法,即as_view方法。这个方法可以将请求重定向到类视图对应的处理方法上,通过请求类型来判断,如果是get请求,就会将该请求转到名为get的方法上。
- path方法的其余参数就无关紧要了,因为我们是前后端分离,其余参数直接忽略,因为无用。
接下来我们来了解一下这个as_view方法的处理过程:
- APIView.as_view() >> View.as_view() >> View.view() >> APIView.dispatch() >> 自己定义的各种类型请求的方法。在APIView.dispatch()中,request数据被重新处理,请求体中的数据被存入新的request的data属性中,data是一个字典,新的request被放入自己定义的请求方法中。
- 请求被处理后,会放到请求方法的request参数上,所以说我们在类视图写不同的请求方法时,记得给每个方法加上参数request,像下面的UserView的get方法一样。
- 该参数request是被处理后的request,request.query_params存储了get请求想要传达的数据,也是一个字典对象。request.request存储了原生的那个request。request.data则是存储了请求体中的数据。
class UserView(APIView):
def get(self, request):
print("get method is starting")
user_list = User.objects.all()
serializer = UserSerializer(instance=user_list, many=True)
return Response(serializer.data)
def put(self, request, username):
old_user = User.objects.get(userName=username)
serializer = UserSerializer(instance=old_user, data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
else:
return Response(serializer.errors)每个请求方法中request的值即为处理过后的request,而put方法的username值则对应着path的路由参数的username,参数类型为string。
2.父子路由
from django.urls import path
from userX.views import UserView
from userX.views import UserView2
urlpatterns = [
path("user/get/", UserView.as_view()),
path("user/add/", UserView.as_view()),
#有int str path这三个常用的,int代表非负整数,str代表非空字符串但不含/,path则代表非空字符串且可以含/
path("user/get/<str:username>/", UserView2.as_view()),
path("user/put/<str:username>/", UserView.as_view()),
path("user/delete/<str:username>/", UserView.as_view())
]在上面的路由中,我们只是写了一个应用需要的部分路由,然而这一部分路由就有5条了,这么多。到了实际开发的时候,十多二十多个应用,如果路由全都写在默认目录的urls.py下,既不美观,又不利于管理。所以我们要把每个应用的路由写在自己的目录下。
我们发现,应用的目录下没有urls文件,所以我们要先在应用目录下创建一个urls.py。
接下来介绍如果将父路由(默认目录下的urls.py)和子路由(应用目录下的urls.py)关联起来。
2.1 父路由操作
from django.urls import path, include
urlpatterns = [
path("user/", include("userX.urls"))
]在父路由上,我们使用了一个include方法,建立起父路由到子路由的路径。
2.2 子路由操作
from django.urls import path
from userX.views import UserView
from userX.views import UserView2
urlpatterns = [
path("get/", UserView.as_view()),
path("add/", UserView.as_view()),
path("get/<str:username>/", UserView2.as_view()),
path("put/<str:username>/", UserView.as_view()),
path("delete/<str:username>/", UserView.as_view())
]八.序列化器
1.概念
- 序列化:序列化器会将模型对象转换成字典,然后再经过response变成json字符串
- 反序列化:客户端发送过来的数据,经过request后变成字典,然后序列化器再将其转换成模型对象,同时也可以使用序列化器来实现数据校验的功能
为什么我们需要序列化器来转换模型对象?当我们从数据库中读取数据出来的时候,如果我们读取一条,那就是一个模型对象,如果我们读取多条,那就是一个querySet,模型类和querySet都是跟模型有关的,不能直接变成JSON。而像list,set,dictionary那样与模型无关的数据,可以直接转变成JSON。我们从数据库里读出来的数据,不能直接转成JSON,所以我们需要序列器来将模型对象转成JSON,或者将JSON转成模型对象。
2.序列化器的使用
序列化器是面向模型构建的,所以说一个模型对应一个序列化器。
2.1 Serializer
想要使用Serializer,我们得先导入改类所在的文件:
from rest_framework import serializers2.1.1 继承Serializer
class UserSerializer(serializers.Serializer):
#source参数的值一定要跟模型字段名字一样,而序列器的字段并不需要跟模型字段的名字一样,可以随意起名
userName = serializers.CharField(max_length=30, source='userName')
password = serializers.CharField(max_length=18, source='password')
birth = serializers.DateField(source='birth')
def create(self, validated_data):
return User.objects.create(**self.validated_data)
def update(self, instance, validated_data):
User.objects.filter(userName=instance.userName).update(**validated_data)
return User.objects.get(userName=instance.userName)上面是对Serializer的继承,我们创建一个UserSerializer类并继承了Serializer,同时里面有3个字段和两个方法。我们先看看UserSerializer对应的模型:
from django.db import models
class User(models.Model):
userName = models.CharField(max_length=30)
password = models.CharField(max_length=18)
birth = models.DateField(default='2000-00-00')发现了吗,模型里面的字段跟序列化器里面的字段很相似,如果两者的字段名相同的话,我们就不需要在序列化器的字段里面使用source参数了。如果两者的字段名不相同的话,我们就需要使用source参数来指定两个类之间模型的对应关系。但是要注意一点,两个类的字段的限制条件要一样,模型的password限制长度为18位,则序列化器的password限制长度也得是18位。
序列化器的字段介绍完了,还有create和update这两个方法没有介绍。我们现在只需要知道,这两个方法是为了Serializer的save方法而实现的。因为save方法会通过判断instance变量是否为空,来判断是使用create方法还是update方法。你们看上面的方法实现,create没有instance参数,而update有方法参数,所以instance变量为空时,调用create方法,将数据存入数据库。instance变量不为空时,会使用instance变量来实现对某一行数据的更新。
不实现这两个方法也是可以的,这样子我们就不能使用save方法来添加或更新数据了,可以在类视图对应方法里面写上对应代码。
2.1.2 使用Serializer
from rest_framework.views import APIView
from rest_framework.response import Response
class UserView(APIView):
def get(self, request):
print("get method is starting")
user_list = User.objects.all()
serializer = UserSerializer(instance=user_list, many=True)
return Response(serializer.data)
def post(self, request):
print("data", request.data)
serializer = UserSerializer(data=request.data)
#返回值为bool值,数据全正确则返回true,否则为false
if serializer.is_valid():
print(serializer.validated_data)
#校验通过,则将数据存入数据库
#User.objects.create(**serializer.validated_data)
serializer.save()
#返回我们存入的数据给前端
return Response(serializer.data)
else:
print(serializer.errors)
#返回错误信息
return Response(serializer.errors)
def put(self, request, username):
old_user = User.objects.get(userName=username)
serializer = UserSerializer(instance=old_user, data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
else:
return Response(serializer.errors)看一下上面的类视图,一共有三个方法,get,post和put。
- get方法中创建了一个序列化器对象,在创建过程中向参数instance传值,代表该序列化器对象对传入的instance对象进行序列化并转成JSON字符串,并将转换后的数据存入data属性中。
- post方法也创建了序列化器对象,但在创建时向参数data传值,此时可以调用save方法来对其进行保存了。因为只传了data,没有传instance,所以会save方法会调用create方法,即新增数据,最后将属性data的数据封装进Response中返回。
- put方法的序列化器对象在创建的时候既传instance,又传data,所以调用save方法时会调用update方法,即更改数据,最后将属性data的数据封装进Response中返回。
接下来,我们来看一下在这个UserView中使用到的序列化器的方法作用:
- is_valid方法:对序列化器的data属性的数据进行数据校验,就是拿序列化器的字段定义时的规范来判断data里面的数据是否符合要求,只要有一个不符合就返回false,全符合就返回true。在数据校验过程中,哪个字段不符合规范,就会被放入errors属性中,哪个字段符合规范,就放入validated_data属性中。所以说,如果返回false,则data = validated_data + errors;如果返回true,则data = validated_data。
- save方法:save方法会根据instance是否为空,来决定调用create还是update。空则调用create,非空则调用update。
2.2 ModelSerializer
from rest_framework import serializers上面继承Serializer的写法,如果只写一个,那就还行,但是如果写多个,那就十分复杂,而且有一堆冗余代码。因此,Serializer的升级版,ModelSerializer出现了。下面是继承ModelSerializer的一个例子:
from rest_framework import serializers
#继承了ModelSerializer后,我们不用再像上面一样写这么复杂,我们只用写下面几行代码,直接会有create和update实现
class UserSerializer(serializers.ModelSerializer):
birth = serializers.DateField(source='birth')#我们也可以自己写字段
class Meta:#配置
model = User # 确定这个序列化器为哪个模型服务
#fields = ["userName", "password"] 代表包括了User中的userName和passowrd字段
#或者,fields = "__all__" 代表包括了User中所有字段
exclude = ["birth"]
#exclude和field不能同时使用,因为一个是用来排除字段的,一个是用来选择字段的
- 我们仍可以像Serializer一样指定字段跟模型字段的对应关系
- 不同的是,我们可以在Meta里面修改配置
- model指定了这个序列化器对应着哪个模型
- fields和exclude两者互斥,不能同时使用,fields用来选择字段,exclude用来排除字段。
- 上面的UserSerializer2可以完全取代之前的那个UserSerializer,UserView中的代码不需要任何改动。
九.类视图
1. APIView
想要使用APIView,需要先导入:
from rest_framework.views import APIViewAPIView继承了View,同时也进行了升级,APIView是适合前后端分离的,而View是适合前后端不分离的。View并没有对请求进行处理,而APIView会对请求进行处理,将请求体的JSON数据转成字典。我们使用DRF设计后端,那么APIView是最基本的视图类,任何类视图都以APIView为基础。
既然APIView是最基础的,所以APIView也是最灵活的。我们在基础了APIView后,还要自己手写get,post,put,delete方法。而且,一个类视图里面,不能写两个及以上的处理同一类型请求的方法,例如,这个类里面不能有两个get方法。如果想要写两个get方法,一个用来获取部分数据,一个用来获取全部数据,那我们需要写到两个类视图里面去。
class UserView(APIView):
def get(self, request):#获取数据
def post(self, request):#添加数据
def put(self, request, username):#修改数据
def delete(self, request, username):#删除数据
2.GenericAPIView
from rest_framework.generics import GenericAPIView
GenericAPIView继承了APIView,同时增加了下面的四个方法:
get_object:返回视图需要的模型类数据对象,主要用来提供给Mixin类使用
get_serializer:返回序列化器对象,主要用来提供给Mixin类使用
get_serializer_class:返回序列化器类,主要用来判断
get_queryset:返回视图使用的查询集,主要用来提供给Mixin类使用
可别小看这四个方法,因为这四个方法,可以大大地简化我们的类视图设计时需要的代码量。
当然,我们需要在这个类视图里面加上两个字段,字段如下:
from rest_framework.response import Response
class UserView(GenericAPIView)
queryset = User.objects.all()
serializer_class = UserSerializer
lookup_field = 'userName'#默认的值为pk,表示用主键来搜索,我们这里使用用户名搜索假设我们使用ModelSerializer作为序列化器的父类,序列化器定义如下:
from rest_framework import serializers
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
exclude = ["birth"]2.1 请求处理代码改变
2.1.1 get改变
获取全部
原本:
def get(self, request):
user_list = User.objects.all()
serializer = UserSerializer(instance=user_list, many=True)
return Response(serializer.data)改进:
def get(self, request):
serializer = self.get_serializer()(instance=self.get_queryset(), many=True)
return Response(serializer.data)获取部分
原本:
def get(self, request, username):
user = User.objects.get(userName=username)
serializer = UserSerializer(instance=user, many=False)
return Response(serializer.data)改进:
def get(self, request):
serializer = self.get_serializer()(instance=self.get_object(), many=False)
return Response(serializer.data)2.1.2 post改变
原本的post方法:
def post(self, request):
serializer = UserSerializer(data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
else:
return Response(serializer.errors)改进后的post方法:
def post(self, request):
serializer =self.get_serializer()(data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
else:
return Response(serializer.errors)2.1.3 put改变
原本:
def put(self, request, username):
old_user = User.objects.get(userName=username)
serializer = UserSerializer(instance=old_user, data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
else:
return Response(serializer.errors)改变:
def put(self, request, username):
serializer = self.get_serializer()(instance=self.get_object(), data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data)
else:
return Response(serializer.errors)2.1.4 delete改变
原本:
def delete(self, request, username):
User.objects.get(userName=username).delete()
return Response()改进:
def delete(self, request, username):
self.get_object().delete()
return Response()经过对上面的四种请求方式处理代码改变的观察,我们发现,代码并没有简化。所以,DRF为什么搞出GenericAPIView来让程序员更麻烦。的确,如果我们只使用GenericAPIView的话,的确是自找麻烦。如果我们加上了Mixin类的话,GenericAPIView直接升华。接下来我们就介绍Mixin类。
3.Mixin类
Mixin类是对请求处理代码的进一步封装,是基于GenericAPIView的。如果一个类视图只继承了Mixin类,没有继承GenericAPIView,反而选择继承了APIView,那么这个类视图注定失败。
3.1 Mixin的种类
Mixin类共有5个,如下所示:
- ListModelMixin,封装了get请求获取全部数据的代码,其下有list方法
- CreateModelMixin,封装了post请求新增数据的代码,其下有create方法
- DestroyModelMixin,封装了delete请求删除数据的代码,其下有destroy方法
- UpdateModelMixin,封装了put请求修改数据的代码,其下有update方法
- RetrieveModelMixin,封装了get请求获取部分数据的代码,其下有retrieve方法
接下来我们看看代码的简化。
3.2 代码简化
想要使用Mixin,就要先导入:
from rest_framework.mixins import ListModelMixin, CreateModelMixin, DestroyModelMixin, UpdateModelMixin, RetrieveModelMixin
我们要处理哪个请求,就继承哪个Mixin类,我这里继承了ListModelMixin, CreateModelMixin, DestroyModelMixin, UpdateModelMixin,因为我们继承了GenericAPIView,而GenericAPIView继承了APIView,APIView不允许有两个get方法,所以我这里不能继承RetrieveModelMixin写第五个方法。
from rest_framework.response import Response
from rest_framework.mixins import ListModelMixin, CreateModelMixin, DestroyModelMixin, UpdateModelMixin, RetrieveModelMixin
from rest_framework.generics import GenericAPIView
class UserView(GenericAPIView, ListModelMixin, CreateModelMixin, DestroyModelMixin, UpdateModelMixin)
queryset = User.objects.all()
serializer_class = UserSerializer
lookup_field = 'userName'#默认的值为pk,表示用主键来搜索,我们这里使用用户名搜索
def get(self, request):
return self.list(request)
def post(self, request):
return self.create(request)
def put(self, request, username):
return self.update(request, username)
def delete(self, request, username):
return self.destroy(request, username)第二个get方法如下:
from rest_framework.response import Response
from rest_framework.mixins import RetrieveModelMixin
from rest_framework.generics import GenericAPIView
class UserView(GenericAPIView, RetrieveModelMixin)
queryset = User.objects.all()
serializer_class = UserSerializer
lookup_field = 'userName'#默认的值为pk,表示用主键来搜索,我们这里使用用户名搜索
def get(self, request, username):
return self.retrieve(request)你就看四种请求类型的处理方法,里面的代码是不是减少了许多,我们这些程序员就不用再像上面一样疯狂地写那么多代码了。
你以为这就结束了?不不不,简化代码的道路还没有结束,那么看上面的代码虽然简化了许多,但是我们发现,我们继承类很多,甚至继承了5个类,于是DRF又帮助我们简化了这个继承关系。
3.3 Mixin与GenericAPIView结合
DRF一共有9个Mixin与GenericAPIView结合的类,这些类同时继承了Mixin和GenericAPIView,我们用到哪些Mixin,只需找到下面的对应的类就行。
- CreateAPIView:CreateModelMixin+GenericAPIView
- ListAPIView:ListModelMixin+GenericAPIView
- RetrieveAPIView:RetrieveModelMixin+GenericAPIView
- DestroyAPIView:DestroyModelMixin+GenericAPIView
- UpdateAPIView:UpdateModelMixin+GenericAPIView
- ListCreateAPIView:ListModelMixin+CreateModelMixin+GenericAPIView
RetrieveUpdateAPIView:RetrieveModelMixin+UpdateModelMixin+GenericAPIView
RetrieveDestroyAPIView:RetrieveModelMixin+DestroyModelMixin+GenericAPIView
RetrieveUpdateDestroyAPIView:RetrieveModelMixin+DestroyModelMixin+UpdateModelMixin+GenericAPIView
4.ViewSet类
我们在上面部分了解了许多DRF封装过的类,虽然继承这些类,大大简化了我们的代码,但同时也大大地降低了我们代码的灵活性,不能根据需求来修改请求处理方式的代码,或者说会付出很大代价。而且只要继承了APIView,一个视图类里面就不能有两个处理同一请求类型的方法,否则就会报错。不仅如此,我们还是要写get方法,post方法,put方法,delete方法等等。下面我们来介绍两个ViewSet类,用来解决上面的这些问题。
4.1 ViewSet
ViewSet继承了ViewSetMixin和APIView,类视图通过继承ViewSet,可以实现一个视图类里面有两个处理同一请求类型的方法。很明显,这个功能不是APIView实现的,所以说这个功能是ViewSetMixin实现的。
想要使用ViewSet,就先要导入:
from rest_framework.viewsets import ViewSet接下来我们看一个简单的例子:
from rest_framework.viewsets import ViewSet
class UserView(ViewSet):
def create_object(self,request):
print("create object")
def get_object(self, request):
print("get object")
def get_object_list(self, request):
print("get object list")
def delete_object(self, request):
print("delete object")
def update_object(self, request):
print("update object")到这里并没有完成,我们还需要在urls.py中写对应的路由:
from django.urls import path
from userX.views import UserView
urlpatterns = [
path("user/", UserView.as_view({"get": "get_object_list", "post": "create_object"})),
path("user/<str:username>/", UserView.as_view({"get": "get_object", "put": "update_object", "delete": "delete_object"})),
]发现了吗,我们能在一个类视图里写两个get方法的原因就在路由这里,as_view方法里面可以传入一个字典,用来指定每个请求类型对应哪个处理方法。
4.2 ModelViewSet
上面的ViewSet不能使用Mixin类,所以这个还不是最终版,ModelViewSet应运而生。ModelViewSet继承了ViewSetMixin和GenericAPIView,所以ModelViewSet可以使用Mixin,因为Mixin就是要搭配GenericAPIView。接下来看我们该怎么使用ModelViewSet。
首先我们需要一个序列化器,如下:
from rest_framework import serializers
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
exclude = ["birth"]想使用ModelViewSet,就要先导入:
from rest_framework.viewsets import ModelViewSet然后我们创建一个类视图并继承ModelViewSet:
from rest_framework.viewsets import ModelViewSet
from rest_framework.mixins import ListModelMixin, CreateModelMixin, DestroyModelMixin, UpdateModelMixin, RetrieveModelMixin
class UserView(ModelViewSet, ListModelMixin, CreateModelMixin, DestroyModelMixin, UpdateModelMixin, RetrieveModelMixin):
queryset = User.objects.all()
serializer_class = UserSerializer 接着我们的路由就可以改成下面这样:
from django.urls import path
from userX.views import UserView
urlpatterns = [
path("user/", UserView.as_view({"get": "list", "post": "create"})),
path("user/<str:username>/", UserView.as_view({"get": "retrieve", "put": "update", "delete": "destroy"})),
]上面的路由对应着ListModelMixin的list方法, CreateModelMixin的create方法, DestroyModelMixin的destroy方法, UpdateModelMixin的update方法和RetrieveModelMixin的retrieve方法。
到这里,视图部分讲完了。接下来继续看一下DRF的认证。
十.JWT认证
现在的前后端分离的认证方法中,我比较喜欢用token,因为只需要将token放入请求头就行了,然后在后端接收一下,验证一下,完全不需要像Cookie和Session一样麻烦,超级轻松而且安全。而在DRF中,有许多使用JWT认证的库,而在本文中,我一个都不使用,我直接在类视图里面重写两个方法,总共加了几行代码,直接实现了使用token来进行认证,完全不需要学习那些现成的库的使用,如果大家想学我的方法,请继续看下去。如果没兴趣,那么请去B站学那些良莠不齐的教程。
1.方法介绍
首先,大家需要明白,我的认证方法是在类视图里面重写了两个方法,以此达到JWT认证。还有,我的类视图是继承ViewSet或ModelViewSet的,所以大家如果想要采用我的方法,最好是继承这两个类之一。
我为了偷懒不学现成的JWT验证框架,于是去翻看了as_view方法的源码,对其中的一个个方法进行重写的尝试,最终被我发现了有偷鸡的可能。因为我们是抱着从请求头中拿JWT的目的,所以我直接锁定了那些需要传入request参数的方法,最终被我发现了,只要我们重写了initial方法,然后再重写handle_exception方法,就能实现JWT认证。
经过我层层阅读其代码,我发现最终as_view方法最终会执行一个dispatch方法,方法代码如下:
def dispatch(self, request, *args, **kwargs):
self.args = args
self.kwargs = kwargs
#将原生request处理后得到封装请求
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
#这个initial方法是用来进行最后的检测,如果检测出毛病,直接抛出异常
self.initial(request, *args, **kwargs)
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
#这个方法就是对请求类型进行判断,然后将请求传给对应的方法处理,返回值是请求处理方法的返回值
response = handler(request, *args, **kwargs)
except Exception as exc:
#处理异常的地方
response = self.handle_exception(exc)
#最后再对response进行处理,判断这个response是HttpResponse还是DRF的Response,并将其转成前端能接收的格式
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response我们浏览这个dispatch方法的代码,不难推断出,访问数据库前的最后校验是在initial方法里面执行的,所以我们的JWT认证可以通过重写initial方法来实现,如果JWT认证失败了,我们就需要抛出异常,如果认证成功,则保持原样。因为JWT认证失败需要抛出异常,所以我们还需要重写handle_exception方法来处理我们抛出的异常,因为原有的handle_exception并不会处理我们自己增加的代码所抛出的异常。所以我得到了类视图的大致模型,如下所示:
from rest_framework.viewsets import ViewSet
class UserView(ViewSet):
def initial(self, request, *args, **kwargs):
super().initial(request, *args, **kwargs)#必须先让父类方法先执行,否则会报错
if request.META.get('HTTP_AUTHORIZATION') is None:#接着从请求头中取出参数名为Authorization的数据,其实就是JWT
raise Exception("token in header is none")#JWT不在请求头上,则抛出异常
else:
#对JWT进行解析,判断JWT是否过期,如果没过期,则通过,如果过期了,则抛出异常
print(request.META.get('HTTP_AUTHORIZATION'))
def handle_exception(self, exc):
#取出异常信息,判断这个异常是否是JWT认证时抛出的异常,并对其进行处理
if str(exc) == "token in header is none":
return Response({"code": 500}) # 我这里就简简单单的返回一个Response对象
return super().handle_exception(exc)#没有JWT抛出的异常,则继续执行父类的handle_exception大家看上面的代码和注释,应该能看懂了吧,接下来是具体的实现。
2.具体实现
想要实现JWT验证,我们首先需要知道JWT是什么?JWT的全名是JSON Web Token,其实就是将一个JSON数据按照某种加密算法转成一个长长的字符串,让一般人根本看不懂这是什么意思。JSON数据分成三个部分:header,payload和Signature。
header一般是固定的,不用自己设置了,而payload才是需要自己设计的部分,这一部分用来存储一些用户信息用来验证,如用户名,用户id,甚至是用户密码,不过我不建议存储用户密码。我这里就不教JSON Web Token和python需要的库了,大家想要深入了解,请点击下列两个链接:
还是一样的,先下载需要的库:
pip install pyjwt我直接将验证过程封装成一个类,然后直接调用这个类方法来完成验证,代码如下:
import jwt
import time
class JwtUtil:
@classmethod
def getJwt(cls, payload={}, username=None, password=None):
if payload.get('exp') is None:
payload['exp'] = time.time() + 4 * 60 * 60
if username is not None:
payload['userName'] = username
if password is not None:
payload['password'] = password
secret = 'This is my secret'
return jwt.encode(payload, secret, algorithm='HS256')
@classmethod
def parseJwt(cls, token=None):
if token is None:
return False
try:
payload = jwt.decode(token, 'This is my secret', algorithms=['HS256'])
username = payload.get('userName')
password = payload.get('password')
#执行数据库操作来查找是否存在该用户
if User.objects.get(userName=username, password=password) is None:
raise Exception('there is not a user in database')
return True
except jwt.ExpiredSignatureError as e:
print(str(e))
except Exception as e:
print(str(e))
finally:
return False因为我是直接在model.py里面写的,所以不需要导入User类。
直接在对应的类视图里面使用上面两个方法就行了,如下:
from rest_framework.viewsets import ViewSet
from userX.models import JwtUtil
from rest_framework.response import Response
class JwtViewSet(ViewSet):
def initial(self, request, *args, **kwargs):
super().initial(request, *args, **kwargs)
if (kwargs.get('state') is not 'login') | (kwargs.get('state') is not 'register'):
if request.META.get('HTTP_AUTHORIZATION') is None:
raise Exception('token in header is none')
else:
token = request.META.get('HTTP_AUTHORIZATION')
print(token)
if JwtUtil.parseJwt(token=token) is False:
raise Exception('token is out of time || token is not correct')
def handle_exception(self, exc):
if (str(exc) == 'token in header is none') | (str(exc) == 'token is out of time || token is not correct'):
return Response({"code": 500, 'msg': str(exc)})
return super().handle_exception(exc)
def do_register(self, request):
user_info = request.data
#################
#该部分是对user_info 进行信息校验,即检测数据库里是否有相同的用户名,或者相同的电话号码,或者相同的邮箱地址等,如果前面其中一条成立,那么注册失败,反之向数据库中插入新的用户数据
#具体代码需要自己写,因为每个人的服务都不同
#################
#注册成功后执行下列代码
token = JwtUtil.getJwt(username= user_info['userName'], password=user_info['password'])
return Response({'code': 200, 'msg': 'Successful to register', 'data': token})
#注册失败后执行下列代码
return Response({'code': 500, 'msg': 'Fail to register'})
def do_login(self, request):
user_info = request.query_params
username = user_info['userName']
password = user_info['password']
#################
#这部分的代码就是查询数据库是否有这个用户了,还是需要自己写
#################
#登录成功后执行下列代码
token = JwtUtil.getJwt(username=username, password=password)
return Response({'code': 200, 'msg': 'Successful to login', 'data': token})
#登录失败后执行下列代码
return Response({'code': 500, 'msg': 'Fail to login'})对应的路由设计:
from django.urls import path
from userX.views import UserView
urlpatterns = [
path("user/account/<str:state>/", UserView.as_view({"post": "do_register", "get": "do_login"})),
]在上面,我直接使用创建一个JwtViewSet继承了ViewSet,并重写了两个方法。如果有哪个类视图想要进行JWT认证,直接继承这个类就行了,不需要继承ViewSet了。
结尾感受
终于写到结尾了,这篇文章有着27000字,自己记录了好几天,上面的代码有许多我没有验证过,都是在学习过程中记录下来的,所以大家在照搬的时候要注意一下。前面的一到九部分,其实大家在网上都可以搜到,只有第十部分是我自己想偷懒于是主动去尝试的,而且还成功了。大家不要看我介绍的时候讲得很轻松,我在一个一个方法尝试的时候可是经常报错的。大家可能会说我的这篇教程一点都不全面,的确不全面。我这篇教程本来就是冲着前后端分离来的,那些渲染什么的,统统不学,自带的admin页面,我也不用。前后端分离,后端根本不需要理会页面怎么写,我们只需要理会该怎么将数据合理地传给前端,并写好接口文档就行了。我一般是采用APIFox来写API文档的,毕竟是一个良心国产软件,必须支持。我本人是先学了springboot才学django的,个人觉得django跟springboot十分不同。
好了,本文到此结束,感谢大家阅读。