写在前面
栈和队列的关系与链表和顺序表的关系差不多,不存在谁替代谁,只有双剑合璧才能破敌万千~~😎😎
文章目录
一、栈
1.1栈的概念及结构
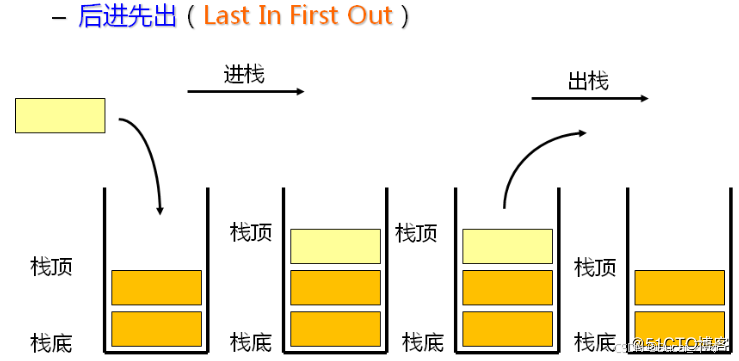
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。
栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶
1.2、栈的实现
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小。
- 栈的实现逻辑与顺序表的大差不差,只是需要规定规定入队列与出队列需要遵守遵守后进先出即可
1.2.1、栈的结构体定义
typedef int stackData;
typedef struct stack
{
stackData* val;
int size;
int cakacity;
}stack;
typedef int stackData;把顺序表结构的类型重命名为:stackData。若将来如果要改变数据栈内容的结构类型。可以极为方便的改变。- 在结构体中定义了。栈的总体大小和当前容量。以便确认是否需要扩容。
- 定义的
stackData*用于接收动态开辟的内存。 size是栈空间的大小。capacity是栈空间当前的元素数量。
1.2.2、栈的初始化栈
void SKinit(stack* head) {
head->val = (stackData*)malloc(sizeof(stackData) * 4);
assert(head->val);
head->size = 4;//栈存储空间的大小
head->top = 0;//top是栈顶元素的下一个位置
}
- 因为栈的结构体是用户自己开辟没有进行栈存储空间内存划分的。所以需要把栈的表存储空间进行初始化。
- 默认开辟两个空间。
- 在成功开辟后。把
size设置为2。top设置为0(此时栈空间内没有存储有效数据)。
1.2.3、入栈
void SKpush(stack* pHead, stackData x) {
assert(pHead);
stack* head = pHead;
if (head->top == head->size) {//判断是否需要扩容
stackData* p1 = (stackData*)realloc(head->val,sizeof(stackData) * head->size * 2);
assert(p1);
head->val = p1;
head->size *= 2;
}
head->val[head->top] = x;
head->top++;
}
- 与顺序表尾插增添并无二样。
1.2.4、出栈
stackData SKPop(stack* pHead) {
assert(pHead);
stack* head = pHead;
stackData date = head->val[head->top - 1];
head->top--;
return date;
}
- 只要把当前数据。进行减减。无需把栈中的内容进行删除。因为再次入栈数据,就会把之前的数据覆盖。
1.2.5、 获取栈顶元素
stackData StackTop(stack* ps) {
assert(ps);
return ps->val[ps->top - 1];
}
- 访问数组而已。
- 因为top是栈顶元素的下一个元素,所以
top-1就是栈顶当前元素的下标。
1.2.6、 获取栈中有效元素个数
int SKsize(stack* pHead) {
return pHead->top;
}
- 只需要返回
top就知道栈空间有多少元素了
1.2.7、检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int SKEmpty(stack* pHead) {
return pHead->top == 0;
}
top也代表栈空间有多少元素,只需要把top与0比较即可。
1.2.8、销毁栈
void SKdestory(stack* pHead) {
while (pHead->top) {
SKPop(pHead);
}
}
- 遍历出栈即可完成销毁。
二、队列
2.1队列的概念及结构
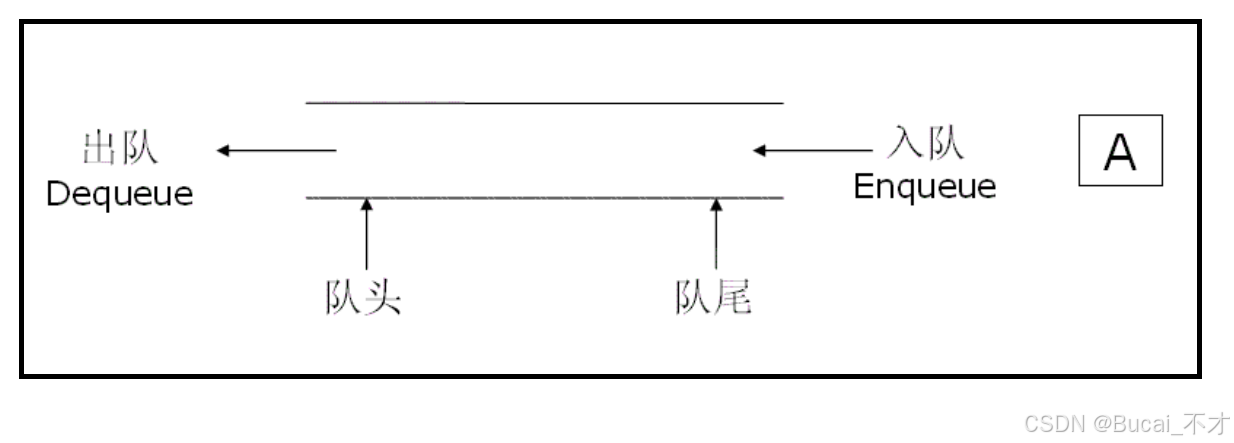
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,
队列是先进先出FIFO(First In First Out)的原则。
- 入队列:进行插入操作的一端称为队尾
- 出队列:进行删除操作的一端称为队头
2.2、队列的实现
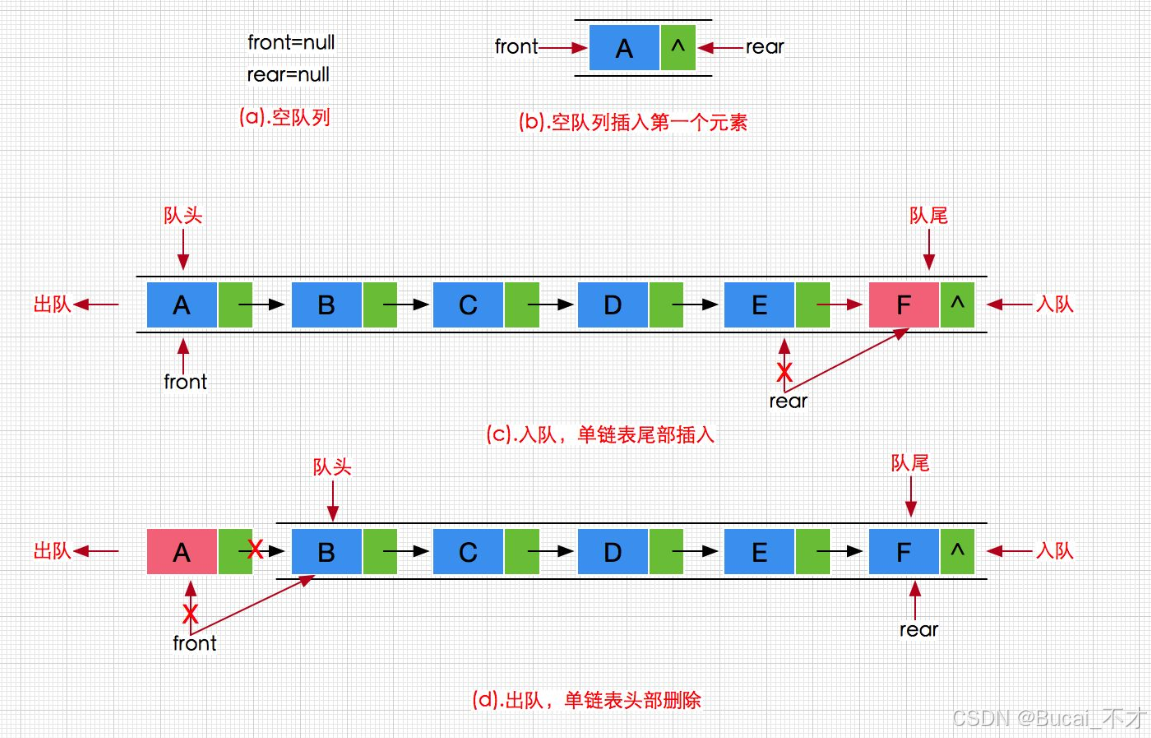
队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列在数组头上出数据,效率会比较低。
即:在单链表中只能使用尾插和头删进行数据的更改
2.2.1、队列的结构体定义
typedef int queData;
typedef struct QueNode {
queData data;
struct qnode* next;
}qnode;
typedef struct Queue {
qnode* head;
qnode* tail;
}que;
typedef int queData;把链表结构的类型重命名为:queData。若将来如果要改变链表内容的结构类型,就可以极为方便的改变。- 在结构体
QueNode中定义了链表的存储的内容与存储下个节点的指针。 - 为了更方便使用链表结构体,把链表结构体重命名为
qnode。 - 在定义完成链表的结构体后,我们需要定义队列的结构体,用来确保每次访问队列
只能访问到链表的头节点或尾节点 - 队列结构体
struct Queue是用来管理链表的,所以成员变量类型都是qnode*,head代表头节点,tail代表尾节点。
2.2.2、初始化队列
void QueInit(que** queue) {
que* p1 = (que*)malloc(sizeof(que));
assert(p1);
p1->head = NULL;
p1->tail = NULL;
*queue = p1;
}
- 动态开辟一个空队列。先把队列设置为空,把前后指针设置为
NULL。
2.2.3、队尾入队列
void QuePush(que* queue, queData x) {
assert(queue);
qnode* p1 = (qnode*)malloc(sizeof(qnode));
assert(p1);
p1->next = NULL;
p1->data = x;
if (queue->head == NULL) {
queue->head = p1;
queue->tail = p1;
}
else {
queue->tail->next = p1;
queue->tail = p1;
}
}
- 首先动态开辟一个链表节点。
- 把入队节点的
next赋为空值,并且把需要插入的x值传递给新开辟的链表节点p1->data。完成入队数据的处理。 - 在入队列之前,我们需要判断队列是否为
NULL,如为NULL说明队列的链表里面目前没有一个节点,那就需要把p1赋值head为作为队列的队头。 - 判断了队列不为
NULL,则直接把队尾的next指向p1,之后更新队尾完成入队。
2.2.4、队头出队列
qnode* QuePop(que* queue) {
assert(queue);
if (queue->head == NULL) {
return NULL;
}
qnode* p1 = queue->head;
queue->head = queue->head->next;
if (queue->head == NULL) {
queue->tail = NULL;
}
return p1;
}
- 在出队列之前,我们需要判断队列是否为
NULL,如为NULL说明队列的链表里面目前没有一个节点,那就需返回NULL即可。 - 判断了队列不为
NULL,用一个指针p1记录原对头,之后把队头的head指针指向next节点, 更新新队头后返回指针p1完成出队。 - 如果把队列的节点全部出完后,就需要把
head与tail赋为NULL。
2.2.5、检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueEmpty(que* queue) {
assert(queue);
if (queue->head == NULL && queue->tail == NULL) {
return true;
}
return false;
}
- 如果队头和队尾指针同时为
NULL则说明队列为空。否则肯定不为空。
2.2.6、获取队列头部元素
queData QueueFront(que* queue){
assert(queue);
assert(!QueEmpty(queue));
return queue->head->data;
}
- 直接返回队头的
data。
2.2.7、获取队列队尾元素
queData QueueBack(que* queue) {
assert(queue);
assert(!QueEmpty(queue));//如果队列为空还哪有说明头部元素
return queue->tail->data;
}
- 直接返回队尾的
data。
2.2.8、获取队列中有效元素个数
int QueSize(que* queue) {
assert(queue);
qnode* p1 = queue->head;
int sz = 0;
while (p1 != NULL) {
sz++;
p1 = p1->next;
}
return sz;
}
- 遍历
++即可
2.2.9、销毁队列
void QueDestory(que* queue) {
assert(queue);
while (!QueEmpty(queue)) {
free(QuePop(queue));
}
}
- 循环出队列即可。
三、栈与队列的相互实现
3.1、栈模拟实现队列
- 队列的特性是先入先出。即:FIFO(First In First Out)的原则。
- 栈的特性是后入先出。即:LIFO(Last In First Out)的原则。
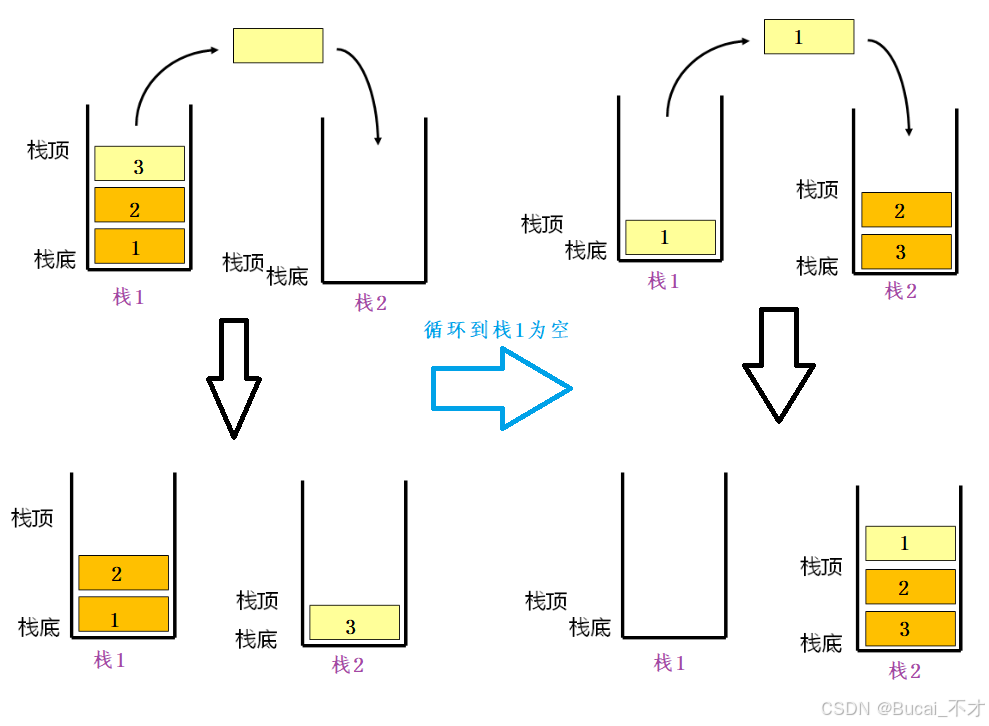
- 我们可以利用两栈后入先出的特性,先用栈1把入队列的值存起来,在存起来后,就把栈1的值出栈到
栈2中进行保存,这样就完成栈中底部的值变为顶部的值了。(如下图) - 在上图中可以看到,当栈2出栈的时候,就变成了
栈1底部的数据先出,即:先入先出。 - 所以我们只需要创建两个栈,一个栈负责入数据:
栈1,一个栈负责出数据:栈2,为了不影响先后顺序,我们必须等到栈2为空的时候才把栈1的数据导入进去。
示例代码
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int stackData;
typedef struct stack
{
stackData* val;
int size;
int top;
}stack;//栈的结构体
typedef struct {
stack* stack1;//接收数据
stack* stack2;//出数据
} MyQueue;//栈模拟的队列
//栈函数的实现
void SKinit(stack** head) {
*head = (stack*)malloc(sizeof(stack));
assert(*head);
(*head)->val = (stackData*)malloc(sizeof(stackData) * 4);
assert((*head)->val);
(*head)->size = 4;
(*head)->top = 0;
}
//入栈
void SKpush(stack* pHead, stackData x) {
assert(pHead);
stack* head = pHead;
if (head->top == head->size) {
stackData* p1 = (stackData*)realloc(head->val,sizeof(stackData) * head->size * 2);
assert(p1);
head->val = p1;
head->size *= 2;
}
head->val[head->top] = x;
head->top++;
}
//出栈
stackData SKPop(stack* pHead) {
assert(pHead);
stack* head = pHead;
stackData date = head->val[head->top - 1];
head->top--;
return date;
}
//销毁
void SKdestory(stack* pHead) {
while (pHead->top) {
SKPop(pHead);
}
}
//大小
int SKsize(stack* pHead) {
return pHead->top;
}
//判断为空
int SKEmpty(stack* pHead) {
return pHead->top == 0;
}
stackData StackTop(stack* ps) {
assert(ps);
return ps->val[ps->top - 1];
}
//队列函数的实现
// 创建一个队列
MyQueue* myQueueCreate() {
MyQueue* obj = (MyQueue*)malloc(sizeof(MyQueue)); // 为队列分配内存
SKinit(&obj->stack1); // 初始化栈1,用于接收数据
SKinit(&obj->stack2); // 初始化栈2,用于出数据
return obj; // 返回队列对象
}
// 入队操作,将元素x压入栈1
void myQueuePush(MyQueue* obj, int x) {
SKpush(obj->stack1, x); // 直接将元素压入栈1
}
// 出队操作,从栈2中弹出元素
int myQueuePop(MyQueue* obj) {
// 如果栈2为空,将栈1中的元素移动到栈2
if (obj->stack2->top == 0) {
// 从栈1依次弹出元素并压入栈2
while (!SKEmpty(obj->stack1)) {
stackData n = SKPop(obj->stack1);
SKpush(obj->stack2, n);
}
}
// 从栈2中弹出元素
return SKPop(obj->stack2);
}
// 查看队列头部元素
int myQueuePeek(MyQueue* obj) {
// 如果栈2为空,将栈1中的元素移动到栈2
if (obj->stack2->top == 0) {
while (!SKEmpty(obj->stack1)) {
stackData n = SKPop(obj->stack1);
SKpush(obj->stack2, n);
}
}
// 返回栈2的栈顶元素
return StackTop(obj->stack2);
}
// 判断队列是否为空
bool myQueueEmpty(MyQueue* obj) {
return (obj->stack2->top == 0) && (obj->stack1->top == 0); // 栈1和栈2都为空时,队列为空
}
// 销毁队列,释放所有资源
void myQueueFree(MyQueue* obj) {
// 一直出队直到队列为空
while (!myQueueEmpty(obj)) {
myQueuePop(obj);
}
// 释放栈1和栈2的内存
free(obj->stack1->val);
free(obj->stack2->val);
free(obj->stack1);
free(obj->stack2);
// 释放队列对象
free(obj);
}
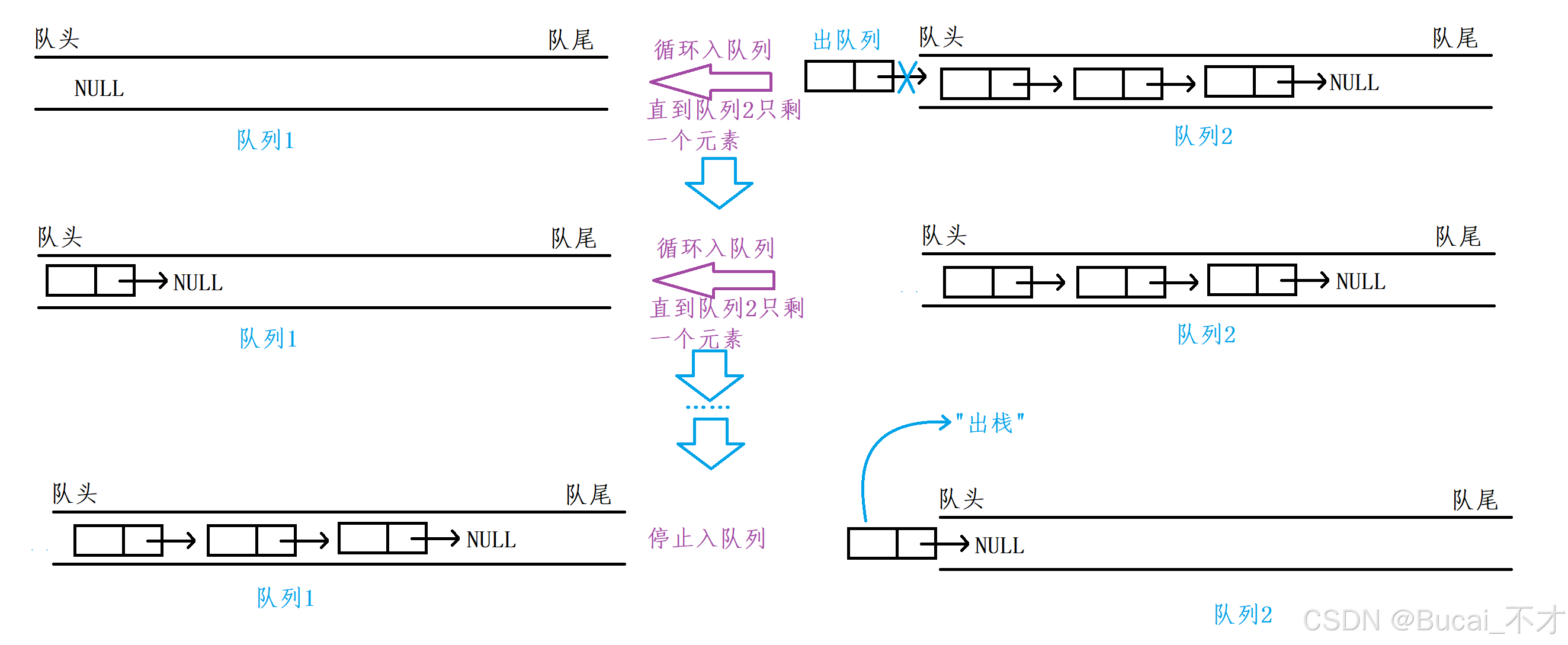
3.2、队列模拟实现栈
- 队列的特性是先入先出。即:FIFO(First In First Out)的原则。
- 栈的特性是后入先出。即:LIFO(Last In First Out)的原则。
- 我们可以利用两个队列进行互相入队,把队列中的最后一个元素进行返回,这样就完成栈的先入先出的原则了。(如下图)
- 至此,再下一次出栈时候只需要判断哪个队列不为空,就循环出队列到另一个队列中,这样就可以模拟实现栈了。
示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
// 定义栈中存储的数据类型
typedef int stackData;
// 栈的结构体定义
typedef struct stack {
stackData* val; // 动态数组,用来存储栈的元素
int size; // 栈的容量
int top; // 栈顶元素的索引
} stack;
// 初始化栈函数
void SKinit(stack** head) {
*head = (stack*)malloc(sizeof(stack));
assert(*head); // 确保内存分配成功
(*head)->val = (stackData*)malloc(sizeof(stackData) * 4);
assert((*head)->val); // 确保内存分配成功
(*head)->size = 4;
(*head)->top = 0;
}
// 入栈操作
void SKpush(stack* pHead, stackData x) {
assert(pHead); // 确保栈指针有效
stack* head = pHead;
// 如果栈满,进行扩容
if (head->top == head->size) {
// 重新分配内存,栈容量加倍
stackData* p1 = (stackData*)realloc(head->val, sizeof(stackData) * head->size * 2);
assert(p1);
head->val = p1;
head->size *= 2;
}
head->val[head->top] = x;
head->top++;
}
// 出栈操作
stackData SKPop(stack* pHead) {
assert(pHead); // 确保栈指针有效
stack* head = pHead;
stackData date = head->val[head->top - 1];
head->top--;
return date;
}
// 销毁栈,释放栈中所有数据
void SKdestory(stack* pHead) {
while (pHead->top) {
SKPop(pHead); // 依次出栈,直到栈为空
}
}
// 获取栈的大小(栈中的元素个数)
int SKsize(stack* pHead) {
return pHead->top; // 栈顶指针即为栈的大小
}
// 判断栈是否为空
int SKEmpty(stack* pHead) {
return pHead->top == 0; // 如果栈顶指针为0,则栈为空
}
// 获取栈顶元素
stackData StackTop(stack* ps) {
assert(ps); // 确保栈指针有效
return ps->val[ps->top - 1]; // 返回栈顶元素
}
// 队列结构体定义
typedef struct {
stack* stack1; // 用于接收数据(入队)
stack* stack2; // 用于出数据(出队)
} MyQueue;
// 创建队列
MyQueue* myQueueCreate() {
// 为队列分配内存
MyQueue* obj = (MyQueue*)malloc(sizeof(MyQueue));
// 初始化两个栈
SKinit(&obj->stack1); // 用于接收数据
SKinit(&obj->stack2); // 用于出数据
return obj; // 返回队列对象
}
// 入队操作,将元素x压入栈1
void myQueuePush(MyQueue* obj, int x) {
SKpush(obj->stack1, x); // 将数据压入栈1
}
// 出队操作,从栈2弹出元素
int myQueuePop(MyQueue* obj) {
// 如果栈2为空,将栈1中的元素转移到栈2
if (obj->stack2->top == 0) {
// 将栈1中的元素依次弹出并压入栈2
while (!SKEmpty(obj->stack1)) {
stackData n = SKPop(obj->stack1);
SKpush(obj->stack2, n);
}
}
// 从栈2中弹出元素并返回
return SKPop(obj->stack2);
}
// 查看队列头部元素
int myQueuePeek(MyQueue* obj) {
// 如果栈2为空,将栈1中的元素转移到栈2
if (obj->stack2->top == 0) {
while (!SKEmpty(obj->stack1)) {
stackData n = SKPop(obj->stack1);
SKpush(obj->stack2, n);
}
}
// 返回栈2的栈顶元素
return StackTop(obj->stack2);
}
// 判断队列是否为空
bool myQueueEmpty(MyQueue* obj) {
return (obj->stack2->top == 0) && (obj->stack1->top == 0); // 栈1和栈2都为空时,队列为空
}
// 销毁队列,释放所有资源
void myQueueFree(MyQueue* obj) {
// 一直出队直到队列为空
while (!myQueueEmpty(obj)) {
myQueuePop(obj);
}
// 释放栈1和栈2的内存
free(obj->stack1->val);
free(obj->stack2->val);
free(obj->stack1);
free(obj->stack2);
// 释放队列对象
free(obj);
}
四、循环队列
在操作系统的生产者消费者模型中可以就会使用循环队列。环形队列可以使用数组实现,也可以使用循环链表实现。
因为是环形队列,所以不存在扩容队列的情况,本篇笔记以数组实现为例。
以数组为数据存储模型比链表实现方便的多。
4.1、循环队列的结构体定义
typedef struct {
int* a;
int front;
int rear;
int k;//开辟的数组大小
} MyCircularQueue;
-
首先创建一个数组,用来存储队列的数据。
-
定义两个指针,用来指向队列数据中的队头和队尾。
-
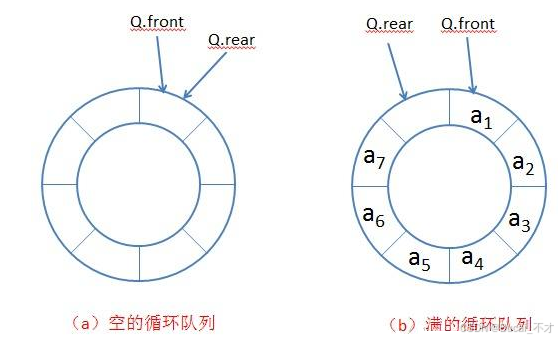
front:只需要保存队头元素在数组中的下标即可。 -
rear:保存队尾元素的下一个下标,这样可以保证队列位空时rear和front的下标相同,队列满时front是rear的下一位。如下图 -
为了达到上图的效果,需要在初始化时候把数组开大
1个空间。多开的空间作为数组的预留位置。 -
定义一个整形变量
k用来保存队列大小。
4.2、循环队列的初始化
MyCircularQueue* myCircularQueueCreate(int k) {//传入开辟队列的大小
MyCircularQueue* que = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));
assert(que);
que->a = (int*)malloc(sizeof(int) * (k + 1));
que->k = k;
que->front = 0;
que->rear = 0;
return que;
}
- 动态开辟一个队列结构体
- 动态开辟一个队列空间,其中队列空间需要比
k大一个1 - 并且把结构体中的其他值进行初始化赋值
4.3、循环队列的判断是否为空
bool IsEmpty(MyCircularQueue* obj) {
return (obj->front == obj->rear);
}
- 根据我们设计逻辑,只有
obj->front == obj->rear时候队列位空
4.4、循环队列的判断是否满了
bool IsFull(MyCircularQueue* obj) {
return (obj->rear + 1) % (obj->k + 1) == obj->front;
}
-
根据我们设计逻辑,如果
rear + 1是front的情况就说明队列满了。 -
解析
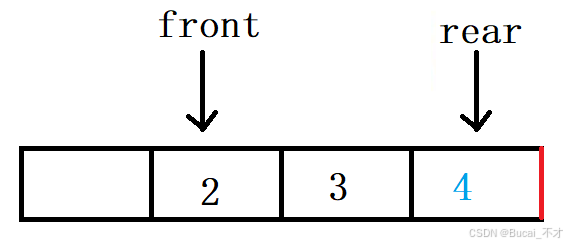
(obj->rear + 1) % (obj->k + 1) == obj->front(假设当前容量是:3。k == 3):- 第一种:只入队列且未满的情况
- 只入队列的情况下说明
front值是未进行改变的,且rear值是最后元素下标的下一位(如下图)。这时候判断,队列是否未满,只需要
(rear +1) % (k + 1)== front。小数模大数的结果还是本身。
- 只入队列的情况下说明
- 第二种:只入队列且已经满的情况
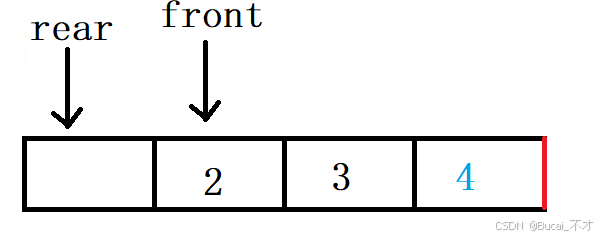
- 只入队列的情况下说明
front值是未进行改变的,且rear值是最后元素下标的下一位(如下图)。在队列满的情况下,当前的
rear的值是:3。rear + 1就超出了数组的大小(如下图)但是在循环队列中
rear + 1是代表着数组原始起点的(如下逻辑图)为了达到
rear+1就能回到数组起始位置,进行rear+1 % k + 1。rear+1的值:4。k+1的值也为:4。相同的值同时模的到的值是0。此时我们只需要判断下标0处是否也是front的值就可以判断出队列是否为满了(obj->rear + 1) % (obj->k + 1) == obj->front。(如上图)
- 只入队列的情况下说明
- 第三种:入满队列后了一些且未满的情况
- 此时队列的
front元素进行了改变,不再是0下标的值,此时我们可以和第二种结合理解。先画出此时的数组的物理结构图和逻辑结构图。(如下图)为了使
rear + 1回到逻辑结构中的下一个位置,我们使用第二种中介绍的方法,使用(obj->rear + 1) % (obj->k + 1)方法,在把rear + 1回到数组起始位置,之后判断此时的front是否也是此下标。
- 此时队列的
- 第一种:只入队列且未满的情况
4.5、循环队列的入队列
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) {
if (myCircularQueueIsFull(obj)) {
return false;
}
else {
obj->a[obj->rear] = value;
obj->rear++;
obj->rear = (obj->rear) % (obj->k + 1);
return true;
}
}
- 入队列返回结果:如果成功插入则返回真。
- 入队列前,需要检查队列是否为满。
- 如果队列不为满,只需要在
rear位置中,存放插入的数据即可。 - 在每次插入完成后,
rear数据都需要进行逻辑后移一位。在逻辑后移中,需要分成2中情况:- 第一种:
rear不在数组最后一位(如下图)此时小数模大数,结果还是本身。不受到
(obj->rear) % (obj->k + 1)的影响。 - 第二种:
rear在数组最后一位(如下图)rear+1的值:4。k+1的值也为:4。相同的值同时模的到的值是0。(obj->rear) % (obj->k + 1)即:把rear的值重新返回到数组头部。(如下图)
- 第一种:
- 只有每次都对
rear取模才能完成循环队列的逻辑。
4.6、循环队列的出队列
bool myCircularQueueDeQueue(MyCircularQueue* obj) {
if (IsEmpty(obj)) {
return false;
}
else {
obj->front++;
obj->front = (obj->front) % (obj->k + 1);
return true;
}
}
- 出队列返回结果:如果成功出队则返回真。
- 出队列前,需要检查队列是否为空。
- 出队列需要把
front下标++,把队列的队头在数组中往后移动一个位置,这样就完成了出队。 front在每次插入完成后,front数据都需要进行逻辑后移一位。在逻辑后移中,也分成2中情况,但是这两种情况与入队列的read相同,这里不做详细说明。
4.7、循环队列获取头队列元素
int myCircularQueueFront(MyCircularQueue* obj) {
if (IsEmpty(obj)) {
return -1;
}
return obj->a[obj->front];
}
- 先判断是否为空,不为空直接返回队头元素即可。
4.7、循环队列获取尾队列元素
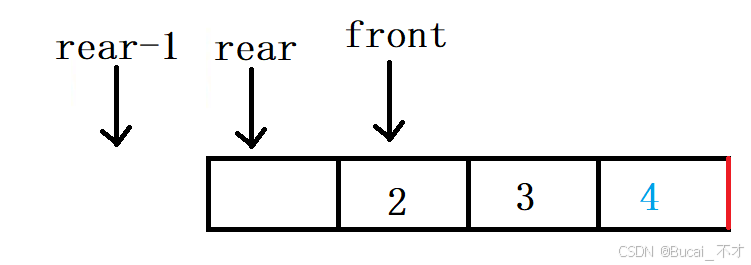
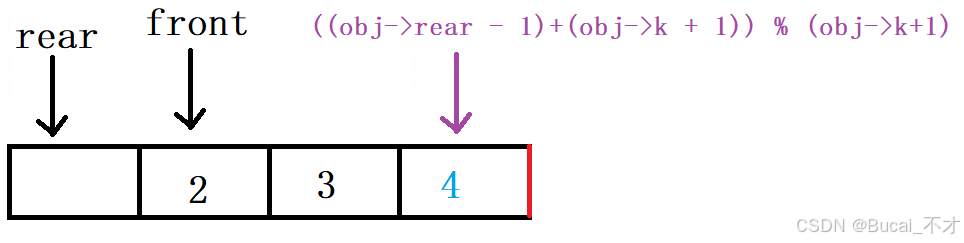
int myCircularQueueRear(MyCircularQueue* obj) {
if (IsEmpty(obj)) {
return -1;
}
//return obj->a[obj->rear - 1];
return obj->a[((obj->rear - 1) + (obj->k + 1)) % (obj->k+1)];
}
-
正常来说是:先判断是否为空,不为空直接返回
rear - 1的位置元素即可。 -
但是有一种特殊情况即:当
rear是数组首元素下标时,rear - 1就造成了越界访问。 -
为了避免越界访问的情况,必须确保在数组首元素时,返回的是数组尾元素的值(可以使用分支语句处理)。这里使用取模处理:(
k = 3)- 我们知道元素本身模本身的结果为:
0,并且小数模大数结果为:小数本身 - 所以当
rear-1时,如果在非首元素位置中,通过分配率((obj->rear - 1) + (obj->k + 1)) % (obj->k+1)可以变成(obj->rear - 1) % (obj->k+1),结果是obj->rear - 1本身 - 如果在非首元素位置中时,
(obj->rear - 1) + (obj->k + 1)的值:-1 + 4 == 3。这时候我们用得到的结果对k+1进行取模就变成了小数模大数结果为:小数本身。这时候rear的结果是数组尾元素的下标,返回的结果就是队列的尾节点元素。
- 我们知道元素本身模本身的结果为:
4.7、循环队列的销毁
void myCircularQueueFree(MyCircularQueue* obj) {
free(obj->a);
free(obj);
}
- 干脆利落的销毁了用于存储队列元素的数组与队列结构体的两个动态开辟空间~
以上就是本章所有内容。若有勘误请私信不才。万分感激💖💖 如果对大家有帮助的话,就请多多为我点赞收藏吧~~~💖💖

ps:表情包来自网络,侵删🌹