Spark简介
概述
Apache Spark是用于大规模数据分析的统一引擎。是一个分布式内存计算框架。
大规模数据:海量数据。
分析:处理、计算。
统一引擎:支持多种语言、多种模式运行。
商业版Spark: 提到Spark,就不得不提databrick公司,俗称砖厂,是由UC Berkeley实验室的成员创立的公司,也是Spark背后的商业公司。
Databrick官网:Learn About Databricks Spark | Databricks
如下:

与开源Spark相比: 比开源Spark块了5倍

Apache官网首页:Apache Spark™ - Unified Engine for large-scale data analytics
如下:
历史
-
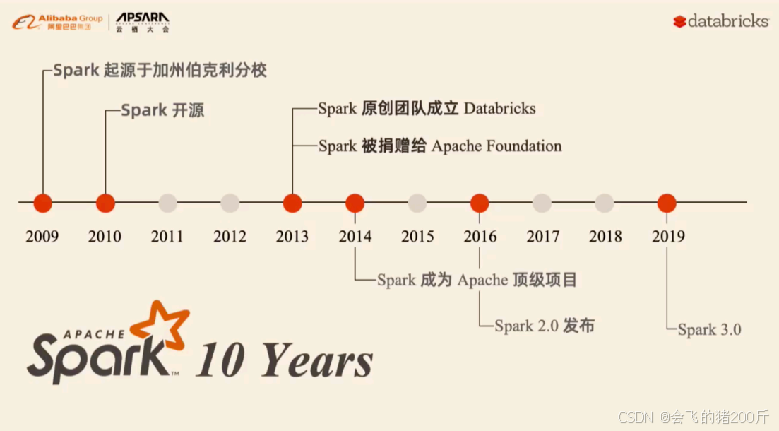
2009年Spark诞生于加州大学伯克利分校AMP实验室,伯克利大学的研究性项目
-
2010年开源
-
2012年Spark第一篇论文发布,第一个正式版(Spark 0.6.0)发布
-
2013年Databricks公司成立并将Spark捐献给Apache软件基金会
-
2014年2月成为Apache顶级项目,同年5月发布Spark 1.0正式版本
-
2018年Spark2.4.0发布,成为全球最大的开源项目
-
2019年11月Spark官方发布3.0预览版
-
2020年6月Spark发布3.0.0正式版
-
2024年12月,Spark发布3.5.4版本,是目前的最新版
Spark特点

4个特点
三支一快(便于记忆)
Fast:运行速度快,基于内存迭代,减少数据落盘
Simple:支持多种编程语言,如:Scala、Java、Python、R
Scalable:支持多种应用场景, 如: 处理离线、实时、图计算、机器学习等各种大数据场景
Unified:支持多模式运行, 如: 本地运行、独立模式运行、Yarn运行、mesos、k8s等
总结:Spark具有运行速度快(Fast)、易用性好(Simple)、通用性强(Scalable)和随处运行(Unified)的特点。
Spark模块
5个模块
整个Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上 如下图:

Spark Core模块:Spark核心模块,其他模块都是基于这个模块构建的,基于代码编程的模块
Spark SQL模块:基于SparkCore之上构建的SQL模块,用于实现结构化数据处理,基于SQL或者DSL进行编程
Spark Streaming模块:基于SparkCore之上构建的准实时计算的模块,用离线批处理来模拟实时计算,代码编程
Spark MLlib模块:提供的机器学习的算法库,主要偏向于推荐系统的算法库
Spark GraphX模块:图计算的模块
Spqrk模式(重点)
5种模式
local模式(本地模式):
概念:这是 Spark 最简单的运行模式,所有的 Spark 计算都在本地单机上执行。就像是在自己的笔记本电脑上进行小规模的数据处理,不需要额外的集群环境。
用途:非常适合用于开发、测试和调试 Spark 应用程序。例如,当你刚刚开始学习 Spark,编写一个简单的单词计数程序时,可以先在 Local 模式下运行,看看程序的逻辑是否正确。
示例:如果你在本地模式下运行一个 Spark 应用程序,Spark 会在本地的一个 Java 虚拟机(JVM)进程中执行任务。假设你有一个小型的数据集,如一个包含几百行文本的文件,你可以很方便地在本地模式下读取这个文件,进行数据转换和计算,比如统计文本中每个单词出现的次数。
standalone模式(集群模式):
概念:Spark 自身构建一个独立的集群,由一个主节点(Master)和多个从节点(Worker)组成。主节点负责管理集群资源和调度任务,从节点负责执行具体的计算任务。它不依赖于其他的集群管理系统,是 Spark 原生的集群模式。
用途:适用于小规模的生产环境或者对集群资源管理要求不高的场景。比如在一个小型的数据团队中,数据量不是特别巨大,且希望有自己独立管理的 Spark 集群,就可以使用 Standalone 模式。
示例:想象一个公司有几台服务器专门用于数据处理,通过配置 Spark 的 Standalone 模式,可以将这些服务器组织成一个集群。当有数据处理任务时,主节点会根据任务的资源需求和从节点的资源空闲情况,将任务分配到合适的从节点上进行处理。
Yarn模式(Hadoop YARN 资源管理模式):
概念:在这种模式下,Spark 应用程序运行在 Hadoop Yarn 之上。Yarn是 Hadoop 的资源管理系统,它负责管理集群中的计算资源和任务调度。Spark 利用 Yarn 的资源管理功能,将任务分配到集群中的各个节点上执行。
用途:如果企业已经有一个成熟的 Hadoop 集群,并且使用 Yarn 进行资源管理,那么 Spark 可以很好地集成到这个集群中。这样可以充分利用现有的集群资源,实现 Hadoop 生态系统中不同组件(如 MapReduce 和 Spark)的协同工作。
示例:在一个大数据中心,有大量的数据存储在 Hadoop 分布式文件系统(HDFS)中,并且已经有 Yarn 来管理集群资源。当需要使用 Spark 进行机器学习任务(如训练一个分类模型)时,Spark on YARN 模式可以让 Spark 应用程序从 Yarn 那里获取所需的计算资源,如 CPU 和内存,然后从 HDFS 中读取数据进行模型训练。
Mesos模式(Apache Mesos 资源管理模式):
概念:Spark 可以运行在 Mesos 之上,Mesos 是一个通用的集群资源管理系统。它可以对集群中的资源(如 CPU、内存等)进行抽象和分配,Spark 可以作为 Mesos 上的一个框架,向 Mesos 申请资源并执行任务。
用途:适用于数据中心同时运行多种类型的计算框架(如 Spark、Hadoop 等)的场景。Mesos 能够对不同框架的资源需求进行统一管理和调度,提高集群资源的利用率。
示例:在一个大型的数据中心,有多种大数据处理框架需要共享集群资源。通过 Mesos 模式,Spark 可以和其他框架(如 Kubernetes 等)一起竞争资源。例如,当 Spark 需要执行一个大规模的数据处理任务时,它向 Mesos 提交资源请求,Mesos 会根据集群中资源的整体情况,为 Spark 分配合适的 CPU 核心和内存,让 Spark 能够顺利执行任务。
Kubernetes 模式(容器编排模式)
概念:Spark 可以在 Kubernetes 平台上运行。Kubernetes 是一个用于容器编排的开源系统,它可以管理容器化的应用程序。在这种模式下,Spark 应用程序被打包成容器,通过 Kubernetes 进行部署、调度和管理。
用途:在云原生环境中非常受欢迎。当企业希望以容器化的方式部署和管理 Spark 应用程序,实现快速部署、弹性伸缩等功能时,Kubernetes 模式是一个很好的选择。例如,在云服务提供商的环境中,根据数据处理任务的负载自动调整 Spark 应用程序的容器数量。
示例:假设一个基于云的数据分析服务,用户提交的 Spark 任务数量和规模是动态变化的。通过 Kubernetes 模式,Spark 应用程序以容器的形式运行,Kubernetes 可以根据任务的负载情况,自动创建或销毁容器。比如在任务高峰期,增加运行 Spark 任务的容器数量,以提高处理效率;在任务低谷期,减少容器数量,节省资源。
Spark通信框架:
Spark 1.6,之前用的是akka,引入了Netty。
Spark 2.0之后,完全使用Netty,并把akka移除了。