视频处理
技术方案
掌握了xxl-job的分片广播调度方式,下边思考如何分布式去执行学成在线平台中的视频处理任务。
任务添加成功后,对于要处理的任务会添加到待处理任务表中,现在启动多个执行器实例去查询这些待处理任务,此时如何保证多个执行器不会查询到重复的任务呢?
XXL-JOB并不直接提供数据处理的功能,它只会给执行器分配好分片序号,在向执行器任务调度的同时下发分片总数以及分片序号等参数,执行器收到这些参数根据自己的业务需求去利用这些参数。
下图表示了多个执行器获取视频处理任务的结构:
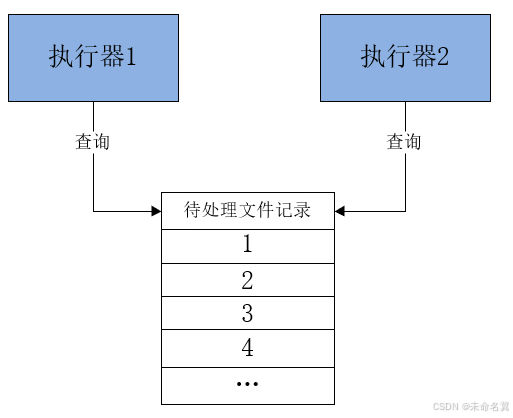
每个执行器收到广播任务有两个参数:分片总数、分片序号。每个执行从数据表取任务时可以让任务id 模上 分片总数,如果等于分片序号则执行此任务。
上边两个执行器实例那么分片总数为2,序号为0、1,从任务1开始,如下:
1 % 2 = 1 执行器2执行
2 % 2 = 0 执行器1执行
3 % 2 = 1 执行器2执行
以此类推.
保证任务不重复执行
通过作业分片方案保证了执行器之间查询到不重复的任务,如果一个执行器在处理一个视频还没有完成,此时调度中心又一次请求调度,为了不重复处理同一个视频该怎么办?
首先配置调度过期策略:
查看文档如下:
- 调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等; - 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间; - 立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间; - 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
这里我们选择忽略,如果立即执行一次就可能重复执行相同的任务。
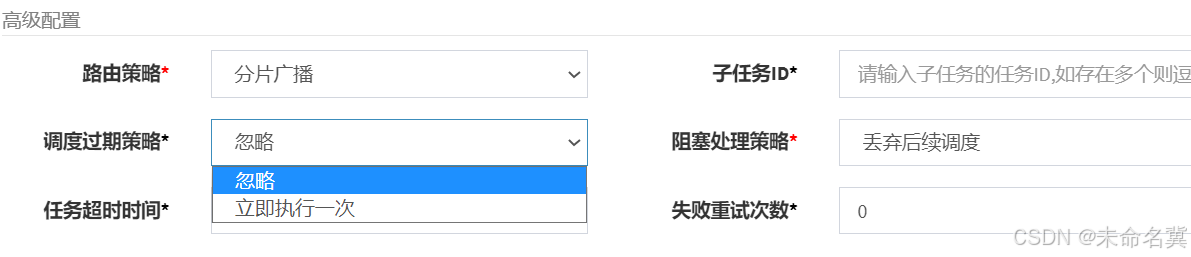
其次,再看阻塞处理策略,阻塞处理策略就是当前执行器正在执行任务还没有结束时调度中心进行任务调度,此时该如何处理。
查看文档如下: 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行; 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败; 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
这里如果选择覆盖之前调度则可能重复执行任务,这里选择 丢弃后续调度或单机串行方式来避免任务重复执行。
只做这些配置可以保证任务不会重复执行吗?
做不到,还需要保证任务处理的幂等性,什么是任务的幂等性?任务的幂等性是指:对于数据的操作不论多少次,操作的结果始终是一致的。在本项目中要实现的是不论多少次任务调度同一个视频只执行一次成功的转码。
什么是幂等性?
它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果。
幂等性是为了解决重复提交问题,比如:恶意刷单,重复支付等。
解决幂等性常用的方案:
1)数据库约束,比如:唯一索引,主键。
2)乐观锁,常用于数据库,更新数据时根据乐观锁状态去更新。
3)唯一序列号,操作传递一个唯一序列号,操作时判断与该序列号相等则执行。
基于以上分析,在执行器接收调度请求去执行视频处理任务时要实现视频处理的幂等性,要有办法去判断该视频是否处理完成,如果正在处理中或处理完则不再处理。这里我们在数据库视频处理表中添加处理状态字段,视频处理完成更新状态为完成,执行视频处理前判断状态是否完成,如果完成则不再处理。
视频处理方案
确定了分片方案,下边梳理整个视频上传及处理的业务流程。
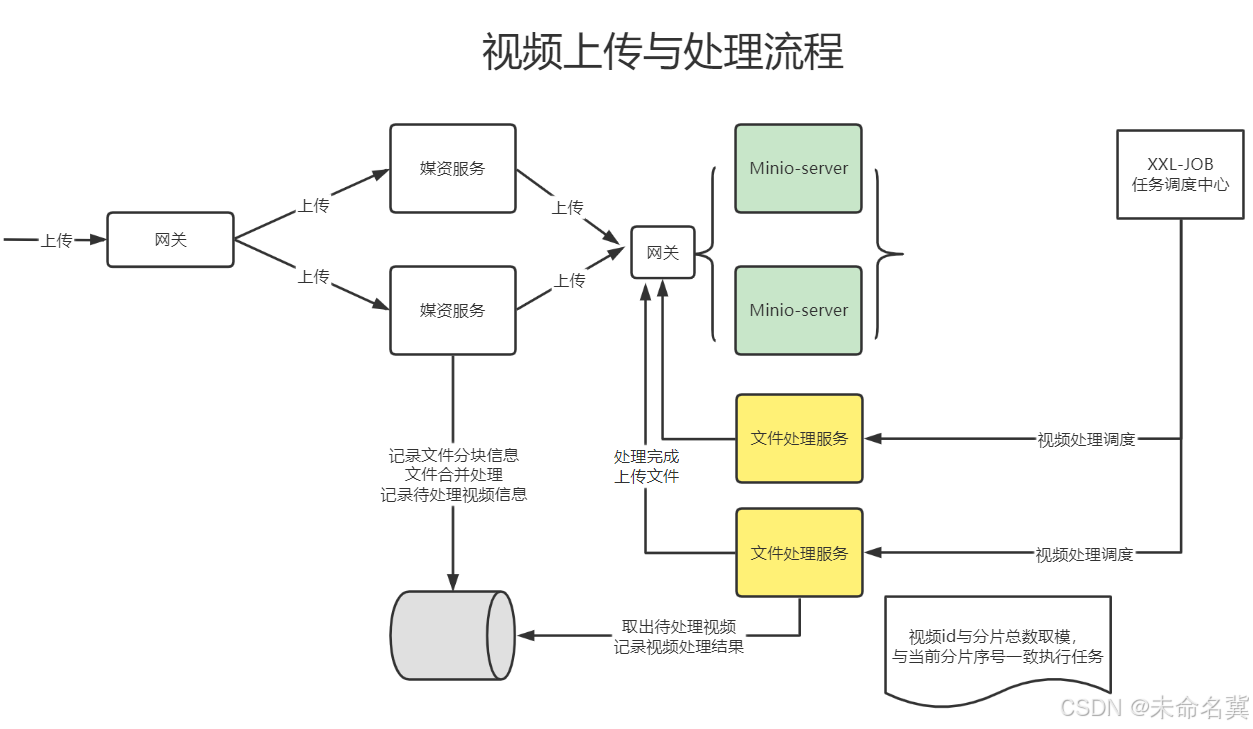
上传视频成功向视频处理待处理表添加记录。
视频处理的详细流程如下:
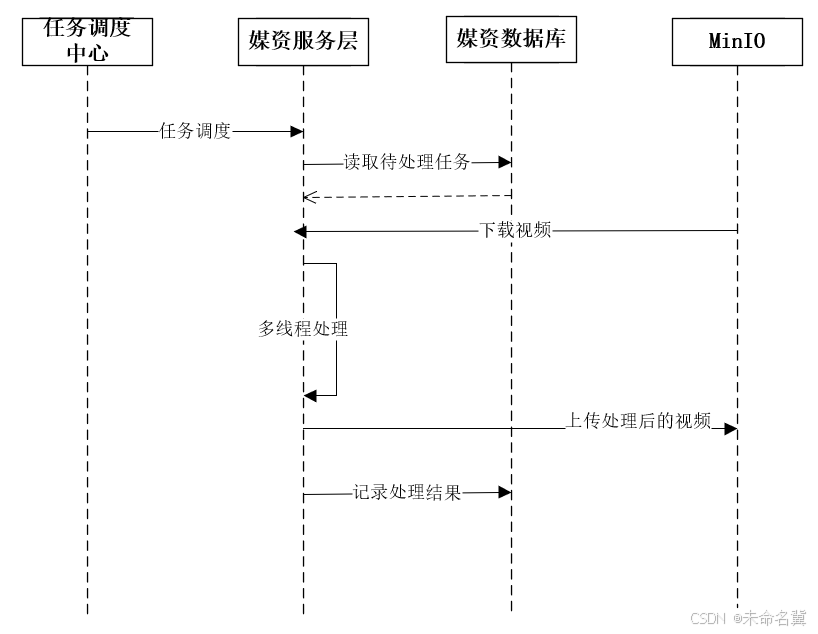
1、任务调度中心广播作业分片。
2、执行器收到广播作业分片,从数据库读取待处理任务,读取未处理及处理失败的任务。
3、执行器更新任务为处理中,根据任务内容从MinIO下载要处理的文件。
4、执行器启动多线程去处理任务。
5、任务处理完成,上传处理后的视频到MinIO。
6、将更新任务处理结果,如果视频处理完成除了更新任务处理结果以外还要将文件的访问地址更新至任务处理表及文件表中,最后将任务完成记录写入历史表。
查询待处理任务
添加待处理任务
向任务待处理表中添加任务:
由于需要再视屏上传成功时就添加任务,因此将该业务逻辑写在视频信息写入数据库的方法中。
/**
* 将文件信息写入到待处理任务表
* @param mediaFiles
*/
public void CreatmediaProcess(MediaFiles mediaFiles) {
//文件名称
String filename = mediaFiles.getFilename();
//文件扩展名
String extension = filename.substring(filename.lastIndexOf("."));
//文件mimeType
String mimeType = getMimeType(extension);
//如果是avi视频添加到视频待处理表
if(mimeType.equals("video/x-msvideo")){
MediaProcess mediaProcess = new MediaProcess();
BeanUtils.copyProperties(mediaFiles,mediaProcess);
mediaProcess.setStatus("1");//未处理
mediaProcess.setFailCount(0);//失败次数默认为0
//该URL用来存储处理后的文件的访问路径,当前应该置空
mediaProcess.setUrl(null);
int insert = mediaProcessMapper.insert(mediaProcess);
if (insert<=0){
log.error("待处理任务上传数据库失败:{}",mediaProcess);
}
}
}在下面这个方法中引用:
/**
* @description 将文件信息添加到文件表
* @param companyId 机构id
* @param fileMd5 文件md5值
* @param uploadFileParamsDto 上传文件的信息
* @param bucket 桶
* @param objectName 对象名称
* @return com.xuecheng.media.model.po.MediaFiles
* @author Mr.M
* @date 2022/10/12 21:22
*/
@Transactional
public MediaFiles addMediaFilesToDb(Long companyId,String fileMd5,UploadFileParamsDto uploadFileParamsDto,String bucket,String objectName){
//从数据库查询文件
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if (mediaFiles == null) {
mediaFiles = new MediaFiles();
//拷贝基本信息
BeanUtils.copyProperties(uploadFileParamsDto, mediaFiles);
mediaFiles.setId(fileMd5);
mediaFiles.setFileId(fileMd5);
mediaFiles.setCompanyId(companyId);
mediaFiles.setUrl("/" + bucket + "/" + objectName);
mediaFiles.setBucket(bucket);
mediaFiles.setFilePath(objectName);
mediaFiles.setCreateDate(LocalDateTime.now());
mediaFiles.setAuditStatus("002003");
mediaFiles.setStatus("1");
//保存文件信息到文件表
int insert = mediaFilesMapper.insert(mediaFiles);
if (insert < 0) {
log.error("保存文件信息到数据库失败,{}",mediaFiles.toString());
XueChengPlusException.cast("保存文件信息失败");
}
log.debug("保存文件信息到数据库成功,{}",mediaFiles.toString());
//将文件信息写入到待处理任务表
CreatmediaProcess(mediaFiles);
}
return mediaFiles;
}查询待处理业务
该代码中既有查询待处理任务也有获取乐观锁的代码。
package com.xuecheng.media.service.impl;
import com.xuecheng.media.mapper.MediaProcessMapper;
import com.xuecheng.media.model.po.MediaProcess;
import com.xuecheng.media.service.MediaFileProcessService;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
public class MediaFileProcessServiceImpl implements MediaFileProcessService {
@Autowired
private MediaProcessMapper mediaProcessMapper;
/**
* 查询需要处理的任务
* @param shardIndex 分片序号
* @param shardTotal 分片总数
* @param count 获取记录数
* @return
*/
@Override
public List<MediaProcess> getMediaProcessList(int shardIndex, int shardTotal, int count) {
List<MediaProcess> mediaProcesses = mediaProcessMapper.selectListByShardIndex(shardTotal, shardIndex, count);
return mediaProcesses;
}
/**
* 获取任务锁
* @param id
* @return true表示获取锁,flase表示未获取锁
*/
@Override
public boolean startTask(long id) {
int i = mediaProcessMapper.startTask(id);
return i<=0?false:true;
}
}
mapper层代码:
package com.xuecheng.media.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.xuecheng.media.model.po.MediaProcess;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import java.util.List;
/**
* <p>
* Mapper 接口
* </p>
*
* @author itcast
*/
public interface MediaProcessMapper extends BaseMapper<MediaProcess> {
/**
* @description 根据分片参数获取待处理任务
* @param shardTotal 分片总数
* @param shardIndex 分片序号
* @param count 任务数
* @return java.util.List<com.xuecheng.media.model.po.MediaProcess>
* @author Mr.M
* @date 2022/9/14 8:54
*/
@Select("select * from media_process t where t.id % #{shardTotal} = #{shardIndex} and (t.status = '1' or t.status = '3') and t.fail_count < 3 limit #{count}")
List<MediaProcess> selectListByShardIndex(@Param("shardTotal") int shardTotal,@Param("shardIndex") int shardIndex,@Param("count") int count);
/**
* 开启一个任务
* @param id 任务id
* @return 更新记录数
*/
@Update("update media_process m set m.status='4' where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=#{id}")
int startTask(@Param("id") long id);
}
分布式锁
前边分析了保证任务不重复执行的方案,理论上每个执行器分到的任务是不重复的,但是当在执行器弹性扩容时无法绝对避免任务不重复执行,比如:原来有四个执行器正在执行任务,由于网络问题原有的0、1号执行器无法与调度中心通信,调度中心就会对执行器重新编号,原来的3、4执行器可能就会执行和0、1号执行器相同的任务。
为了避免多线程去争抢同一个任务可以使用synchronized同步锁去解决,如下代码:
synchronized(锁对象){
执行任务...
}synchronized只能保证同一个虚拟机中多个线程去争抢锁。

如果是多个执行器分布式部署,并不能保证同一个视频只有一个执行器去处理。
现在要实现分布式环境下所有虚拟机中的线程去同步执行就需要让多个虚拟机去共用一个锁,虚拟机可以分布式部署,锁也可以分布式部署,如下图
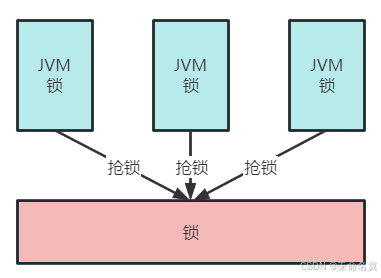
虚拟机都去抢占同一个锁,锁是一个单独的程序提供加锁、解锁服务。
该锁已不属于某个虚拟机,而是分布式部署,由多个虚拟机所共享,这种锁叫分布式锁。
实现分布式锁的方案有很多,常用的如下:
1、基于数据库实现分布锁
利用数据库主键唯一性的特点,或利用数据库唯一索引、行级锁的特点,比如:多个线程同时向数据库插入主键相同的同一条记录,谁插入成功谁就获取锁,多个线程同时去更新相同的记录,谁更新成功谁就抢到锁。
2、基于redis实现锁
redis提供了分布式锁的实现方案,比如:SETNX、set nx、redisson等。
拿SETNX举例说明,SETNX命令的工作过程是去set一个不存在的key,多个线程去设置同一个key只会有一个线程设置成功,设置成功的的线程拿到锁。
3、使用zookeeper实现
zookeeper是一个分布式协调服务,主要解决分布式程序之间的同步的问题。zookeeper的结构类似的文件目录,多线程向zookeeper创建一个子目录(节点)只会有一个创建成功,利用此特点可以实现分布式锁,谁创建该结点成功谁就获得锁。
本次我们选用数据库实现分布锁,后边的模块会选用其它方案到时再详细介绍。
开启任务
下边基于数据库方式实现分布锁,开始执行任务将任务执行状态更新为4表示任务执行中。
下边的sql语句可以实现更新操作:
update media_process m set m.status='4' where m.id=?如果是多个线程去执行该sql都将会执行成功,但需求是只能有一个线程抢到锁,所以此sql无法满足需求。
使用乐观锁方式实现更新操作:
update media_process m set m.status='4' where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=?多个线程同时执行上边的sql只会有一个线程执行成功。
什么是乐观锁、悲观锁?
synchronized是一种悲观锁,在执行被synchronized包裹的代码时需要首先获取锁,没有拿到锁则无法执行,是总悲观的认为别的线程会去抢,所以要悲观锁。
乐观锁的思想是它不认为会有线程去争抢,尽管去执行,如果没有执行成功就再去重试。
数据库的乐观锁实现方式是在表中增加一个version字段,更新时判断是否等于某个版本,等于则更新否则更新失败,如下方式。
update t1 set t1.data1 = '',t1.version='2' where t1.version='1'实现如下:
1、定义mapper
public interface MediaProcessMapper extends BaseMapper<MediaProcess> {
/**
* 开启一个任务
* @param id 任务id
* @return 更新记录数
*/
@Update("update media_process m set m.status='4' where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=#{id}")
int startTask(@Param("id") long id);
}2、在MediaFileProcessService中定义接口
/**
* 开启一个任务
* @param id 任务id
* @return true开启任务成功,false开启任务失败
*/
public boolean startTask(long id);
//实现如下
public boolean startTask(long id) {
int result = mediaProcessMapper.startTask(id);
return result<=0?false:true;
}代码位于:查询待处理业务部分
更新任务状态
/**
* @description 保存任务结果
* @param taskId 任务id
* @param status 任务状态
* @param fileId 文件id
* @param url url
* @param errorMsg 错误信息
* @return void
* @author Mr.M
* @date 2022/10/15 11:29
*/
void saveProcessFinishStatus(Long taskId,String status,String fileId,String url,String errorMsg);service层实现:
package com.xuecheng.media.service.impl;
import com.xuecheng.media.mapper.MediaFilesMapper;
import com.xuecheng.media.mapper.MediaProcessHistoryMapper;
import com.xuecheng.media.mapper.MediaProcessMapper;
import com.xuecheng.media.model.po.MediaFiles;
import com.xuecheng.media.model.po.MediaProcess;
import com.xuecheng.media.model.po.MediaProcessHistory;
import com.xuecheng.media.service.MediaFileProcessService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.time.LocalDateTime;
import java.util.List;
@Service
@Slf4j
public class MediaFileProcessServiceImpl implements MediaFileProcessService {
@Autowired
private MediaProcessMapper mediaProcessMapper;
@Autowired
private MediaFilesMapper mediaFilesMapper;
@Autowired
private MediaProcessHistoryMapper mediaProcessHistoryMapper;
/**
* 查询需要处理的任务
* @param shardIndex 分片序号
* @param shardTotal 分片总数
* @param count 获取记录数
* @return
*/
@Override
public List<MediaProcess> getMediaProcessList(int shardIndex, int shardTotal, int count) {
List<MediaProcess> mediaProcesses = mediaProcessMapper.selectListByShardIndex(shardTotal, shardIndex, count);
return mediaProcesses;
}
/**
* 获取任务锁
* @param id
* @return true表示获取锁,flase表示未获取锁
*/
@Override
public boolean startTask(long id) {
int i = mediaProcessMapper.startTask(id);
return i<=0?false:true;
}
/**
* @description 保存任务结果
* @param taskId 任务id
* @param status 任务状态
* @param fileId 文件id
* @param url url
* @param errorMsg 错误信息
* @return void
* @author Mr.M
* @date 2022/10/15 11:29
*/
@Override
public void saveProcessFinishStatus(Long taskId, String status, String fileId, String url, String errorMsg) {
//根据任务id查询任务信息
MediaProcess mediaProcess = mediaProcessMapper.selectById(taskId);
//判断任务状态
//任务执行失败
//修改待执行任务表
//修改状态为执行失败,任务执行次数加一
if (status.equals("3")){
mediaProcess.setStatus("3");
mediaProcess.setFailCount(mediaProcess.getFailCount()+1);
mediaProcess.setErrormsg(errorMsg);
int i = mediaProcessMapper.updateById(mediaProcess);
if (i<=0){
log.error("更新待执行任务表失败,任务id:"+taskId);
return;
}
return;
}
//任务执行成功:
//修改文件信息表,修改他的url
//查询文件信息表
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileId);
mediaFiles.setUrl(url);
int update = mediaFilesMapper.updateById(mediaFiles);
if (update<=0){
log.error("更新文件信息表失败,文件id:"+fileId);
return;
}
//更新待执行的任务表,添加URL,修改状态添加成功时间
mediaProcess.setStatus("2");
mediaProcess.setUrl(url);
mediaProcess.setFinishDate(LocalDateTime.now());
int i = mediaProcessMapper.deleteById(taskId);
if (i<=0){
log.error("更新待执行任务表失败,任务id:"+taskId);
return;
}
//新增完成任务表
MediaProcessHistory mediaProcessHistory = new MediaProcessHistory();
BeanUtils.copyProperties(mediaProcess,mediaProcessHistory);
int insert = mediaProcessHistoryMapper.insert(mediaProcessHistory);
if (insert<=0){
log.error("保存任务完成信息失败,任务id:"+taskId);
return;
}
}
}
视频处理
视频采用并发处理,每个视频使用一个线程去处理,每次处理的视频数量不要超过cpu核心数。
所有视频处理完成结束本次执行,为防止代码异常出现无限期等待则添加超时设置,到达超时时间还没有处理完成仍结束任务。
定义任务类VideoTask 如下:
业务实现思路:
package com.xuecheng.media.service.jobhandler;
import com.xuecheng.base.utils.Mp4VideoUtil;
import com.xuecheng.media.mapper.MediaFilesMapper;
import com.xuecheng.media.model.dto.UploadFileParamsDto;
import com.xuecheng.media.model.po.MediaProcess;
import com.xuecheng.media.service.MediaFileProcessService;
import com.xuecheng.media.service.MediaFileService;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
*
* 视频处理任务类
*/
@Component
@Slf4j
public class VideoTask {
@Autowired
private MediaFileProcessService mediaFileProcessService;
@Autowired
private MediaFileService mediaFileService;
//转码程序的存储路径,保存在nacos的配置文件中
@Value("${videoprocess.ffmpegpath}")
private String ffmpegpath;
//
// private static Logger logger = LoggerFactory.getLogger(VideoTask.class);
/**
* 分片广播任务,视频处理任务类
*/
@XxlJob("videoJobHandler")
public void videoJobHandler() {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
log.debug("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
//获取当前的CPU个数以确定最大线程数
int cpuCoreNums = Runtime.getRuntime().availableProcessors();
//获取当前任务的列表
List<MediaProcess> mediaProcessList = mediaFileProcessService.getMediaProcessList(shardIndex, shardTotal, cpuCoreNums);
//获取当前任务的总数
int size = mediaProcessList.size();
log.debug("取出待处理视频任务{}条", size);
if (size <= 0) {
return;
}
//开启多线程
//创建任务数个的线程池
//启动size个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(size);
//计数器,用来记录有多少线程完成
CountDownLatch countDownLatch = new CountDownLatch(size);
//将获取的任务加入线程池
mediaProcessList.forEach(mediaProcess -> threadPool.execute(() -> {
try {
//任务id
Long taskId = mediaProcess.getId();
//抢占任务
boolean b = mediaFileProcessService.startTask(taskId);
if (!b) {
return;
}
log.debug("开始执行任务:{}", mediaProcess);
//桶
String bucket = mediaProcess.getBucket();
//ObjectName
String ObjectName = mediaProcess.getFilePath();
//在线程中开始写执行逻辑
//从minio中下载视频
File file = mediaFileService.downloadFileFromMinIO(bucket, ObjectName);
if (file == null) {
//下载失败
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(),"3",mediaProcess.getFileId(),null,"下载视频出错");
countDownLatch.countDown();
return;
}
//给文件转码
//创建一个临时文件,用来存储转码后的文件
File mp4File = null;
String result = "";
try {
mp4File = File.createTempFile("minio", ".mp4");
} catch (IOException e){
e.printStackTrace();
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(),"3",mediaProcess.getFileId(),null,"创建临时文件失败");
countDownLatch.countDown();
return;
}
//开始处理视频
Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpegpath, file.getAbsolutePath(), mp4File.getName(), mp4File.getAbsolutePath());
//开始视频转换,成功将返回success
result = videoUtil.generateMp4();
//判断是否生成成功
if (!"success".equals(result)) {
//上传失败
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(),"3",mediaProcess.getFileId(),null,result);
countDownLatch.countDown();
return;
}
//将文件上传到minio
//获取文件mimeType
String mimeType = mediaFileService.getMimeType(".mp4");
//原始视频的md5值
String fileId = mediaProcess.getFileId();
String objectName = getFilePath(fileId, ".mp4");
//访问url
String url = "/" + bucket + "/" + objectName;
boolean b1 = mediaFileService.updataFile(mimeType, bucket, objectName, mp4File.getAbsolutePath());
if (!b1){
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(),"3",mediaProcess.getFileId(),null,"上传文件失败");
}
//修改待处理任务表信息
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(),"2",mediaProcess.getFileId(),url,null);
} finally {
countDownLatch.countDown();
}
}
));
try {
//等待,给一个充裕的超时时间,防止无限等待,到达超时时间还没有处理完成则结束任务
countDownLatch.await(30, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
/**
* 获取文件在minio中的存储路径
* @param fileMd5 文件的MD5码
* @param fileExt 文件的后缀
* @return
*/
private String getFilePath(String fileMd5,String fileExt){
return fileMd5.substring(0,1) + "/" + fileMd5.substring(1,2) + "/" + fileMd5 + "/" +fileMd5 +fileExt;
}
}
其它问题
7.9.1 任务补偿机制
如果有线程抢占了某个视频的处理任务,如果线程处理过程中挂掉了,该视频的状态将会一直是处理中,其它线程将无法处理,这个问题需要用补偿机制。
单独启动一个任务找到待处理任务表中超过执行期限但仍在处理中的任务,将任务的状态改为执行失败。
任务执行期限是处理一个视频的最大时间,比如定为30分钟,通过任务的启动时间去判断任务是否超过执行期限。
大家思考这个sql该如何实现?
大家尝试自己实现此任务补偿机制。
7.9.2 达到最大失败次数
当任务达到最大失败次数时一般就说明程序处理此视频存在问题,这种情况就需要人工处理,在页面上会提示失败的信息,人工可手动执行该视频进行处理,或通过其它转码工具进行视频转码,转码后直接上传mp4视频。
7.9.3 分块文件清理问题
上传一个文件进行分块上传,上传一半不传了,之前上传到minio的分块文件要清理吗?怎么做的?
1、在数据库中有一张文件表记录minio中存储的文件信息。
2、文件开始上传时会写入文件表,状态为上传中,上传完成会更新状态为上传完成。
3、当一个文件传了一半不再上传了说明该文件没有上传完成,会有定时任务去查询文件表中的记录,如果文件未上传完成则删除minio中没有上传成功的文件目录。
面试
1、Xx-job的工作原理是什么?Xx-job是什么怎么工作?
XXL-]OB分布式任务调度服务由调用中心和执行器组成,调用中心负责按任务调度策略向执行器下发任务,执行器
负责接收任务执行任务。
1)首先部署并启动xx-job调度中心。(一个java工程)
2)首先在微服务添加xx-job依赖,在微服务中配置执行器
3)启动微服务,执行器向调度中心上报自己。
4)在微服务中写一个任务方法并用xx-job的注解去标记执行任务的方法名称。
5)在调度中心配置任务调度策略,调度策略就是每隔多长时间执行还是在每天或每月的固定时间去执行,比如每天
0点执行,或每隔1小时执行一次等。
6)在调度中心启动任务。
7)
调度中心根据任务调度策略,到达时间就开始下发任务给执行器。
8)执行器收到任务就开始执行任务。
2、如何保证任务不重复执行?
1)调度中心按分片广播的方式去下发任务
2)执行器收到作业分片广播的参数:分片总数和分片序号,计算任务d除以分片总数得到一个余数,如果余数等
于分片序号这时就去执行这个任务,这里保证了不同的执行器执行不同的任务。
3)配置调度过期策略为“忽略”,避免同一个执行器多次重复执行同一个任务
4)配置任务阻塞理策略为“丢弃后续调度”,注意:丢弃也没事下一次调度就又可以执行了
5)另外还要保证任务处理的幂等性,执行过的任务可以打一个状态标记已完成,下次再调度执行该任务判断该任
务已完成就不再执行
3、任务幂等性如何保证?
它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果。
幂等性是为了解决重复提交问题,比如:恶意刷单,重复支付等。
解决幂等性常用的方案:
1)数据库约束,比如:唯一索引,主键。同一个主键不可能两次都插入成功。
2)乐观锁,常用于数据库,更新数据时根据乐观锁状态去更新。
3)唯一序列号,请求前生成唯一的序列号,携带序列号去请求,执行时在rdis记录该序列号表示以该序列号的请
求执行过了,如果相同的序列号再次来执行说明是重复执行。
这里我们在数据库视频处理表中添加处理状态字段,视频处理完成更新状态为完成,执行视频处理前判断状态是否
完成,如果完成则不再处理。
媒资绑定
接口定义
根据业务流程,用户进入课程计划列表,首先确定向哪个课程计划添加视频,点击”添加视频“后用户选择视频,选择视频,点击提交,前端以json格式请求以下参数:
提交媒资文件id、文件名称、教学计划id
{
"mediaId": "70a98b4a2fffc89e50b101f959cc33ca",
"fileName": "22-Hmily实现TCC事务-开发bank2的confirm方法.avi",
"teachplanId": 257
}此接口在内容管理模块提供。
在内容管理模块定义请求参数模型类型:
@Data
@ApiModel(value="BindTeachplanMediaDto", description="教学计划-媒资绑定提交数据")
public class BindTeachplanMediaDto {
@ApiModelProperty(value = "媒资文件id", required = true)
private String mediaId;
@ApiModelProperty(value = "媒资文件名称", required = true)
private String fileName;
@ApiModelProperty(value = "课程计划标识", required = true)
private Long teachplanId;
}在TeachplanController类中定义接口如下:
@ApiOperation(value = "课程计划和媒资信息绑定")
@PostMapping("/teachplan/association/media")
public void associationMedia(@RequestBody BindTeachplanMediaDto bindTeachplanMediaDto){
}
接口开发
Service开发
根据需求定义service接口
/**
* @description 教学计划绑定媒资
* @param bindTeachplanMediaDto
* @return com.xuecheng.content.model.po.TeachplanMedia
* @author Mr.M
* @date 2022/9/14 22:20
*/
public TeachplanMedia associationMedia(BindTeachplanMediaDto bindTeachplanMediaDto);
定义接口实现
@Transactional
@Override
public TeachplanMedia associationMedia(BindTeachplanMediaDto bindTeachplanMediaDto) {
//教学计划id
Long teachplanId = bindTeachplanMediaDto.getTeachplanId();
Teachplan teachplan = teachplanMapper.selectById(teachplanId);
if(teachplan==null){
XueChengPlusException.cast("教学计划不存在");
}
Integer grade = teachplan.getGrade();
if(grade!=2){
XueChengPlusException.cast("只允许第二级教学计划绑定媒资文件");
}
//课程id
Long courseId = teachplan.getCourseId();
//先删除原来该教学计划绑定的媒资
teachplanMediaMapper.delete(new LambdaQueryWrapper<TeachplanMedia>().eq(TeachplanMedia::getTeachplanId,teachplanId));
//再添加教学计划与媒资的绑定关系
TeachplanMedia teachplanMedia = new TeachplanMedia();
teachplanMedia.setCourseId(courseId);
teachplanMedia.setTeachplanId(teachplanId);
teachplanMedia.setMediaFilename(bindTeachplanMediaDto.getFileName());
teachplanMedia.setMediaId(bindTeachplanMediaDto.getMediaId());
teachplanMedia.setCreateDate(LocalDateTime.now());
teachplanMediaMapper.insert(teachplanMedia);
return teachplanMedia;
}