文章目录

🍔准备工作
我们运行下面的代码,爬取一下百度网站
import urllib.request
url = "https://www.baidu.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
req = urllib.request.Request(url=url, headers=headers)
reponse = urllib.request.urlopen(req)
print(reponse.read().decode("utf-8"))
创建一个file,后缀为html,把爬取的代码粘贴过去
🌹BeautifulSoup()
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python 库。它提供了一种简单而灵活的方式,帮助开发者从网页中提取所需的数据
使用 BeautifulSoup,你可以将 HTML 或 XML 文档加载到解析树中,并使用类似于 DOM(文档对象模型)的方式来遍历和搜索文档的结构。然后,你可以使用各种方法和属性来定位、提取和操作文档中的元素和数据。
以下是 BeautifulSoup 的一些常见用途:
- 解析和提取数据:通过加载 HTML 或 XML 文档,BeautifulSoup 可以帮助你轻松地提取出所需的数据。你可以使用 CSS 选择器或类似于字典的属性访问方式来定位元素,并获取其文本内容、属性值等。
- 数据清洗和转换:BeautifulSoup 提供了诸多方法来处理解析树中的元素和数据。你可以删除、替换或修改特定的标签、属性,也可以对文本内容进行处理,如去除空白字符、标准化格式等。
- 网页爬虫:在网络爬虫中,你可以使用 BeautifulSoup 来解析抓取到的网页内容,提取出需要的数据,如标题、链接、图像等。它可以帮助你处理网页中的复杂结构,并提供便捷的 API 进行数据提取和处理。
- 数据可视化和分析:BeautifulSoup 可以与其他数据处理和可视化库(如 Pandas、Matplotlib)结合使用,进一步分析和展示提取到的数据。你可以将数据转换为数据框架、绘制图表或进行其他分析操作。
总的来说,BeautifulSoup 是一个功能强大且易于使用的工具,用于解析和处理 HTML、XML 等文档,并从中提取所需的数据。它在数据爬取、数据清洗和转换等领域都有广泛的应用。
⭐代码实现
from bs4 import BeautifulSoup
file = open("./baidu.html","rb")
html=file.read()
# 解析的是html文件
# 解析器是html.parser
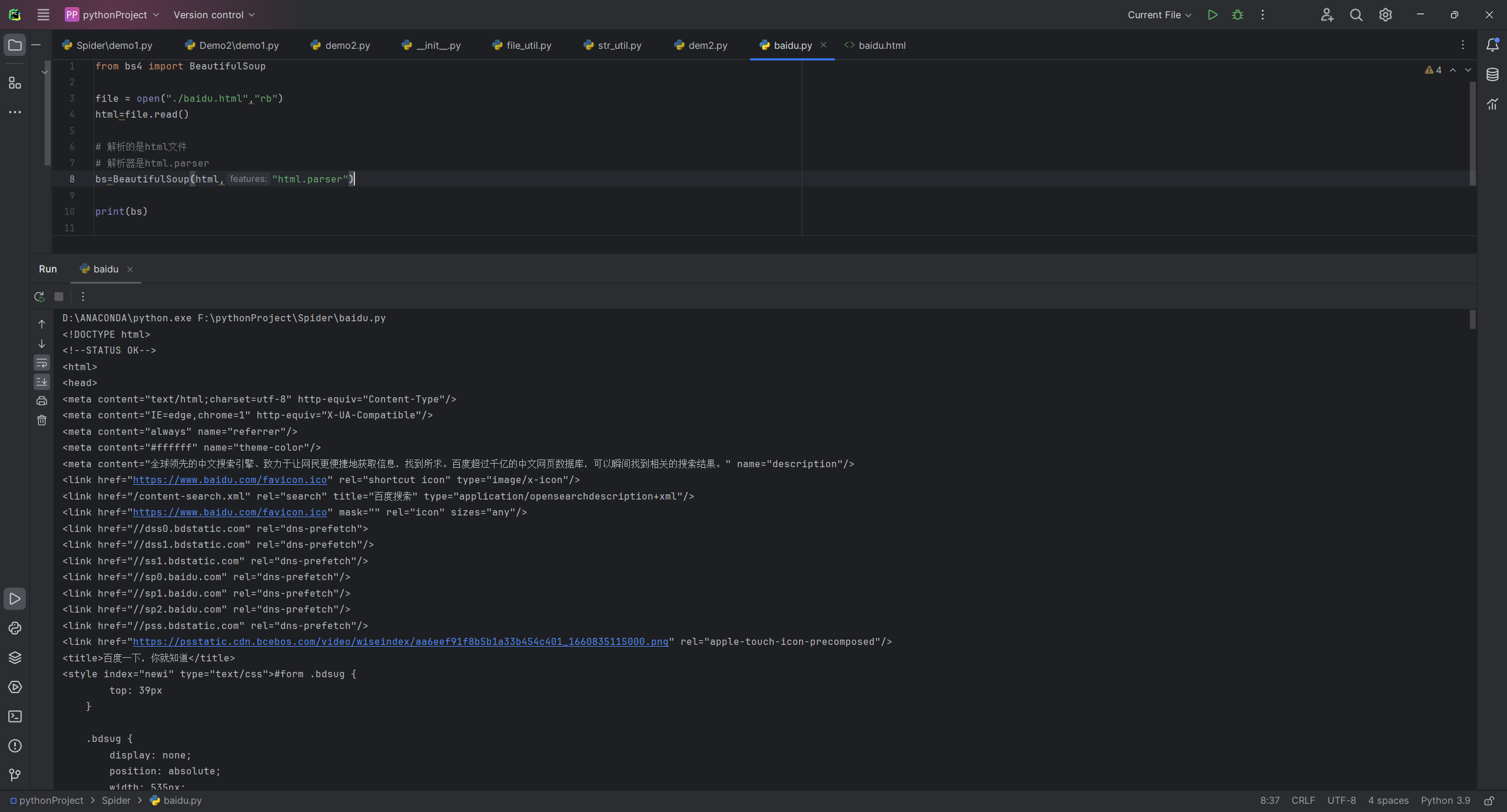
bs=BeautifulSoup(html,"html.parser")
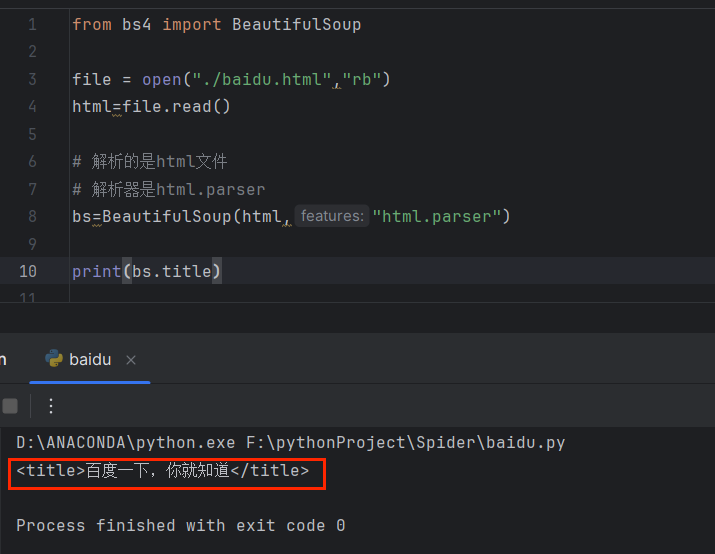
print(bs.title)
运行后发现
运行结果提取出了title
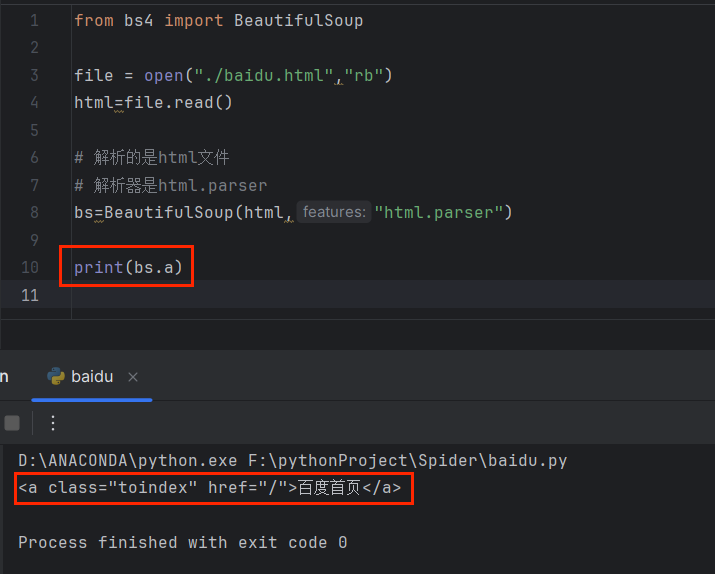
同理
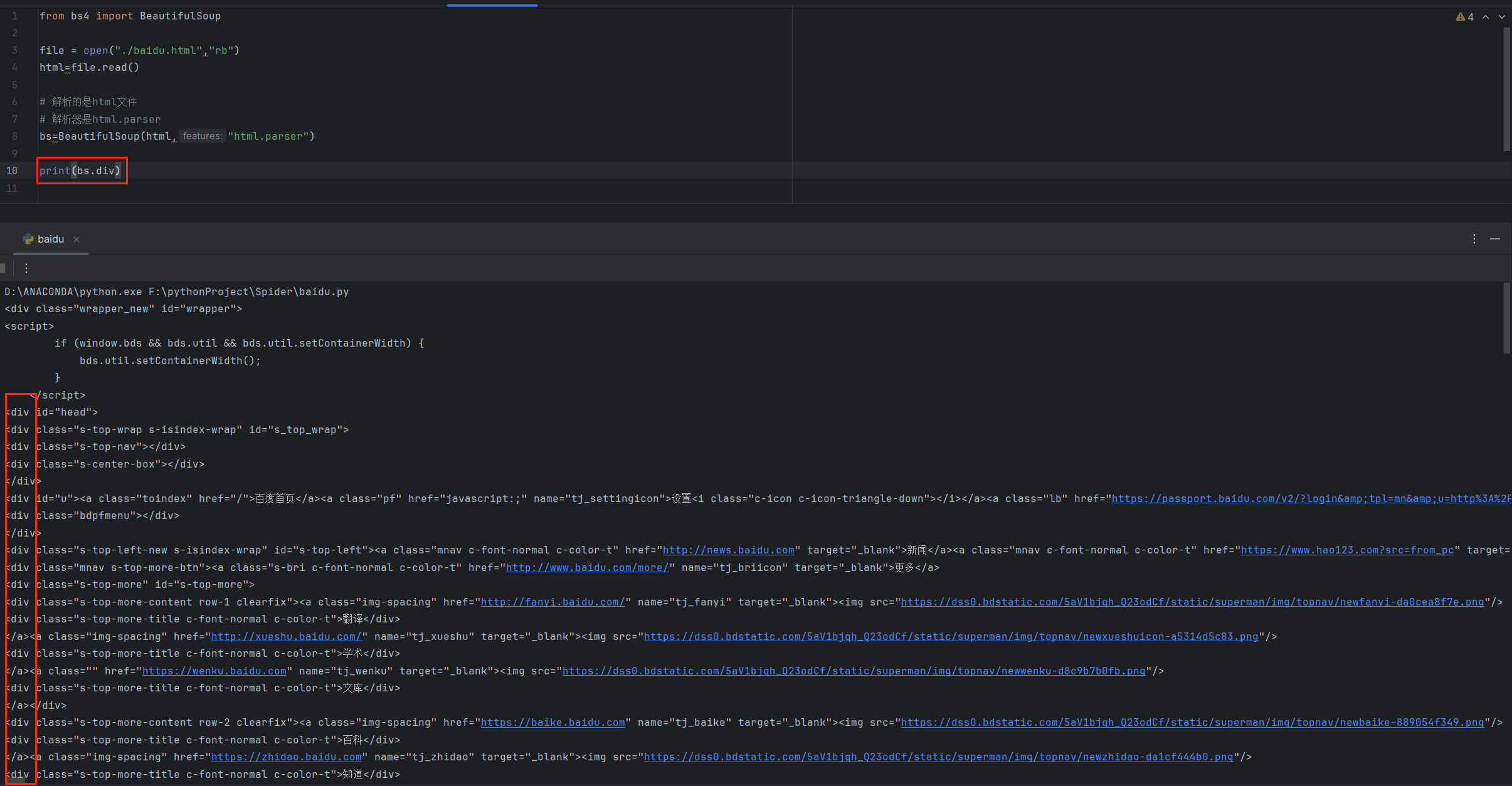
✨打印标签里面的内容
print(bs.title.string)
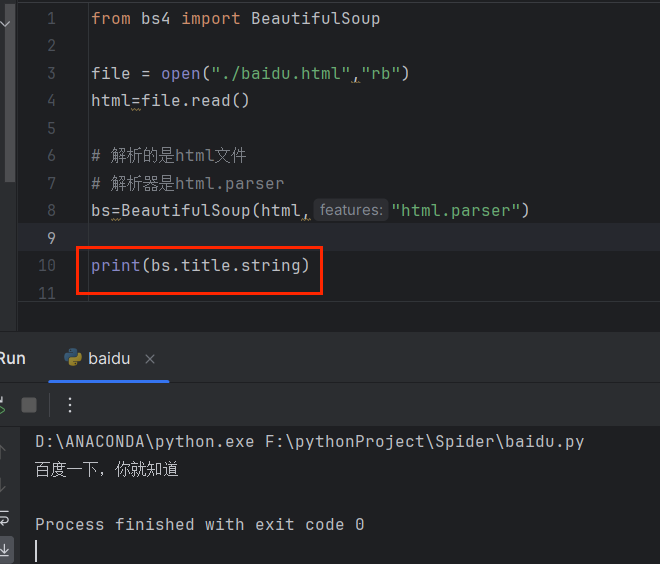
✨快速拿到一个标签里的属性
print(bs.a.attrs)
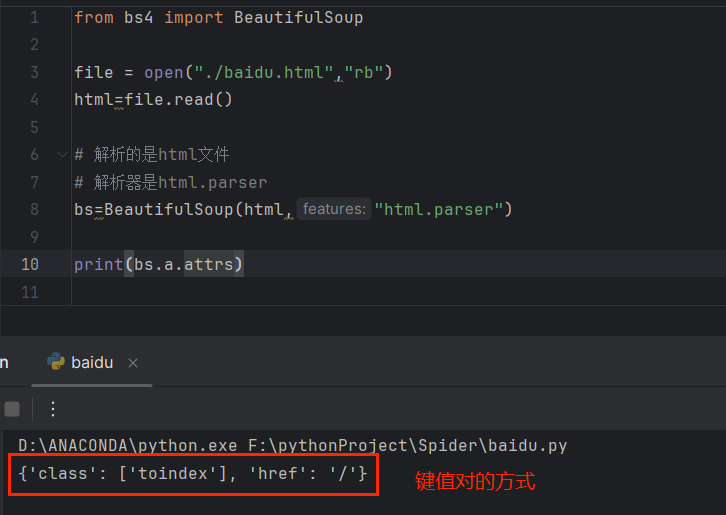
✨打印整个文档
print(bs)
🎆获取特定标签的特定内容
print(bs.head.contents[1])
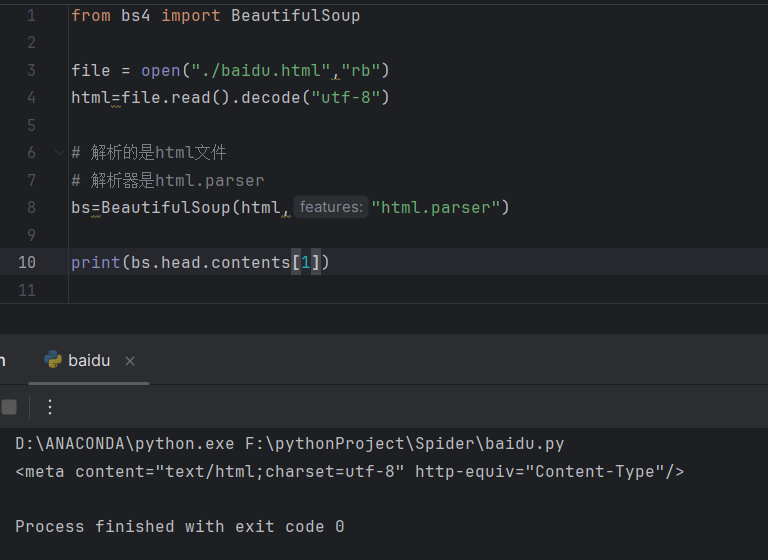
🌹查找标签
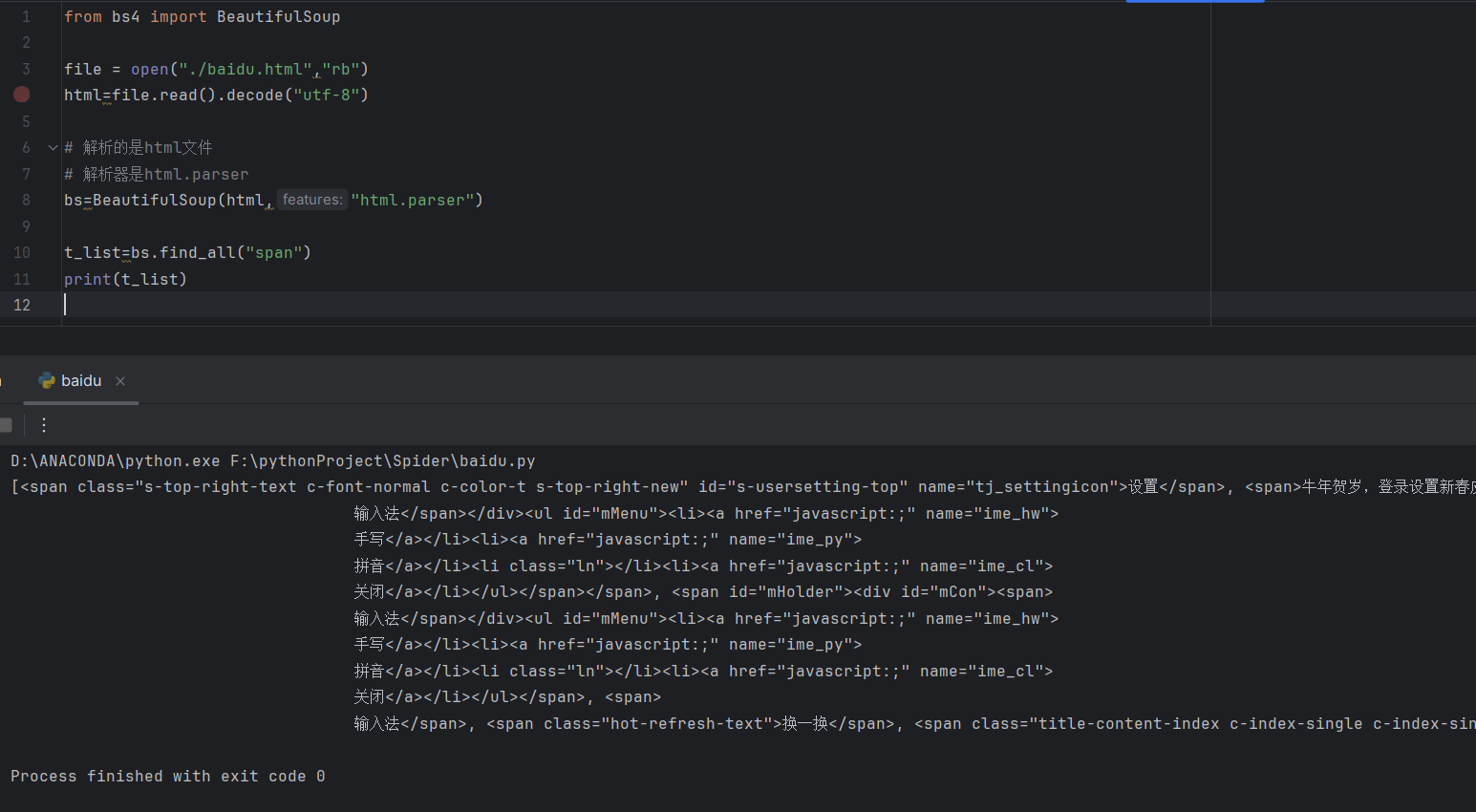
🎈在文档查找标签 find_all
查找标签
搜索到的仅仅是那一种标签
t_list=bs.find_all("span")
把所有的 某个标签 放到列表里面
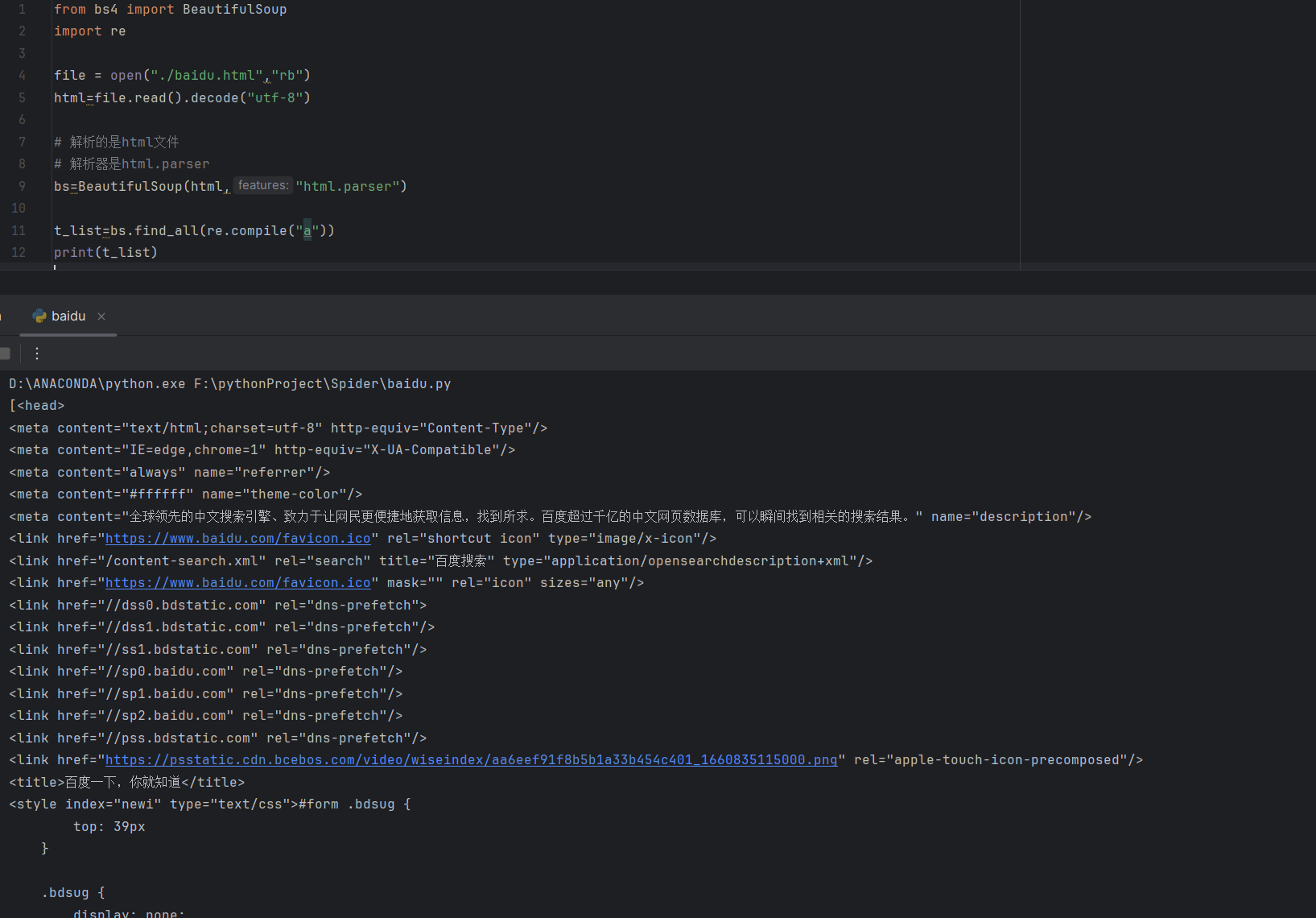
🎈正则表达式搜索
需要引入库
import re
搜索出来的是包含 某个标签 的
我们查找a标签,head标签里面有a这个 字母,所以被选出来了
由于link标签里面的链接中有a字母,所以link标签也被选出来了
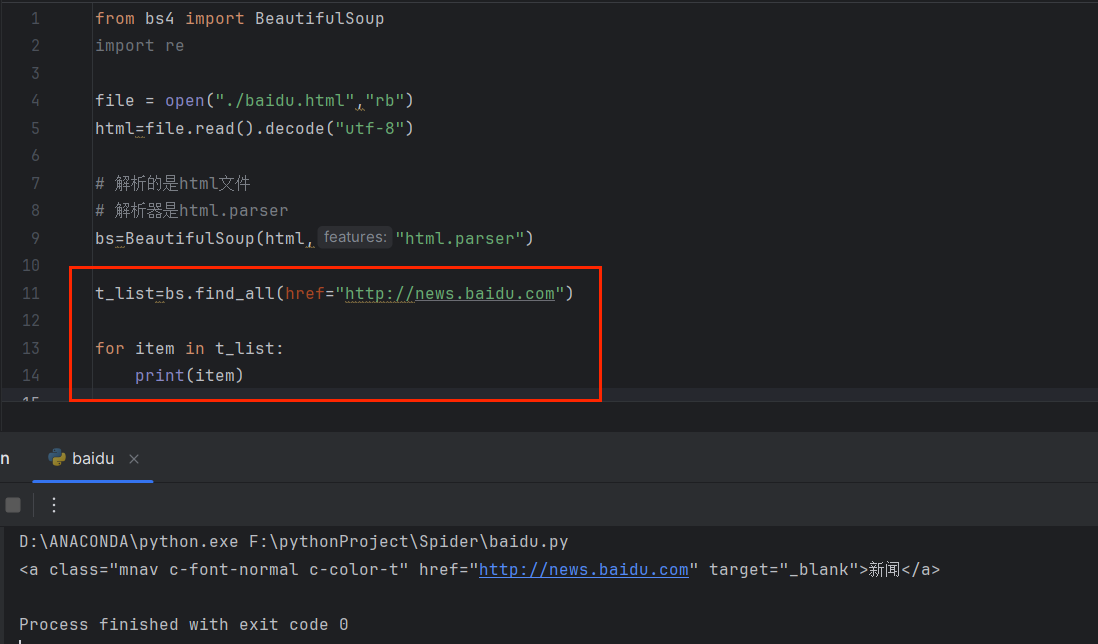
🌹查找参数
比如下面这种
🌹文本(text)参数
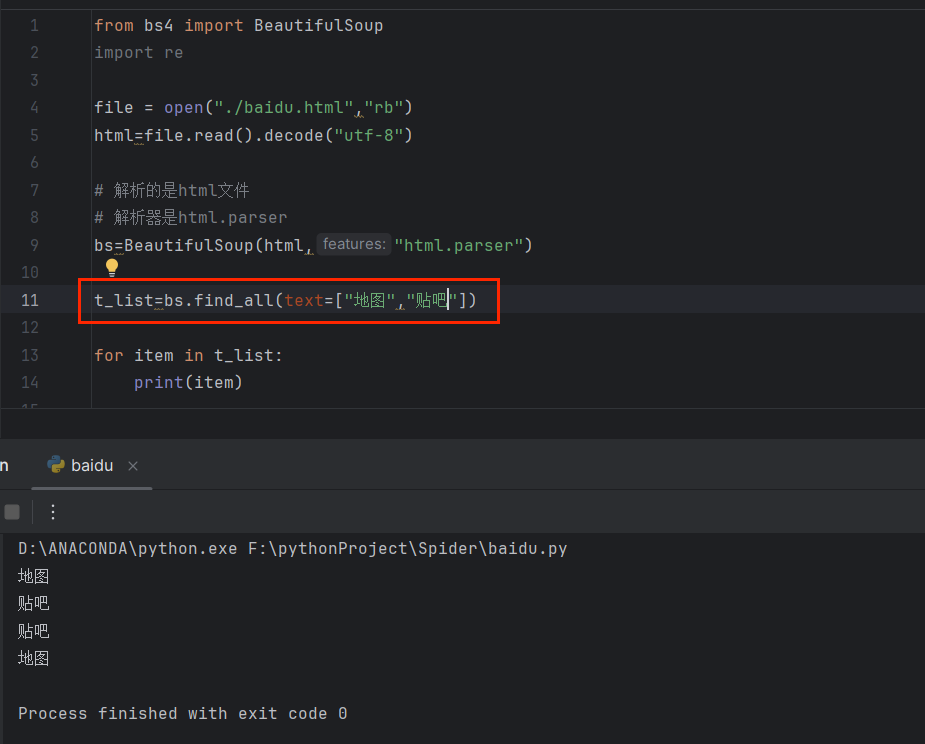
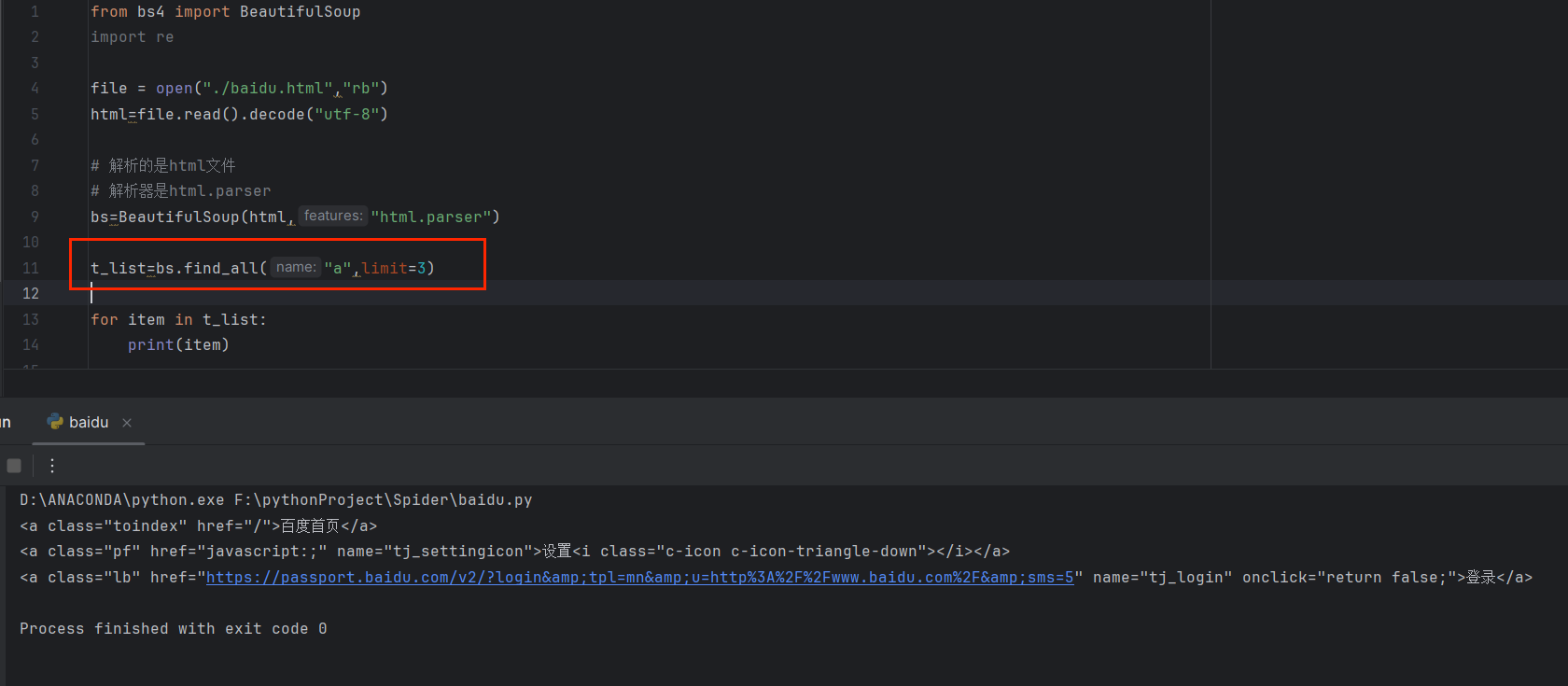
🌹limit参数
限制获取到的个数
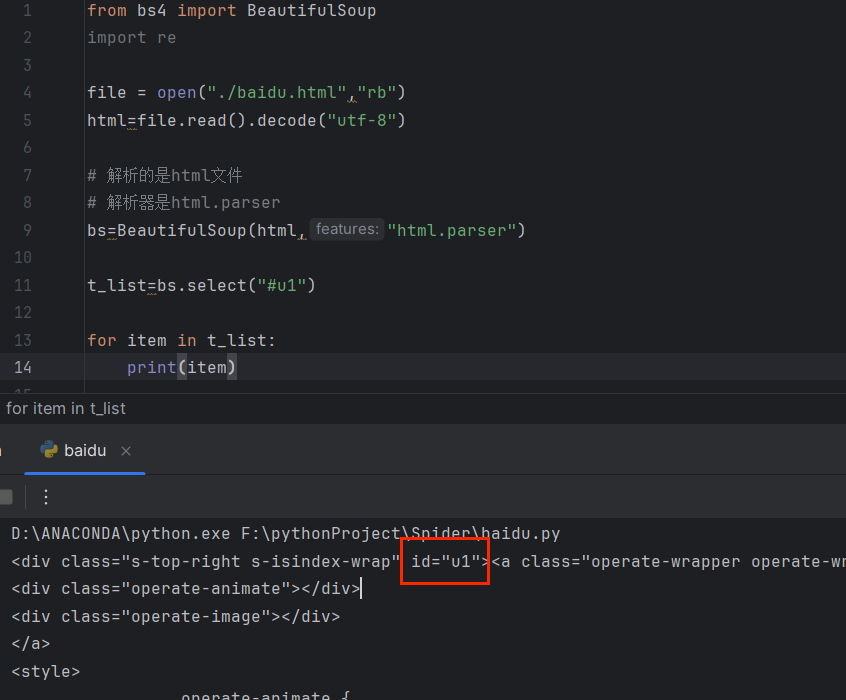
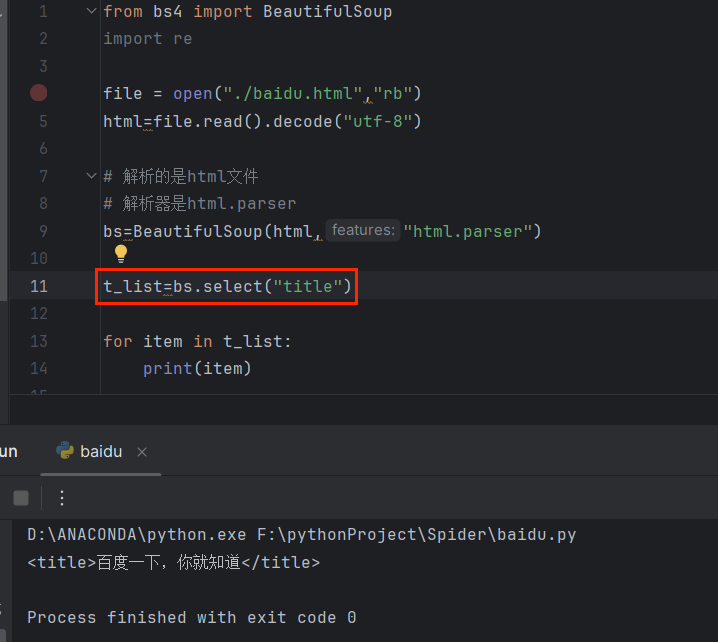
🛸通过标签来查找 select
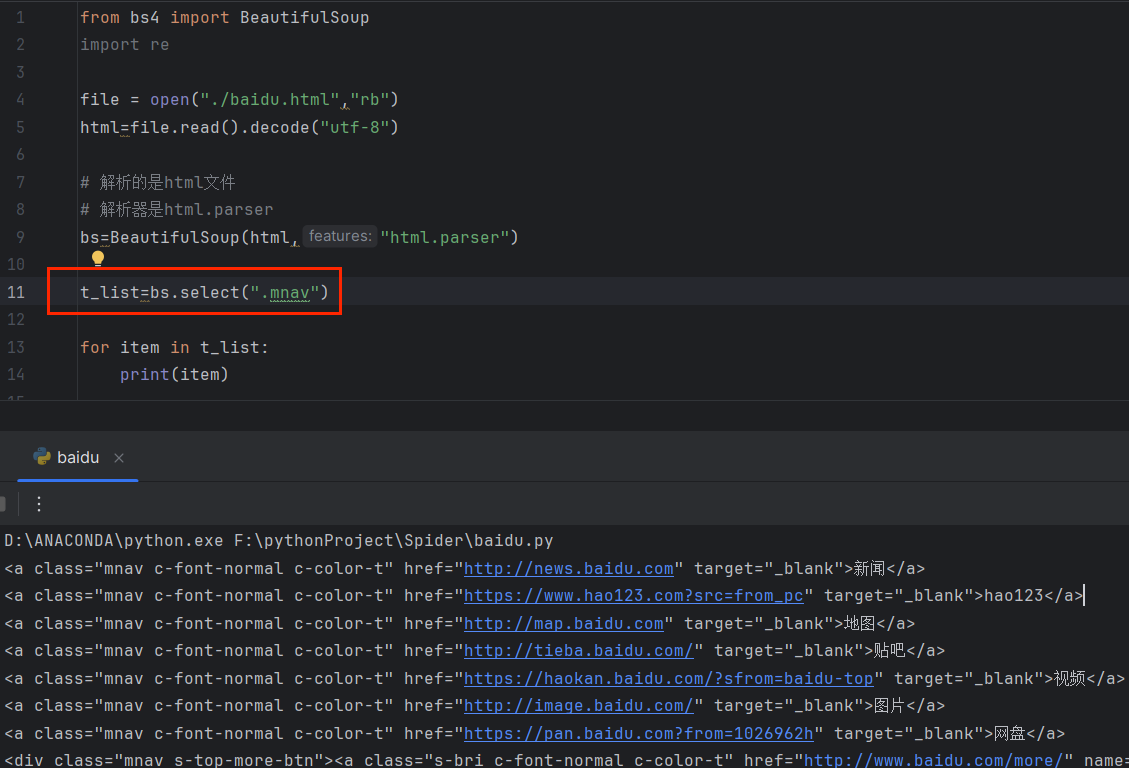
🛸通过类名来查找
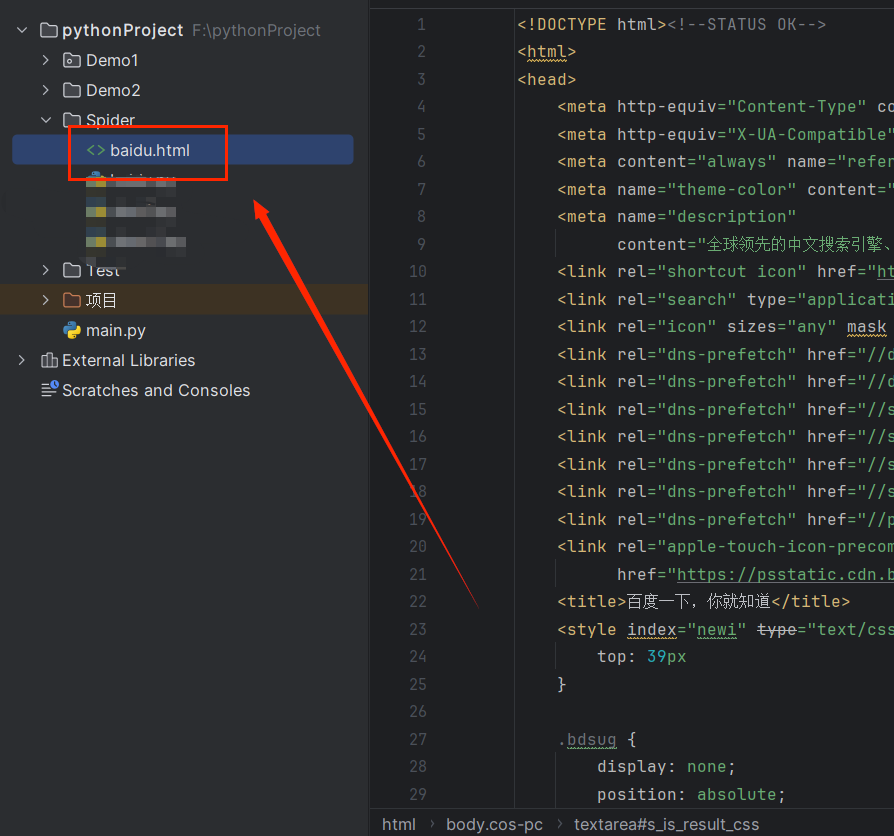
🛸通过id来查找