逻辑回归是属于机器学习里面的监督学习,它是以回归的思想来解决分类问题的一种非常经典的二分类分类器。由于其训练后的参数有较强的可解释性,在诸多领域中,逻辑回归通常用作 baseline 模型,以方便后期更好的挖掘业务相关信息或提升模型性能
一、逻辑回归的核心思想
1. 线性回归回顾
在理解逻辑回归之前,先简单回顾一下线性回归。线性回归试图找到一个线性函数,来拟合数据的特征与目标值之间的关系。假设我们有n个特征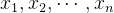

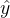
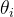
2. 逻辑回归的转变
逻辑回归的目标是进行分类,而不是预测连续值。对于二分类问题,我们希望模型能够输出样本属于某个类别的概率。为了实现这一点,逻辑回归引入了 sigmoid 函数,将线性回归的输出映射到[0,1]区间。
sigmoid 函数的定义为:
其中,z是线性回归的输出,即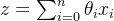
经过 sigmoid 函数的变换后,我们得到样本属于正类(通常标记为 1)的概率
那么样本属于负类(通常标记为 0)的概率为:
二、逻辑回归的损失函数
1. 损失函数的定义
损失函数用于衡量模型预测值与真实值之间的差异。对于逻辑回归,常用的损失函数是对数损失函数(Log Loss)。
单个样本的对数损失函数为: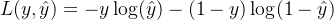
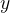
对于
![J(\theta) = -\frac{1}{m} \sum_{i = 1}^{m} [y^{(i)} \log(\hat{y}^{(i)}) + (1 - y^{(i)}) \log(1 - \hat{y}^{(i)})]](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9KJTI4JTVDdGhldGElMjk%3D%20%3D%20-%5Cfrac%7B1%7D%7Bm%7D%20%5Csum_%7Bi%20%3D%201%7D%5E%7Bm%7D%20%5By%5E%7B%28i%29%7D%20%5Clog%28%5Chat%7By%7D%5E%7B%28i%29%7D%29%20+%20%281%20-%20y%5E%7B%28i%29%7D%29%20%5Clog%281%20-%20%5Chat%7By%7D%5E%7B%28i%29%7D%29%5D)


2. 损失函数的解释
对数损失函数的设计基于极大似然估计的思想。我们希望模型预测的概率分布尽可能接近真实的标签分布。当真实标签
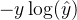

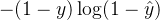
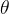
三、梯度下降求解逻辑回归
1.什么是梯度
梯度:梯度的本意是一个向量,由函数对每个参数的偏导组成,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向变化最快,变化率最大。
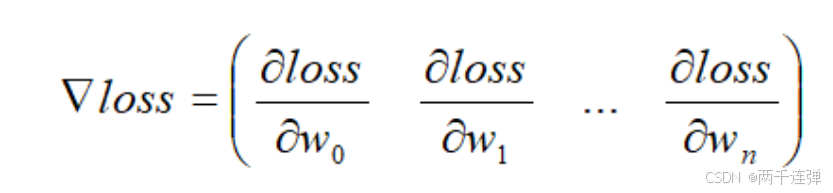
2. 梯度下降的原理
梯度下降是一种常用的优化算法,用于寻找函数的最小值。其基本思想是沿着函数梯度的反方向,逐步更新参数,使得函数值不断减小。
对于逻辑回归的损失函数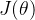
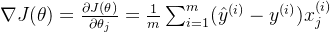
其中,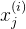
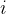
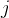
3. 梯度下降的迭代过程
在梯度下降算法中,我们通过不断迭代更新参数
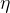
学习率的选择非常重要,如果学习率过小,算法收敛速度会很慢;如果学习率过大,可能会导致算法无法收敛,甚至发散。在实际应用中,通常需要通过实验来选择合适的学习率。
4. 随机梯度下降和批量梯度下降
- 批量梯度下降(Batch Gradient Descent,BGD):每次迭代都使用整个数据集来计算梯度,计算准确,但当数据集很大时,计算量非常大,效率较低。
- 随机梯度下降(Stochastic Gradient Descent,SGD):每次迭代只使用一个样本数据来计算梯度,计算速度快,但梯度更新方向可能不稳定,导致收敛过程有波动。
- 小批量梯度下降(Mini - Batch Gradient Descent,MBGD):结合了 BGD 和 SGD 的优点,每次迭代使用一小部分样本数据(称为一个 mini - batch)来计算梯度,既保证了计算效率,又能使梯度更新相对稳定。
5.梯度下降算法流程
- 随机初始参数;
- 确定学习率;
- 求出损失函数对参数梯度;
- 按照公式更新参数;
- 重复 3 、 4 直到满足终止条件(如:损失函数或参数更新变化值小于某个阈值,或者训练次数达到设定阈值)。
四、逻辑回归的动手实现
下面我们使用 Python 和 NumPy 库来手动实现逻辑回归算法,并在一个简单的数据集上进行训练和测试。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成一个包含1000个样本,20个特征的二分类数据集
X, y = make_classification(n_samples = 1000, n_features = 20, n_redundant = 0, random_state = 42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
def sigmoid(z):
return 1 / (1 + np.exp(-z))
class LogisticRegression:
def __init__(self, learning_rate = 0.01, num_iterations = 1000):
self.learning_rate = learning_rate
self.num_iterations = num_iterations
self.theta = None
def fit(self, X, y):
m, n = X.shape
# 初始化参数theta
self.theta = np.zeros(n)
for _ in range(self.num_iterations):
z = np.dot(X, self.theta)
h = sigmoid(z)
gradient = np.dot(X.T, (h - y)) / m
self.theta -= self.learning_rate * gradient
def predict(self, X):
z = np.dot(X, self.theta)
h = sigmoid(z)
return np.where(h >= 0.5, 1, 0)
# 创建逻辑回归模型实例
model = LogisticRegression(learning_rate = 0.01, num_iterations = 1000)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
通过以上步骤,我们成功地手动实现了一个简单的逻辑回归模型,并在生成的数据集上进行了训练和评估。在实际应用中,还可以进一步优化模型,比如通过交叉验证来更准确地选择学习率,使用 L1 或 L2 正则化防止过拟合,从而让模型在复杂的实际场景中表现得更加出色。
五、总结
逻辑回归是机器学习里经典的二分类分类器,因参数可解释性强常作 baseline 模型。它的核心思想是引入 sigmoid 函数,将线性回归输出映射到 [0,1] 区间,以得出样本分属正、负类的概率。常用对数损失函数衡量预测与真实值差异,基于极大似然估计思想找最优参数。通过梯度下降求解,沿梯度反方向更新参数,有批量、随机、小批量梯度下降等几种方式。
本文使用用 Python 和 NumPy 库等手动实现了一个简单的逻辑回归,在实际应用中还可以通过交叉验证、正则化等方法进行优化。
此外,在实际应用中,逻辑回归不仅可以用于简单的二分类问题,还能够通过扩展(如多分类逻辑回归、有序逻辑回归等)来处理更为复杂的分类任务。此外,逻辑回归也是许多其他复杂模型的基石,例如神经网络中的激活函数就借鉴了 sigmoid 函数的思想。
希望这篇博客能帮助你全面深入地理解逻辑回归。如果你在实际应用中遇到了相关问题,或者对某些内容还有疑问,欢迎在评论区留言交流。你也可以分享自己在使用朴素贝叶斯算法过程中的经验和心得,让更多的人受益。